阿里云分布式调度系统-伏羲
最近在做一个类似的东西,看了一篇讲FuxiSort的paper,就去详细学习了下。
paper链接:
链接: https://pan.baidu.com/s/1H9GdDd7lgcgWkw0tkC95Jw 提取码: gix8
下文作者:陶阳宇,花名举水,阿里云高级技术专家,飞天分布式系统早期核心开发人员,开发和优化过伏羲系统中多个功能模块,参加了飞天5K、世界排序大赛等多个技术攻坚项目。在分布式计算、高并发系统的设计和开发方面有较丰富的经验。
本文涉及阿里云分布式调度团队在分布式调度系统的设计、实现、优化等方面的实践以及由此总结的分布式系统设计的一般性原则,具体包括分布式调度的任务调度、资源调度、容错机制、规模挑战、安全与性能隔离以及未来发展方向六部分。
云计算并不是无中生有的概念,它将普通的单台PC计算能力通过分布式调度软件连接起来。其最核心的问题是如何把一百台、一千台、一万台机器高效地组织起来,灵活进行任务调度和管理,从而可以像使用台式机一样使用云计算。在云计算中,最核心的模块是分布式调度,它好比云计算的中央处理器。目前,业界已存在多种分布式调度实现方案,如伏羲、Hadoop MapReduce、YARN、Mesos等系统。
阿里云伏羲
伏羲系统在前人的基础上进行了一系列改造,首先与YARN和Mesos系统类似,将资源的调度和任务调度分离,形成两层架构,使其具备以下优势:
规模:两层架构易于横向扩展,资源管理和调度模块仅负责资源的整体分配,不负责具体任务调度,可以轻松扩展集群节点规模;
容错:当某个任务运行失败不会影响其他任务的执行;同时资源调度失败也不影响任务调度;
扩展性:不同的计算任务可以采用不同的参数配置和调度策略,同时支持资源抢占;
调度效率:计算framework决定资源的生命周期,可以复用资源,提高资源交互效率。
这套系统目前已经在阿里集团进行了大范围的应用,能支持单集群5000节点、并发运行10000作业、30分钟完成100T数据terasort,性能是Yahoo在Sort Benchmark的世界纪录的两倍。
伏羲的系统架构
伏羲的系统架构如图1所示,整个集群包括一台Fuxi Master以及多台Tubo。其中Fuxi Master是集群的中控角色,负责资源的管理和调度;Tubo是每台机器上都有的一个Agent,负责管理本台机器上的用户进程;同时集群中还有一个叫Package Manager的角色,因为用户的可执行程序以及一些配置需要事先打成一个压缩包并上传到Package Manager上,Package Manager专门负责集群中包的分发。
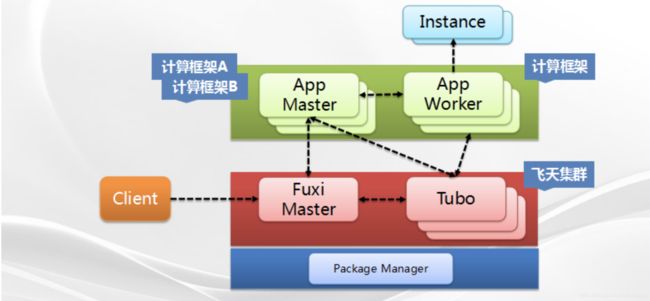
集群部署完后,用户通过Client端的工具向Fuxi Master提交计算任务;Fuxi Master接收到任务后首先通知某一个Tubo启动这个计算任务所对应的APP Master;APP Master启动之后,它获知了自己的计算任务,包括数据分布在哪里、有多少的任务需要计算等等信息;接着APP Master会向Fuxi Master提交资源申请,表明它需要多少计算资源;Fuxi Master经过资源调度以后,将资源的分配结果下发给APP Master;APP Master在这个资源的基础之上进行它的任务调度,来决定哪些机器上运行哪些计算任务,并且将这个计算任务发送给对应机器上的Tubo进程;Tubo接受到命令之后就会从Package Manager中下载对应的可执行程序并解压;然后启动用户的可执行程序,加载用户的配置(图1中的APP Worker);APP Worker根据配置中的信息读取文件存储系统中的数据,然后进行计算并且将计算结果发往下一个APP Worker。其中,数据的切片称之为Instance或者叫计算实例。
Fuxi Master与Tubo这套结构解决了分布式调度中的资源调度,每个计算任务的APP Master以及一组APP Worker组合起来解决任务调度的问题。
任务调度
伏羲在进行任务调度时,主要涉及两个角色:计算框架所需的APP Master以及若干个APP Worker。
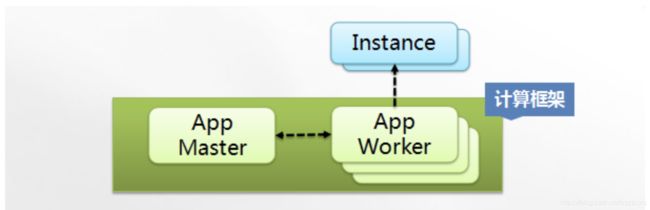
APP Master首先向Fuxi Master申请/释放资源;拿到Fuxi Master分配的资源以后会调度相应的APP Worker到集群中的节点上,并分配Instance(数据切片)到APP Worker;APP Master同时还要负责APP Worker之间的数据传递以及最终汇总生成Job Status;同时为了达到容错效果,APP Master还要负责管理APP Worker的生命周期,例如当发生故障之后它要负责重启APP Worker。
而APP Worker的职责相对比较简单,首先它需要接收App Master发来的Instance,并执行用户计算逻辑;其次它需要不断地向APP Master报告它的执行进度等运行状态;其最为主要的任务是负责读取输入数据,将计算结果写到输出文件;此处的Instance是指输入数据的切片。伏羲任务调度系统的技术要点主要包括数据的Locality、数据的Shuffle以及Instance重试和Backup Instance三点。
数据Locality
数据Locality是指调度时要考虑数据的亲近性,也就是说APP Worker在处理数据时,尽量从本地的磁盘读取数据,输出也尽量写到本地磁盘,避免远程的读写。要实现这一目标,在任务调度时,尽量让Instance(数据分片)数据最多的节点上的AppWorker来处理该Instance。
数据Shuffle
数据Shuffle指的是APP Worker之间的数据传递。在实际运行中,APP Worker之间是有多种传递形态的,如一对一、一对N、M对N等模式。如果用户去处理不同形态的传输模式,势必会带来较大的代价。伏羲分布式调度系统将数据传递的过程封装成streamline lib,用户无需关心数据传递的细节。首先Map进行运算,将结果直接交给streamline,streamline底层会根据不同的配置将数据传给下游计算任务的streamline;然后streamline将接到的数据交给上层的计算任务。
Instance重试和backup instance
在Instance的运行过程中可能有多种原因导致Instance失败,比如APP Worker进程重启或运行时机器、磁盘发生故障,种种原因都可能导致一个Instance在运行时最终失败;另外APP Master还会监控Instance的运行速度,如果发现Instance运行非常慢(容易造成长尾),会在另外的APP Worker上同时运行该Instance,也就是同时有两个APP Worker处理同一份数据,APP Master会选取最先结束的结果为最终结果。判断一个Instance运行缓慢的依据有:
该Instance运行时间超过其他Instance的平均运行时间;
该Instance数据处理速度低于其他Instance平均值;
目前已完成的Instance比例,防止在整体任务运行初期发生误判。
资源调度
资源调度要考虑几个目标:一是集群资源利用率最大化;二是每个任务的资源等待时间最小化;三是能分组控制资源配额;四是能支持临时紧急任务。在飞天分布式系统中,Fuxi Master与Tubo两者配合完成资源调度。
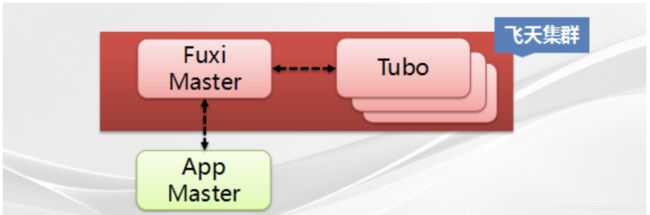
在飞天分布式系统中,Fuxi Master与Tubo两者配合完成资源调度。Tubo是每个节点都有的,用于收集每个机器的硬件资源(CPU、Memory、Disk、Net),并发送给FuxiMaster;FuxiMaster是中控节点,负责整个集群的资源调度。当启动计算任务时,会生成APP Master,它根据自己的需要向Fuxi Master申请资源,当计算完成不再需要时,归还该资源。
飞天分布式调度常用的分配资源策略包括优先级和抢占、公平调度、配额。在实际应用场景中,不同策略可配合起来使用。
策略之优先级和抢占
每个Job在提交时会带一个priority值(整数值),该值越小优先级越高;相同优先级按提交时间,先提交的优先级高;FuxiMaster在调度时,资源优先分配给高优先级的Job,剩余的资源继续分配给次高优先级Job。
如果临时有高优先级的紧急任务加入,FuxiMaster会从当前正在运行的任务中,从最低优先级任务开始强制收回资源,以分配给紧急任务,此过程称为“抢占”。抢占递归进行,直到被抢任务优先级不高于紧急任务,也就是不能抢占比自己优先级高的任务。
策略之公平调度
公平调度策略是指当有资源时Fuxi Master依次轮询地将部分资源分配给各个Job,它避免了较大Job抢占全部资源导致其他Job饿死现象发生。公平调度首先按优先级分组,同一优先级组内的平均分配,如果有剩余资源再去下一个优先级组进行分配,依此类推。
配额
配额是资源分配时的第三个策略,通常是按照不同的业务进行区分,多个任务组成一个组,例如淘宝、支付宝等;集群管理员会设立每一个组的资源上限,意味着这个组最多能使用这么多CPU、Memory、磁盘等,该上限值称为Quota;每个组的Job所分配的资源总和不会超过该组内的Quota,当然如果每一个组内没有用完的Quota是可以分享给其他组的,会按照Quota的比例进行均分。
容错机制
在大规模进程集群中故障是常态,这些常态会来自硬件,比如主板、电源、内存条;也可能来自软件,比如进程有Bug导致进程Crash,机器故障导致性能慢。因此,分布式调度必须具有容错机制,以保证正在运行的任务不受影响,并对用户透明,能够从故障中恢复过来,保障系统的高可用。下面将从任务调度的Failover和资源调度的Failover两个方面介绍。
AppMaster进程重启后的任务调度Failover
每个计算任务有自己的APP Master,如果APP Master进程发生了重启,那其重启之后的任务调度如何进行Failover呢?这里采用了Snapshot机制,它将Instance的运行进度保存下来,当APP Master重启之后会自动加载Snapshot以获取之前每个Instance的执行进度,然后继续运行Instance;当APP Master进程重启之后,从APP Worker汇报的状态中重建出之前的调度结果,继续运行Instance。
FuxiMaster进程重启后的资源调度Failover
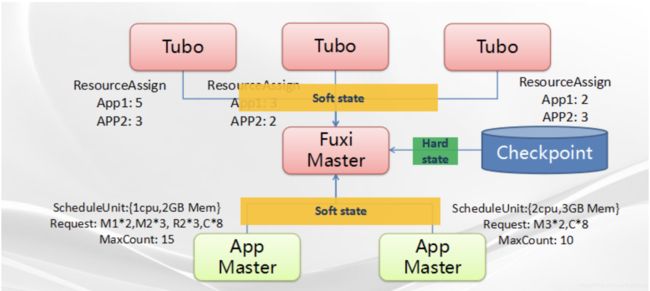
另一种情况是Fuxi Master发生了Failover。Fuxi Master Failover起来之后需要重建内部状态,该状态通常分为两种:一是Hard State,主要是之前提交的Application配置信息,如不同的Job配置参数等,它们来自于Fuxi Master写的Snapshot;另一类是Soft State,Fuxi Master会收集来自各个Tubo以及APP Master的信息重建出自己的状态,这些信息包括机器列表、每个APP Master的资源请求以及之前的资源分配结果。
Fuxi Master进程重启之后的资源调度过程如图4所示,首先会从Checkpoint中读取出所有Job的配置信息;同时会收集所有的Tubo以及APP Master上报上来的关于资源分配的结果,如CPU多少、Memory多少等等。
规模挑战
分布式系统设计主要目标之一就是横向扩展(scale-out),目前阿里云飞天在2013年时已支撑单个集群5000个节点、并发1万个任务。在做横向扩展设计时,需要注意两个要点:一是多线程异步;二是增量的资源调度。
多线程异步
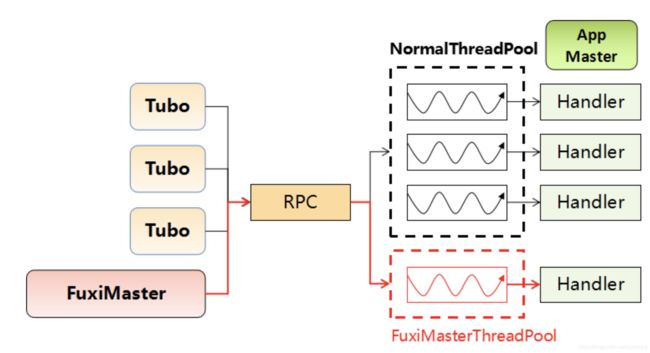
多线程异步是编写分布式程序一个非常重要而且常用的技术手段。在网络通信模块中,每个APP Master都需要跟Fuxi Master进行资源通信,同时也需要跟多个Tubo进行通信以启动它们的APP Worker。APP Master处理网络通信的过程称之为RPC,RPC通信时必须采用线程池来处理。如图5中采用四个线程池来处理这些消息。由于Fuxi Master是一个中控节点,而Tubo的数量非常众多,如果将这些消息都在同一个线程池中处理,则Fuxi Master的消息有可能会被大量的Tubo消息阻塞(对头阻塞问题)。为了解决该问题,在伏羲系统当中设立了一个独立的线程池来处理Fuxi Master的消息;另外一个线程池来处理Tubo的消息,将线程池进行分开,也称之为泳道;独立的泳道能有效解决Fuxi Master的消息被对头阻塞的问题。
增量的资源调度
伏羲解决规模问题的另一个技术点是增量。目前,伏羲采用增量的消息通信和资源调度,下面通过具体例子,来介绍伏羲所采用的增量资源调度的协议。
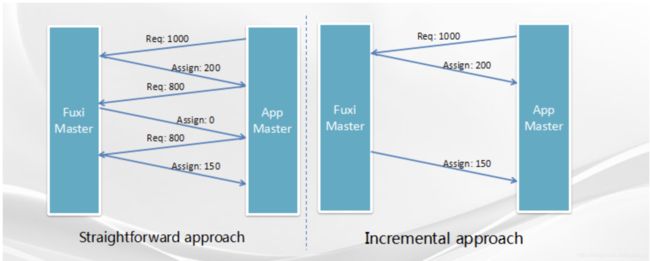
图6左侧是中控节点Fuxi Master;右边为某一个APP Master,如果说APP Master需要1000份资源,最直接的一种实现方式是将“我要1000个资源”这样的消息直接发送给Fuxi Master;Fuxi Master在接到消息之后可能当前的剩余资源只有200份,它将会“我分配给你200”这样的消息发送给APP Master;那APP Master还会继续发送消息“我还要剩余的800”,Fuxi Master回复“此时没有资源,我分配0个给你”;则APP Master在下一次通信的时候需要继续发送“我还要剩余的800”……依此类推,可能某一个时刻Fuxi Master还能分一点资源下来。这就是最直观的全量消息通信,每一次APP Master提出请求时都要指明它总共需要多少。
而在伏羲的实现当中为了减小通信量和不必要的开销,采用了增量的语义。首先APP Master发送一个请求“我要1000个资源”,Fuxi Master收到之后将当时空闲的200个资源返回给APP Master;之后APP Master无需再提交请求说我还需要800,因为Fuxi Master会将这1000个请求记录下来等到某一时刻又有更多的资源,比如150个资源释放,它直接将150个分配结果发送给APP Master即可。这期间APP Master无需再发多余的网络通信。
安全与性能隔离
在分布式系统当中通常有多个用户在执行自己的计算任务,多个任务之间需要互相隔离、互相不影响。飞天伏羲实现了全链路的访问控制,采用了两种访问控制进行安全的验证,一种是Capability,指通信双方基于私钥进行解密并验证的一种方式;还有一种称为Token的方式,这种方式需要通信的双方临时生成基于私钥加密的口令,在通信时进行验证。
两种方式最大区别在于口令生成的时机,Capability方式是在通信之前就已经加密好;而Token是需要在通信时临时生成。

两种方式使用于不同的场景,如图7所示FuxiMaster与Tubo通信采用的是Capability方式,因为这两个角色在集群部署时就已启动,可以事先进行加密生成好Capability;FuxiMaster与APP之间是采用Token的方式,这是因为APP与FuxiMaster进行通信时,当每个任务执行完计算之后会退出;在进程与进程之间,伏羲采用了沙箱的方式将不同的进程进行隔离开、互不干扰。
除了安全的隔离之外,还需要考虑性能的隔离。目前伏羲采用的几种技术手段:Cgroup(Linux LXC)、Docker container、VM等。这几种技术的隔离性、资源配额/度量、移动性、安全性的比较如图8所示,不再一一叙述。

伏羲目前采用的隔离技术是基于Docker和LXC混合部署的方式,之所以抛弃虚拟机的方式,是因为其性能损耗太多。当运行计算任务时,如果完全放在虚拟机当中,它的IO以及CPU时间片会受到很大的影响,会降低任务的执行效率。在目前阿里的生产环境中,实践发现基于Docker和LXC的隔离技术已经可以很好地满足需求。
分布式调度的发展方向
随着计算能力和数据量的持续增长,分布式调度未来可能朝向以下几个方向发展:
在线服务与离线任务混跑。云计算最终的目的是降低IT成本,最大限度地利用单台PC的CPU处理能力,所以未来的趋势一定是在线服务与离线任务能够在同一物理集群上运行从而实现削峰填谷效果、最大化提高集群利用率。但是由于两种任务的特点不同,在线运用对于响应时间要求很高,而离线运用则对调度的吞吐率要求比较高,因此混跑会带来性能隔离与资源利用率之间的矛盾。
实时计算的发展,Map Reduce是一个很伟大的框架,但其是为数据量一定的批处理而设计的。随着云计算越来越普及,很多计算形态需要实时拿到计算结果,并且其输入数据可能是不间断的。目前,伏羲也已经开发出了实时的计算框架——OnlineJob,它可以提供更快的执行速度。
更大的规模,目前已能够支撑5000台的节点,随着计算量越来越大,客户的需求越来越多,需要进一步优化伏羲系统,能够支撑起1万、5万、10万等更大规模单集群,同时能够支撑更多的并发任务。