C++:深入理解编译和链接过程
深入理解编译链接
我们知道,用c/c++语言编写程序的时候,必须要经过编译和链接过程,才能将我们c/c++的源代码转化为可执行文件(Windows下是.exe程序,Linux下是elf格式的可执行文件)。
那么编译和链接过程到底做了什么,这个可执行文件又是被加载到哪里运行的呢
数据和指令
无论用哪种语言所写的代码,归根结底会产生两种东西:指令和数据。那哪些代码是指令,哪些代码是数据?
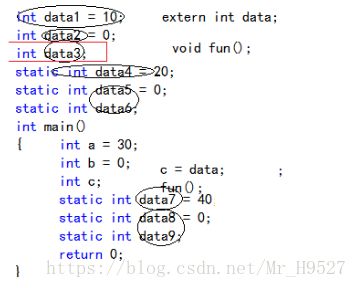
所有的全局变量和静态变量都是数据,除此之外都是指令(包括局部变量)。我们来看一段代码

很明显在上面这段代码中,data1,2,3,4,5,6,7,8,9都是数据,除了这些之外其他的代码都是指令。我们都知道,程序是被加载到内存上运行的,既然代码被分成了指令和数据两种不同的东西,那么在内存中他们就不可能被无序的,混乱的放在一起,肯定会有一定的划分规定。
虚拟地址空间
在每个程序运行的时候,我们的操作系统都会给他分配一个固定大小的虚拟地址空间(x86,32bit,Linux内核下默认大小为4G),那这段内存是怎样分配的呢?我们来看一下

这就是虚拟地址空间各个区域的分布图,从图中可以看出,整个4G的空间有1G是供操作系统使用的内核空间,用户无法访问,还有3G是我们的用户空间,以供该虚拟地址空间上进程的运行。在这3G的用户空间中又被分成了很多段,从0地址开始的128M大小是系统的预留空间,用户也是无法访问的,接下来是.text段,该段空间中存放的是代码,然后是.data段和.bss段,这两段里面存放的都是数据,但又有不同:.data段中存放的数据是已经初始化并且初始化值不为0的数据,而.bss段中存放的是未经初始化或者初始化为0的数据。我们可以看一下Linux下虚拟地址空间的分配状况
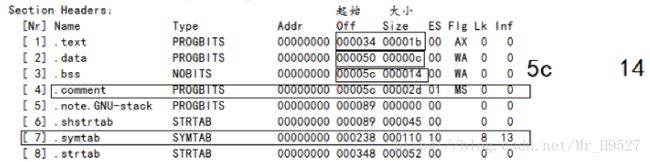
上面是Linux下一块进程的虚拟地址空间的段表信息,我们可以清楚的看到上面有我们的.text段,.data段,.bss段等信息,说明这些段是真实存在的,而不是我们人为臆造出来的。但是我们在查看段表信息的时候会发现,.bss段的起始地址和.comment段的起始地址是相同的,这是为什么呢?bss三个英文字母的含义是:better save space(更好的节省空间),这里所节省的空间是谁的空间呢?我们知道程序运行的时候要从文件中加载到内存上,而上面这个段表信息是在生成中间文件.o文件时所调出来的,也就是说此时还没有生成可执行文件,自然系统也不会为其分配虚拟地址空间,因此显而易见,这里所节约的是文件的空间,
也就是说,在生成的中间文件中,系统并没有为.bss段分配空间,那其中的数据是如何保存的呢,其实不难理解。我们先把这个问题保留下来,后面会解决。现在我们来看一下编译和链接过程主要做了什么。
编译过程
编译过程中,系统主要会做三件事:预编译,编译,汇编。
预编译: 去掉代码中的注释,处理以“#“号开头的预处理命令,进行宏替换
编译:生成符号,将源代码的指令转化为汇编指令
汇编:生成二进制可重定位文件
这里我们比较陌生的就是生成符号了,也是我们的重点。c/c++代码在编译时会生成符号,所有的数据都会生成符号,而指令只有函数名会生成符号。我们在返回我们上面那个段表中看一下,我们知道上面的代码中会有六个数据存放在.bss段,可是.bss段的大小只有20个字节也就是说其中只有5个数据(16进制的14转换到十进制是20),那另外的那个数据难道丢了吗??其实,生成符号的过程中,所有静态的变量生成的符号是local符号(仅当前文件可见),所有初始化了的非静态全局变量都会生成一个global(所有文件可见)的强符号,而未被初始化的非静态全局变量就会生成一个global的弱符号。弱符号是不确定的符号,不确定是否有其他文件中同名的变量会生成强符号,或者其他同名的变量虽然生成弱符号,但是所占的内存比该弱符号大,以上两种情况,在链接过程中,该弱符号都会被替换掉(强符号若同名会产生编译错误,在编译时就已经确定,弱符号在链接时才确定)。那很明显上面的代码中,data3会产生弱符号,因此在编译时弱符号不会被存储在.bss段,而是被保存在comment块中,我们来看一下符号表

我们看到,未被初始化的Data3并未被存放在.bss段,而是在comment块中,因为他是一个弱符号。此时我们在另外一个文件中定义一个变量和一个函数,在main.c文件调用这个函数和变量
我们再看一下符号表

可以明显的看到最下面的两个*UND*的符号,这是因为在编译的过程中,是每个文件单独编译的,不会看到其他文件中定义的东西,在main.c中只有变量data和函数fun()的声明,所以他们会被认为是未定义的符号。
链接过程
编译完成之后,紧接着会进行链接过程,我们先来看一下来链接过程到底做了什么
合并段
在elf文件中字节对齐是以4字节对齐的,但是在可执行程序中对齐方式是以页的方式对齐的(一个页的大小为4k),因此如果我们在链接时将各个.o文件各个段单独的加载到可执行文件中,将会非常浪费空间:如下表

因此我们需要合并段,调整段偏移,将各个文件不同的段合并起来,每个.o文件的.text段合并在一起.data段合并在一起,这样,在生成的可执行 文件中,各个段都只有一个,如下图,由于在链接时只需要加载代码段(.text段)和数据段(.data段和.bss段)。因此合并段之后,在系统给我们分配内存时,只需要分配两个页面大小就可以,分别存放代码和数据如图

调整段偏移
合并段之后,必须进行的一个操作就是调整段偏移和段长度。每个进程都有自己的虚拟地址空间,都是从0地址开始的,将各个文件的各个段加载进来之后,段的大小会有所变化,相对于0地址的偏移量也会不同,因此我们需要调整段偏移和段偏移如图

汇总所有符号
每个obj文件在编译时都会生成自己的符号表,所以我们要把这些符号都合并起来进行符号解析
完成符号的重定位
在进行合并段,调整段偏移时,输入文件的各个段在连接后的虚拟地址就已经确定了,这一步完成后,连接器开始计算各个符号的虚拟地址,因为各个符号在段内的相对位置是固定的,所以段内各个符号的地址也已经是确定的了,只不过连接器需要给每个符号加上一个偏移量,使他们能够调整到正确的虚拟地址,这就是符号的重定位过程
在 elf文件中,有一个叫重定位表的结构专门用来保存这些与从定位有关的信息,重定位表在elf文件中往往是一个或多个段
运行