bitCount-计算数字二进制中1的个数
目录
- 1. 题目描述
- 2. 解决方法
- 3. bitcount解法分析
- 4. 参考
个人博客原创链接: http://dopaminer.xyz/2021/10/28/bitCount/
主要介绍bitcount位运算实现,思路和java中bitcount的实现一样。
1. 题目描述
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为 汉明重量).)。
LeetCode
2. 解决方法
- 解法1
第一反应就是直接暴力,代码如下:
int hammingWeight(uint32_t n) {
int ret = 0;
for (int i = 0; i < 32; i++) {
if (n & (1 << i)) {
ret++;
}
}
return ret;
}
这种算法的时间复杂度O(k),因为这里为uint32_t,k为32。取决于传入的数据的数据类型长度。
空间复杂度O(1)。
- 解法2
在解法一中这种算法可以优化,具体分析过程见leetcode。代码如下
int hammingWeight(uint32_t n) {
int ret = 0;
while (n) {
n &= n - 1;
ret++;
}
return ret;
}
时间复杂度O( l o g n log_n logn),循环次数等于n的二进制位中1的个数。
空间复杂度O(1)。
- 解法3
除了上述解法外,还有一种基于位运算的解法,先上C/C++代码
int hammingWeight(uint32_t n) {
n = n - ((n >> 1) & 0x55555555);
n = (n & 0x33333333) + ((n >> 2) & 0x33333333);
n = (n + (n >> 4)) & 0x0f0f0f0f;
n = n + (n >> 8);
n = n + (n >> 16);
return n & 0x3f;
}
这也是java里bitcount的实现。下面具体分析这种解法的过程。
3. bitcount解法分析
为了更好的了解过程,下面将对上述解法3的代码逐行分析。
- 第一行
n = n - ((n >> 1) & 0x55555555);
要理解这一行代码的作用,首先要先明白下述原理。
一个2bit的二进制数,其所有的组合有00, 01, 10, 11。若要计算这个2bit的数的二进制有多少个1,则可以用这个数减去其二进制第二个位上的数字,得到的便是这个2bit数字的二进制中的1个个数。

根据这个原理,就可以知道上面那行代码的作用,它依次统计两个bit上1的个数,并将结果保存到对应的两个bit上,举例:
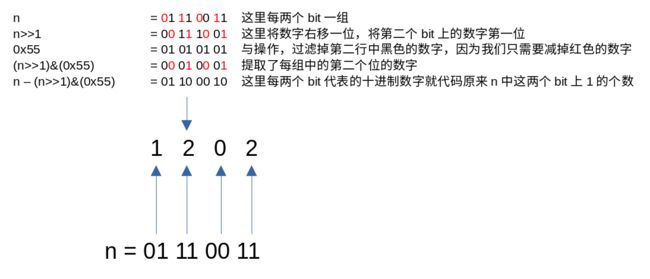
- 第二行
n = (n & 0x33333333) + ((n >> 2) & 0x33333333);
在上面我们将数字每2个bit分一组,计算出这两个bit有多少个1,并将结果放到对应的组上。这行代码的目的则是为了将相邻两组中的1的个数加起来。从而实现将数字二进制中4个bit为一组进行分组,并且每组中1的个数有多少个。
继续复用上述例子

- 第三行
n = (n + (n >> 4)) & 0x0f0f0f0f;
与上述同理,将数字8个bit为一组,并计算每组有多少个1

- 第四行
n = n + (n >> 8);
这里也和上述同理,利用8bit分组的结果,将相邻两个8bit组和起来,计算16bit一组中,每组中有多少个1。
- 第五行
n = n + (n >> 16);
同理,计算32bit一组有多少个1。
- 第六行
return n & 0x3f;
因为n为32位,在最大的情况下也只有32个1,因此用6个位即可表示所有情况。因此和0x3f与运算。
全部代码
n = n - ((n >> 1) & 0x55555555); // 1
n = (n & 0x33333333) + ((n >> 2) & 0x33333333); // 2
n = (n + (n >> 4)) & 0x0f0f0f0f; // 3
n = n + (n >> 8); // 4
n = n + (n >> 16); // 5
return n & 0x3f; // 6
这里可能会有疑问,既然在return的时候已经只取了最后6个位,那为什么第2 3行不可以和 第4 5行一样不要过滤呢?看下面这个例子。
当我们输入uint32_t类型的最大值的时候,分别看有过滤和没过滤,每一行代码的输出结果
验证代码:
#include - 有
0x0f0f0f0f过滤的

-
无
0x0f0f0f0f过滤的把
n = (n + (n >> 4)) & 0x0f0f0f0f;中的0x0f0f0f0f删掉。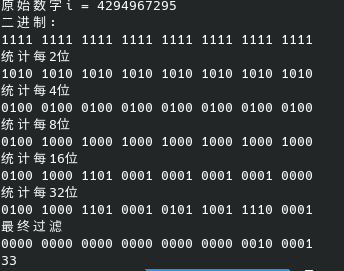
这里可以发现最终结果中多了一个1,现在顺着输出往回找看看这个1是哪里来的。

可以发现由于没有过滤,其无效bit在加的过程导致其进位到有效bit上了,直接导致结果出错。
那为什么后面就不需要过滤?理论上可以过滤,但是在32位的情况下可以发现到后面,即使无效bit再怎么和前面相加,都不会导致其进位到有效bit上了(比如在i = i + (i>>8)中,因为高8位和低8位中的前4位在上面已经置0了,而两个4bit的数相加的大小是不可能超过8bit的,也就不会有无效位进位问题了)。因此就在最后return的时候过滤,减少算法与运算的次数,提高效率。
emm…反正挺麻烦的,最后再看一下大概流程。

int hammingWeight(uint32_t n) {
n = n - ((n >> 1) & 0x55555555); //2bit一组,计算有多少个1
n = (n & 0x33333333) + ((n >> 2) & 0x33333333); //根据2bit分组的结果,计算4bit一组有多少个1
n = (n + (n >> 4)) & 0x0f0f0f0f; //根据4bit分组的结果,计算8bit一组有多少个1
n = n + (n >> 8); //根据8bit分组的结果,计算16bit一组有多少个1,这里没过滤,有无效位
n = n + (n >> 16); //根据16bit分组的结果,计算32bit一组有多少个1,这里也没过滤,有无效位
return n & 0x3f; //一次性过滤,只取最后6个位的结果。
}
4. 参考
https://www.cnblogs.com/inmoonlight/p/9301733.html
https://blog.csdn.net/u011497638/article/details/77947324