【c++ 学习笔记】string 类的模拟实现
目录
- 写一个简单的 string 类
-
- string 类的框架
- string 类的构造函数
- string 类的拷贝构造函数
- string 类的赋值运算符重载
- string 的遍历
- string 类的析构函数
- 返回c形式的字符串
- 重载 operator[ ]
- string 类比较大小
- reserve 扩容实现
- resize 实现
- string 尾插数据
- string 的 += 实现
- 在某个位置插入 insert
- 在某个位置删除 erase
- swap
- find
- clear
- 流插入
- 流提取
写一个简单的 string 类
string 类是一个可以动态增长的字符数组,其实就相当于是存储字符的顺序表。接下来我们自己写一个 string 类,注意需要自己定义一个命名空间和库里面的 string 类进行隔离。
string 类的框架
#pragma once
//避免和库里面的string冲突,这里用命名空间和库进行隔离
namespace potato
{
class string
{
public:
//成员函数
private:
char* _str; //动态开辟的数组指针
size_t _size; //数组的有效字符个数
size_t _capacity;//数组的容量
};
}
string 类的构造函数
这里主要实现了无参构造函数和带参构造函数:
//string有很多构造函数,这里只实现最重要的几个构造函数
//无参构造函数
string()
:_str(new char[1])
,_size(0)
,_capacity(0)
{
_str[0] = '\0';
}
//带参的构造函数
string(const char* str)
//因为初始化列表按照声明的顺序初始化,为了避免后续出错这里只初始化_size
:_size(strlen(str))
{
_capacity = _size;
//这里的_capacity是指能够存储多少有效字符(算上'\0'),所以这里需要多开辟一个空间
_str = new char[_capacity + 1];
strcpy(_str, str);
}
注意需要多开一个空间来存储 \0 标识字符,标识字符不算是 string 类的有效字符,给 _size 和 _capacity 都赋好初值后,借助 strcpy 函数来拷贝字符串。
但是一般可以使用缺省参数的形式,将上面的代码进行进一步的简化。
//注意这里不能使用nullptr,因为strlen()遇到\0才终止,需要进行解引用,而不能对空指针进行解引用
//这里可以什么都不写,默认最后以\0结束
string(const char* str = "")
:_size(strlen(str))
{
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
string 类的拷贝构造函数
这里需要自己用深拷贝实现一个拷贝构造函数,防止浅拷贝带来的一些问题
//拷贝构造函数
string(const string& s)
//拷贝构造函数的初始化列表
:_size(s._size)
,_capacity(s._capacity)
{
_str = new char[s._capacity + 1];
strcpy(this->_str,s._str);
}
string 类的赋值运算符重载
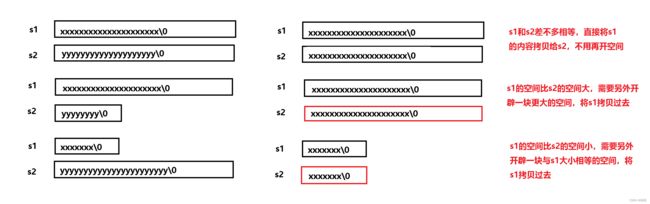
赋值和拷贝构造的区别是,拷贝构造是用一个对象去初始化另一个对象,赋值是两个已经存在的对象。赋值重载需要考虑三种情况:
可以直接释放旧空间,然后重新开辟新空间再赋值。
//operator=
//operator=
string& operator= (const string& s)
{
//需要判断是否是自己给自己赋值
if (this != &s)
{
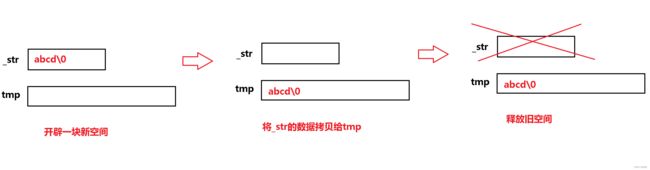
//先开辟一块空间
char* tmp = new char[s._capacity + 1];
//将_str内容拷贝给tmp
strcpy(tmp, s._str);
//将this指向的旧空间释放掉
delete[] _str;
//让_str指向新开辟出来拷贝了s值得tmp空间
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
string 的遍历
注意看以下代码:
//返回c形式的字符串
const char* c_str()
{
return _str;
}
//重载operator[],返回pos位置字符的引用
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos)const
{
assert(pos < _size);
return _str[pos];
}
size_t size()const
{
return _size;
}
//这里使用引用传参并用const修饰,防止实参被改变
void Print(const string& s)
{
for (size_t i = 0; i < s.size(); ++i)
{
std::cout << s[i] << " ";
}
std::cout << std::endl;
}
void test()
{
string s1("Hello World");
for (size_t i = 0; i < s1.size(); ++i)
{
s1[i]++;
}
std::cout << std::endl;
Print(s1);
}
由于 Print 函数中传过来的 s 是 const 修饰的对象,而 const 对象不能调用非 const 成员函数。所以这里需要将 size() 函数形参加 const 修饰。这样普通对象和 const 修饰的对象都可以调用 size() 函数。
而同理 operator[ ] 也需要加 const 修饰。但是 operator[ ] 加 const 修饰后,虽然满足了 Print 函数的要求,但是 test 函数中的 s1[ i ] ++ 又会报错。
所以这里还需要进行函数重载。一个是给普通对象调用,允许修改,一个是给 const 对象调用,不允许修改。
还可以用迭代器的方法去实现:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + size();
}
string::iterator it = s1.begin();
while (it != s1.end())
{
std::cout << *it << " ";
++it;
}
std::cout << std::endl;
图示如下:
>注意迭代器也需要重载两个版本,如下面代码:
void Print(const string& s)
{
for (size_t i = 0; i < s.size(); ++i)
{
std::cout << s[i] << " ";
}
std::cout << std::endl;
string::iterator it = s.begin();
while (it != s.end())
{
(*it)--;
++it;
}
std::cout << std::endl;
}
注意这里不能这样使用迭代器,因为 const 对象不能调用非 const 成员函数。所以还需要重载一份 const 迭代器。
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + size();
}
iterator begin()const
{
return _str;
}
iterator end()const
{
return _str + _size;
}
注意 const 迭代器就像指针的 const,可以修改本身,但是不能修改指向的内容。 其特点就是指向的内容只能读不能写。
string 类的析构函数
析构函数如下:
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity - 0;
}
返回c形式的字符串
返回数组首元素的地址
//返回c形式的字符串
const char* c_str()
{
return _str;
}
重载 operator[ ]
//重载operator[],返回pos位置字符的引用
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
string 类比较大小
逐个比较两个 string 对象的 ASCⅡ 值。
不修改成员变量数据的函数,最好加上const修饰
bool operator> (const string& s)const
{
return strcmp(_str, s._str) > 0;
}
bool operator== (const string& s)const
{
return strcmp(_str, s._str) == 0;
}
bool operator>= (const string& s)const
{
return *this > s || *this == s;
}
bool operator< (const string& s)const
{
return (!(*this>=s));
}
bool operator<= (const string& s)const
{
return (!(*this > s));
}
bool operator!= (const string& s)const
{
return (!(*this == s));
}
reserve 扩容实现
开辟新空间,将旧空间的数据拷贝到新空间,然后释放旧空间,指针指向新空间。
void reserve(size_t n)
{
//先开辟新空间
//开辟的新空间需要多开一个给\0
//需要考虑缩容的情况
if(n > _capacity)
{
char* tmp = new char[n + 1];
//再将数据进行拷贝
strcpy(tmp, _str);
//释放旧空间
delete[] _str;
_capacity = n;
}
}
resize 实现
resize 的作用就是开辟空间加初始化。而 resize 不会进行缩容,因为缩容也会有代价,将原来的空间还给操作系统,不能还一部分,而是需要还整块空间,所以这里 resize 只会改变 _size,不会改变 _capacity,而且只初始化未被初始化的那部分数据。resize 需要分情况进行判断。
代码如下:
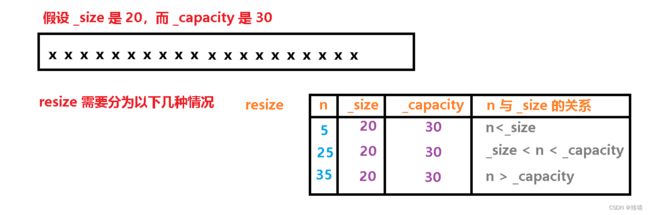
//需要分三种情况进行讨论
void resize(size_t n, char ch = '\0')
{
if (n <= _size)
{
//保留前 n 个数据
_size = n;
_str[_size] = '\0';
}
else
{
//如果n > _capacity 就进行扩容
if (n > _capacity)
{
reserve(n);
}
//让_size ~ n 这段区间填上字符ch
size_t i = _size;
while (i < n)
{
_str[i] = 'ch';
++i;
}
_size = n;
_str[_size] = '\0';
}
}
string 尾插数据
插入单个数据就进行二倍扩容或者一点五倍扩容,如果插入一个字符串,需要多少空间就开辟多少空间。示例代码如下:
void push_back(char ch)
{
//扩容
if (_size + 1 > _capacity)
{
reserve(_capacity * 2);
}
_str[_size] = ch;
++_size;
}
void append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
string 的 += 实现
string& operator+= (char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
在某个位置插入 insert
在 pos 位置插入一个字符代码如下:
//在pos位置插入一个字符串
void insert(size_t pos, char ch)
{
assert(pos <= _size);
//下面这种写法当pos为0会出问题,因为_size是无符号整型,
//减到零再减一是最大正数,导致while会无限循环
//size_t end = _size;
//while (end >= pos)
//{
// _str[end - 1] = _str[end];
// --end;
//}
if (_size + 1 > _capacity)
{
reserve(_capacity * 2);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
}
在 pos 位置插入一个字符串,代码如下:
void insert(size_t pos, const char* str)
{
assert(pos <= _size);
//判断向后挪动几个数,存到len中
size_t len = strlen(_str);
//挪动数据
//注意这里应该是pos+len-1而不是pos+len
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
}
//拷贝插入
//不能用strcpy,因为strcoy会将\0也拷贝进去
//所以这里使用strncpy
strncpy(_str + pos, str, len);
_size += len;
}
在某个位置删除 erase
erase 删除的时候也需要考虑以下几种情况:
代码如下:

void erase(size_t pos, size_t len = npos)
{
//如果 len == npos 或者 pos + len >= _size 就全删
//因为 npos 是最大值,这里如果不加 len == npos 判断,pos + len 会溢出
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
//删一部分,需要挪动数据覆盖
else
{
//strcpy是从前往后覆盖
strcpy(_str + pos, _str + pos + len);
_size -= pos;
}
}
swap
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
find
//支持从某个位置开始找,如果不加第二个参数,就从0位置开始找
size_t find(char ch,size_t pos = 0)
{
for (size_t i = pos; i < _size; ++i)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
clear
void clear()
{
_str[0] = '\0';
_size = 0;
}
流插入
std::ostream& operator<<(std::ostream& out, const potato::string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}
流提取
c++ 缓冲区保存键盘输入的数据,流提取去缓冲区里拿数据。而空格和换行不进入缓冲区,因为如果正常输入多个字符,中间以空格或者回车做分隔符,cin 不会拿到空格或者换行的数据,只把空格或换行当成多个数据的间隔。
所以需要使用 get 成员函数来拿到空格或换行。
缓冲区里面也会有空格和换行,但是 cin 在缓冲区里拿数据的时候会默认空格和换行是多个数据之间的间隔,会忽略空格和换行,所以需要用 get。
istream& operator>>(istream& in, const string& s)
{
//如果s里面原来有数据,需要清除之前的数据再进行流提取
s.clear();
//这里需要避免认为‘ ’或\0为输入多个字符之间的间隔,而不是结束标志
//需要用到get函数,可以拿到任何一个字符
char ch = in.get(); //在流对象缓冲区里面取ch
in >> ch;
while (ch != ' ' && ch != '\n')
{
s += ch;
in >> ch;
}
return in;
}
如果插入的字符串很长,+= 是二倍扩容,字符串太长可能需要频繁的扩容,可以通过另一种方式解决这个问题,如果用 reserve,则并不知道到底需要多大的容量合适。所以这里使用以下方式进行修改:
istream& operator>>(istream& in, const string& s)
{
s.clear();
char ch = in.get();
char buff[128];
size_t i = 0;
while (ch !+ ' ' && ch != '\n')
{
//输入的是有效字符,将其放入buff[i]的位置
buff[i++] = ch;
//如果填满了(需要考虑\0)
if (i == 127)
{
//在 127 位置填 \0
buff[127] = '\0';
//每填满一次,就扩充buff大小的空间
s += buff;
i = 0;
}
ch = in.get();
}
//如果没有填满buff
if (i != 0)
{
//buff的i位置填\0
buff[i] = '\0';
//将buff内的几个数放到s中
s += buff;
}
return in;
}