MySQL——SQL语句
文章目录
- 一. SQL的概念
-
- 1. 定义
- 2. 分类
- 二. DML语句
-
- 1. insert练习
-
- 1.1 语法
- 1.2 代码示例
- 2. update练习
-
- 2.1 语法:
- 2.2 代码示例
- 3. delete练习
-
- 3.1 语法
- 3.2 示例代码
- 三. DQL语句
-
- 1. 常见约束
- 2. select练习
-
- 2.1 不带条件查询练习
- 2.2 带条件查询练习
- 2.3 排序查询
- 2.4 聚合查询
- 2.5 分组查询
- 2.6 分页查询
一. SQL的概念
1. 定义
Sql 是专门操作数据库的增删改查的一种语言。
- 结构化查询语言(Structured Query Language)简称 SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
2. 分类
-
数据定义语言(DDL Data Definition Language)
针对数据库或表做创建、 修改和删除操作。 关键字:CREATE,ALTER,DROP 和 SHOW。 -
数据查询语言(DQL Data Query Language)
针对表中数据做查询操作 关键字:SELECT。 -
数据操作语言(DML Data Manipulation Language)
针对表中数据做添加、修改和删除操作 关键字:INSERT、UPDATE 和 DELETE。 -
数据控制语言(DCL Data Control language)
通过 GRANT 或 REVOKE 关键字实现权限控制。 -
事务控制语言(TCL Transcation Cnontrol language)
通过 COMMIT、SAVEPOINT、ROLLBACK命令确保被DML语句影响的表的所有行及时得以更新。
二. DML语句
1. insert练习
1.1 语法
insert语法:
insert [into] 表名 (col,col2,col3....)
values/value(value1,value2,.....)
说明:into可以省略
增加数据的时候可以选择性的使用字段添加数据,values后面设置的值必须和增加的字段数量类型一致
values或者value都可以使用
1.2 代码示例
/*注释:
单行注释#或者--
多行注释/*123*/
*/
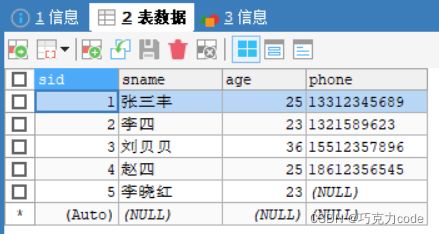
#增加学生信息:完整语法使用
INSERT INTO
students(sid,sname,age,phone)
VALUES(1,"张三丰",25,"13312345689");
#增加学生:省略into关键字
INSERT students(sid,sname,age,phone)
VALUES(2,"李四",23,"1321589623");
#增加学生:使用value关键字
INSERT INTO students(sid,sname,age,phone)
VALUE(3,"刘贝贝",36,"15512357896");
#增加学生:可以省略主键值设置,主键设置了自增加,每次会默认增加一
INSERT INTO students(sname,age,phone)
VALUES("赵四",25,"18612356545");
#增加学生:姓名和年龄,表的字段可以选择性的添加,省略的字段必须设置允许为空
INSERT INTO students(sname,age)VALUES("李晓红",23);
2. update练习
2.1 语法:
update 表名 set col=value,col2=value2,.....
[where col=value and col2=value2]
说明:
where表示修改的条件关键字
set后面可以设置多个字段值,使用逗号分隔字段
where后面也可以设置多个条件,多个条件之间使用and连接
2.2 代码示例
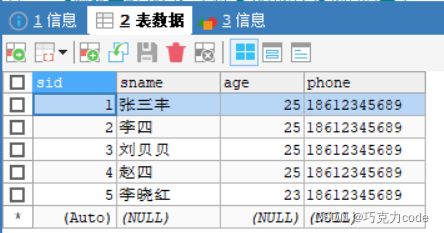
#修改学生信息:将所有的学生年龄设置为18
UPDATE students SET age=18;
#修改学生信息:将学生手机号为空的设置手机号为15525369874
UPDATE students SET phone="15525369874" WHERE phone IS NULL;
#修改学生信息:同时修改多个字段
#将学生年龄修改为25,手机修改为18612345689
UPDATE students SET age=25,phone="18612345689";
#修改学生信息:设置多个条件
#修改学生年龄是23,修改的学生的id是5,姓名是李晓红
UPDATE students SET age=23 WHERE sid=5 AND sname="李晓红";
3. delete练习
3.1 语法
delete from 表名 [where col=value and col2=value2]
说明:
不加where条件的时候表示删除表中所有数据
where条件后面可以设置多个条件字段值
3.2 示例代码
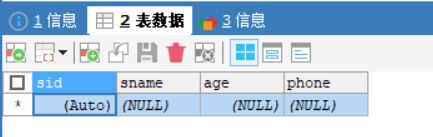
#删除id为3学生信息
DELETE FROM students WHERE sid=3;
#删除年龄为25,手机号为18612345689的学生
DELETE FROM students WHERE age=25 AND phone="18612345689";
#删除所有数据
DELETE FROM students;
三. DQL语句
1. 常见约束
约束概念:mysql数据库表中对字段的值规范要求。
mysql常见约束:
- 非空:NOT NULL 字段的值不能为空
- 唯一:UNIQUE 表中字段的值不能有重复值
- 主键:PRIMARY KEY 每张表都有一主键字段(非空并且唯一)
- 自增长:AUTO_INCREMENT 字段的值会每次增加1(字段类型需要是int整型)
- 默认:DEFAULT 字段设置一个默认值
- 外键:FOREIGN KEY 通常是在做两表关联的时候设置一个关联约束
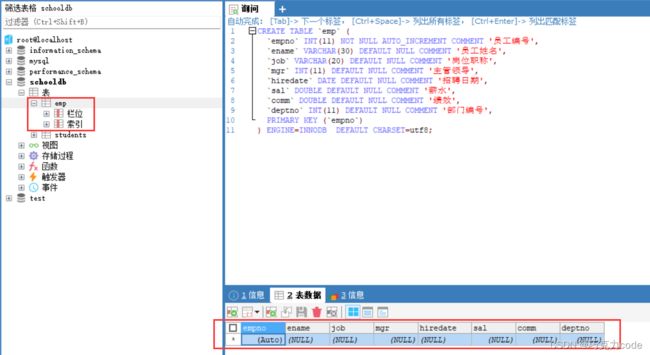
#创建员工表
CREATE TABLE `emp` (
`empno` INT(11) NOT NULL AUTO_INCREMENT COMMENT '员工编号',
`ename` VARCHAR(30) DEFAULT NULL COMMENT '员工姓名',
`job` VARCHAR(20) DEFAULT NULL COMMENT '岗位职称',
`mgr` INT(11) DEFAULT NULL COMMENT '主管领导',
`hiredate` DATE DEFAULT NULL COMMENT '招聘日期',
`sal` DOUBLE DEFAULT NULL COMMENT '薪水',
`comm` DOUBLE DEFAULT NULL COMMENT '绩效',
`deptno` INT(11) DEFAULT NULL COMMENT '部门编号',
PRIMARY KEY (`empno`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
#添加员工数据
INSERT INTO
`emp`(`empno`,`ename`,`job`,`mgr`,`hiredate`,
`sal`,`comm`,`deptno`)
VALUES
(1,'张三','经理',5,'2005-10-16',42000,NULL,10),
(2,'王洪','销售员',7,'2019-02-01',8000,1000,11),
(3,'欧阳华','销售员',4,'2006-10-16',15000,8900,11),
(4,'刘玄德','经理',5,'2009-10-01',50000,34000,10),
(5,'赵思才','董事长',NULL,'2018-10-16',500000,NULL,1001),
(6,'张得让','文员',1,'2009-10-16',5000,NULL,14),
(7,'张石材','经理',5,'2010-10-16',20000,5600,10),
(8,'王牡丹','文员',1,'2012-10-16',4500,1200,10),
(9,'刘绮莉','销售员',4,'2018-02-16',12300,0,11),
(10,'吴晓华','文员',1,'2014-10-16',5500,NULL,14),
(11,'钱是从','经理',5,'2008-10-16',35000,NULL,11),
(12,'王百万','文员',1,'2018-10-16',5000,NULL,14),
(13,'王思葱','维修技师',7,'2018-07-16',25000,4500,12),
(14,'杨思盈','文员',1,'2018-09-16',7000,NULL,14),
(15,'杨迪','保洁员',11,'2011-10-16',4000,NULL,13);
2. select练习
语法:
select col1,col2,col3....... from 表名 [where col=value and col2=value2]
说明:
select 表示查询的关键字
from表示查询的目标表名称
where条件关键字,表示可以进行条件查询
2.1 不带条件查询练习
#1、创建emp数据库表
#2、查询所有员工的姓名
SELECT ename FROM emp;
#3、查询所有员工的姓名和工资
SELECT ename,sal FROM emp;
#4、查询员工的所有信息
SELECT empno,ename,job,mgr,hiredate,sal,comm,deptno FROM emp;
#查询所有信息的简写:*代表表中的所有字段名(学习阶段可以使用,工作研发的时候不建议使用)
SELECT * FROM emp;
#5、查询员工的姓名和工资,展示的时候使用“姓名”“工资”
#as别名关键字的使用:可以给表字段名或者表名起别名(更加容易识别和理解)
SELECT ename AS "姓名" ,sal AS "基本工资" FROM emp;
#as可以省略
SELECT ename "姓名" ,sal "基本工资" FROM emp;
#引号可以省略
SELECT ename 姓名,sal 基本工资 FROM emp;
#给表起别名:通过别名调用表的字段(通常使用在表关联查询的时候)
SELECT e.`ename`,e.`job`,e.`sal` FROM emp e;
#6、查询所有员工的部门编号
SELECT deptno FROM emp;
#7、查询所有员工的不重复的部门编号
#去重查询关键字使用:DISTINCT
SELECT DISTINCT deptno FROM emp;
#8、查询所有员工的姓名和绩效,如果为空则用0表示
#函数ifnull的使用:参数1表示需要查询的目标字段,参数2表示替换目标值的数据
SELECT ename 姓名,IFNULL(comm,0) 绩效 FROM emp;
#9、查询员工姓名及其岗位: 如我是张三,我的岗位是销售员
SELECT ename,job FROM emp;
#函数concat的使用:将多个字符串进行拼接处理
SELECT CONCAT("我是:",ename,",我的岗位是:",job) 个人简介
FROM emp;
#10、今年业绩不错,每个员工工资sal涨个1000,把涨薪前后的结果显示出来
#查询的字段可以直接进行数字的运算操作:+ - * /
SELECT ename 姓名, sal 涨薪前 ,sal+1000 涨薪后 FROM emp;
#11、查询每个员工的薪资(工资+绩效)
#当绩效没有的时候,使用0替换:函数参与字段的运算操作
SELECT ename 姓名,sal+IFNULL(comm,0) 薪资 FROM emp;
2.2 带条件查询练习
/*
条件查询
1.比较运算符的使用:> < >= <= between ...and ...
2.or关键字的使用和in关键字使用
3.不等于符号的使用:!= <> not
4.null值判断:is 和 is not
5.模糊查询:like关键字
*/
#12、查询出底薪在10000~30000之间的员工信息
#区间条件使用:sal>=10000 sal<=30000 或者 sal between 10000 and 30000
SELECT * FROM emp WHERE sal>=10000 AND sal<=30000;
#注意:between 小值 and 大值
SELECT * FROM emp WHERE sal BETWEEN 10000 AND 30000;
#13、查询部门编号为10或者11的员工信息
#or关键字的使用:表示或者的条件
SELECT * FROM emp WHERE deptno=10 OR deptno=11;
#in 关键字使用:表示条件范围
SELECT * FROM emp WHERE deptno IN (10,11);
#14、查询出部门编号不是11部门的员工信息
#不等于符号的使用:!= <> not
SELECT * FROM emp WHERE deptno !=11;
SELECT * FROM emp WHERE deptno <>11;
SELECT * FROM emp WHERE NOT(deptno=11);
#15、查询出上级领导为null的员工信息
#is关键字的使用:作用相当于=但是不能直接使用=去判断
SELECT * FROM emp WHERE mgr IS NULL;
#16、查询出上级领导不为null的员工信息
SELECT * FROM emp WHERE mgr IS NOT NULL;
#like关键字使用:_一个下划线代表一个字符 %代表一个或者多个字符
#17、查询出名字以张开头,并且两个字的员工信息
SELECT * FROM emp WHERE ename LIKE "张_";
#18、查询出名字是三个字的员工信息
SELECT * FROM emp WHERE ename LIKE "___";
#19、查询出名字以张开头的员工信息
SELECT * FROM emp WHERE ename LIKE "张%";
#20、找到职位最后是以"员"结尾的员工信息
SELECT * FROM emp WHERE job LIKE "%员";
#21、查询出名字里面带“思”的员工信息
SELECT * FROM emp WHERE ename LIKE "%思%";
2.3 排序查询
语法:
select * from 表名 order by 排序字段名 asc /desc;
说明:
order by 表示排序,后面是排序依赖的字段,一条sql只能写一次(多个条件排序的时候只能有一个)
asc 升序 (从小到大的顺序展示),默认值,可以省略
desc 降序(从大到小展示),关键字不能省略
注意事项:
当排序字段涉及到多个的时候,先按照第一个字段排序,当第一个字段值相同的时候,再按照第二个字段排序,依次类推,直到所有的字段排序完成。如果第一个字段的值没有重复数据,后面的字段就不排序。
示例代码
#按照底薪降序显示员工信息:按照底薪从高到低排列展示
SELECT * FROM emp ORDER BY sal DESC;
#按照招聘时间降序显示
SELECT * FROM emp ORDER BY hiredate DESC;
#按照部门编号升序显示员工信息
SELECT * FROM emp ORDER BY deptno ;
#按照领导升序排列显示:null是表示最小
SELECT * FROM emp ORDER BY mgr ;
#按照部门编号升序,再按照入职日期降序,最后按照薪资降序排列,显示员工信息
SELECT * FROM emp ORDER BY deptno ASC, hiredate DESC , sal DESC;
2.4 聚合查询
语法:
所谓聚合查询,指的是mysql提供的几个聚合函数的使用。
max() 求字段最大值
min() 求字段最小值
sum() 求字段的和的值
avg() 求字段值的平均值
count() 求表数据的总条数
示例代码
#求出员工的最高薪资:max
SELECT MAX(sal) FROM emp;
#求员工的最早入职日期:min
SELECT MIN(hiredate) FROM emp;
#求员工的平均薪资:avg
SELECT AVG(sal) FROM emp;
#求员工的薪资总和:sum
SELECT SUM(sal) FROM emp;
#求员工的数量:获取表数据的总条数
SELECT COUNT(empno) FROM emp;
SELECT COUNT(*) FROM emp;
2.5 分组查询
语法:
select 查询字段 from 表名 group by 分组字段 [having 分组条件]
注意事项:
分组查询可以带条件,也可以不带条件。
如果带条件,需要having关键字。
having条件后面通常使用聚合查询。
where和having区别:
1.where后面使用表中固有的字段
2.having通常是跟聚合查询的条件,通常是表中没有的字段属性
示例代码:
#统计每个部门下的员工数量
#查询员工数量、部门编号,以部门编号分组
SELECT deptno ,COUNT(*) FROM emp GROUP BY deptno;
#统计每个岗位下的员工平均薪资
#查询平均工资、岗位,以岗位分组
SELECT job,AVG(sal) FROM emp GROUP BY job;
#统计每个部门的最高薪资
#查询最高薪资、部门编号,以部门编号分组
SELECT deptno,MAX(sal) FROM emp GROUP BY deptno;
#查询每个部门中薪资大于10000的员工人数
#查询部门编号、员工数,以部门编号分组,条件是sal>10000
SELECT deptno,COUNT(*) FROM emp WHERE sal>10000 GROUP BY deptno;
#查询出部门人数大于2的部门及其人数,并按照人数降序排列
#查询部门编号、人数,以部门分组,条件是部门人数>2,排序:部门人数排序
SELECT deptno ,COUNT(*) FROM emp
GROUP BY deptno HAVING COUNT(*) >2
ORDER BY COUNT(*) DESC;
2.6 分页查询
语法:
select 字段 from 表名 limit index,size
说明:
index:表示查询数据的起始索引,索引从0开始。可以省略,此时表示查询第一页数据
size:每页查询显示的数据条数
示例代码
#将我们的员工表数据进行分页查询,设置每页显示三条
#查询第一页数据
SELECT * FROM emp LIMIT 0,3;
#查询第二页数据
SELECT * FROM emp LIMIT 3,3;
#查询第三页数据
SELECT * FROM emp LIMIT 6,3;
#limit 的参数可以省略前面的第一个参数
#查询薪资的前三名
SELECT * FROM emp ORDER BY sal DESC LIMIT 3;
#查询公司入职最早的员工信息
SELECT * FROM emp ORDER BY hiredate LIMIT 1;
#注意事项:使用limit关键字做最值查询时候,需要满足数据库表中没有重复数据