python_day_0B 正则表达式
目录
0x00 re模块基本使用:
0x01 表示字符
0x02 表示数量(数量描述符)
0x03 代码:
0x04 关于转义:
0x05 表示边界
0x06 匹配分组:
0x07 正则表达式的高级应用:
0x08 sub例题讲解
0x09 贪婪与非贪婪
0x0A 练习题讲解
0x00 re模块基本使用:
原理:
1. 将正则表达式的字符串形式 编译 为 Pattern 对象:re.complie()
2.使用Pattern对象处理文本并获得匹配结果: match() find() findall()
3.使用Pattern对象获取信息,进行其他操作
完整写法:
import re
pattern = re.compile("hello")
matches = pattern.match("hello 123")
if(None!= matches):
print(matches.group())
else:
print("无匹配结果")简写形式:
import re
words = re.findall("\d+","hello 1232 word") //返回值: list
print(words)import re
"""
result = re.match(正则表达式,要匹配的字符串)
如果字符串匹配正则表达式,则match方法返回匹配对象
(Match Object),否则返回None(注意不是空字符串"")
匹配对象Match Object具有group方法
用来返回字符串匹配的部分
"""
result = re.match("itcast","itcast.cn")
print(result.group())
print(dir(result))
#查看result对象的所有方法和属性
0x01 表示字符
| 字符 | 功能 |
| . | 匹配任意一个字符(除了“\n”之外) |
| [] | 匹配[]中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即空格,tab键即\t,换行符\t,\r(光标回到行首) |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符 |
0x02 表示数量(数量描述符)
| 字符 | 功能 |
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,} | 匹配前一个字符至少出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
0x03 代码:
import re
"""
result = re.match(正则表达式,要匹配的字符串)
如果字符串匹配正则表达式,则match方法返回匹配对象
(Match Object),否则返回None(注意不是空字符串"")
匹配对象Match Object具有group方法
用来返回字符串匹配的部分
"""
result = re.match("itcast","itcast.cn")
print(result.group())
print(dir(result))
#查看result对象的所有方法和属性
result2 = re.match(".","i")
result3 = re.match(".","shang")
#result4 = re.match(".","\n")
print(result2.group())
print(result3.group())
#print(result4.group())
#要求字符串中必须有三个及其以上的字符
result5 = re.match("...","xi")
print(result5)
result6 = re.match("\d","123142")
print(result6.group())
result7 = re.match("\d","dsa")
print(result7)
result8 = re.match("\s","\tdsa")
print(result8.group())
#[]
result9 = re.match("1[34578]","18")
print(result9.group())
#[]中的^表示对括号中的元素取反。
result10 = re.match("1[^34578]","19")
print(result10.group())
#[]中的元素既可以用列举法来写,可以用-表示一个范围
result11 = re.match("1[a-z3-8]","1z")
print(result11.group())
"""
\d == [0-9]
\D == [^0-9]
\w == [a-zA-Z0-9_]
\W == [^a-zA-Z0-9_]
"""
result11 = re.match("1*","1111")
print(result11.group())执行结果:
 0x04 关于转义:
0x04 关于转义:
字符串中出现一个斜线,规则中需要将每一个斜线转义(因为规则中的斜线\另有其意义,例如\w,所以必须转义),所以应该出现加倍的斜线。
例如:字符串中就像打印\nabc,而不是换行abc,那么字符串中就需要将\转义,将整个字符串写成\\nabc。这样一来,规则中就需要写成\\\\n\w{3}来匹配这个字符串

这样一来,那岂不是很麻烦???如果字符串中有4个斜线,那么规则就要写上8个斜线???
python中可以通过原始字符串来解决这个问题,在规则前加上r表示该字符串是原始字符串('r' represents "raw"),这样一来,字符串中有多少个斜杠,规则就写多少个斜杠即可。
例如:

0x05 表示边界
^可以理解为必须以什么东西开头,因为python re模块中的match方法默认是从头开始匹配的,所以^在match方法中作用不是很明显。
$可以理解为必须以什么东西结尾
 运行结果:
运行结果:
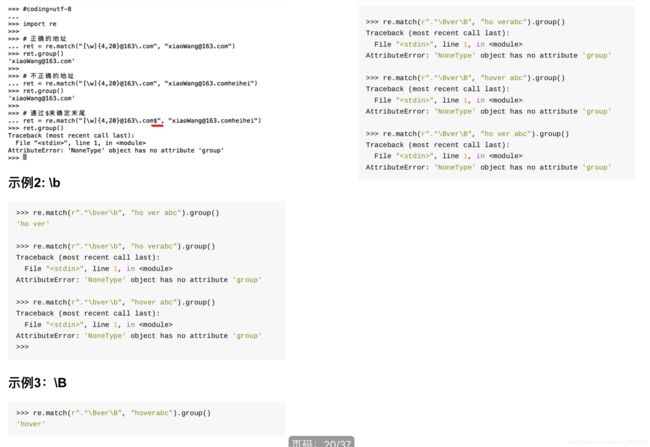
0x06 匹配分组:

 运行结果:
运行结果:

 实例:
实例:
分组有什么用呢?分组之后,我们可以将匹配到的信息按组提取出来。result.group(1)就表示提取匹配内容的第一组括号中的信息。result.group(0)则表示整个匹配到的部分。
 result.groups() 则将所有括号匹配到的信息放到一个元组之中,一次性显示出来。
result.groups() 则将所有括号匹配到的信息放到一个元组之中,一次性显示出来。

那么如何用匹配分组限定html中标签匹配呢?
 如果这样改写
如果这样改写

其中,\2表示和第2个括号中的内容相同,\1表示和第1个括号中的内容相同。
辣么问题来了,当一个规则中分组特别多时,要提取某个括号中的内容岂不是很麻烦?这时我们可以给分组起一个名字,来区分它们。
给分组起名字:?P
(?P=name)则表示 必须 和分组名为name的内容 相同
![]() 总结:?P加尖括号表示定义,?P加等号表示使用
总结:?P加尖括号表示定义,?P加等号表示使用
0x07 正则表达式的高级应用:
1.search("规则","字符串"):表示从左向右搜索字符串,直到在字符串中找到符合规则的部分

注意:search找到符合规则的字符串之后就会停止搜索

那么如何找到所有符合要求的字符串呢?用findall
2.findall("规则","字符串") 表示从左到右搜索字符串,直到在字符串中找到所有符合规则的部分。

3.替换:
vi中如何批量替换
:起始行号,结束行号s/原字符串/替换成字符串
其中s represents search

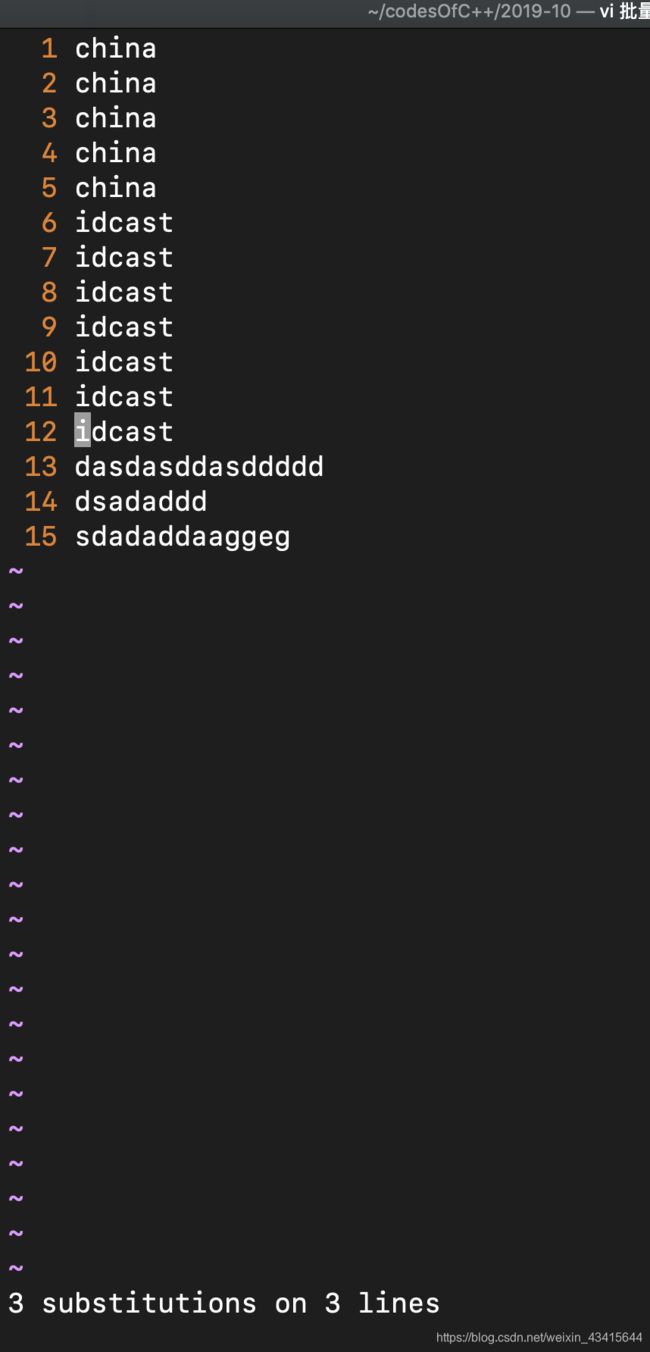 那么
那么
那么如何替换掉一行中所有的t呢?只需要在原来的式子后面加上一个/g
即1,5s/t/d/g
那么python 中如何进行批量替换呢?sub!
re.sub(r"原来的部分(规则)","替换成","字符串")

sub的高级用法:
写一个函数,将匹配对象传给函数,将函数的返回值作为替换内容。在实际应用中,我们常常有这样一种需求,例如:找到字符串中匹配的数字,然后给这个数字加上多少,迭代它的值。那么这个功能如何用sub实现呢?

根据原来的值进行相应的替换,注意进行强制类型转化

0x08 sub例题讲解
题目:将html文件中标签全部去除掉
注意python的如果用三个引号来表示字符串那么表示保留字符串原来的换行等格式,这种操作用于从其他地方大段赋值字符串到程序中
string = """ 大段代格式的字符串"""
解:

如上图所示,<.+>将所有的字符都替换了???为什么会这样呢?这便和python的贪婪模式有关,所谓贪婪,即尽可能多的去匹配,即.+会从头开始一直匹配直到遇到最后一个>为止,中间的>都被匹配了。
split("分隔符","字符串")
根据匹配进行切割字符串,并返回一个列表

0x09 贪婪与非贪婪

在.+之后加上?可以关闭贪婪模式,进入非贪婪模式,即尽可能少得去匹配。

0x0A 练习题讲解
题目1:匹配网址


题目2:找出单词
有一句英文如下:
hello world ha ha
查找所有的单词
