信息与通信工程学科面试——概率论
概率论复习
1.频率与概率
频率:一个事件的频数/总试验次数即为该事件的频率,其具有随机性
概率:是一个确定的值。满足非负性、规范性(即必然事件的概率为1)、可列可加性(即互不相容事件的概率等于各个事件概率和)
2.古典概型与几何概型
1、古典概型的基本事件都是有限的,概率为事件所包含的基本事件除以总基本事件个数。 2、几何概型的基本事件通常不可计数,只能通过一定的测度,像长度,面积,体积的的比值来表示。
3.全概率公式与贝叶斯公式
它们实质上是加法公式和乘法公式的综合运用。其中全概率公式是知原因求结果,并将原因分为n个分别求结果并相加。贝叶斯公式是知结果求原因,通过条件概率公式以及全概率公式推导而来。
4.独立事件
需要明确的是独立与互斥完全是不同的概念,两者毫无关系。
![]()
满足P(AB)=P(A)P(B)的事件即为独立事件。所以必然事件、不可能事件与任何事件都独立。
5.泊松分布、二项分布、0-1分布


6.分布函数以及常见的随机变量分布
常见的随机变量分布:均匀分布、指数分布(永远年轻)、高斯分布
分布函数与概率密度函数的关系:

已知X的概率密度函数和Y与X的关系,会求解Y的概率密度函数:求解步骤为:
先求Y的分布函数,将Y=g(X)代入,转换为X的分布函数。对左右求导即可得到。
拓展:二维分布函数

7.边缘分布

二维正态分布的两个边缘分布都是一维正态分布,但是边缘分布均为正态分布的随机变量,其联合分布不一定是二维正态分布。
8.条件分布

但是对于二维连续型随机变量来说,不能用以上来定义,因为此时分母为零。其分布函数定义为(联合概率密度/边缘概率密度)再积分,因此其概率密度为(联合概率密度/边缘概率密度)

9.随机变量的相互独立性
随机变量的相互独立性若用分布函数表示,即:

对上式求导
1.若变量为连续型,则表现为联合概率密度为边缘概率密度的乘积
2.若变量为离散型,则表现为联合事件的概率等于两个单事件概率的乘积
10.随机变量函数的分布
已知x和y的分布,需要会求以下分布

方法:

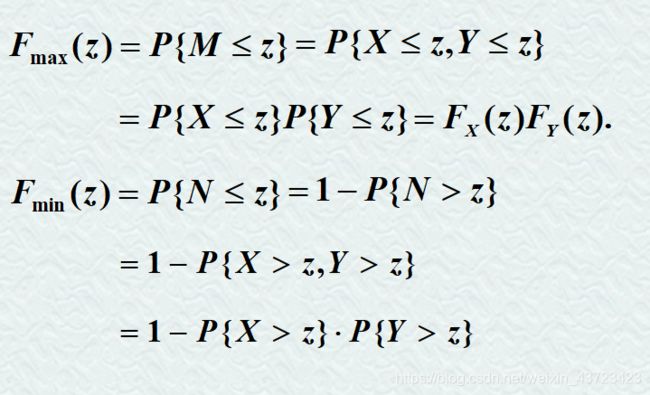
11.期望、方差、协方差
期望、方差的性质和概念:https://www.cnblogs.com/jfdwd/p/11274056.html
协方差:描述的是两个变量的相关度。为消除两个变量的度量的影响,将协方差除以根号下(x的方差*y的方差)作为相关系数。当X、Y独立时,协方差为0,相关系数也为0,反之不成立,只有X、Y为二维正态分布函数两者才等价。
12.大数定理、中心极限定理
大数定理是描述相当多次数重复实验的结果的定律。根据这个定律,样本数量越多,则其平均就越趋近期望值。
中心极限定理:大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布。
-----------------------------------------以下为数理统计部分------------------------------------------------
1.抽样的三大分布
分别为卡方分布、t分布、F分布

2.重要的几个抽样定理
当总体为正态分布时,给出几个重要的抽样分布定理.


3.参数估计以及区间估计
一、参数估计问题是利用从总体抽样得到的信息来估计总体的某些参数或者参数的某些函数.
评价一个估计量的好坏:无偏性、有效性、相合性。
1.无偏性:我们希望估计值在未知参数真值附近摆动,而它的期望值等于未知参数的真值.
2.有效性:一个参数往往有不止一个无偏估计,所以无偏估计以方差小者为好, 这就引进了有效性这一概念 .
3.相合性:随着n的无限增大,一个好的估计量与被估参数的真值之间任意接近的可能性会越来越大,这就是所谓的相合性或一致性。
寻求估计量的方法:矩估计法(理论依据为大数定理)、最大似然估计法
矩估计法:用相应的样本矩去估计总体矩的估计方法就称为矩估计法.其优点是简单易行,并不需要事先知道总体是什么分布 .缺点是,当总体类型已知时,没有 充分利用分布提供的信息 .
最大似然估计法:最大似然法明确地使用概率模型,其目标是寻找能够以较高概率产生观察数据的估计值
二、区间估计:点估计值仅仅是未知参数的一个近似值,它没有反映出这个近似值的误差范围,使用起来把握不大. 区间估计正好弥补了点估计的这个缺陷 .

求解置信区间的步骤:第一步:明确问题, 是求什么参数的置信区间?置信水平1-α是多少?第二步:寻找待估计参数θ的一个良好的点估计T (X1,X2,…Xn) 第三步:寻找一个待估参数θ和估计量T的函数 S(T,θ ),且其分布为已知. 称S(T, θ )为枢轴量. 第四步:对于给定的置信水平1-α,根据S(T,θ )的分布,确定上下限。最后做等价变形即可。
假设检验(显著性检验)
根据样本的信息检验关于总体的某个假设是否正确.
误差分为:系统误差和抽样误差。差异可能是由抽样的随机性引起的,称为抽样误差;然而,这种随机性的波动是有一定限度的,如果差异超过了这个限度,必须认为这个差异反映了事物的本质差别,即为系统误差。
那么如何判断它究竟是由于偶然性在起作用,还是生产确实不正常?
提出一个假设H0,如果H0 是对的,那么衡量差异大小的某个统计量落入区域 W(拒绝域) 是个小概率事件. 如果该统计量的实测值落入W,也就是说, H0 成立下的小概率事件发生了,那么就认为H0不可信而否定它. 否则我们就不能否定H0 (只好接受)。不否定H0并不是肯定H0一定对,而只是说差异还不够显著,还没有达到足以否定H0的程度 .所以假设检验又叫显著性检验。
会出现两类错误:第一是H0为真,但判定为假,概率为α。第二是如果H0不成立,但统计量的实测值未落入否定域,从而没有作出否定H0的结论,即接受了错误的H0,那就犯了“以假为真”的错误 .
两类错误是互相关联的, 当样本容量固定时,一类错误概率的减少导致另一类错误概率的增加. 要同时降低两类错误的概率 ,需要增加样本容量.