机器学习之回归与聚类算法
回归与聚类算法
- 线性回归
- 欠拟合与过拟合
- 分类算法-----逻辑回归与二分类
- 模型保存和加载
- 无监督学习----K-means算法
目录
- 回归与聚类算法
-
- 线性回归
-
-
- 线性回归的损失和优化原理
- 优化损失
- 线性回归API
-
- 欠拟合与过拟合
-
-
- 正则化
- 岭回归
-
- 分类算法-----逻辑回归与二分类
-
-
- 分类的评估方法
-
- 模型保存和加载
- 无监督学习----K-means算法
线性回归
回归问题:目标值—连续型的数据
什么是线性回归?
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
函数关系 :特征值和目标值
这个函数,我们叫他线性模型
特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归

广义线性模型:

线性模型:
自变量一次/参数一次
线性关系必须是自变量一次
线性回归的损失和优化原理
目标:求模型参数
损失函数/cost/成本函数/目标函数 :真实值和预测值之间的差距

优化损失
-
正规方程----直接求解

-
梯度下降----不断试错、改进

线性回归API

回归性能评估:

案例:房价预测
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
def linear():
"""
正规方程的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5)得出模型
print("正规方程-权重系数为:\n", estimator.coef_)
print("正规方程-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("正规方程-均方误差为:\n", error)
return None
if __name__ == "__main__":
# 正规方程的优化方法对波士顿房价进行预测
linear()
from sklearn.datasets import load_boston
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def linear():
"""
梯度下降的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000, penalty="l1")
estimator.fit(x_train, y_train)
# 5)得出模型
print("梯度下降-权重系数为:\n", estimator.coef_)
print("梯度下降-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("梯度下降-均方误差为:\n", error)
return None
if __name__ == "__main__":
# 梯度下降的优化方法对波士顿房价进行预测
linear()
正规方程和梯度下降

拓展:关于优化方法GD、SGD、SAG
-
GD
梯度下降,原始的梯度下降法需要计算所有样本的值才能够得出梯度,计算量大,所以后面才有会一系列的改进。 -
SGD
随机梯度下降,是一个优化方法。它在一次迭代时只考虑一个训练样本。
优点:
1.高效
2.容易实现
缺点:
1.SGD需要许多超参数:比如正则项参数、迭代数。
2.SGD对于特征标准化是敏感的。
- SAG
随机平均梯度法,由于收敛的速度太慢,有人提出SAG等基于梯度下降的算法
Scikit-learn: 岭回归、逻辑回归等当中都会有SAG优化
欠拟合与过拟合
欠拟合:因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅

过拟合:机器已经基本能区别天鹅和其他动物了。然后,很不巧已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
训练集上表现的号,但是测试集上表现不好 -------过拟合
 定义:
定义:
- 过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(摸型过于复杂)
- 欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
如何解决?
欠拟合:原因:学习到的特征数据过少
解决方法:增加数据的特征数量
过拟合:原因:学习到的特征数据过多,存在嘈杂数据,模型过于复杂
解决方法:正则化

解决:

正则化
- L2正则化/Ridge/岭回归
- 作用:可以使得其中一些w的都很小,都接近于0,削弱某个特征的影响。
- 优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
- Ridge回归
- 加入L2正则化后的损失函数:

- L1正则化/LASSO
- 作用:可以使得其中一些w的值直接为0,删除这个特征的影响。
- LASSO回归
岭回归

- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
案例:
import joblib
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def linear():
"""
岭回归对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
# estimator = Ridge(alpha=0.5, max_iter=10000)
# estimator.fit(x_train, y_train)
# 5)得出模型
print("岭回归-权重系数为:\n", estimator.coef_)
print("岭回归-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方误差为:\n", error)
return None
if __name__ == "__main__":
# 岭回归对波士顿房价进行预测
linear()
分类算法-----逻辑回归与二分类
逻辑回归:是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛。
原理:
 回归结果输入到sigmoid函数中
回归结果输入到sigmoid函数中
输出结果[0,1]

 优化损失:
优化损失:
使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是O类别的概率。

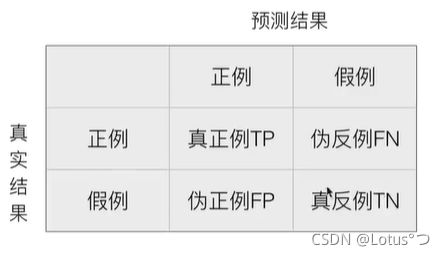
分类的评估方法
混淆矩阵:
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
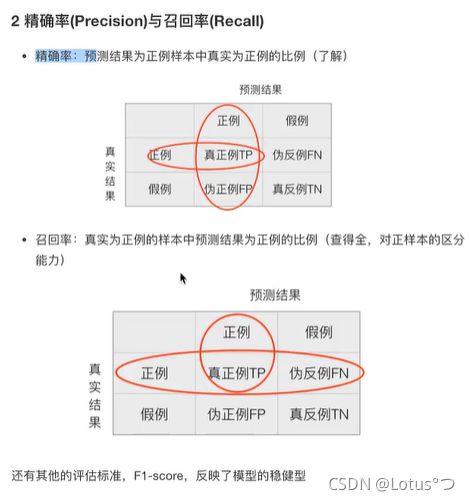
精确率和召回率:


ROC曲线:
ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是O的样本,分类器预测为1的概率是相等的,此时AUC为0.5
 AUC指标:
AUC指标:
- AUC的最小值为0.5,最大值为1,取值越高越好
- AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5
案例:
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score, classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1、读取数据
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv(path, names=column_name)
# 2、缺失值处理
# a.替换 --> np.nan
data = data.replace(to_replace="?", value=np.nan)
# b.删除缺失样本
data.dropna(inplace=True)
# data.isnull().any() # 不存在缺失值
# 3、划分数据集
# 筛选特征值和目标值
x = data.iloc[:, 1:-1]
y = data["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 4、标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 5、预估器流程
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 逻辑回归的模型参数:回归系数和偏置
estimator.coef_
# 6、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 查看精确率、召回率、F1-score
report = classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"])
print(report)
# y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
# 将y_test 转换成 0 1
y_true = np.where(y_test > 3, 1, 0)
print(roc_auc_score(y_true, y_predict))
模型保存和加载

import joblib
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def linear():
"""
岭回归对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
# estimator = Ridge(alpha=0.5, max_iter=10000)
# estimator.fit(x_train, y_train)
# 保存模型
# joblib.dump(estimator, "my_ridge.pkl")
# 加载模型
estimator = joblib.load("my_ridge.pkl")
# 5)得出模型
print("岭回归-权重系数为:\n", estimator.coef_)
print("岭回归-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方误差为:\n", error)
return None
if __name__ == "__main__":
# 岭回归对波士顿房价进行预测
linear()
无监督学习----K-means算法
无监督学习:没有目标值
K-means聚类步骤:
1、随机设置K个特征空间内的点作为初始的聚类中心·
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值).
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
K-超参数
1.看需求
2.调节超参数
API

Kmeans性能评估指标:



案例:
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score
# 1、获取数据
order_products = pd.read_csv("order_products__prior.csv")
products = pd.read_csv("products.csv")
orders = pd.read_csv("orders.csv")
aisles = pd.read_csv("aisles.csv")
# 2、合并表
# order_products__prior.csv:订单与商品信息
# 字段:order_id, product_id, add_to_cart_order, reordered
# products.csv:商品信息
# 字段:product_id, product_name, aisle_id, department_id
# orders.csv:用户的订单信息
# 字段:order_id,user_id,eval_set,order_number,….
# aisles.csv:商品所属具体物品类别
# 字段: aisle_id, aisle
# 合并aisles和products aisle和product_id
tab1 = pd.merge(aisles, products, on=["aisle_id", "aisle_id"])
tab2 = pd.merge(tab1, order_products, on=["product_id", "product_id"])
tab3 = pd.merge(tab2, orders, on=["order_id", "order_id"])
# 3、找到user_id和aisle之间的关系
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
data = table[:10000]
# 实例化一个转换器类
transfer = PCA(n_components=0.95)
# 调用fit_transform
data_new = transfer.fit_transform(data)
# 预估器流程
estimator = KMeans(n_clusters=3)
estimator.fit(data_new)
y_predict = estimator.predict(data_new)
# 模型评估-轮廓系数
silhouette_score(data_new, y_predict)