SpringCloud 完整版--(Spring Cloud Netflix 体系)
目录
- SpringCloud
- Spring Cloud Netflix 体系
- 分布式概念:
-
- 分析图
-
- 单体应用
- 分布式架构
- 集群
- 微服务
- 分布式+微服务+集群
- 服务注册与发现Eureka
-
- 作用:
-
- 为什么使用Eureka?
-
- 解答:
- 分析图
- 搭建:
-
- 1、注册中心Eureka-server搭建
-
- 创建项目
- 配置 yml
- 访问
- 2、product-server 服务的搭建
-
- 配置yml
- 启动服务
- Eureka自我保护机制
-
- 解析
- 分析图
- 关闭自我保护机制测试
- 开启自我保护机制测试
-
- 问题
- 完善product-server 服务的搭建
-
- 3、product-api
-
- 创建项目
- Product类
- product-server
-
- 假数据
- service层
- controller
- 微服务调用方式Ribbon
-
- 远程调用
-
- 4、order-server 服务的搭建
-
- 创建项目
- 5、order-api
-
- 创建项目
- 配置依赖
- Order类
- service层
- controller层
- 配置yml
- 访问注册中心
- 访问订单服务
- order-server远程调用product-server
-
- RestTemplate
- 远程调用成功
- 远程调用+负载均衡
-
-
- 负载均衡效果
- Ribbon调用的原理
- 修改Ribbon负载均衡策略
- 总结
-
- 微服务调用方式Feign
-
-
-
- product-api配置依赖
- feign接口
- feign接口实现类
- Feign远程调用分析图
- 总体调用流程
- Feign远程调用原理分析
-
- Feign参数设置
-
- 默认超时时间
-
- 示例
- 结果
- 调整默认时间
- 超时重试次数设置
-
- 分析图
- feign远程调用重试次数修改
- 问题
-
- 服务熔断与降级Hystrix
-
-
- 集成Hystrix
-
- 依赖
- 启动类
- 代码
-
- Hystrix开关
- 降级没生效
-
- 解决:
- 不明白Hystrix开关地方
- Feign集成Hystrix流程梳理
-
- 降级代码流程梳理
- 配置梳理
- 异常报警通知
-
- 开启redis
- redis依赖
- yml配置redis
- 代码
- 分析图
- Hystrix超时时间设置
-
- yml配置
- 需求分析图
- 处理分析图
- 集成Dashboard
-
- 作用:
- 配置依赖
- 启动类
- 配置yml
- 访问路径
- 问题bug
-
- 微服务网关Zuul
-
- 1、作用和使用
- 搭建
-
- 创建项目
- yml配置
- 启动类
- 访问失败
- 解决方法
- 2、Zuul 网关的配置
-
- 自定义Zuul的路由规则
- Zuul网关的cookie被过滤问题
-
- 问题
- 原因
- 解决
- 3、Zuul网关自定义filter过滤器实现登录鉴权
-
- 分析图
- 鉴权代码
- 访问测试
-
- 访问product服务
- 访问order服务
- 链路追踪组件Sleuth&Zipkin(日志)
-
- 整合Sleuth
-
- 普通日志打印
-
- 问题:
- 整合Sleuth日志打印
-
- 添加依赖
- 搭配 zipkin 使用
-
- 添加依赖和配置
- 启动jar包
- 访问成功
- 分布式配置中心Config
-
- config配置中心分析
- 搭建config-server
-
- 启动类和yml配置
- 建立gitee
- yml配置
- 访问config服务
- 服务去配置中心拉取配置
-
- 依赖和配置
- 启动看结果
SpringCloud
Spring Cloud 是一套分布式微服务的技术解决方案,它提供了快速构建分布式系统的常用的一些组件,比如说配置管理、服务的注册与发现、服务调用的负载均衡、资源隔离、熔断降级等等 。
不过 Spring Cloud 只是 Spring官方提供的一套微服务标准定义,而真正的实现,目前有两套体系用的比较多:
一个是 Spring Cloud Netflix
一个是 Spring Cloud Alibaba
Spring Cloud Netflix 是基于 Netflix 这个公司的开源组件集成的一套微服务解决方案,
其中的组件有
1、Ribbon—— 负 载 均 衡
2、Hystrix——服务熔断
3、Zuul——网关
4、Eureka——服务注册与发现
5、Feign——服务调用
Spring Cloud Alibaba 是基于阿里巴巴开源组件集成的一套微服务解决方案,
其中包括
1、Dubbo——消息通讯
2、Nacos——服务注册与发现
3、Seata——事务隔离
4、Sentinel——熔断降级
有了 Spring Cloud 这样的技术生态,使得我们在落地微服务架构时,不用去考虑第三方技术集成带来额外成本,只要通过配置组件来完成架构下的技术问题,从而可以让我们更加侧重性能方面
Spring Cloud Netflix 体系
分布式概念:
分布式是从部署的角度去讲的,我们的项目可能会有redis,mysql,tomcat、mq等很多技术,这些东西分别部署在多台服务器当中,那么这个架构就可以称之为分布式的架构。
分析图
单体应用
所有服务都部署在同一个服务器里面

分布式架构
每个技术分别部署在不同的服务器里面

集群
这个结构依然属于分布式架构,因为项目同样分布在多台服务器当中
使用较多的那个服务,多搞几台服务器来部署叫做集群,分担tomcat的压力
后面可以用nginx来分配哪些请求分给哪个服务器的服务来处理
后面的mysql也要做集群的,因为如果访问量大的话,tomcat做集群虽然压力分摊了,但是最终还是要访问到这个mysql,如果mysql不做集群,那么访问也会堵在mysql这边。
后面可以弄一些Mysql的主从操作
相当于原本一条公里,车辆行驶过多,然后开辟多条公路,但是所有的公路只有一个收费站的话,车辆还是全部都会被堵在收费站这里

问题:
比如现在是一个电商业务,此时的所有服务(会员服务、订单服务、商品服务)都是放在一起的,如果其中一个服务出现bug,那么后续的流程就都走不通了。
微服务
就是要把业务细细拆分开来,做到某一个业务出现问题,而不耽误到整个流程的执行。

分布式+微服务+集群
分布式:多种技术分别部署在不同的服务器上面
微服务:把业务拆分为多个服务,把这些服务分别部署在不同的服务器上
集群:访问量多的服务,可以单独给这个服务多配置几台服务器,减轻访问压力


服务注册与发现Eureka
SpringCloud Euraka是SpringCloud集合中一个组件,它是对Euraka的集成,用于服务注册和发现。Eureka是Netflix中的一个开源框架。它和 zookeeper、Consul一样,都是用于服务注册管理的.
作用:
为什么使用Eureka?
比如【订单服务】需要远程调用到【商品服务】,在远程调用的过程中,【商品服务】挂了,但是【订单服务】并不知道,所以还是一直去调用这个【商品服务】。
解答:
所以这个时候就用到了注册中心。
每个服务在启动的时候把自己的信息注册到【注册中心】里面,然后每个服务都会每隔30s发送一次自己的信息到注册中心,并且把注册中心中存放各个服务信息的信息列表拉取到自己服务本地,如果有的服务连续三次没有给注册中心发送心跳包,注册中心就会把该服务的节点信息从消息列表里面剔除掉。这样的话,每个服务就能通过拉取到本地的消息列表,知道要调用的那个服务是否还存在。
而已经挂了的服务比如【商品服务】,因为连续三次没有给注册中心发送心跳包后,信息已经被消息中心从消息列表里面剔除掉了,那么【订单服务】拉取到本地的消息列表里面就没有这个【商品服务】的消息,那么也就不会继续访问这个服务了。
分析图

1、在启动服务的时候把自己的信息注册到注册中心里面
2、把注册中心的服务列表拉取到本地(就是订单服务等)
3、服务和注册中心之间有一个心跳机制,每隔30s会给注册中心发送一个心跳包(服务的ip地址)确保还活着,并且会重新到注册中心拉取一份最新的服务列表到本地
4、如果有的服务连续三次没有给注册中心发送心跳包,注册中心就会把该服务的节点信息剔除掉
搭建:
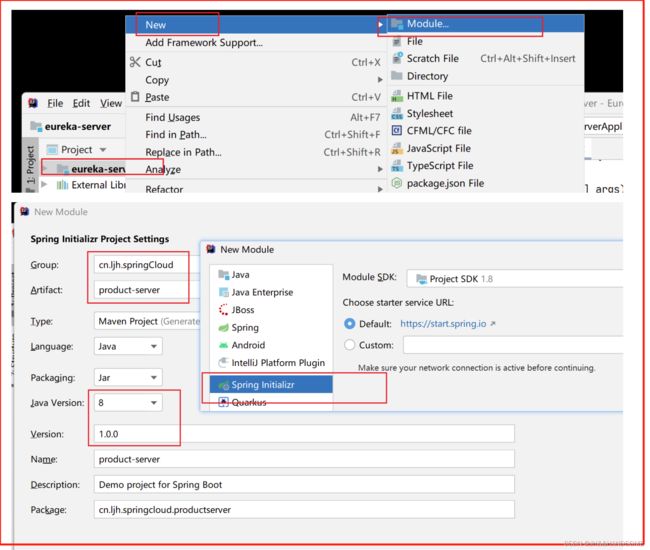
1、注册中心Eureka-server搭建
创建项目
选择boot项目

选择依赖


配置 yml
配置 application.yml

配置解析

启动类贴注解开启注册中心

访问
localhost:8761 启动成功

2、product-server 服务的搭建


配置yml

启动服务

Eureka自我保护机制
解析
Eureka Server 在运行期间会去统计心跳失败比例在 15 分钟之内是否低于 85%,如果低于 85%,Eureka Server 会将这些实例保护起来,让这些实例不会过期,但是在保护期内如果服务刚好这个服务提供者非正常下线了,此时服务消费者就会拿到一个无效的服务实例,此时会调用失败,对于这个问题需要服务消费者端要有一些容错机制,如重试,断路器等。
我们在单机测试的时候很容易满足心跳失败比例在 15 分钟之内低于 85%,这个时候就会触发 Eureka 的保护机制,一旦开启了保护机制,则服务注册中心维护的服务实例就不是那么准确了,此时我们可以使用eureka.server.enable-self-preservation=false来关闭保护机制,这样可以确保注册中心中不可用的实例被及时的剔除(不推荐)
分析图

关闭自我保护机制测试

8090和8091同时去访问注册中心

把8091停掉后,过了90秒

开启自我保护机制测试

问题
开启自我保护机制后,关掉8091,按理说8091服务的信息应该还是在注册中心,但是不清楚为什么这边刚把8091听到,注册中心重新刷新就没有了8091的信息了

完善product-server 服务的搭建
3、product-api
创建项目
因为订单服务和商品服务都需要用到商品对象,所以我们可以创建一个product-api 模块来存放一些被共同用到的类

Product类
创建商品对象Product

product-server
Product-server服务想要用到这个Product对象,那么就需要把这个product-api以jar包的形式映入到该服务里面。

假数据
先了解架构问题,所以弄点假数据就可以了,先不用操作数据库

service层

controller

访问
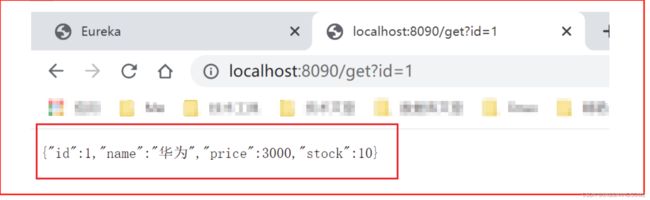
微服务调用方式Ribbon
远程调用
Ribbon 负载均衡组件,也叫远程调用组件
4、order-server 服务的搭建
创建项目
创建boot项目

5、order-api
创建项目
创建maven项目

配置依赖

Order类

order-server服务把order-api引进来,这样这个order-server服务才能用到order-api里面的对象

service层

controller层
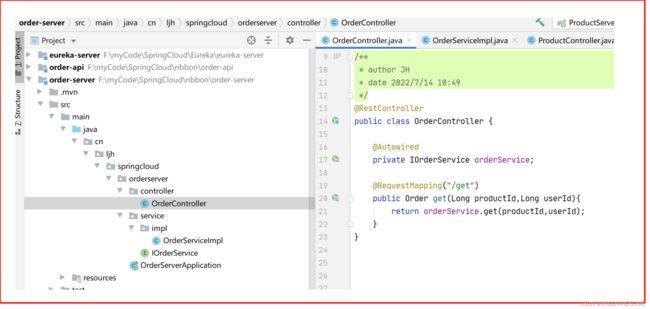
配置yml

访问注册中心

访问订单服务

order-server远程调用product-server
RestTemplate
Ribbon这个组件进行远程调用使用到的就是这个 RestTemplate
方法贴个@Bean注解,方法的返回值会交给spring容器来进行管理

RestTemplate因为先交给spring管理了,后面才能注入进来用
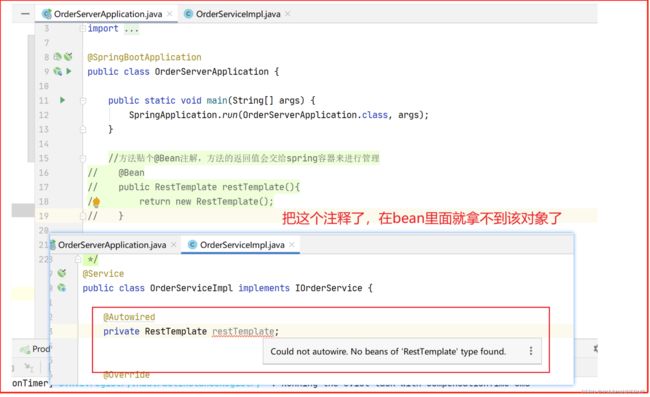
远程调用成功

远程调用+负载均衡
要想有负载均衡的效果,需要改动一下
@LoadBalanced 贴了这个注解,这个restTemplate在远程调用的时候就具有负载均衡的效果了

@Value(“${server.port}”) 在当前环境中找到端口,注入到这个属性里面
根据访问的端口号,看是否实现了负载均衡
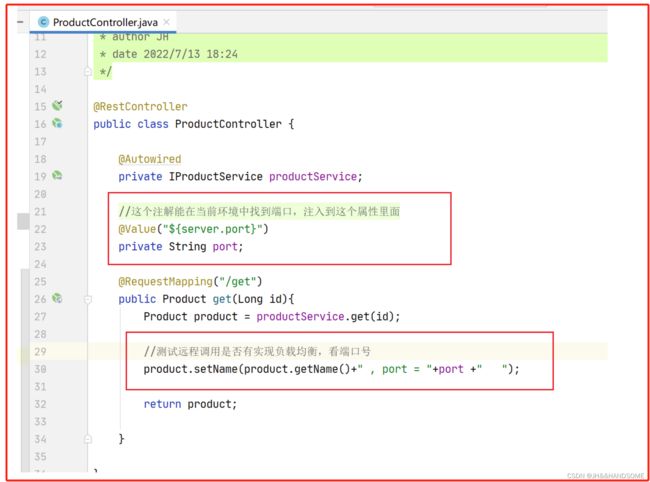
负载均衡效果
刷新了四次,有负载均衡的效果


Ribbon调用的原理

修改Ribbon负载均衡策略
修改策略从调用方order-server服务这边的配置修改
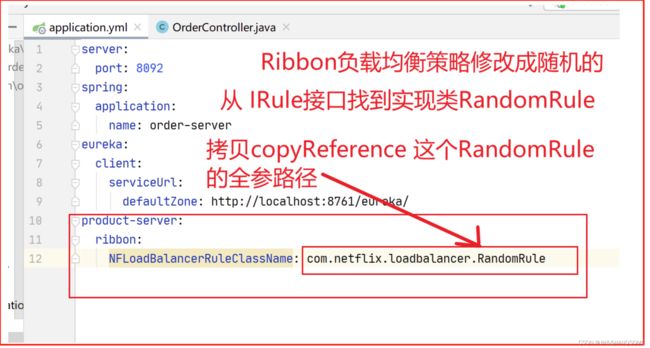
因为我现在的boot的版本过高,该版本的IRule类已经没有了,所以这里记录下就行了。
总结
负载均衡ribbon就是用一个RestTemplate去调用就ok了
微服务调用方式Feign
Feign跟Ribbon一样是远程调用的组件,后面用的更多的是Feign,一样能实现负载均衡
Feign 底层也是用Ribbon来进行调用
product-api配置依赖
添加feign的注解
feign接口
接口写在product-api里面,以后其他服务要用到商品对象就可以直接调用

feign接口实现类
在product-server写实现类,获取商品对象

Feign远程调用分析图
启动类贴个扫描Feign的注解

在这里进行远程调用,product-server 远程调用 product-api 的接口

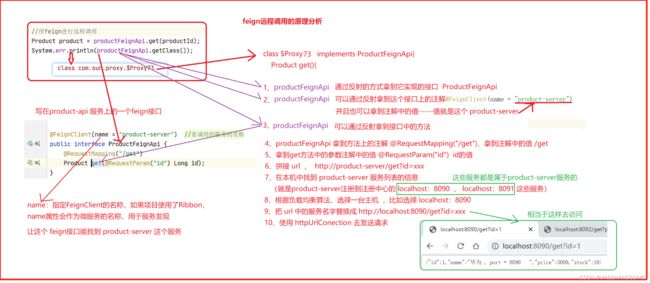
总体调用流程

Feign远程调用原理分析
Feign参数设置
默认超时时间
Ribbon 在远程调用的时候默认是60s
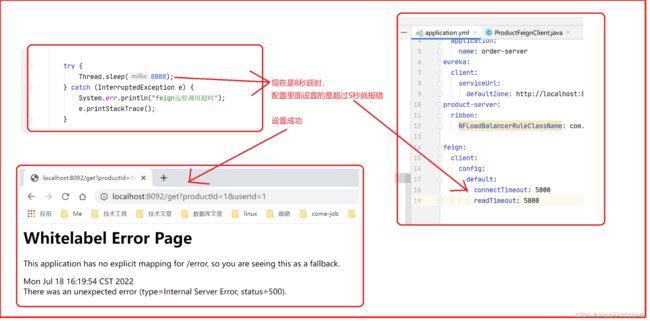
Feign在远程调用的时候是有一个超时时间的,默认是1s
百度:feign默认的connectTimeout时长是10s,readTimeout时长是60s。但是实际服务之间调用readTimeout超过1秒就会超时。
但是我的例子发现feign要超过60秒才会超时报错
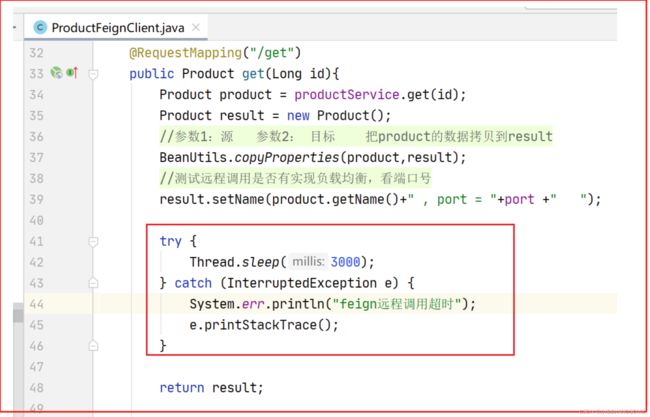
示例
在远程调用的时候睡个三秒,而feign远程调用超过1s就会报错
结果
设置成3秒后,竟然没有报错,而是转3秒后成功访问,后面设置成30秒也不会报错,有点奇怪。按理说应该会报延迟错误。
这个是我设置成61秒,才会的超时。
看来默认超时时间是60秒,>= 60 就会超时
设置成59秒就不会报错


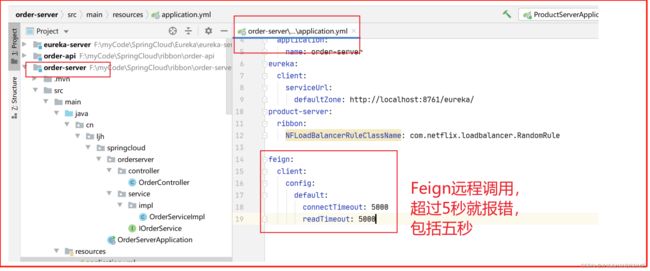
调整默认时间
feign:
client:
config:
default:
connectTimeout: 5000
readTimeout: 5000
比如A给B打电话,connectTimeout 的时间就好比 A打电话给B,到B接通电话的这段时间,这段等待B接通电话的时间,就是connectTimeout的时间,
而B接通电话,和A在聊天的这段时间,就是 readTimeout 的时间。
connectTimeout :电话接通前嘟嘟嘟的等待时间
readTimeout :电话接通后聊天时间
一般都配置在服务的调用方法
调整默认时间有效果
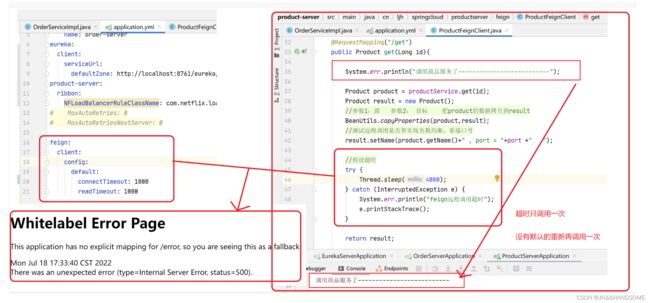
超时重试次数设置
因为feign默认是延时访问失败后,会重新访问一次。但是这是不合理的,如果重新访问的业务不是幂等性的业务,比如给某个人加积分,第一次调用延时了,但是积分已经加进去了,后面又重新访问了一次,积分又加了一次,这样是不合需求的。
分析图
两个设置的重试次数分析
颜色代表设计到哪个设置


feign远程调用重试次数修改
一般是在调用方设置,比如我是order-server去调用product-server,那么我就在order-server 的yml配置里面进行配置

问题
可能是版本问题,我这边的设置延迟了,也只是调用一次,没有上面说的默认会重新调用一次
服务熔断与降级Hystrix
复杂分布式体系结构中的应用程序具有数十种依赖关系,每种依赖关系不可避免的坏在某个时刻失败,如果主机应用程序未与这些外部故障隔离开来,则可能会被淘汰。
feign在远程调用的时候,这个Hystrix默认是关闭的,需要开启才能生效,在调用方的yml配置开启。
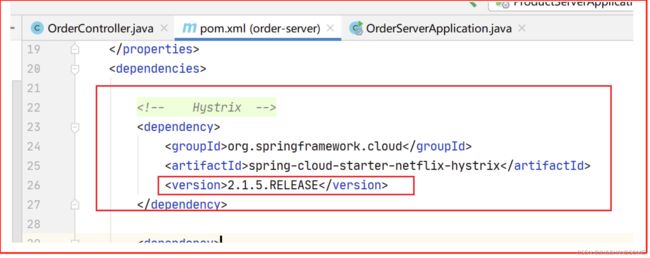
集成Hystrix
依赖
用这个版本,才有这个注解 @HystrixCommand
启动类
添加@EnableCircuitBreaker注解,在这个版本,这个注解已经被弃用了

代码

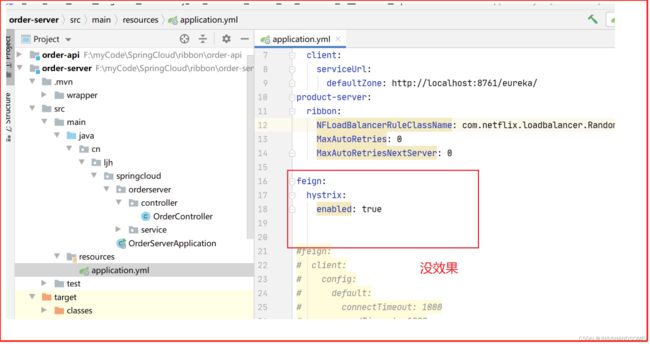
Hystrix开关
Hystrix开关默认是关闭的
就是访问该方法一直报错后,后面直接就走降级方法。
这个是默认的,业务方法一直出错,后面就直接走降级方法。过段时间才会重新走业务方法看该方法是否恢复正常。

需求:远程调用业务的时候,出现问题,不要报错,可以返回一个默认值之类的,做到不要影响到核心业务。

降级没生效
自己写的降级方法不生效,出错后没有走降级方法

Hystrix开关默认是关闭的
解决方法:
没用

解决:



不明白Hystrix开关地方
后面加了其他yml配置,执行的结果又符合预期,所以这张分析图可能是有的地方还没明白,
估计应该是执行的业务逻辑时间超过默认的时间才会依然走降级方法。不必深究。

Feign集成Hystrix流程梳理
降级代码流程梳理

配置梳理

异常报警通知
需求:走降级方法之后,要短信或者是邮件通知开发者。实现一段时间发送一次邮件或短信
做法:用redis处理
开启redis
这里只是开启redis,要想项目和redis联系起来,还得去yml那边配置redis的基本信息

redis依赖
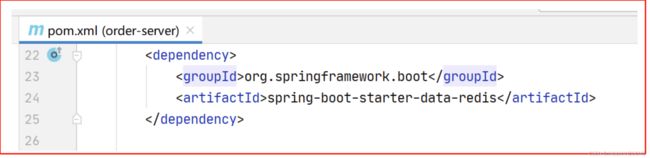
yml配置redis

代码

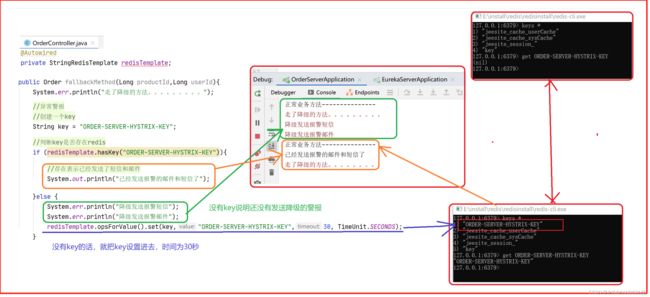
分析图
这个没啥好说的,有key就表示发送了警报,没key就要发送警报,这个key设置的时间看具体情况而定
Hystrix超时时间设置
yml配置
修改了超时时间

需求分析图

处理分析图
处理结果符合预期。

集成Dashboard
作用:
断路器Dashboard监控仪表盘
它主要用来实时监控Hystrix的各项指标信息。通过Hystrix Dashboard反馈的实时信息,可以帮助我们快速发现系统中存在的问题。
配置依赖

启动类

配置yml

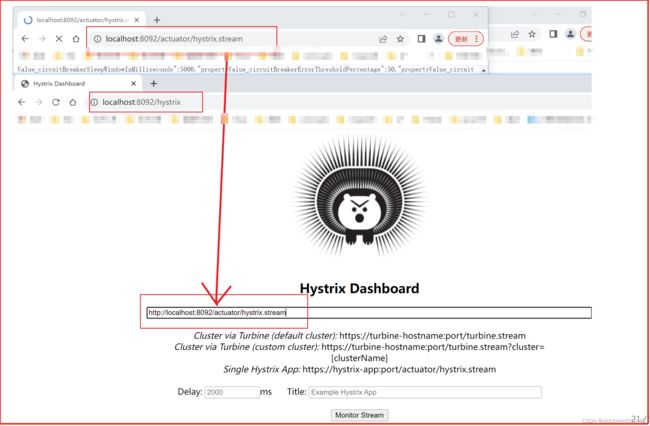
访问路径
访问入口:http://localhost:启动端口/hystrix
然后再地址栏上输入:http://localhost:启动端口/actuator/hystrix.stream

图形化界面
访问入口:http://localhost:启动端口/hystrix-----------------图形化界面
问题bug
估计又是版本问题,我这个cloud版本比较新
这个偏向运维,不深究
Unable to connect to Command Metric Stream.

微服务网关Zuul
1、作用和使用
Zuul网关是系统的唯一对外的入口,介于客户端和服务器端之间的中间层,处理非业务功能 提供路由请求、鉴权、监控、缓存、限流等功能
统一入口
zuul网关把请求分发给各个服务,也叫作路由

搭建
创建项目

yml配置

启动类

访问失败
统一访问网关
因依赖问题,被迫中止,找不出哪个依赖冲突

解决方法
如图访问成功
修改了依赖的版本,把之前的所有cloud和boot的依赖全部删除掉了,重新下载
yml配置如图
2、Zuul 网关的配置
自定义Zuul的路由规则
修改默认路由规则
原本的路由规则是 http://localhost:8080/要访问的服务名(默认是服务名,如product-server)/具体的方法?参数
通过配置修改这个默认的服务名
改了order之后,原本的默认的路径order-server还是生效的

改成了order之后,原本的默认的路径order-server还是生效的
如果想要原本的路径服务名不生效,修改配置

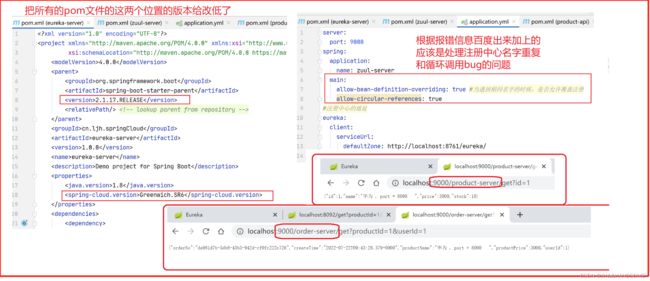
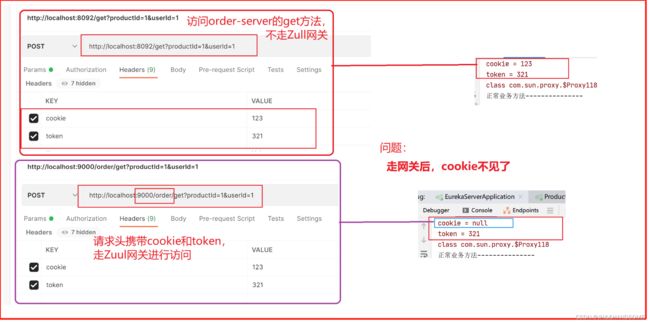
Zuul网关的cookie被过滤问题
问题
原因
默认情况,网关会把Cookie", “Set-Cookie”, "Authorization"这三个请求头过滤掉,下游的服务是获取不到这几个请求头的。

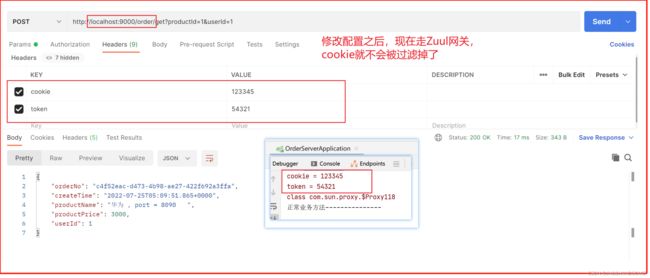
解决
但是我们这个cookie是需要用到的,怎么处理才能让cookie不被过滤掉呢?
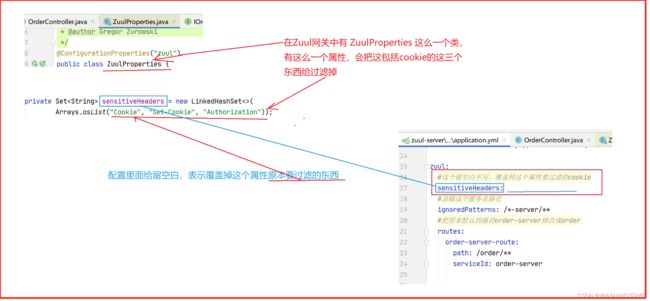
如果不需要过滤这个请求头,可以修改过滤的集合的值.
下面这个属性直接设置:
sensitiveHeaders
底层源码类 ZuulProperties
配置成功
3、Zuul网关自定义filter过滤器实现登录鉴权
自定义前置过滤器----zuul网关到调用服务之前,这两者之间弄一个过滤器。
分析图

鉴权代码
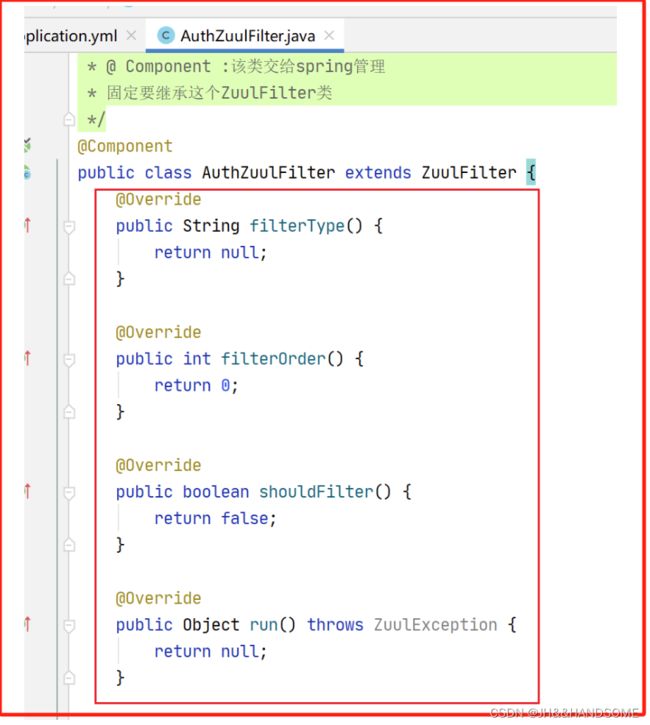
继承的ZuulFilter类,要实现的四个方法

把product-server的默认服务名修改一下

访问测试
访问下product和order。
预期:product服务能正常访问,order服务返回401错误码

访问product服务
没有被拦截,正常返回数据

访问order服务
应该要被拦截


链路追踪组件Sleuth&Zipkin(日志)
整合Sleuth
Sleuth是一个专门用于记录链路数据的开源组件
普通日志打印
最原始的贴注解,然后打印日志,这样就可以打印在文件中了,不只局限在idea控制台查看。
问题:
但是这样也看不出来这个打印日志是不是出自同一个请求打印出来的日志,没有唯一的标识来表示这些打印都来自同一个请求。
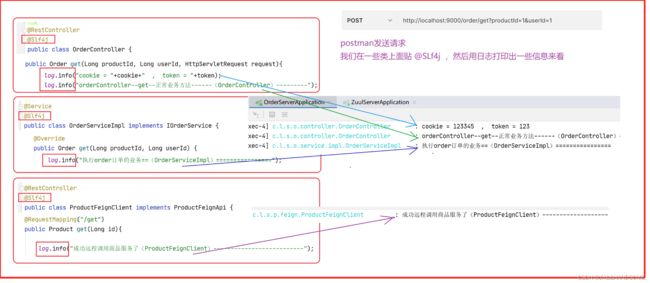
针对这个问题,我们需要整合Sleuth来进行解决
整合Sleuth日志打印
添加依赖
在order-server服务和product-server服务添加Sleuth依赖


搭配 zipkin 使用
图形化界面,展示调用链的关系
这个组件是一个springboot项目,不需要我们建一个服务,只需要用一个命令来调用就行了
默认端口号 9411
添加依赖和配置


启动jar包

访问成功
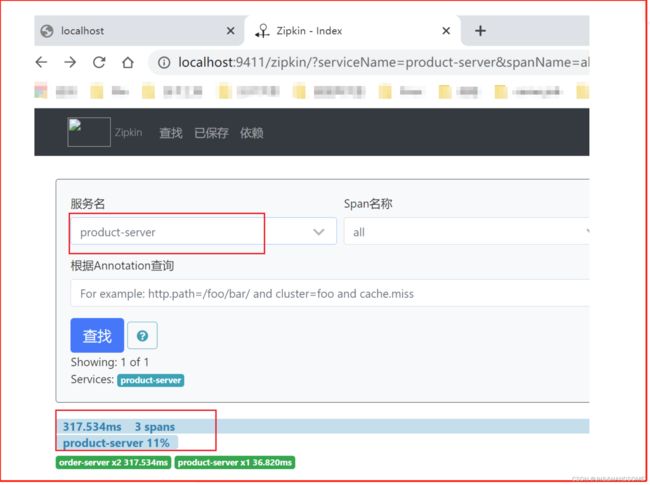
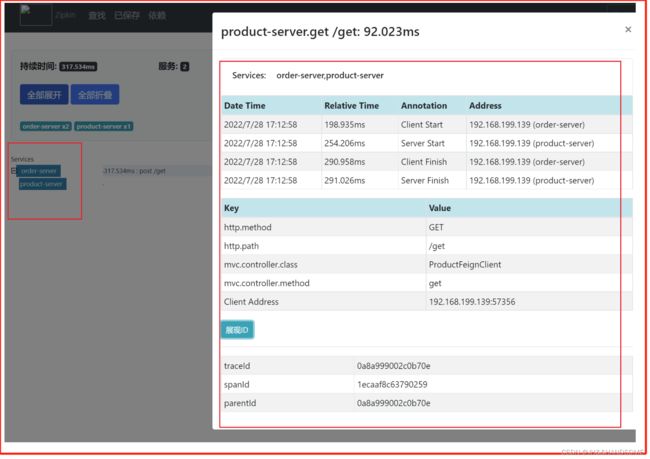
分布式配置中心Config
config配置中心分析
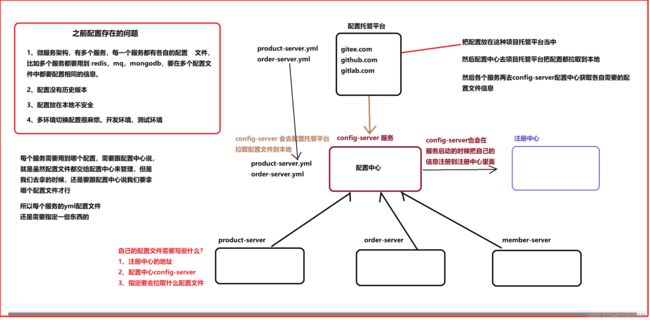
搭建config-server

启动类和yml配置

建立gitee
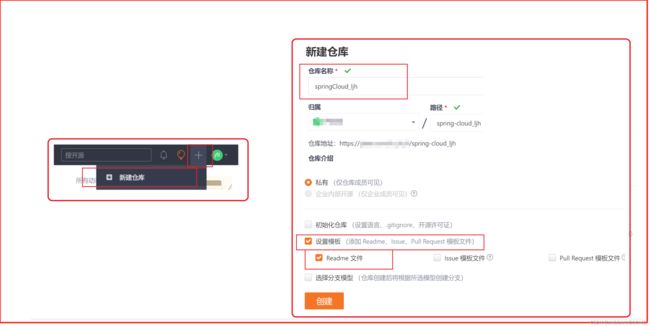
创建一个product-server服务的配置文件

yml配置
config-server 服务 配置到去哪里拉取配置文件的路径后,服务就可以启动成功



访问config服务

注意:

报500的话,可能是gitee的yml配置文件的格式有问题,或者是项目的yml格式 有问题
服务去配置中心拉取配置
依赖和配置

修改application.yml 为 bootstrap.yml , 把一些普通的配置丢在 gitee上面进行托管,然后通过 config配置中心获取配置。(config 配置中心会去 gitee 获取配置)
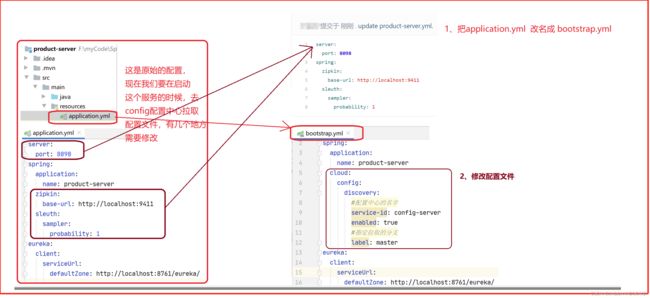
原因:
配置 application.yml ,项目在启动服务的启动类的时候,就会去加载配置文件中的配置。
问题来了,我们现在的配置是在 gitee 码云上面,然后通过config配置中心从gitee中拉取下来,但是我们服务启动的时候就加载application.yml 配置文件,那个时候虽然已经在配置文件里面指定了config,但是还没有从gitee 上面把配置来取下来,就会报错。主要是application.yml配置的运行的优先级不高。
这个时候我们改成bootstrap.yml来配置,
之前是先加载配置文件,再去gitee拉取配置文件,改成 bootstrap.yml后,就变成先去gitee拉取配置文件,然后再执行加载bootstrap.yml这个配置文件

启动看结果
原本的配置文件是 8090,现在gitee上面改成 8098,看访问8098 是否成功。
现在已经可以通过config 配置中心,从 gitee 托管平台成功拉取到自己所需要的配置了
