Flink1.14新特性介绍及尝鲜
一、Flink简介
l官网:Apache Flink: Stateful Computations over Data Streams
lApache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
版本定位:专注于质量改进和维护的版本
发版时间:2021年9月30日
贡献者: 200+
相关链接:1.14 Release - Apache Flink - Apache Software Foundation https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/release-notes/flink-1.14/#known-issues

Flink 1.14 升级概览

二、流批一体的处理体验
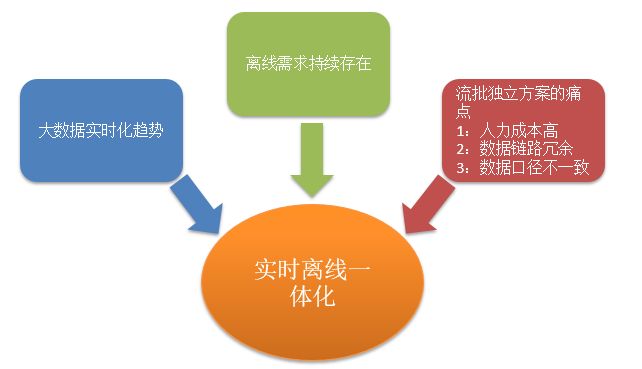
1、流批一体的背景
2、执行模式

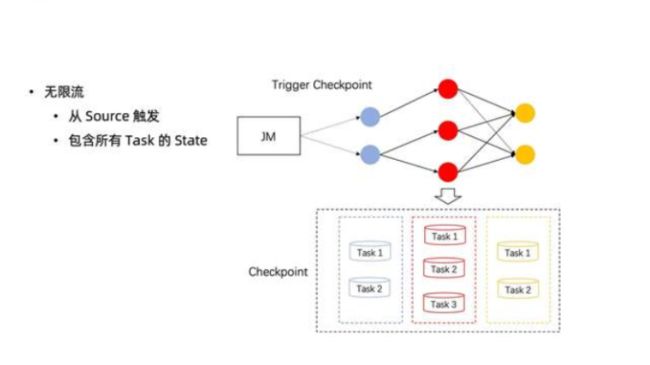
3、流执行模式的 Checkpoint
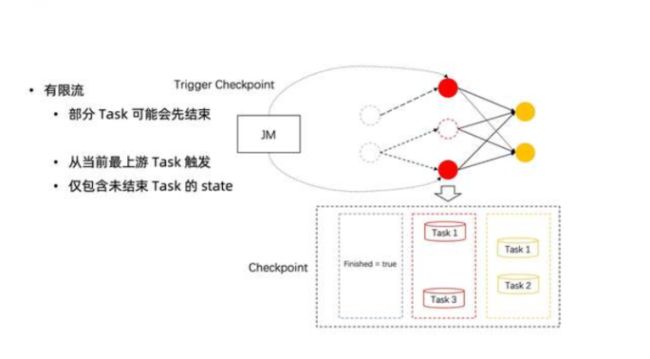
4、Task 结束后的 Checkpoint
通过在配置中添加 execution.checkpointing.checkpoints-after-tasks-finish.enabled: true 启用
5、Task 结束后的两阶段提交
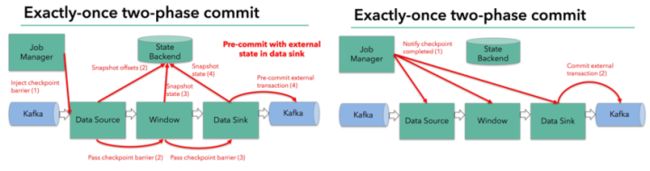
有限流
Task / 作业结束后不能保证有 Checkpoint,最后一部分数据如何提交?
数据处理完成后,Task 等待 Checkpoint 完成后再退出
Apache Flink: An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
6、DataStream 和 Table/SQL 混合应用的批执行模式
参考官网:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/data_stream_api
以下代码显示了如何在两个 API 之间来回切换的示例

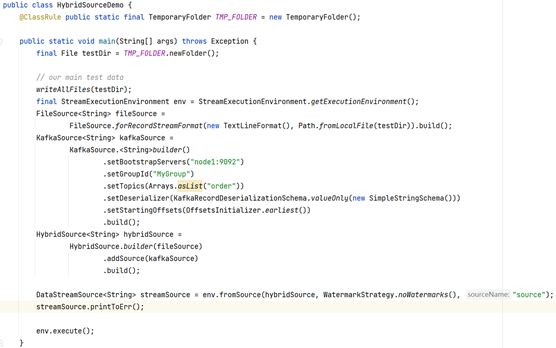
7、混合 Source
参考官网:Hybrid Source | Apache Flink
一个简单的示例,其中FileSource和KafkaSource具有固定的Kafka起始位置。
三、Flink反压机制问题
1、Flink反压机制问题

2、数据在Buffer内停留方式

3、Checkpoint 机制的痛点
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/concepts/stateful-stream-processing/

4、未对齐的 Checkpoint
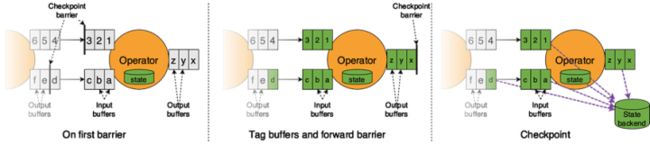
lBarrier 不受数据阻塞,解决反压时无法作出 checkpoint 的问题
lBarrier 无需对齐
Stateful Stream Processing | Apache Flink
5、缓冲区去膨胀
缓冲区去膨胀是 Flink 中的一项新技术,可以最小化 Checkpoint 的延迟和开销。它通过自动调整网络内存的用量,在确保高吞吐的同时最小化缓冲区中的数据量。
Apache Flink 在其网络栈中缓冲了一定量的数据,以便有效利用快速网络的高带宽。Flink 应用以高吞吐运行时,会使用部分(或全部)网络缓冲内存。对齐的 Checkpoint 随着数据在毫秒级的时间内流过网络缓冲区。
当 Flink 应用出现(暂时的)反压时(例如外部系统反压或遇到数据倾斜),往往会导致网络缓冲区中存放了相对应用当前吞吐(因反压而降低)所需的带宽过多的数据。更加不利的是,缓冲的数据越多意味着 Checkpoint 机制需要做越多的工作。对齐的 Checkpoint 需要等待更多的数据得到处理,非对齐的 Checkpoint 则需要持久化更多排队中的数据。
这就轮到缓冲区去膨胀登场了。它将网络栈从持有最多 X 字节的数据改为持有需要接收端 X 毫秒计算时间处理的数据。默认值是 1000 毫秒,意味着网络栈会缓冲下游任务 1000 毫秒所能处理的数据量。通过持续的测量和调整,系统能够在不断变化的情况下保持这一特性。因此,Flink 对齐式 Checkpoint 具备了稳定的、可预测的对齐时间,反压时存放在非对齐式 Checkpoint中的数据量也极大程度减少了。
缓冲区去膨胀可以作为非对齐式 Checkpoint 的补充,甚至是替代选择。请参考:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/memory/network_mem_tuning/#the-buffer-debloating-mechanism
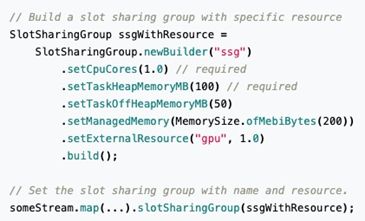
6、细粒度资源管理
支持 DataStream API
自定义 SSG 划分方式及资源配置
TaskManager 动态资源扣减

四、Table / SQL / Python API
1、Table API / SQL
Window Table-Valued Function 支持更多算子与窗口类型
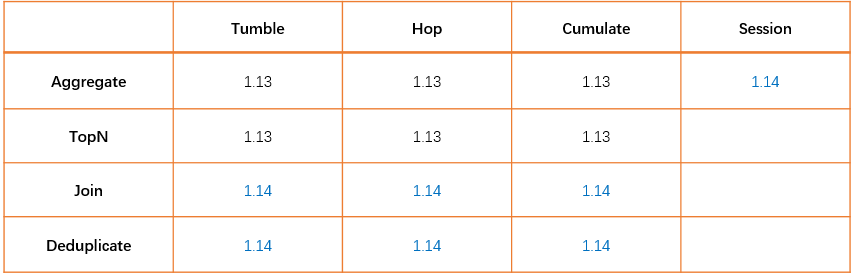
1.Table API 支持声明式注册 Source / Sink
2.功能对齐 SQL DDL
3.支持 new Source
4.替代旧的 connect() 接口 [Deprecated]
5.全新的代码生成器,彻底解决 Java 代码超长问题
6.旧的 Flink Planner 被移除,Blink Planner 成为唯一实现

2、Python API
支持 Python DataStream API 下的 UDF Chaining
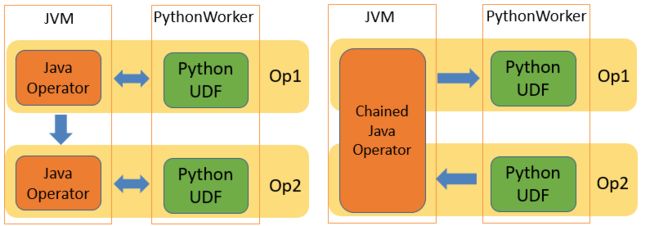
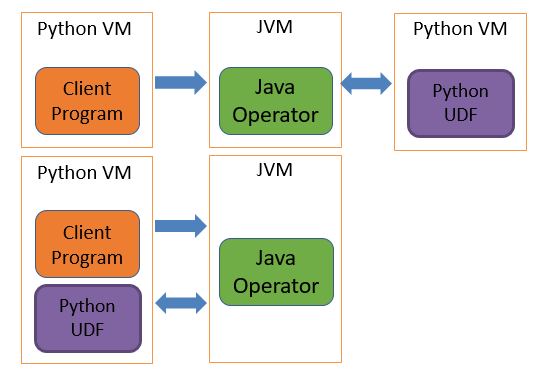
1.支持 Loopback 模式
2.本地运行启动更快
3.相同进程内便于 Debug
五、连接器:Apache Pulsar
1、Apache Pulsar基本介绍
Apache Pulsar 是一个云原生企业级的发布订阅(pub-sub)消息系统,最初由Yahoo开发,并于2016年底开源,现在是Apache软件基金会顶级开源项目。Pulsar在Yahoo的生产环境运行了三年多,助力Yahoo的主要应用,如Yahoo Mail、Yahoo Finance、Yahoo Sports、Flickr、Gemini广告平台和Yahoo分布式键值存储系统Sherpa。
Apache Pulsar的功能与特性:
1.多租户模式:
2.灵活的消息系统
3.云原生架构
4.segmented Sreams(分片流)
5.支持跨地域复制
Apache Pulsar公开课:【Python+大数据】 Apache Pulsar 云原生消息中间件之王_哔哩哔哩_bilibili
2、Flink操作Apache Pulsar
参考网址:Pulsar | Apache Flink
添加依赖
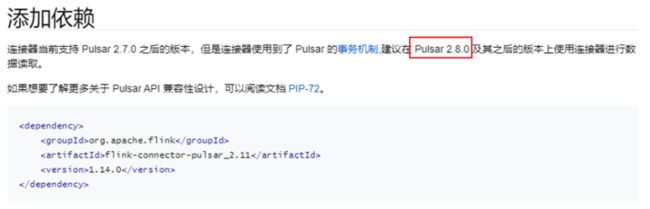
3、Flink操作Apache Pulsar
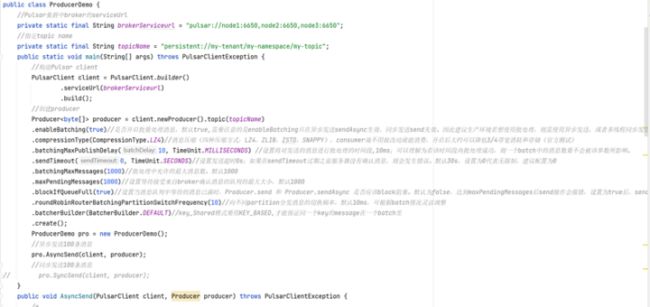
使用Java操作Pulsar: 原生方式模拟生产者代码
总结
1.介绍了目前社区在批流一体上的工作,通过介绍批流不同的执行模式和 JM 节点任务触发的优化改进更好的去兼容批作业;
2.分析现有的 Checkpoint 机制痛点,在新版本中如何改进,以及在大规模作业调度优化和细粒度的资源管理上面如何做到对性能优化;
3.介绍了 TableSQL API 和 Pyhton上相关的性能优化。
4.旧的表/SQL 规划器已被删除。不再支持 BatchTableEnvironment 和DataSet API与Table API 互操作。将统一的TableEnvironment与新的规划器或 DataStream API 在批处理执行模式下用于批处理和流处理。
5.对 Apache Mesos 的支持已被删除