深度学习之相关硬件知识总结
俗话说得好,工欲善其事必先利其器,想要学好深度学习,你必须拥有足够的算力,否则一切都只是停留在纸上谈兵了。下面就自己了解的进行以下总结:
(1)算力---处理单元
人工智能的实现需要依赖三个要素:算法是核心,硬件和数据是基础。 算法主要分为为工程学法和模拟法。工程学方法是采用传统的编程技术,利用大量数据处理经验改进提升算法性能;模拟法则是模仿人类或其他生物所用的方法或者技能,提升算法性能,例如遗传算法和神经网络。 硬件方面,目前主要是使用 GPU 并行计算神经网络。
从产业结构来讲,人工智能生态分为基础、技术、应用三层。基础层包括数据资源和计算能力;技术层包括算法、模型及应用开发;应用层包括人工智能+各行业(领域),比如在互联网、金融、汽车、游戏等产业应用的语音识别、人脸识别、无人机、机器人、无人驾驶等功能。
CPU、GPU 和 TPU 是常见的处理单元,具体差异比较如下:
- CPU出现于大规模集成电路时代,处理器架构设计的迭代更新以及集成电路工艺的不断提升促使其不断发展完善。从最初专用于数学计算到广泛应用于通用计算,从4位到8位、16位、32位处理器,最后到64位处理器,从各厂商互不兼容到不同指令集架构规范的出现,CPU 自诞生以来一直在飞速发展,CPU比较适合串行计算。
- GPU(图像处理单元)是英伟达(NVIDIA)制造的图形处理器 (GPU)专门用于在个人电脑、工作站、游戏机和一些移动设备上进行图像运算工作,是显示卡的“心脏”。就目前来看,GPU不是完全代替CPU,而是两者分工合作,GPU特别适合大规模并行运算。
- TPU,即谷歌的张量处理器——Tensor Processing Unit。TPU是一款为机器学习而定制的芯片,经过了专门深度机器学习方面的训练,它有更高效能(每瓦计算能力)。大致上,相对于现在的处理器有7年的领先优势,宽容度更高,每秒在芯片中可以挤出更多的操作时间,使用更复杂和强大的机器学习模型,将之更快的部署,用户也会更加迅速地获得更智能的结果。
- FPGA,即现场可编程门阵列,它是在PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。作为专用集成电路(ASIC)领域中的一种半定制电路而出现的芯片,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。系统设计师可以根据需要通过可编辑的连接把FPGA内部的逻辑块连接起来,就好像一个电路试验板被放在了一个芯片里,可以作为一种用以实现特殊任务的可再编程芯片应用与机器学习中。
(2)怎么选择算力
这里可以参考华盛顿大学博士Tim Dettmers结合竞赛经验给出的GPU选择建议,可以结合自己的情况进行选择,

性能最好的GPU:RTX 2080 Ti(现在已经30系列的天下,显卡也在不断升级更新中)
性价比高,但小贵:RTX 2080, GTX 1080
性价比高,同时便宜:GTX 1070, GTX 1070 Ti, GTX 1060
使用的数据集>250GB:RTX 2080 Ti, RTX 2080
预算很少:GTX 1060 (6GB)
几乎没预算:GTX 1050 Ti (4GB)/CPU(建模)+ AWS/TPU(训练)
参加Kaggle竞赛:GTX 1060 (6GB)(建模)+ AWS(最终训练)+ fast ai库
有前途的CV研究员:GTX 2080 Ti; 在2019年升级到RTX Titan
普通研究员:RTX 2080 Ti/GTX 10XX -> RTX Titan,注意内存是否合适
有雄心壮志的深度学习菜鸟:从GTX 1060 (6GB)、GTX 1070、GTX 1070 Ti开始,慢慢进阶
随便玩玩的深度学习菜鸟:GTX 1050 Ti (4或2GB)
计算显卡的主要性能指标:
1、CUDA compute capability,这是英伟达公司对显卡计算能力的一个衡量指标;
2、FLOPS 每秒浮点运算次数,TFLOPS表示每秒万亿(10^12)次浮点计算;
3、另外,显存大小也决定了实验中能够使用的样本数量和模型复杂度。
由于想要利用nvidia的显卡进行加速,一般需要同等配置cuda加速器,这里可以参考我的另一篇博客,至于显卡的选择还是结合自己的情况进行选择吧!
对于nvidia显卡的选择,市面上有很多,由于AMD和NVIDIA是最上游的芯片及公版设计商。华硕、技嘉、微星、七彩虹、索泰百等等这些品牌都是下游的具体硬件生产商AMD和NVIDIA把自己研发的芯片生度产出来,然后交给这些下游的合作负责具体产品的二次设计和生产。这些品牌有的拥有自己的工厂,有的则是以代工的方式生专产,然后以各自的品牌在市场上销售。华硕 技嘉 微星 索泰这种一线品牌,质量更好,但价位偏高,七彩虹 影驰这种二线品牌,性能更好,价位适中,但容易出问题,可以根据自己的预算选择。同时AMD或者英伟达会发行芯片给显卡厂商,自己也会推出公版显卡。公版显卡(FE)会有不同的散热方案(但是比非公差)。另外,公版也是一种设计方案,所以显卡厂商也会推出公版设计的显卡。非公版的芯片还是英伟达的,不同的厂商有不同的散热、供电、接口方案,也会有超频(带OC的卡),会有更强性能,价格也会差很多。就RTX2080Ti而言,顶级非公和丐版非公相差3000-4000块。
(3)算法---框架的选择
现在市场上的深度学习框架呈现百家争鸣的态势,各家公司都想在人工智能的浪潮中分一杯羹,
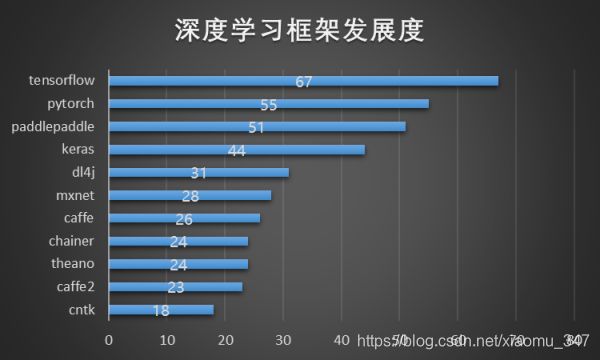
除了上面常见的tf、torch等深度学习框架外,在国内BAT等大厂也纷纷推出了自家的产品,下面就来简单总结以下,
- 百度paddlepaddle:这算是国内最成熟的一个框架了,百度最早在人工智能领域的布局使得他们在国内这一块也走的最远,飞桨同时支持动态图和静态图,能方便地调试模型,方便地部署,非常适合业务应用的落地实现。飞桨也已经支持数百个节点的高效并行训练。可以说在过去2年的时间里,深度学习领域在大规模的落地应用,各家框架也都在快速的发展,但是百度的飞桨看来是这个阶段发展更快的框架,甚至是发展更快的AI开发生态。
- 腾讯ncnn,这是一个为手机端极致优化的高性能神经网络前向计算框架,无第三方依赖,跨平台,手机端 cpu的速度快于目前所有已知的开源框架。
- 阿里X-DeepLearning,主要是针对面向广告、推荐、搜索等高维稀疏数据场景,填补TensorFlow、PyTorch等现有开源深度学习框架主要面向图像、语音等低维稠密数据的不足。
- 华为MindSpore,结合自家的昇腾芯片,华为在这一块的布局开始快速发力。
- 清华大学Jittor,是一个采用元算子表达神经网络计算单元、完全基于动态编译(Just-in-Time)的深度学习框架,其主要特性为元算子和统一计算图。在编程语言上,Jittor 采用了灵活而易用的 Python。用户可以使用它,编写元算子计算的 Python 代码,然后 Jittor将其动态编译为 C++,实现高性能。
- 一流科技OneFlow:其Actor机制和SBP机制,在计算图中显式表达了数据搬运,而且在静态分析时同等对待数据搬运和数据计算,以最大化重叠搬运和计算。
综上所述,要想在深度学习这块有所作为,根据自己的情况进行算力和算法的选择,和自己情况适配最好的才是最棒的!
参考链接:
GPU/CPU/TPU都是啥?有何区别? - 全文 - 电子发烧友网(GPU/CPU/TPU都是啥?有何区别?)
Deep Learning GPU Benchmarks - V100 vs 2080 Ti vs 1080 Ti vs Titan V
https://blog.csdn.net/weixin_33690367/article/details/89586323(GPU、TPU、FPGA,三大AI芯片“争奇斗艳”)
https://blog.csdn.net/zhang43211234/article/details/80953080(主流深度学习框架对比)
https://blog.csdn.net/zengNLP/article/details/105003287(盘点国内那些深度学习框架)
百度安全验证(oneflow)