pg 崩溃恢复篇(一)—— WAL的作用与全页写机制
WAL(Write Ahead Log)机制最初在7.1版中实现,以减轻服务器崩溃的影响。它也是基于时间点恢复(PITR)和流复制(SR)实现的基础。WAL机制非常复杂,在第一篇中,我们只看看为什么需要WAL,它有什么作用,又会有什么不足。
一、 没有WAL的插入操作
要看为什么需要有WAL,那就先看看如果没有会怎么样。
假设我们TABLE_A中插入一些数据,这些数据没有使用WAL功能,如图: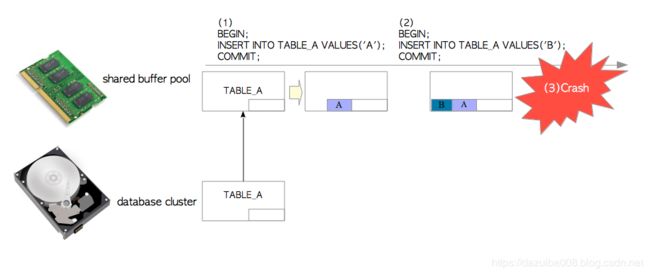
(1)发出第一个INSERT语句:
PostgreSQL将TABLE_A的页面从数据库文件加载到共享缓冲池中,并将一个元组插入到页面中。此页面不会立即写入数据库文件(修改后的页面称为脏页)。
(2)发出第二个INSERT语句:
PostgreSQL在缓冲池的页面中插入一个新的元组。此页面也不会立即写入数据库文件。
(3)系统崩溃:
此时所有插入的数据都将丢失。
因此在系统故障时,没有WAL的数据库系统是很脆弱的。
二、 插入操作和数据库恢复
为了解决上述问题,并且不过于影响性能,pg支持了WAL。将所有修改作为历史数据写入持久化存储,以备故障时使用,这些历史数据称为XLOG或WAL记录。
当增删改等变更操作发生时,pg会将xlog记录写入内存中的WAL缓冲区。当事务提交/回滚时,立即把WAL缓冲区中内容写入磁盘。XLOG记录的LSN(日志序列号,被用作XLOG记录的唯一标识符)标志记录在事务日志中的位置。
pg崩溃恢复的起点是哪里?答案是重做点(REDO point),即最新的检查点开始时xlog记录写入的位置。
1. 带有WAL的元组插入
也可参考此ppt https://www.slideshare.net/suzuki_hironobu/fig-902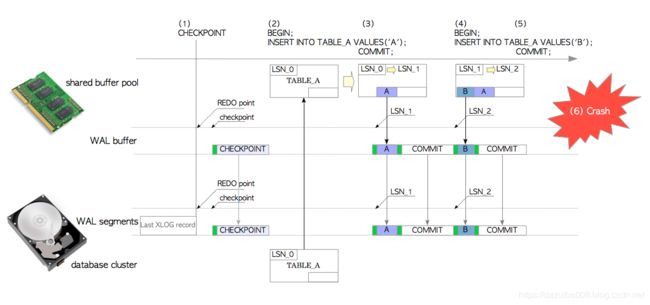
(1)checkpointer后台进程定期执行检查点:
每当checkpointer启动时,会将一条名为checkpoint record的XLOG记录写入当前WAL段。此记录包含最新重做点位置(最新的检查点开始时xlog记录写入的位置)。
(2)发出第一个INSERT语句:
- pg将TABLE_A的数据页从数据库文件加载到共享缓冲池中
- 向该页中插入一个元组
- 向WAL缓冲区LSN_1位置写入一条的相应xlog记录。在本例中,XLOG记录是头数据+整个元组(a pair of a header-data and the tuple entire)
- 将TABLE_A的LSN从LSN_0更新到LSN_1
(3)当此事务提交时:
创建并向WAL缓冲区写入一条commit相应记录。
将WAL缓冲区中的从LSN_1开始的所有XLOG写入WAL文件中。
(4)发出第二个INSERT语句:
继续向该页中插入一个新元组
向WAL缓冲区LSN_2位置写入一条的相应xlog记录
将TABLE_A的LSN从LSN_1更新到LSN_2
(5)当此事务提交时:
PostgreSQL以与步骤(3)相同的方式操作。
(6)系统崩溃:
即使共享缓冲池中的所有数据都丢失,但因为页面的所有修改都已作为历史数据写入WAL段文件,这些修改可以恢复回来。
2. 带有WAL的崩溃恢复
以下将说明如何将数据库恢复到崩溃之前的状态。不需要任何特殊操作,重启pg时会自动进入恢复模式,pg会从重做点开始顺序读取和重放相应WAL文件中的XLOG记录。
也可参考此ppt https://www.slideshare.net/suzuki_hironobu/fig-903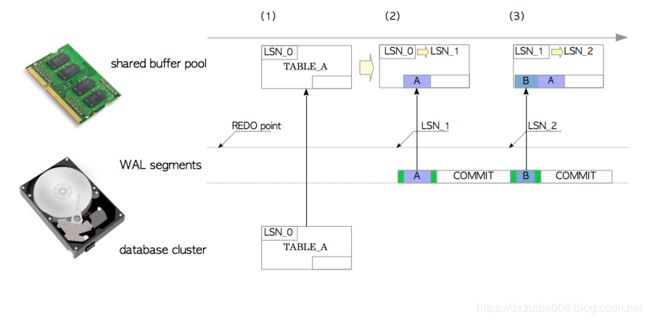
(1)PostgreSQL从相应的WAL文件中读取第一个INSERT语句的XLOG记录,并将TABLE_A的页面从数据库文件加载到共享缓冲池中。
(2)在重放XLOG记录之前,pg会比较XLOG记录的LSN和相应页面的LSN。重放XLOG记录的规则如下:
如果XLOG记录的LSN大于页面的LSN(xlog中数据较新,还写入到数据文件),则XLOG记录中的数据部分将插入页面,并将页面LSN将更新为XLOG记录的LSN。
如果XLOG记录的LSN较小(数据文件已是最新数据),不用做任何操作,直接读取下一个WAL数据
在本例中,XLOG记录需要被重放,因为XLOG记录的LSN(LSN_1)大于TABLE_A的LSN(LSN_0)。重放后,将TABLE_A的LSN从LSN_0更新为LSN_1。
(3)pg按照同样的方式重放其余XLOG记录。
pg可以通过按时间顺序重放在WAL段文件中的XLOG记录自我恢复,因此pg中的XLOG记录显然是一种REDO日志。
三、 全页写
是不是只要按上面的方式写入WAL就一定不会有问题呢?
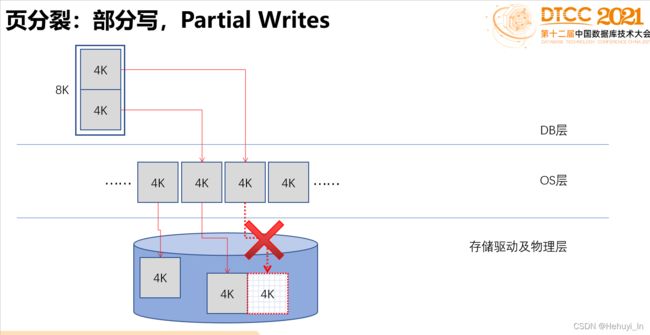
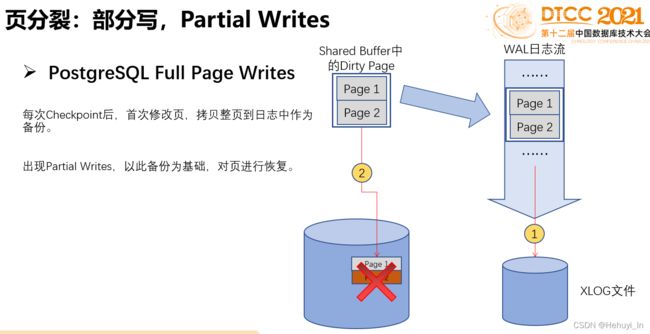
1. 部分写问题
PG数据页写入是以page为单位,每个page默认大小为8K,而操作系统数据块是4K(操作系统每次写入4k),在断电等情况下,极有可能部分pg数据页只写到4K系统就已经崩溃。此时pg数据页中就一半是新写入的数据,一半是还没来得及写入的旧数据,这称为部分写问题。这种数据页可以看作是损坏的,在崩溃恢复时,由于XLOG记录无法在损坏的页面上重放,它无法完全恢复该页。因此,我们需要一个额外附加的功能。
2. 全页写
pg支持一种称为全页写的功能来处理部分写问题。如果启用(默认启用),pg会在每个检查点之后、每个页面第一次发生变更时,将头数据和整个页面作为一条XLOG记录写入WAL缓冲区。在pg中,这种包含整个页面的XLOG记录称为备份块或全页镜像 (backup block or full-page image)。
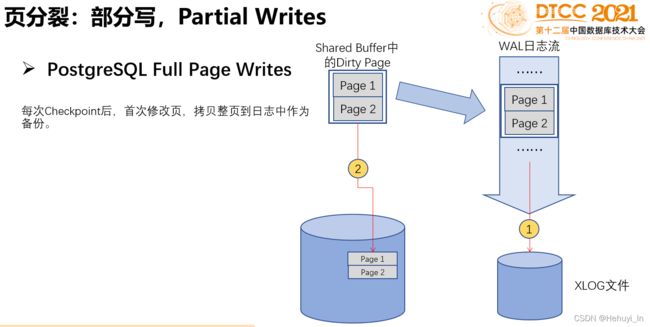
3. 启用全页写的插入
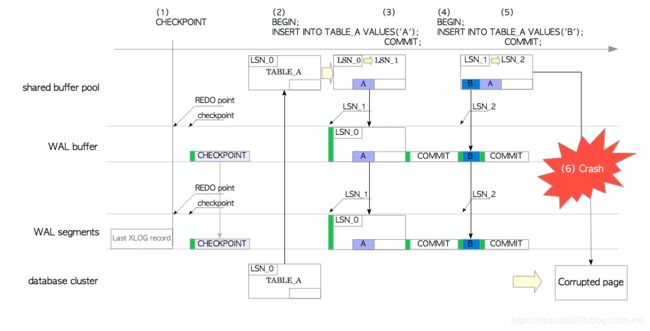
(1)检查点启动一个检查点进程。
(2)在第一个INSERT语句插入时,与前一个小节中的操作几乎相同,但此时XLOG记录的是头数据+整个页面的备份块(它包含整个页面而不仅是插入的元组),因为这是在最新的检查点之后首次写入这个页面。
(3)当此事务提交时,PostgreSQL的操作方式与前一小节相同。
(4)在第二个INSERT语句插入时,PostgreSQL的操作方式与上一小节完全相同,此时XLOG记录只是头数据+插入的元组,而不是备份块。
(5)当此事务提交时,PostgreSQL的操作方式与前一小节相同。
(6)为了说明全页写的效果,我们假设:当bgwriter向数据文件写入数据时发生操作系统故障,磁盘上TABLE_A的页面发生部分写问题,已被破坏。
4. 启用全页写的崩溃恢复
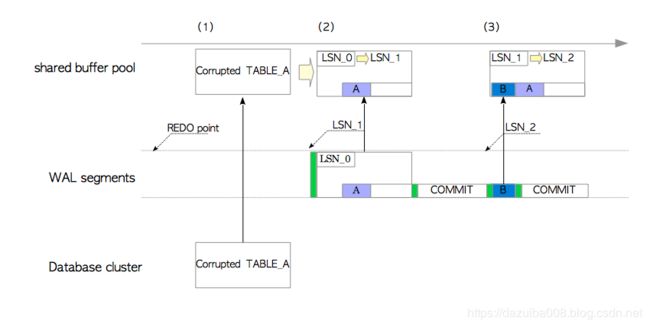
(1)pg读取第一个INSERT语句的XLOG记录,并将损坏的TABLE_A页面从数据库文件加载到共享缓冲池中。在此例中,XLOG记录是备份块,根据全页写规则,每个页面的第一个XLOG记录始终是备份块。
(2)当XLOG记录是备份块时,会使用另一个重放规则:XLOG记录的数据部分(即页面本身)会直接覆盖当前页面而不去比较LSN值,并且页面的LSN更新为XLOG记录的LSN。
在此示例中,pg使用XLOG中记录的数据部分覆盖了损坏的页面,并将TABLE_A的LSN更新为LSN_1。通过这种方式,损坏的页面可以通过它自己的备份块恢复。
(3)第二个XLOG记录是非备份块,pg的操作方式与前一小节中的操作方式相同。
此时,即使发生了一些数据写入错误,也可以恢复pg。当然,如果发生的是文件系统或介质故障,就不能恢复了。
5. 全页写的不足和优化
full_page_write需要在xlog中记录整个数据页,会写更多xlog文件,不仅有数据变化信息,还有数据页本身信息,这会额外增加IO和磁盘消耗,同时也会引起主备延迟变大。

为了优化full_page_write,社区提供了一个类似MySQL的双写patch,它的主要设计是创建两个共享内存块队列,checkpoint专用buffer队列和非checkpoint专用buffer队列,同时关闭full_page_write。当用户DML产生的数据buffer需要刷盘时,并不是立即刷到磁盘,而是先进入double write的buffer队列,当buffer队列满时,则将buffer队列里面的数据首先刷到特别的double write文件,然后再将数据刷到数据库文件。
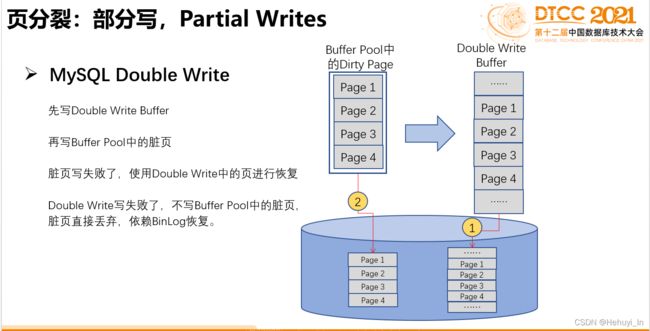
通过这种设计就不需要在checkpoint 之后在对数据页面的第一次写的时候会将整个数据页面写到 xlog 里面。当数据库需要恢复的时候,遍历所有double write文件里面的记录块,找到每个记录块对应的数据库page,然后对这个page进行checksum,如果page损坏,那么直接把记录块里面的内容覆盖到buffer数据。最后把double write文件删除,重新初始化buffer队列。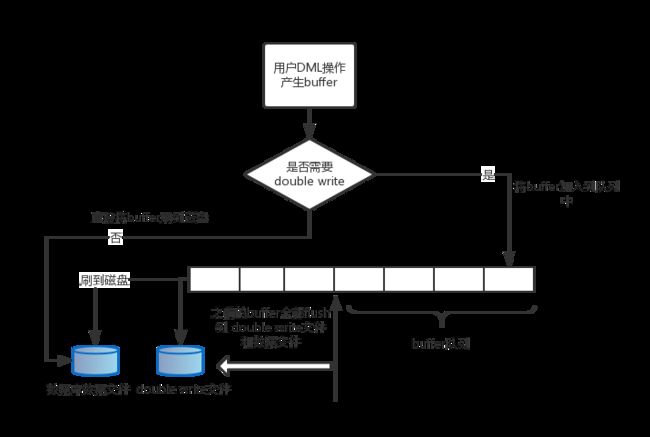
参考
The Internals of PostgreSQL : Chapter 9 Write Ahead Logging — WAL
Postgresql管理系列-第九章 WAL(Write Ahead Logging)介绍_魂醉的博客-CSDN博客
PgSQL · 特性分析 · full page write 机制