NVWAL: Exploiting NVRAM in Write-Ahead Logging论文阅读
问题
SQLite 作为一个使用广泛的DBMS 存在不足
How-ever logging a single database transaction in SQLite WAL mode still entails at least 16 KBytes I/O traffic to underlying storage mainly due to metadata journaling overhead in the EXT4 file system
即便是采用了WAL,记录一个数据库事务仍然需要16Kbytes的I/O流量,这主要是由于EXT4文件系统的元数据journaling开销引起的。
解决问题
NVM可以取代磁盘或利用他的字节粒度寻址性然后将每一个事务的LOG存到NVM中
这篇研究采用了后者的方法就是 NVWAL
The recent advances of byte-addressable NVRAM (Non-
Volatile RAM) open up a new opportunity to reduce the
high latency of NAND flash memory and the I/O overhead
NVRAM的一些好的性质(细粒度性的可字节寻址)可以减少IO开销,办法是 将NVRAM取代DISK 或者 将保存事务的log存到NVRAM中作为持久对象
Alternatively, in order to take advantage of the fine granularity of byte-addressable NVRAM,each log record in a transaction can be stored in NVRAM as a persistent object
这篇论文的主要工作是
- Byte-granularity differential logging (字节粒度差分logging)
- Transaction-aware memory persistency guarantee(事务感知内存持久性的保证?)
- User-level NVRAM management for WAL(用户层的NVRAM对WAL管理)
- Effect of NVRAM latency on application performance(NVRAM延迟对应用性能的影响)
具体
1.字节粒度差分LOGGING:
旧的SQ把整个B-树?操作?存进LOG再存进NVRAM
然而这样索引B树 会造成很大的IO开销
而
NVWAL只把DIRTY of b-tree
存进去这样就能利用NVRAM的可字节寻址特性 减少IO开销
2.Transaction-aware memory persistency guarantee
利用lazy synchronization 去Transaction-aware memory persistency guarantee ,这种延迟同步方法,只需要保证log-write 和 commit之间的顺序
This transaction-aware memory persistency guaranteet he persist order only between a set of log-write operations and the commit operation.It eliminates the unnecessary overhead of enforcing memory write ordering constraints
(这里的MEMORY WRITE order 是指什么 ,写到LOG吗?)
3.
User-level NVRAM management for WAL
内核级别的NVRAM堆管理会存在很大的开销(因为rollback?)因此可以通过预先分配一个大的NVRAM block给用户级来管理这样就可以省去许多的系统呼叫;
we pre-allocate a large
NVRAM block and manage the user-level heap inside the
block where we store multiple WAL frames
预先分配一个block和在存储多个WAR帧的块中管理用户级堆
4.Effect of NVRAM latency on application performance
利用NVWAL Consequetly减少 失败原子性//rollback的开销
和让事务对延迟更加不敏感
Background
NVWAL: Design and Implementation
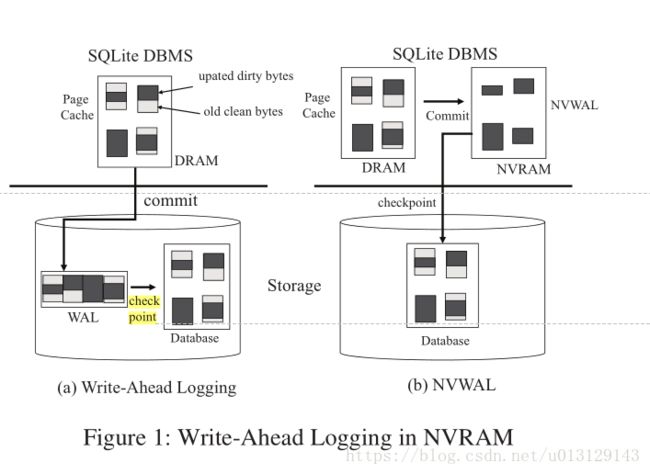
对比图1中的(a)(b)
b把WAL存储在较高性能的NVRAM中就能减少 (a)中因为要IO造成的开销
storing write-ahead
logs in high performance NVRAM can replace expensive
block I/O traffic with lightweight memory write instructions;
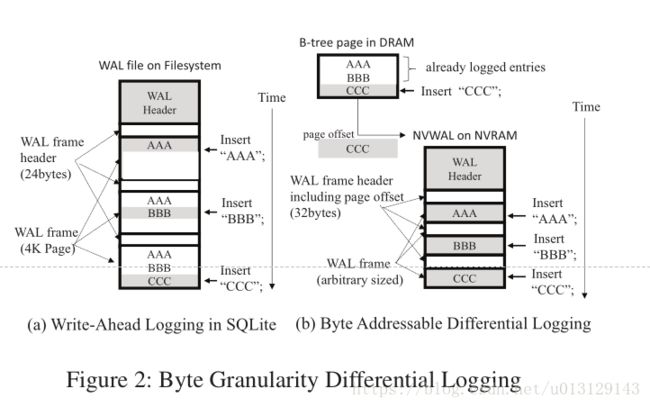
现在的SQLite无论脏数据多小,他都把整个B树存进log中(因为block device),
所以运用byte-granularity differential logging
As illustrated in Figure 2(b), the NVWAL structure con-
sists of an NVWAL header and pairs of a 32 bytes WAL
frame header and arbitrary-sized WAL frames (log entries)
created by differential logging.
The NVWAL header(metadata,指向下一个有可用空间的WAL frame)
contains database file metadata as in the legacy SQLite WAL
header and a pointer to the available space for the next WAL
frame to be stored (next_frame).
Each WAL frame header(commit,checkpoint id,dabtabase page,etc)
consists of a commit flag, a checkpointing id number, a
database page number, an in-page offset, a frame size, and
checksum bytes for the WAL frame.
For each WAL frame,(标识有Btree 的脏page)
we identify which portion of the B-tree page is dirty and
truncate the preceding and trailing clean regions so that only
the dirty portions of the B-tree page are flushed to NVRAM,
as shown in Figure 2
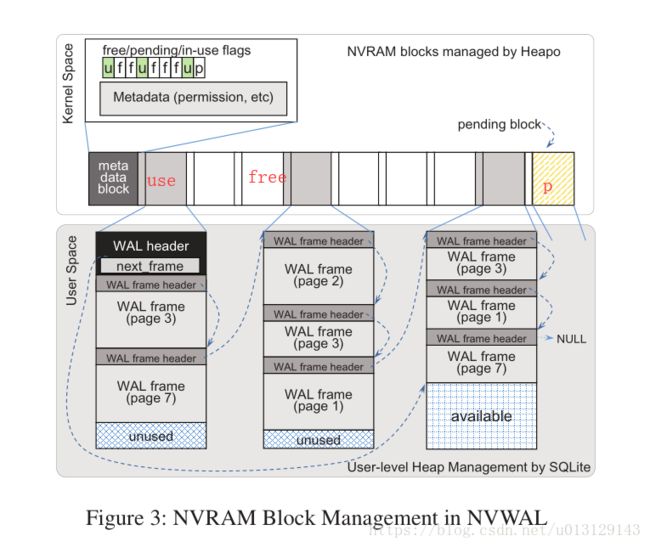
User-Level NVRAM Heap Management
每个NVRAM块有三个状态 free (未分配NVRAM内存) , in-use(存有WAL) , pending(以分配未使用)
nv_pre_malloc() allocates a set of NVRAM pages that
occupy a consecutive address space, maps them to a frac-
tion of the virtual address space of a process, and sets
the status of the block to pending
分配连续的空间给一个NVRAM pages并映射到虚拟地址,设置这个block状态为pending
nv_malloc_set_used_flag() to change its status from pending to in-use.
当一个WAL中的header连接到一个pending BLOCK时就改变这个BLOCK的状态
就跟链表原理一样
If the system crashes while an NVRAM
block is still in pending status, the SQLite NVWAL recovery
process can safely deallocate the block
当系统出现故障,Pendding 就被回收,这就很好的管理了!

这个算法的思想很简单
就是脏页产生了,我就去通过UESER SPACE存到NVRAM
作者的解释:
If page p’s WAL frame is not
in the log, the entire page p and its WAL frame header are
copied to the available space of the last NVRAM block in
the linked list if they fit. If the available space in the last
NVRAM block is not large enough to hold them, we allo-
cate another NVRAM block from Heapo, add the block to
the linked list of NVRAM blocks, set the status of the block
to in-use, and store the dirty WAL frame and its header in
the newly allocated NVRAM block. If page p’s WAL frames
are found in the log, the differences between the page and
the WAL frame are computed to construct a small WAL
frame, as described in section 3.2; the small differential log
entry is stored as a WAL frame in the NVRAM log
看这个P在不在LOG中,如果不在就创建新的,如果在,就对比,小的存进去(为什么不是时间新的存进去?)
我的理解
他给的算法并没有一些对比的算法,只是简单的将这个P存到USERSAPCE 再存到NVRAM中
我理解的关键的代码:
pagePtr p; 就是产生的脏页(是不是就是BTree?)
compute_wal_frame() 如之前所说的,去除BTree的头尾,只保留dirty data
wh.add_new_block(block) block整个就是可用空间,所以WH(WAL Header)指向他
dmb() 我猜就是等待CACHE 读写的系统调用? 必须等他完成了才能继续进行读写操作
第一个dmb() 等待把用户修改的数据全部结束到CACHE
cache_line_flush() 就是 INSER “AAA”?
dmb() 等待这个 cache写到别的地方完成
persist_barrier() 按顺序写吗???
next_nv_frame = wh.next_frame; 指向可用空间,就是刚弄好的那个block中的可用WAL FRAME
nvFramePtrList.add(next_nv_frame) //最后一个wal frame的header指向他 (链表)
p = p.next 指针移动
end ------- 我理解就是 end上面的操作就是把用户修改的数据从cache 存到 userspace (图)
end 下面就是把 userspace存到NVRAM
dmb()
while f do ----就把每个wal frame 存到 NVRAM
dmb()
然后就是判断 需不需要保存到database了
看到后面有解释这些内存栅栏的作用,就是跟我上面想的差不多,就是为了等待cache读写内存完成.(因为读写是并行且随机的)
There are a few implementation specific issues that de-
serve further elaboration. We implemented NVWAL in
ARM based platform. The cache line flush instruction
in an ARM, dccmvac, is non-blocking. In order to en-
sure that the memory operations that mark the commit
flag (line 30–34) are not reordered with the following
cache_line_flush(), the cache line flush instruction
should be preceded by the data memory barrier, dmb. The
dmb instruction completes only when any previous explicit
memory access instructions are all completed. The dmb() in
line 22 ensures that all WAL frames are written at least to
the L1 or L2 cache. In the proposed lazy synchronization,
a batch of non-blocking dccmvac instructions are called in
line 23–26 in order to flush the cache lines. The dmb() in
line 27 is also needed in order to block until the preced-
ing cache_line_flush() flushes all the WAL frames to
NVRAM. dmb() in line 32 also ensures that the memory
operation that marks the commit flag is not reordered with
cache_line_flush()
Transaction-Aware Memory Persistency
Guarantee

WAL的恢复算法是基于事务顺序存在LOG的,但是 内存的读写是随机的
(persist barrier是什么???)
In order to guarantee that memory write
operations flush data all the way down to NVRAM, cache
line flush operations such as clflush should accompany
persist barrier instructions such as Intel’s PCOMMIT, as
shown in Figure 4(b). Persist barrier ensures that the
cache lines queued in the memory subsystem are persisted
in NVRAM. Otherwise, a commit mark can be written to
NVRAM before log entries are stored
为了保证内存的写操作都能写到nvram所以clflush必须后面跟persist barrier.
persist barrier保障了cache lines在NVRAM的持久性
commit mark能在 log 存储前写进NVRAM

作者通过WAL 和 transaction-aware memory persistency guarantee scheme来实现顺序性和持久性
具体的细节:
log-commit的两个操作
1.将一系列的log写进NVRAM
2.将COMMIT 标记写进NVRAM
只在两个之间调用CLFLUSH,SFENCE ,PERSIST BARRIER
log的写不需要保证顺序但是commit必须在写完所有wal frame之后执行
SQLite不允许多个写指令并发进行所以一个写操作需要一个单独的锁(就像临界资源 单访问)
NVWAL能允许处理器以任何顺序去把WAL FRAME FLUSH到NVRAM 因为NVWAL把copy log to nvram 和 同步log到nvram的操作分开了正如算法1 end上是copy 下是同步
这上面的 细节 就是 FIGURE4 中的©
There are a few implementation specific issues that de-
serve further elaboration. We implemented NVWAL in
ARM based platform. The cache line flush instruction
in an ARM, dccmvac, is non-blocking. In order to en-
sure that the memory operations that mark the commit
flag (line 30–34) are not reordered with the following
cache_line_flush(), the cache line flush instruction
should be preceded by the data memory barrier, dmb. The
dmb instruction completes only when any previous explicit
memory access instructions are all completed. The dmb() in
line 22 ensures that all WAL frames are written at least to
the L1 or L2 cache. In the proposed lazy synchronization,
a batch of non-blocking dccmvac instructions are called in
line 23–26 in order to flush the cache lines. The dmb() in
line 27 is also needed in order to block until the preced-
ing cache_line_flush() flushes all the WAL frames to
NVRAM. dmb() in line 32 also ensures that the memory
operation that marks the commit flag is not reordered with
cache_line_flush().
这一段是对算法1中 一些 dmb()的解释,跟我想的差不多
加粗的两句 就是说当所有访问内存的指令完成了才能执行dmb后面的指令
The commit mark resides at the WAL frame header and
is one bit long. As in a prior work [10], we assume that
NVRAM devices guarantee atomic writes for 8 bytes. This
means that even if a random power failure occurs, capacitors
in DIMM guarantee no corruption of 8 bytes. Because the
commit mark is just a bit flag, the commit mark can be safely
flushed to NVRAM with 8 bytes padding. If atomic writes
can be done in the unit of a cache line, as in [35], cache
line padding is necessary to prevent cache_line_flush()
from flushing an unintended memory region
大概就是说
commit mark是一个字节长
我们以八个字节原子地写入NVRAM
即使发生电源故障,DIMM这个东西也会保证不会八个字节全损坏
所以就能保证了commit的安全
如果atomic 写可以在cache line中完成,如[35]所示,则cache line填充是必要的,以防止cache_line_flush() flush意外的内存区域
(所以pendding就是让这个chche line刚好一次被flush完吗?)
然后作者提出了一个Asynchronous Commit 就是FIGURE4(D)
compromising the consistency using checksum bytes
因为有checksum bytes 所以可以即使异步也能保证consistency
具体就是
1.commit 和check sum一起写
NVRAM
2.一系列的log一起写
进NVRAM
这两个可以异步进行
但是当故障发生在 1之后,2之前,导致checksum能匹配到一个根本不是原来的log所以这个异步有问题,但是他的性能很快作者用它来作为性能比较
Checkpointing and Crash Recovery
这里是对为什么算法1这么牛逼的解释
首先NVRAM 有个周期性的checkpoint 让他存进database(就是存到硬盘中)
In NVWAL, we reconstruct the
dirty pages by combining the log entries in the NVWAL
log and the respective original database pages
结合nvwal的Log 和各自的数据库页重构了dirty pages
重构的细节没有给出
Heapo’s nvfree() system call 这个是什么作用
然后说了故障出现从log中恢复的做法:
(就是根据log重新执行一遍)
nvwal的算法和SQL的差不多,只不过nvwal的DIRTY PAGE是字节可寻址的
NVWAL是一个即将实现的模型,现在唯一很难去验证的
Without a persist barrier, we are un-
able to perform a physical power-off test for NVWAL be-
cause clflush and the emulated persist barrier do not
guarantee the failure atomicity
大概意思关机测试难以执行 因为clflush和persistbarrier 不保证原子性 就是冲洗cache不会记录进行到什么进度
就是说dumb()persist_barier等待过程发生了 故障,没办法解决!!
然后就是解释他牛逼的算法怎么应对故障发生!!
If a system fails while allocating an NVRAM block (line 6
of Algorithm 1), the allocated NVRAM block is marked
as pending, but SQLite may not have written its refer-
ence in another persistent NVRAM block. When the sys-
tem recovers, the heap manager can reclaim any pending
NVRAM blocks to prevent a memory leak
在分配nvram block失败的时候这个block就是pendding那么系统恢复了heapo就可以回收这个状态为pendding的块
If a system crashes after an NVRAM reference was stored
in the WAL header but before the block was marked as in-
use, the SQLite recovery process will find that the block
was freed by the NVRAM heap manager’s recovery pro-
cess and the block’s reference can be safely deleted.
我分配好了那个block同时wal header也连接上去了但是故障发生了,那这个连接上的block就是free状态,所以没问题
算法中就是6,7行执行完了 13之前出问题
If system crashes while copying a dirty WAL frame
to NVRAM using memcpy() (line 22 of Algorithm 1),
SQLite can easily recover from the failure because the
frame’s transaction has not written a commit mark, thus
the transaction is considered to have been aborted. In
database transactions, writing a commit mark is the last
operation of the transaction commit process
把dirty wal拷贝到NVRAM发生了错误也没关系,因为我还没提交所以nvwal还有纪录再做就是了
Recovery from checkpointing process’ failure is also triv-
ial and not different from legacy checkpointing recovery.
Because the write-ahead logs will not be deleted before all
the dirty pages are persistently stored in the database file,
the SQLite recovery process can simply replay the check-
pointing process to recover from the failure
checkpoint过程发生错误也没关系,因为还没写完到磁盘data base就不会清空nvram(不执行完整不清空)
接下来就是说
memory persistency分成strict persistency 和relaxed persistency
算法1就是strict persistency
严格的持久性可能显著限制持久性能,因为它在持久操作之间强制执行严格的排序约束
relaxed persistency decouples the memory consistency and persistency models
但是A major disadvantage of relaxed persistency is the increased programming complexity
作者虽然运用了strict persistency 但是他们更喜欢 relaxed persistency 因为他能动态的执行when copying the WAL frames from DRAM to NVRAM,他们将要做下一步工作就是改算法成relaxed了