代码量锐减 80%,一次祖传代码重构实践

导读
此前,团队接管并重构了十多年前的搜索链路中的 Query 理解祖传代码,代码量减少80%,性能、稳定性、可观测性都得到大幅度提升,且支持自研云和业务机房双环境部署。本文将分享重构过程中碰到的代码坏味道,并分析这样写的动机、预防和拯救措施。
目录
1 背景
2 重复的代码
3 过长函数
4 臃肿的类
5 过长的参数列表
6 令人迷惑的临时字段
7 传入参数范围过大
8 不必要的串行
9 被忽略的编译 warning
10 魔法数字和常量
11 过长的 if
12 总结
有一次,我和我妈一起打扫房间,我问我妈:什么时候书房变成了杂物间,堆满了垃圾?
我妈说:我有一次懒得扔纸箱,就把纸箱扔到了书房,然后慢慢就这样了。
我尴尬的笑了笑:那你为什么不定期打扫?扔掉那些你不用的东西?
我妈:前面一直将就着,就等你放假了一起打扫。
我:
代码也是如此,十一年的老代码,从某次懒得扔垃圾开始,坏味道便逐渐开始充斥着整个项目。
经过三个月大扫除,我和小伙伴重构了这个迭代十一年的老模块。重构的过程,不仅是对坏味道的清除,对老模块的重新设计,也是一场与十一年前老同事跨越时空的对话。本文将分享重构过程中碰到的代码坏味道,以第一人称分析当初这样写的动机及对应的预防和拯救措施。
01
背景
1.1 接手
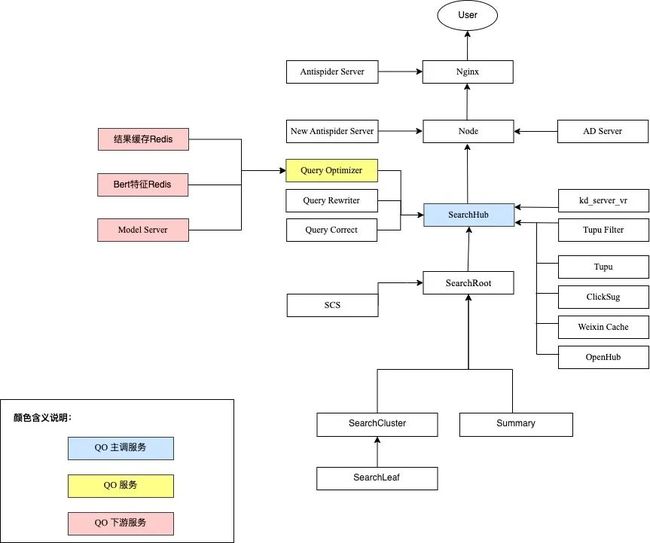
在一次组织架构调整后,我们组接手了链路搜索的几个底层基础模块—— QU(Query 理解)相关的三个模块,其中包括本次重构对象 Query Optimizer ,负责根据用户在搜索系统中输入的 Query(查询语句)产出切词、词权、紧密度、意图识别结果。QO 在搜索链路中的上下游关系如下图所示:
1.2 为什么重构
面对一份10年陈的祖传代码,我们选择重构的原因主要如下:
迭代效率低:新增一个简单的算子需要 3 人天,效率低下。
稳定性较差:不定期出现 P99 毛刺。
启动速度慢:服务启动需要 18 分钟。
内存浪费多:单进程需 114 G 内存。
排查工具少:缺少多项监控和 trace 跟踪能力。
GCC 老旧 :使用 GCC 4.8,无法使用现代 C++。
无法部署到自研云:无法和腾讯域下的类似能力做合并。
基于上述原因,也缘于我们热爱挑战、勇于折腾,我们决定在项目完全接手后启动重构计划。
后面的内容将分享老代码中的坏味道,当初这样写的动机、对应的预防和拯救措施及优化之后的效果。
02
重复的代码
2.1 示例
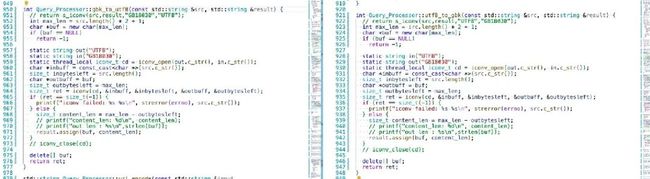
下面代码为 gbk 与 utf8 格式的互相转换函数。两个函数之间除了变量输入顺序不一样,其他都是一样的。
2.2 动机
我懒得提取公共代码。CV 大法最简单,最快速。
2.3 预防和拯救措施
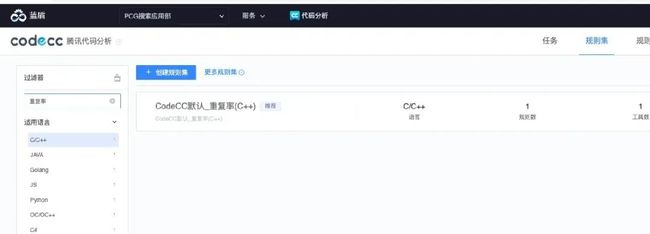
CodeCC 能扫描出部分重复代码。
代码编写过程中,优先复用已有的代码。
提升单测覆盖率要求。越多的重复代码意味着,我需要写越多的单测,逼迫自己去使用已有工具。
当两个层次相同的类存在相同的方法时,就把方法提出出来,上移到一个上层的类或者独立的方法。比如上面的编码函数在不同的类中都存在,最后我们将该方法提取出来了,并复用了可以共用的部分。
2.4 优化之后

03
过长函数
3.1 示例
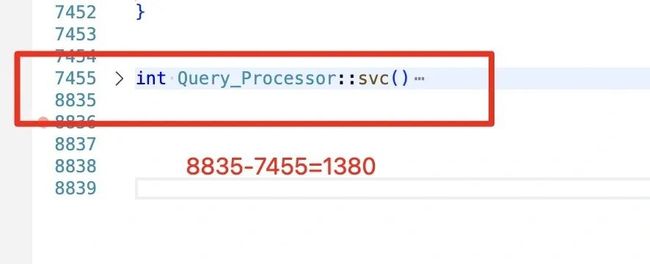
你见过 1380 行代码的函数吗?我见过虽然其中 300 行是被注释掉了,100行是注释。
3.2 动机
我不想删代码,所以注释代码。为什么不想删代码,因为还想着后面还要用。事实证明,后面没有再用。
多写点注释,后面的人就能看懂。
当一个函数代码行数越来越多的时候,我不愿意去承担重构的风险。如果要新加一个功能,在主流程加上我的逻辑是最保险的。如果我要去改动别人的代码,即使只是提取出来作为一个函数,我需要承担更多的风险。
3.3 预防和拯救措施
如果代码未来还会有用,建议加上开关,而不是注释。又或者可以先删除,未来需要使用时,通过 git 记录找回来。
如果需要写很多注释来表明某个逻辑,可以提出该段逻辑为一个独立的函数。
项目框架搭建过程中,想清楚每个接口的职责,不要让某个接口大包大揽,最后成为垃圾场。
使用 CodeCC 规则进行检查。

3.4 优化之后

04
臃肿的类
4.1 示例
作为一个负责请求处理的类,不仅包括 HTTP 服务实例、缓存实例,还需要执行几十个具体的策略逻辑,实在是有点不堪重负。当我阅读完这个类的代码,我觉得我读完了一本书,要睡着了。
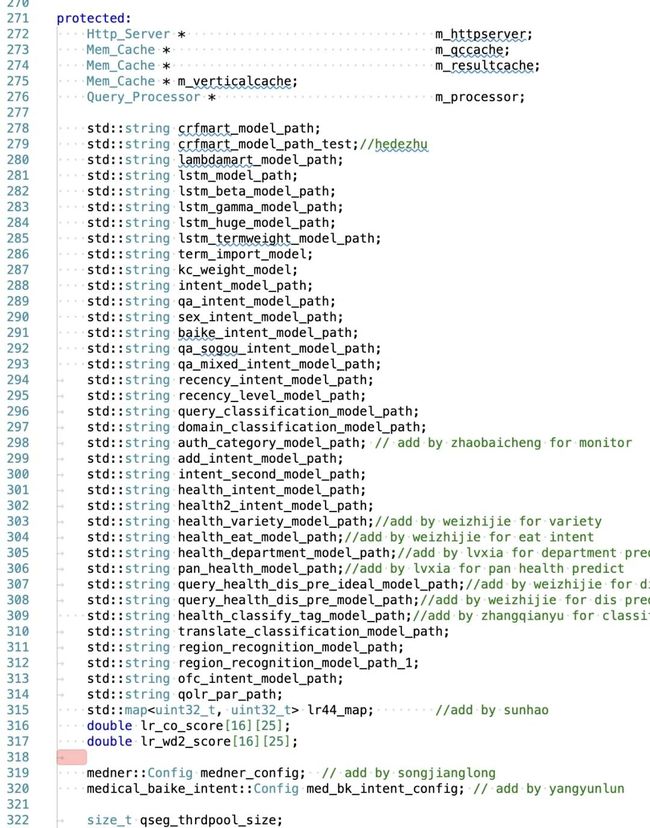
4.2 动机
最开始,仅仅有一个策略逻辑。这个逻辑放在请求处理类中时,我觉得理所应当。然而,后面的策略同学觉得和我的逻辑应该差不多,直接 CV。
我们有时候赋予一个类太大的职责范围了,以至于我们后面无论想到啥,似乎都符合我们给这个类的人设,理所当然的把逻辑加进去。
4.3 预防和拯救措施
每个类应该在注释中说明该类职责。当类中实例过多时,应当想办法拆解,把一部分职责委托为其他类。
仔细思考是否可以提取出一个新的类,比如,将数个彼此相关的变量提取到一个新的类,放到一起。
4.4 优化之后

05
过长参数列表
5.1 示例
一个方法56个参数,我真怕自己传错参数了。
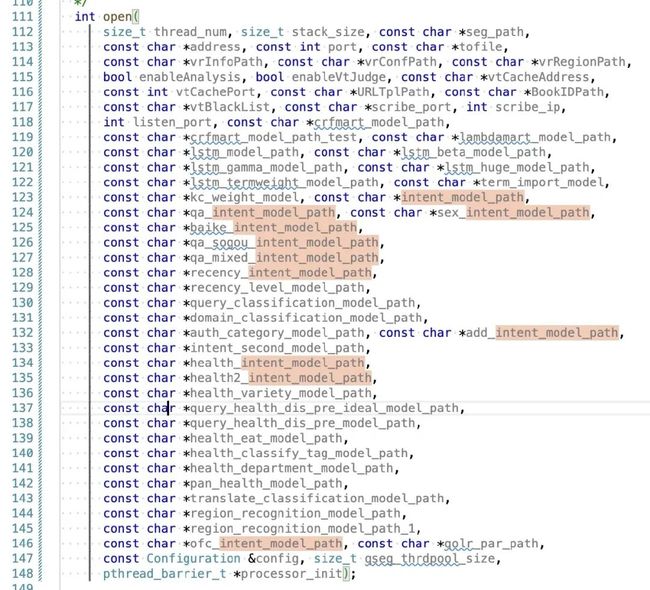
5.2 动机
其实我本可以将参数放在 config 里面,但是为了保险,别人怎么做,我就怎么做。当有一个坏的开始,后面就会有人不断重复这个错误的示范。反正没有代码 CR,只要能 RUN 就行。
5.3 预防和拯救措施
编码过程中关注参数列表的长度。
关注单测增量覆盖率,让 CV 付出代价。毕竟在单测中,你需要填充这个过长的参数列表,如果你自己都受不了,那别人也会受不了。
传递对象,让方法从对象中获取它需要的参数。
5.4 优化之后

06
令人迷惑的临时字段
6.1 示例
下面的代码表示:如果 HaveSecond 为 true 的时候,i 及 i+1个单词的weight*100/2。给你十分钟,你能明白这个含义吗?为什么看不懂?因为 is_second 这个变量的含义很绕。
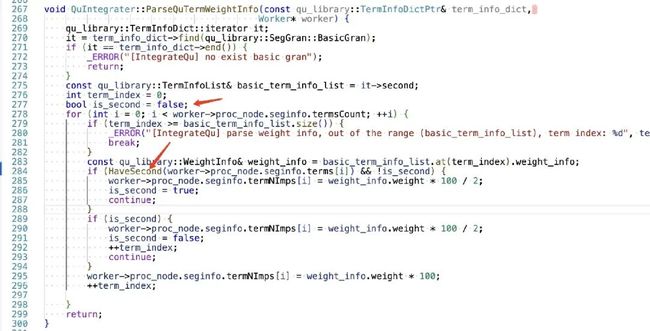
6.2 动机
在循环中,如果需要在特定条件下,对 i 及 i+1 个元素进行操作,我担心会溢出。所以,我把该操作分为多步,并用一个临时变量表明接下来需要进行操作。
6.3 预防和拯救措施
注意代码可读性,每个变量需要有它特定的含义。同时,注意最少代码原则,思考清楚,这个变量真的是需要的吗?
如果两个逻辑需要通过一个变量来进行连接,那为什么不直接把这两个逻辑合在一起,消除这个变量。
6.4 优化之后
07
传入参数范围过大
7.1 示例
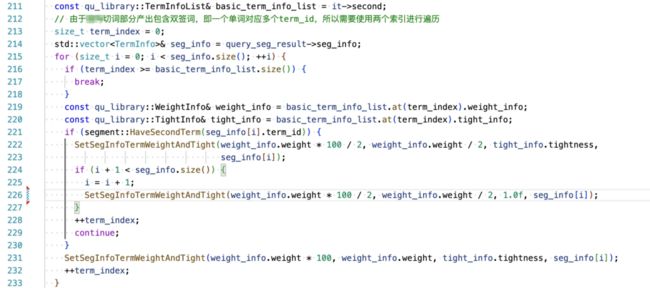
worker 是整个服务输出结果的存储对象,其中 proc_node 存储了所有算子的中间输出结果。然而 worker 指针和 proc_node 指针被传递到了多个函数。这些函数真的需要这么多的信息?



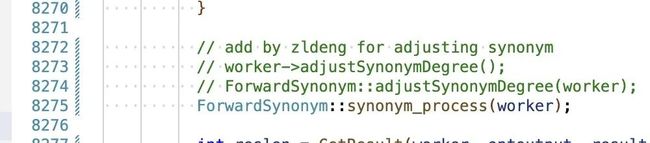
7.2 动机
我懒得去思考不同接口的数据依赖。于是将所有数据塞到同一个结构体,要用什么直接拿,要写入什么信息,直接写入。反正都是串行执行,不存在多线程问题。
7.3 预防和拯救措施
遵循最少知识原则,只给该接口它所需要的数据。
7.4 优化之后

08
不必要的串行
8.1 示例
如下代码要进行两次切词,一次带标点符号的切词,一次为去除标点符号的切词。两者其实可以并行。
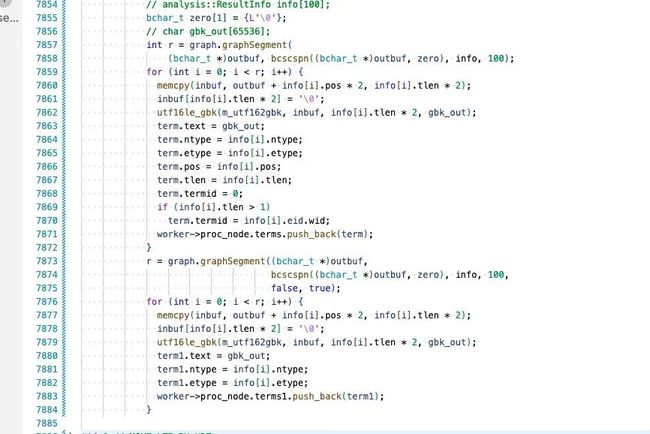
8.2 动机
反正已经有请求级别的并行了,任务处理级别的并行意义不大。
万一有多线程安全问题,等于给自己挖坑。
8.3 预防和拯救措施
多关注性能。CR 过程中对于主流程添加的逻辑,审视可能带来的耗时增加。上线灰度时,留心监控中被调耗时和内存利用率。
如果请求处理过程中,存在多个可以并行的任务,建议使用 DAG 进行任务注册和任务运行。
8.4 优化之后
基于 DAG 进行调度,多个子任务之间并行处理。最终主流程从 13.19 ms 优化到 9.71 ms,优化 26%。
09
被忽视的编译 warning
9.1 示例
下面代码没有 return,升级 gcc 后(gcc4.8.5->8.3.1),调用函数访问到了异常值,coredump 了。

下面代码 sprintf 写入 char 数组的时候,没有给\0保留位置,最终栈空间因为越界被写坏,函数局部变量值都变成异常值,导致后面的数组访问到随机内存空间。

9.2 动机
warning,不是 error,能编译通过,我觉得问题不大,有点 warning 很正常。
目前代码能正确运行,我也不想动。
编译过程中输出太多信息了,我不可能去看每一条输出信息。
9.3 预防和拯救措施
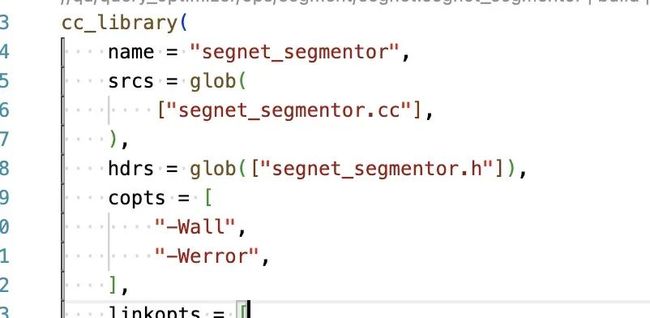
编译时打开 -Wall -Werror 编译选项,将 warning 变成 error,中断编译,让 warning 得到足够重视。
9.4 优化之后
10
魔法数字和常量
10.1 示例
谁来告诉我 ‘43000’ ‘4300’是什么?
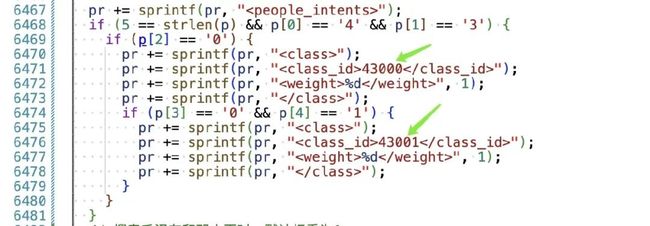
10.2 动机
针对 badcase 进行特殊处理,我懒得写注释了,也不想花时间定义常量。
10.3 预防和拯救措施
针对常量,遵循代码规范,使用常量定义,并添加注释。
10.4 优化之后
下面常量定义已脱敏,不代表真实含义。

11
过长的 if
11.1 示例
下面这个判断执行了100多次。

11.2 动机
经验比较少,不了解用查表进行优化。
11.3 预防和拯救措施
针对很长的判断,尽量使用查表替代判断。
11.4 优化之后

12
总结
重构中碰到的部分代码坏味道分享到此为止。体验了这次大扫除的辛苦,我发誓,我以后再也不偷懒了,多动脑、少 CV、少走捷径,手动狗头。
-End-
原创作者|龙鑫

你还有什么预防坏代码的措施?欢迎分享。我们将选取1则最有意义的评论,送出腾讯云开发者-鼠标垫1个(见下图)。10月16日中午12点开奖。

欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边等你来~

(长按图片立即扫码)



