Spring循环依赖及其解决方式
部分原文链接:java 循环依赖_Java详解之Spring Bean的循环依赖解决方案_以太创服的博客-CSDN博客
1,什么是循环依赖:
在spring中,对象的创建是交给Spring容器去执行的,Spring创建的Bean默认是单例的,也就是说,在整个Spring容器中,每一个对象都是有且只有一个。
那么这个时候就可能存在一种情况:
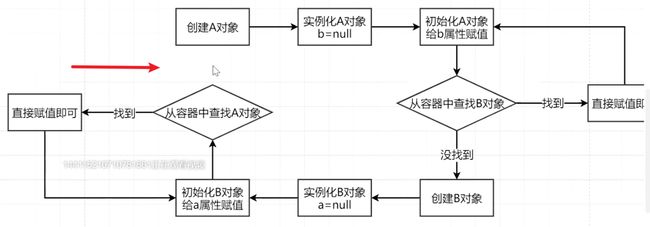
比如说,有一个A对象,它有一个b属性,还有一个B对象,它有一个a属性。当在对这两个对象进行属性赋值的时候,就会产生循环依赖问题。

假设先创建A对象,首先对A对象进行实例化,对A对象实例化完成之后,紧接着要对A对象进行初始化步骤中的属性赋值操作,那么在对b属性赋值的时候,此时是没有B对象的,
所以接着要开始创建B对象了,当创建了B对象,并对B对象进行实例化完成之后,接着要对B对象进行初始化步骤里边的属性赋值操作——对a属性进行赋值了,而这个时候A对象也还没有创建完成。
所以这个时候,就形成了一个闭环,形成了一个循环依赖,也就是出现了循环引用的问题,这个时候程序就会报错,提示程序无法继续执行下去了。
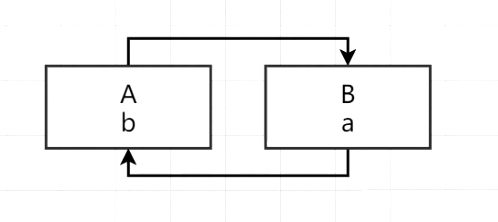
这是循环依赖最直接、最简单的一个例子,不管循环依赖是两个对象之间,还是三个对象、四个对象、五个对象等等,最后产生了循环依赖的原因都是如此。
循环依赖问题详解-图解:

当前这种情况形成了一个闭环,即产生了循环依赖问题。
循环依赖其实就是循环引用,就是两个或者两个以上的bean互相依赖对方,最终形成闭环,然后程序就会报错,提示程序无法继续执行下去了。
2,Spring中循环依赖分两类:
-
- 构造函数引起的循环依赖
- field属性引起的循环依赖
其中,构造器的循环依赖问题是无法解决的,只能拋出异常,
在解决属性的循环依赖时,spring采用的是 提前暴露对象的方法。
3,如何检测是否存在循环依赖 :
检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打个标记,如果递归调用一圈回来后,发现该Bean正在创建中的话,即说明发生了循环依赖了。
4,关于Spring中的创建对象过程:
4.1)Spring的单例对象的初始化步骤:
在Spring中,单例对象的初始化主要分为三步:
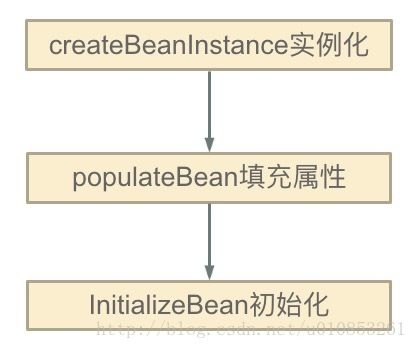
第一步(createBeanInstance):实例化,其实也就是调用对象的构造方法实例化对象;
第二步(populateBean):初始化--填充属性,这一步主要是对bean对象的属性进行填充,即注入属性、满足依赖;
第三步(initializeBean):初始化--增强处理,这一步之后该Bean就可以使用了。
从上面单例bean的初始化可以知道:循环依赖主要发生在第二步--填充属性,所以我们要解决循环引用也应该从这个过程着手。
对于单例来说,在Spring容器整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,
Spring为了解决单例的循环依赖问题,使用了三级缓存。
4.2)对象的具体属性是可以延后设置的:
PS:什么是Java的引用传递:在Java的方法中,传递对象参数的时候,实际传递的是该对象在内存中的内存地址。
Spring的循环依赖的理论依据是,基于Java的引用传递:即,可以先实例化对象,实例化对象之后,在内存中就有了该对象的内存地址了,我们就可以先从内存中获取到该对象了。
而对象的具体属性,是可以延后设置的。
举例:
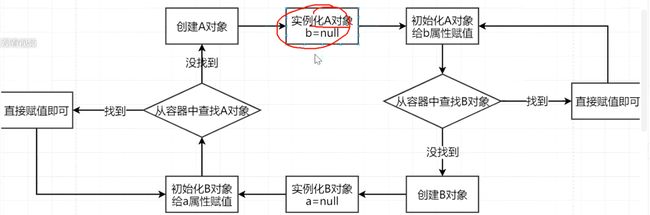
如上图所示,初始化B对象,要对a属性赋值的时候,要从容器中查找A对象的时候,这个时候其实Spring容器中有没有A对象?
其实是有的。只不过这个时候的A对象和我们传统意义上的A对象有些不一样。
对象的两种状态:
在对象的创建过程中,我们可以将对象分为两种状态:
-
- 一种是完成实例化以及初始化的对象,这种我们将其叫做“成品对象”;
- 另外一种是完成了实例化、但是还没有完成初始化的对象,这一种对象我们将其叫做“半成品对象”。
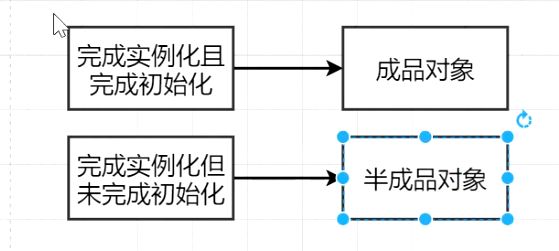
那么我们刚才从Spring容器中查找A对象的时候,这个时候的A对象是一种什么对象?毫无疑问,是一种“半成品对象”。
那么接着有一个至关重要的问题:如果当前对象持有了某一个对象的引用,那么能否在后续的步骤中给当前对象的相应的属性去进行赋值操作?
答案是可以的,因为有了某一个对象的引用之后,就意味着有了那个对象在内存中实际的内存地址,那么就一定能够对当前对象的相应属性进行一个赋值操作。
重新回到刚才从容器中查找A对象的步骤,此时虽然获取不到成品A对象,但是能够获取到半成品的A对象。
那么如何从容器中获取半成品的A对象呢,答案就是用到了缓存这个东西,即接下来的三级缓存。

在红框的步骤中,当我们实例化完成A对象之后,将半成品A对象先放入到一个缓存结构中;(比如说Map)
4.3)根本在于将实例化和初始化分开来考虑:
一般来说,Spring解决循环依赖问题的办法就是三级缓存以及提前暴露对象。
通过上边的分析,我们可以发现,其实解决的根本就是在创建对象的过程中,将Bean对象的实例化和初始化分开来进行考虑。

5,三级缓存解决循环依赖的理论过程:

按照上图中所示:
初始化A对象、给b属性进行赋值操作,然后从容器中查找B对象,
这个时候如果从容器中没有找到B对象,那么再从缓存中来查找一下是否存在B对象,
如果还是找不到,那么紧接着就开始创建B对象,创建完成B对象之后,然后是实例化B对象,
实例化B对象之后,我们将此时的半成品B对象也放入到缓存中去!

然后接着是初始化B对象、给a属性进行赋值操作,然后会先从容器中查找是否存在A对象,如果容器中没有A对象,那么再从缓存中去查找是否存在A对象,
此时发现缓存中是有A对象的,那么就可以完成了对B对象的a属性的赋值工作了,那么B对象就可以初始化完成了,那么这时的B对象就是一个成品了。
【注意此时B对象虽然是个成品了,但是它里边的a属性对应的A对象此时仍然是一个半成品】。
当B对象已经是一个成品了,那么将成品B对象放入缓存中,此时A对象的b属性就可以顺利进行赋值操作了,
A对象的b属性进行赋值操作之后,A对象就可以顺利的初始化完成,然后A对象便成为了一个成品对象了。
因为刚才创建B对象是因为要对A对象的b属性进行赋值才进行的, 所以接下来继续走创建B对象的代码,
先从Spring容器中以及三级缓存中查找是否已经存在B对象,这个时候缓存中已经存在B对象了,所以直接获取B对象即可。
以上,就是三级缓存解决循环依赖问题的大致理论过程。
6,三级缓存的概念:
6.1>引言:
在Spring容器的整个生命周期中,单例Bean有且仅有一个实例对象。这很容易让人想到可以用缓存来加速访问。
从源码中也可以看出Spring大量运用了Cache的手段,在循环依赖问题的解决过程中甚至不惜使用了“三级缓存”,这也便是它设计的精妙之处~
6.2>这三级缓存分别指:
(三级)singletonFactories : 单例对象工厂的cache,存放 bean 工厂对象;
(二级)earlySingletonObjects :提前曝光的单例对象的Cache ,用于存放已经实例化、但是还没有初始化填充属性的 bean 对象,(尚未填充属性);
(一级)singletonObjects:单例对象的cache,用于存放已经完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用。
PS:什么是提前曝光的对象:
所谓提前曝光的对象就是说,这是一个不完整的对象,它的属性还没有赋值,对象也没有被初始化-增强处理,它仅仅是被创建出来了(在内存中开辟出内存空间了、有内存地址了)。
这就是提前曝光的对象。
提前曝光的对象非常重要,是三级缓存解决循环依赖问题的一个很巧妙的地方。
6.3>三级缓存的大致工作流程:
-
- 在创建bean的时候,首先想到的是从cache中获取这个单例的bean,这个缓存指的是一级缓存singletonObjects。
- 如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。
- 如果还是获取不到,就从三级缓存中获取--singletonFactory.getObject()方法;
- 如果 在三级缓存中 获取到这个单例Bean了,则:从singletonFactories中移除该Bean,并放入earlySingletonObjects中,其实也就是从三级缓存提升到了二级缓存中,目的是将该Bean提前曝光。
从上面三级缓存的分析,我们可以知道,Spring解决循环依赖的诀窍就在于singletonFactories这个第三级缓存。这个cache的类型是ObjectFactory。这里就是解决循环依赖的关键,
在 createBeanInstance实例化Bean 之后,也就是说单例对象此时已经被实例化出来了。
这个对象已经被生产出来了,虽然还不完美(还没有属性赋值和增强实现,还是一个半成品对象),但是已经能被引用了(因为可以根据引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来,让其他的对象使用。
这样做有什么好处呢?让我们来分析一下:
6.4>举例:
假如说,“A的某个属性依赖了B的实例对象,同时B的某个field属性依赖了A的实例对象”这种循环依赖的情况。
A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories三级缓存中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去获取B对象,
结果发现B还没有被创建,所以走创建B对象的流程,B对象在初始化属性赋值的时候发现自己依赖了A对象,于是尝试获取A对象,尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过三级缓存中的ObjectFactory.getObject()方法拿到A对象(虽然A此时还是一个半成品对象),并将其放入到二级缓存中、从三级缓存中移除。
B拿到A对象后,顺利完成了初始化阶段,之后B对象将自己放入到一级缓存singletonObjects中。
此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段,最终A也完成了初始化,进入了一级缓存singletonObjects中,
所以最后,A和B对象都完成了初始化。
7,源码-三级缓存:
7.1> 三级缓存在哪里:
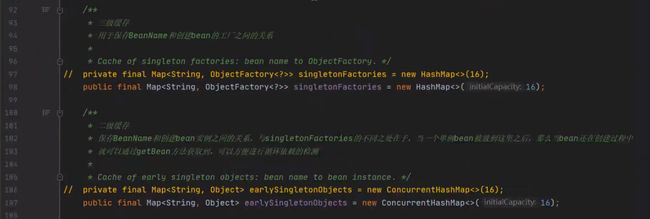
在Spring源码中有一个非常重要的类,叫做——DefaultSingletonBeanRegistry。在这个类里边,有三个缓存结构,这就是Spring里边的三级缓存。
如图所示:
/** Cache of singleton objects: bean name to bean instance. */
private final Map singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map earlySingletonObjects = new ConcurrentHashMap<>(16); 
解释:
-
- 三级缓存:singletonFactories;
- 二级缓存:earlySingletonObjects;
- 一级缓存:singletonObjects;
其实不管是三级缓存也好、还是二级缓存也好、还是一级缓存也好,都是我们人为的给它下的一个定义。源码的作者在写的时候并没有说哪个是一级、哪个是二级、哪个是三级。
7.2> 这三个缓存有什么样的区别:
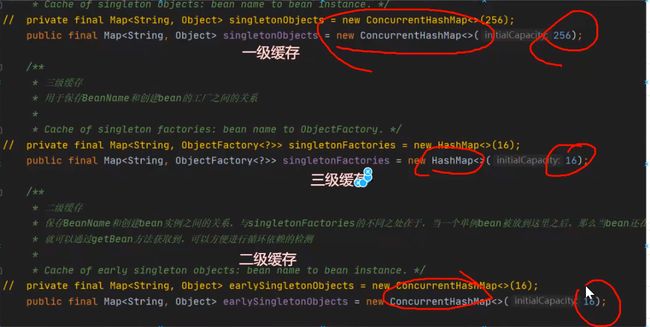
Map类型不同:
首先,从表面看,一级缓存和二级缓存是ConcurrentHashMap,三级缓存是HashMap结构。
容量不同:
其次,一级缓存的容量是256,二级缓存和三级缓存的容量是16。
泛型不一样:
其次,它们的泛型不一样:
- 三级缓存里边放的是ObjectFactory类型;
- 一级缓存和二级缓存的里边放的是Object类型的对象,
而这也才是最根本、最重要的区别。

7.3> ObjectFactory:
这个ObjectFactory是什么?其实它是一个函数式接口。
函数式接口的主要作用就是可以把匿名内部类和lambda表达式当作参数传递进方法里边去。
比如说,这里有一个函数式接口:{()->createBean()},那么此时将其作为参数传递到方法里边去了,那么当调用getObject()方法的时候,实际上调用的就是createBean()方法。
想理解函数式接口的详情可以去Java8新特性里边去学习一下。


7.4,先看Spring是如何实例化出一个对象的:
先记住六个方法:

首先,创建对象是从哪一个步骤开始的,在创建对象的时候有一个非常重要的方法,叫做——refresh()方法,在ClassPathXmlApplicationContext类里边。

在refresh()方法里边,包含了十三个创建对象的非常重要的步骤。

在【finishBeanFactoryInitialization(beanFactory);】这个步骤的时候,注意一下,正是在这一个步骤里边,才真正开始了对象的实例化操作。

进入finishBeanFactoryInitialization()方法,里边有一个步骤:beanFactory.preInstantiateSingletons();
在这个步骤里边,最后有一个步骤叫做:getBean(beanName);
这个getBean()方法的作用就是从Spring容器中先获取一下该对象,来判断该对象是否已经存在于Spring容器中。

点进去这个getBean()方法之后,里边是doGetBean()方法。

在doGetBean()方法里边,又可以看到一个方法叫做getSingleton(),就是从Spring容器中获取该单例对象,
如果Spring容器中此时没有该对象,那么就会走下边的if (sharedInstance != null && args == null) 相反的else方法。

在这个else里边,可以找到一段代码:
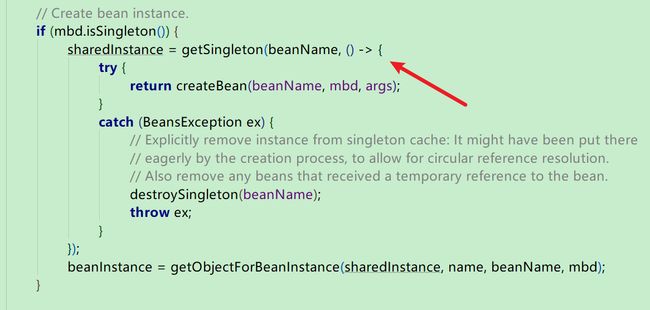
在这里,我们又发现了一个getSingleton()方法,只不过这时这里的参数多了一个lambda表达式。
但是该lambda表达式现在不会被调用执行,因为只有在调用getObject方法的时候才会调用执行该lambda表达式。
现在这个lambda表达式只是作为一个参数,传递到了getSingleton()方法里边去。
点击进入这个getSingleton()方法,可以看到一段代码:

这个singletonFactory参数是什么,就是上一段的lambda表达式:

那么此时执行了该lambda表达式的getObject()方法时,实际上执行就是该lambda表达式里边的内容——createBean()方法。

点进去createBean()方法之后,又可以找到一个叫做doCreateBean()的方法。

这里提个醒,在Spring源码里边,有很多以do开头的方法,当你看到这些以do开头的方法时,应该意识到,在这个方法里边,往往才是真正的逻辑处理过程。
点进去doCreateBean()方法,可以找到这个方法——createBeanInstance(),这个方法是实际执行对象的实例化操作的。

点进去createBeanInstance()方法里边,最后边可以找到一个方法——instantiateBean()方法。
进入实际的实例化环节点进去这个instantiateBean()方法,会发现一段代码:

点进去这个instantiate()方法之后,会发现这么一段代码:
这不就是常见的反射代码嘛,现在这里是获取了当前对象的构造器了,当有了构造器之后,那么紧接着就是该创建该对象了。

找到后边的代码BeanUtils.instantiateClass(constructorToUse),点进去instantiateClass这个方法,可以看到:
return ctor.newInstance(argsWithDefaultValues);
此时,就算是利用反射的方式,来创建出了对象了。

上述步骤,就是用来说明:Spring在创建对象的时候,在实例化对象的环节,是使用的反射的方式来完成了对对象的实例化了。
7.5,三级缓存在这里:
返回到doCreateBean()那一个步骤,里边有这么一段代码:
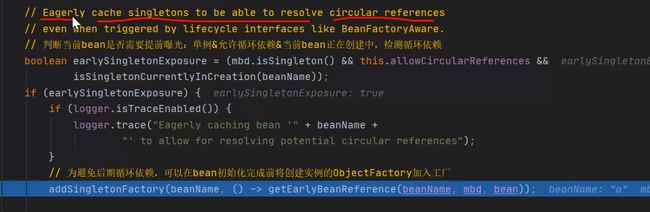
其中,
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
这一句代码其实就是Spring三级缓存的核心点。
看注释也能看出来:“这里能够解决循环依赖问题。”

观察addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
这一句代码,发现后边的参数又是一个lambda表达式,点进去这个addSingletonFactory方法进去,可以看到Spring三级缓存的核心代码:

> 这三句代码的意思:
this.singletonFactories.put(beanName, singletonFactory); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName);
先看这一句:
this.singletonFactories.put(beanName, singletonFactory);
这一句代码的意思:
this.singletonFactories是我们的三级缓存,这个都知道;
这一句代码的意思是将singletonFactory也就是那个lambda表达式形式的ObjectFactory对象,将其作为参数放入到三级缓存singletonFactories中。
this.earlySingletonObjects.remove(beanName);这一句的意思是:放入到三级缓存singletonFactories中之后,并从2级缓存earlySingletonObjects中移除(虽然这里没有)。
this.registeredSingletons.add(beanName);这一句的意思是:将该对象放入注册的容器中,意味着设置A对象已经开始注册。
7.6,三级缓存的流程举例:
7.6.1,实例化A对象,并放入到三级缓存singletonFactories中;
从容器中和缓存中都获取不到A对象,说明还没有A对象,那么开始创建A对象。
假设此时的key为beanName,比如说“对象A”。
示意图:

在创建A对象的时候,刚才已经实例化完成A对象了,所以将此时的半成品A对象给放入到三级缓存中去了,
7.6.2,对A对象进行属性赋值操作:
将半成品A对象放入到三级缓存中之后,那么接下来该干嘛了,该给A对象的属性赋值了。也就是接下来的代码:

在populateBean()方法中,该给A对象的属性进行赋值了。
“在对属性赋值的过程中,可能会存在有一些属性依赖其他的Bean,那么就会递归着去创建依赖的Bean”。

详情:
点进去populateBean方法里边,在里边的最后一步:

点进去这个applyPropertyValues方法,看到这一段代码:可以看出,此时属性名叫做b,以及属性值的类型是RuntimeBeanReference。

再往下看到这一句代码:

点进去这个resolveValueIfNecessary方法,

很明显,刚才已经知道属性值是RuntimeBeanReference类型,所以会进入到if条件里边的resolveReference方法,点进去该方法,看到这一段代码:
第一句是获取一下Bean的名称;
第二句是从Spring容器中获取一下b属性对应的B对象;

点进去该getBean方法之后,发现如下代码:

7.6.3,实例化B对象,并将其放入到三级缓存中:
此时,发现开始套娃了。类比于之前,接下来会进入到doGetBean方法,在该方法里边会先判断Spring容器中是否已经存在该对象,如果发现Spring容器中不存在该对象,则走else——开始创建该对象,然后进入一个叫做getSingleton的方法,此时进入该方法的时候会传入一个lambda表达式。
然后会进入getSingleton这个方法,在这个方法里边会去执行singletonFactory.getObject();也就是会开始调用执行lambda表达式里边的createBean方法:

点进去这个createBean之后,会执行一句代码:

点进去这个doCreateBean方法之后,会去执行一句代码:

点进去createBeanInstance 方法之后,会去执行如下代码:

点进去instantiateBean方法之后,会去执行如下代码:

点进去instantiate方法之后,可以看到如下代码,

执行这段代码之后,就是通过反射的方式创建出了该对象的构造器了,那么紧接着就可以根据构造器创建出来该对象了:

点进去这个instantiateClass方法进去,会发现如下代码:
return ctor.newInstance(argsWithDefaultValues);

此时,就算是利用反射的方式,来创建出了对象了。
然后,回到刚才的doCreateBean()那一个步骤,会发现如下代码:

点进去这个addSingletonFactory方法之后,可以看到是将B对象的lambda表达式形式的ObjectFactory对象也添加到三级缓存中,然后将该B对象从二级缓存中移除(虽然这里没有),设置该对象已经开始注册。
那么此时B对象也就创建完成,并放入了三级缓存中。
7.6.4,对B对象进行属性赋值操作:
紧接着,就是该对B对象的属性赋值操作了:

B对象只有一个a属性:
B对象的属性赋值操作的详情:
populateBean方法——applyPropertyValues方法—— valueResolver.resolveValueIfNecessary()方法——resolveReference方法——this.beanFactory.getBean方法——doGetBean方法——getSingleton方法——getSingleton(beanName, true)方法
在最后这一个getSingleton(beanName, true)方法里边,可以看到如下代码:
Object singletonObject = this.singletonObjects.get(beanName);
这句代码的意思是先从一级缓存中获取该对象即对象A;
因为此时半成品对象A是在三级缓存中的,所以此时会进入if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {...}中,
isSingletonCurrentlyInCreation的意思是该对象是否正在创建中,毫无疑问此时对象A和B都是正在创建中的状态。
接着继续执行代码:singletonObject = this.earlySingletonObjects.get(beanName);,意思是从二级缓存中获取该对象,此时还是获取不到,
最终,会走到这一句代码:
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
这个时候是从三级缓存中去取该对象,答案是能够取到的。
只不过此时从三级缓存中取出来的实际上是一个lambda表达式,
所以当取出来的是一个lambda表达式的时候,会紧接着执行singletonObject = singletonFactory.getObject();
即通过getObject方法来实际执行lambda表达式(() -> getEarlyBeanReference(beanName, mbd, bean))中的方法——getEarlyBeanReference。

点进去getEarlyBeanReference方法,看到如下一段代码:
这一段代码的处理逻辑,才是三级缓存的精髓所在。
在这里,先将A对象赋值给了exposedObject,
然后如果进入if条件,会修改exposedObject,
如果进不去,就直接返回了exposedObject。
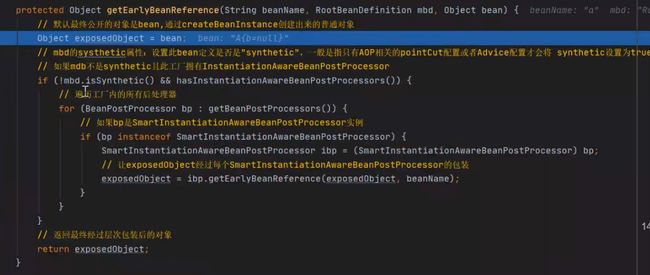
7.6.5,从三级缓存中获取到A对象,将其赋值给B对象的a属性,同时将A对象放入到二级缓存earlySingletonObjects中;
所以刚才的singletonObject = singletonFactory.getObject(); 便从三级缓存中获取到了A对象。
然后接着执行代码:this.earlySingletonObjects.put(beanName, singletonObject);
意思是将A对象放入到二级缓存中了。注意此时的A对象还是个半成品。
然后执行代码this.singletonFactories.remove(beanName);意思是将A对象从三级缓存中移除。
于是,现在的一二三级缓存变成了这个情形:

因为半成品A对象此时在缓存中,所以获取到了A对象,完成了对a属性的赋值操作,
如图:初始化B对象过程中,完成了对a属性的赋值操作:

7.6.6,B对象创建完成,将B对象放入到一级缓存singletonObjects中:
接着,B对象创建完成,此时的B对象接着就从一个半成品对象成为了一个成品对象了。
但还没完,在接着的getSingleton方法的最后还有一句代码:

在这个addSingleton方法里边,有这么一段代码:
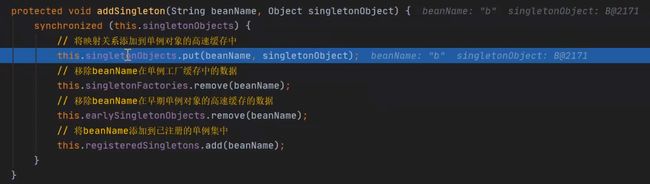
this.singletonObjects.put(beanName, singletonObject);
这一句代码的意思是将B对象放入到一级缓存中,此时的B对象是一个成品对象了。
然后是this.singletonFactories.remove(beanName);意思是移除三级缓存中的B对象。(又一次尝试移除)
然后是this.earlySingletonObjects.remove(beanName);,意思是移除二级缓存中的B对象。
最终如图所示:

7.6.7,A对象也随之创建完成,将其放入到一级缓存singletonObjects中;
B对象创建完成之后,接着就意味着A对象的b属性也就接着完成了赋值操作,A对象也就继而创建完成,从一个半成品对象成为了一个成品对象了。
然后也是同样在创建完成之后,执行addSingleton方法,和B对象的过程一样,最终,将A对象放入一级缓存中,然后将三级缓存和二级缓存中的A对象移除。
最终如图所示:
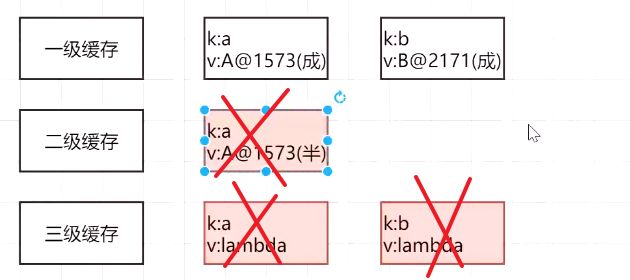
此时,A对象已经创建完成了。注意,刚才B对象的创建以及存入一级缓存中主要是因为A对象的b属性赋值才发生的,
7.6.8,后边需要创建B对象的时候,直接从一级缓存中获取:
所以接下来代码还是会继续创建B对象的,只不过创建B对象的时候发现能够直接从一级缓存中取到,
就不再继续走原来的一系列实例化初始化操作了,变为直接从一级缓存中取出来。
8,问题与建议
8.1,三个缓存对象,在获取数据的时候,是按照什么顺序来获取的?
答:先从一级缓存中获取对象,如果没有再从二级缓存中获取,二级缓存中没有再从三级缓存中获取。
所以当前面级别的缓存中存在了对象,那么后面级别的缓存就需要把该对象给移除。
8.2,如果只有一级缓存,能解决循环依赖问题吗?
不能,如果只有一级缓存,那么成品对象和半成品对象会放到一起,这个是没办法区分的,所以需要两个缓存来分别存放不同状态的对象,一级缓存-存放成品,二级缓存-存放半成品。
8.3,如果只有一级和二级缓存,能否解决循环依赖问题?
在刚刚的整个流程中,三级缓存一共出现了几次? getsingleton , doCreateBean。
如果对象的创建过程中不包含 aop ,那么一级二级缓存就可以解决循环依赖问题,
但是如果包含 aop 的操作,那么没有三级缓存的话,循环依赖问题是解决不了的。
8.4,为什么添加了AOP的操作之后,就必须需要三级缓存来解决循环依赖问题?
在创建代理对象的时候,是否需要生成原始对象?答案肯定是需要。
当创建完成原始对象之后,后续有需要创建代理对象,那么此时就是一个 beanName 对应有两个对象,(原始对象和代理对象),那么在通过beanName引用的时候应该使用哪一个对象?
在整个容器中,有且仅能有一个同名的对象,当需要生成代理对象的时候,就要把代理对象覆盖原始对象。
程序是怎么知道在什么时候要进行代理对象的创建的呢?
那么就需要一个类似于回调的接口判断,当第一次对外暴露使用的时候,来判断当前对象是否需要去创建代理对象;
而三级缓存加了什么操作?添加了一个 getEarlyBeanReference 的方法。
getEarlyBeanRefenerce 方法里边的 if 判断:
-
- 如果需要代理,就返回代理对象,
- 如果没有代理,就返回原始对象。
8.5,三级缓存能够解决AOP代理问题的核心:
因为在getBean的时候,getBean——doGetBean——getSingleton——getSingleton(beanName, true);
会有如下代码:
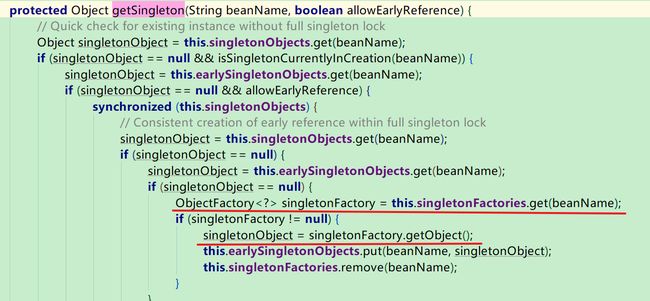
在这里,当一级缓存和二级缓存中都没有该对象的时候,会在三级缓存中去查找,
在三级缓存中查找到了之后,会取到一个lambda表达式,紧接着会执行getObject方法,也就是实际上会调用lambda表达式中的方法——doCreateBean方法里边的这里:

即执行这部分代码里边的getEarlyBeanReference方法:
点进去getEarlyBeanReference方法:
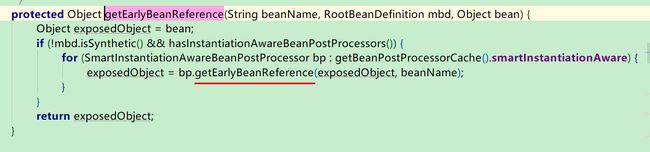
再点进去 bp.getEarlyBeanReference()方法:
此时会到达AbstractAutoProxyCreator类的getEarlyBeanReference方法:
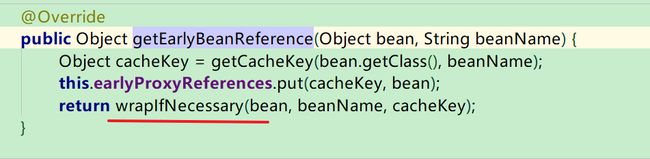
点进去wrapIfNecessary方法:
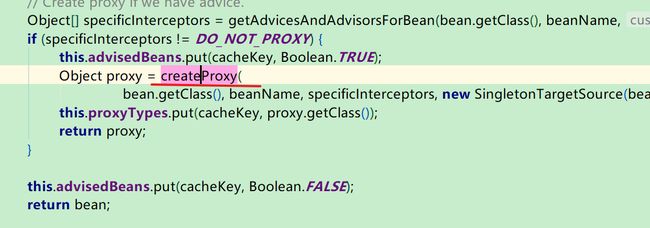
点进去createProxy方法:

在最后是一个返回代理方式的方法,点进去:

继续点进去:

此时会发现,要么选择jdk代理,要么选择cglib代理,即创建了代理对象——回到刚才的getEarlyBeanReference方法中,
说明了bp.getEarlyBeanReference(exposedObject, beanName);这一步的目的是创建代理对象。
而三级缓存加了什么操作?正是添加了一个 getEarlyBeanReference 的方法。
所以回到最初的从三级缓存中获取到对象的时候,取到的是一个lambda表达式的原因,
因为当实际执行lambda表达式的时候,执行的lambda表达式里边的那个getEarlyBeanReference方法,就是在该方法里边:
——要么执行了bp.getEarlyBeanReference()方法:返回的提前暴露对象exposedObject,是该对象的代理对象;
——要么返回的提前暴露对象exposedObject,就直接是该原始对象本身。

所以说,使用了三级缓存就意味着使用了lambda表达式,就意味着可以在实际执行lambda表达式的时候,lambda表达式中的方法要么返回代理对象、要么返回原始对象,避免了根据同一个beanName一下子获取到两个对象的错误。
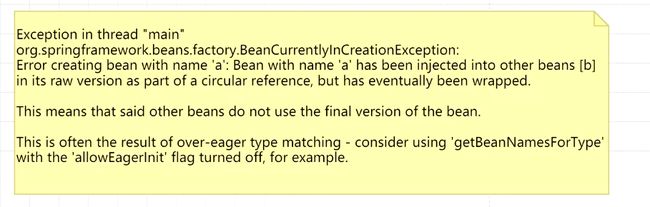
所以说,在提前暴露对象的时候,可以去判断返回的是原始对象还是代理对象,只返回一个,这就是三级缓存可以解决AOP代理问题的核心。
总结:为什么Spring中除了一级二级缓存之外还有三级缓存,因为要防止AOP代理出现问题;
![]()
8.6,对于循环依赖问题,Spring一定能百分之百解决掉吗?
答:
Spring其实也只是提供了一种机制-三级缓存机制,来解决循环依赖问题,但是对于循环依赖问题,Spring一定能百分之百解决掉吗?不能。
Spring提供了三级缓存只是说能够预防一部分的循环依赖问题,但是不能说就能够预防所有的循环依赖问题。
所以说有的时候,也需要我们去检查写的代码是否存在问题,然后去解决。
8.7)对于依赖注入的使用建议:
不要使用基于构造函数的依赖注入,会导致循环依赖问题无法解决;
可以通过以下方式进行依赖注入:
1、使用@Autowired注解,让Spring决定在合适的时机注入;
2、使用基于setter方法的依赖注入。
9,捋一捋:源码八个步骤解析
1、实例化A对象,并将其放入到三级缓存singletonFactories中;
- SpringBoot项目启动执行到SpringApplication#run 中的refreshContext(context);,最终调用Spring容器的AbstractApplicationContext#refresh方法,开始初始化BeanFactory。
- 在AbstractApplicationContext#refresh步骤中,执行到AbstractApplicationContext#finishBeanFactoryInitialization方法,开始完成 Bean 工厂初始化。
- 执行到AbstracBeanFactory.preInstantiateSingletons(),开始根据BeanFactory中的BeanDefinition信息初始化Bean对象。
- 在AbstracBeanFactory.preInstantiateSingletons()方法中,发现A对象的BeanDefinition,执行AbstracBeanFactory.getBean方法,获取A对象。
- 在AbstracBeanFactory.getBean方法中,执行AbstracBeanFactory.doGetBean方法,获取A对象。
- 在AbstracBeanFactory.doGetBean方法中执行DefaultSingletonBeanRegistry#getSingleton方法,尝试从缓存中获取A对象的单例对象缓存。
- 到一级缓存singletonObjects中找,未找到;
- 到二级缓存earlySingletonObjects中找,未找到;
- 到三级缓存singletonFactories中找,未找到;
- 再次执行DefaultSingletonBeanRegistry#getSingleton的重载方法,传入lamda表达式形式的ObjectFactory对象,内部调用AbstractAutowireCapableBeanFactory#createBean方法,尝试创建A对象。
- 在AbstractAutowireCapableBeanFactory#createBean方法中,调用AbstractAutowireCapableBeanFactory#doCreateBean方法,实际执行创建A对象。
- 实例化A对象,给字段赋值默认值后,调用DefaultSingletonBeanRegistry#addSingletonFactory方法,传入A对象的lamda表达式形式的ObjectFactory对象,将ObjectFactory对象放入三级缓存singletonFactories中,并从2级缓存earlySingletonObjects中移除(虽然这里没有),设置A对象已经开始注册。
- 此处传入的lamda表达式,内部调用了`AbstractAutowireCapableBeanFactory#getEarlyBeanReference`,此方法用来执行实现了`SmartInstantiationAwareBeanPostProcessor`的后置处理器,比如实现AOP的AbstractAutoProxyCreator
2、对A对象进行属性赋值操作:
- 然后开始执行A对象的AbstractAutowireCapableBeanFactory#populateBean,进行属性填充。
3、创建B对象,并将其放入到三级缓存singletonFactories中:
- 在进行属性填充时,发现依赖了B对象,执行AbstracBeanFactory.getBean方法,尝试获取B对象。参考上面步骤4~9。
4、对B对象进行属性赋值操作:
- 执行到B对象的属性填充时,发现依赖了A对象,执行AbstracBeanFactory.getBean方法,尝试获取A对象。
- 在AbstracBeanFactory.doGetBean方法中执行DefaultSingletonBeanRegistry#getSingleton方法,尝试从缓存中获取A对象的单例对象缓存。
- 到一级缓存singletonObjects中找,未找到;
- 到二级缓存earlySingletonObjects中找,未找到;
5、在三级缓存中找到了A对象,并将其放入到二级缓存earlySingletonObjects中;
- 到三级缓存singletonFactories中找,找到了,并调用ObjectFactory的getObject方法获取A对象的引用,ObjectFactory内部调用了`AbstractAutowireCapableBeanFactory#getEarlyBeanReference`,获取到A的早期对象,将A的早期对象放入二级缓存earlySingletonObjects中,并将三级缓存singletonFactories中A对象移除;
6、B对象初始化完成,将B对象放入到一级缓存singletonObjects中;
- 这样拿到A的对象之后,B的属性填充完毕,B初始化完成,方法return到DefaultSingletonBeanRegistry#getSingleton的重载方法时,调用DefaultSingletonBeanRegistry#addSingleton方法,将B对象放入一级缓存,并将B从二三级缓存中移除(虽然已经没有了)。
7、A对象也随之初始化完成,将A对象也放入到一级缓存singletonObjects中;
- 这样在return回A的流程,第11步,将A依赖的B属性填充完整,此时A也填充完毕,初始化完成,方法继续return到A流程的DefaultSingletonBeanRegistry#getSingleton的重载方法时,调用DefaultSingletonBeanRegistry#addSingleton方法,将A对象放入一级缓存,并将A从二三级缓存中移除(此时只有二级缓存中有)。
- 这样A和B就初始化完成了。
- 如果A或者B存在AOP,需要返回代理对象,这操作是在第9步的AbstractAutowireCapableBeanFactory#getEarlyBeanReference中完成的,B尝试获取A的时候,触发了这个方法,如果A需要被代理,则是在这个方法中执行的,这个方法最终返回了一个代理对象,并将这个对象以A的名义放入了二级缓存。
8、后边需要创建B对象的时候,直接从一级缓存singletonObjects中获取:
接下来代码还是会继续创建B对象的,只不过创建B对象的时候发现能够直接从一级缓存中取到,
就不再继续走原来的一系列实例化初始化操作了,变为直接从一级缓存中取出来即可。