C++模板
文章目录
- 前言
- 一、模板初阶
-
- 1.1、函数模板
- 1.2、隐式实例化 && 显式实例化
- 1.3 模板参数的匹配原则
- 1.4、类模板
- 二、模板进阶
-
- 2.1 非类型模板参数
- 2.2 模板的特化
- 2.3 模板的分离编译
- 三、模板的优缺点
前言
C++的每一个feature都有它的理由。在C语言中,我们如何实现两个数的交换呢?
我们写如下函数:
void swap1(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
但是,我没说是交换什么类型的数。如果我说交换double型的数怎么办?好吧,再写一份,
void swap2(double* p1, double *p2)
{
double tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
But,我又像交换两个char型数据怎么办?难道要再写一份swap3代码吗?我们会发现,这些代码有大量重复,写这样的代码简直是浪费时间。而为了解决这个问题,模板应运而生。
一、模板初阶
模板是泛型编程很好的体现,在EffectiveC++中,作者在第一个条款中就明确指出模板是C++必不可少的部分。而模板就是写与类型无关的代码,你给编译器一个模型,它会按照你的需求和模板来生成代码。
1.1、函数模板
模板解决了部分的代码重复性问题,它能允许不同类型的代码拥有一样的编写方式。
// template 与下面的都行
template<class T1, class T2>
void swap(T1& x1, T2& x2)
{
T tmp;
tmp = x1;
x1 = x2;
x2 = tmp;
}
swap(1,1);
swap(1.11,2.22);
swap('a','b');
注意,这里的T1,T2是类型,而我们传的是参数,编译器是按照变量去推导类型。
编译器会在编译阶段(预处理阶段)按照你的需求生成对应的函数,这个过程叫做模板的实例化。编译器不是去调用我们所写的模板,而是去调用根据模板实例化出的函数。模板本身并不会被编译成机器指令。想象一下,印刷厂用模板印刷书,你要的是书而不是板子。
1.2、隐式实例化 && 显式实例化
考虑这样一个模板函数,
template<class T>
T Add(const T& x1, const T& x2)
{
return x1 + x2;
}
//这样调用
int i1 = 0, i2 = 1;
double d1 = 1.11;
Add(i1, i2); //没问题,编译器会自动推导出T的类型为int,这是隐式实例化
Add(i1, d1); //有问题,编译器推导出int和double,矛盾
怎么办呢?可以这样,
Add(i1, (int)d1); //强转一下
Add<int>(i1, d1); //显式实例化,隐式将di转换成int。
函数模板才有隐式实例化,实际上类模板都是显示实例化。
1.3 模板参数的匹配原则
模板函数允许与自己同名的函数存在,并且还可以实例化为的函数。
template<class T1, class T2>
void swap(T1& x1, T2& x2)
{
T tmp;
tmp = x1;
x1 = x2;
x2 = tmp;
}
void swap(int& x1, int& x2)
{
int tmp;
tmp = x1;
x1 = x2;
x2 = tmp;
}
int a = 0, b = 1;
swap(a,b); //调用非模板的swap
swap<int>(a,b); //调用模板实例化出来的swap。
1.4、类模板
类模板和函数模板大抵相同,想一想在C语言中,我们写一个栈的数据结构,如果我们想要两个栈,int和double的,C根本无法解决,除了再写一份,这简直太蠢了。有了模板就可以解决。
template<class T>
class stack
{
//...
};
stack<int> st; //这样生成
函数模板允许与自已同名的普通函数存在,但是类模板不行。
template<class T>
void Fun() //模板函数
{}
void Fun() //普通函数
{}
template<class T>
class A //一旦A作为模板,就不允许再出现普通的类A
{};
class A //这个不被允许
{};
二、模板进阶
2.1 非类型模板参数
模板不仅仅支持类型参数,还支持非类型模板参数,stl库里面的array就是很好的体现。

template<class T, size_t N>
class array
{
public:
array()
{
// N = 10; //这一步编译不通过,因为N被认为是常数.
}
private:
T _a[N]; //这里将N作为一个常数,否则不能这样定义数组
};
//这样使用
array<int, 100> a1;
array<int, 1000> a2;
这里的N是个常数
注意:浮点数、类对象、字符串不可以做非类型模板参数;非类型的模板参数必须在编译期就能确认结果。
实际上,模板参数也可以带有缺省值。
//类模板缺省
template<class T = int, size_t N = 100>
class array
{//...};
array<int> a1; //缺省N
array<> a2; //全缺省,但是尖括号不能省略,只是很少这样写。
函数模板缺省
template<class T = int, size_t N = 100>
void Func()
{
T t;
cout << typeid(t).name() << endl;
cout << N << endl;
cout << "模板函数" << endl;
}
void Func()
{
cout << "非模板函数" << endl;
}
Func(); //这会去调用非模板函数
Func<>(); //去调用模板函数,且全缺省
Func<double>(); //模板函数,缺省掉N
Func<double, 200>(); // 正常的模板函数
2.2 模板的特化
模板可以写与类型无关的代码,这虽然很好,但有时候模板有点强大的过头了:
template<class T>
bool isEqual(const T& lhs, const T& rhs)
{
return lhs == rhs;
}
上面是一个判断两个同类型的变量是否相等的模板函数,如果我们传入普通的两个整型,结果确实如我们所愿。但是如果我们传入两个指针呢?像这样,
const char* p1 = "hello";
const char* p2 = "world";
bool ret = isEqual(p1,p2); //ret是true 还是 false ?
在这个栗子中,我传入的是char*的指针,那么isEqual只会拿指针的地址去做比较,是的,结果也是false,但是这并不是我们想要的,我们想的是
return “hello” == “world”; 而编译器做的确是,return p1 == p2;这时候我们就需要对字符指针类型做出特殊处理,这叫做模板的特化。
模板特化自然也有许多条件 ,我们在栗子中进行讲解。
template<class T>
bool isEqual(const T& lhs, const T& rhs)
{
return lhs == rhs;
}
template<> //特化一个char*版本的
bool isEqual<char*>(char* lhs, char* rhs)
{
return strcmp(lhs, rhs) == 0;
}
类的模板特化大抵相同,只需在类名后边加上<特化类型>就可以。
1 \可以看到几个显然的特点,你想要特化,得有原来的模板即你想要特化的那个模板得存在,不能只有特化版本.
2 \模板的template里面的参数缺省保留<>,函数名后面加上<>,且里面是特化的类型。
3 \函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误.
但是,这个特化很鸡肋,一般情况下,函数模板遇到不能处理或者处理有误的类型时都是直接给出该类型的函数。
特化也分为全特化和偏特化。全特化很简单,就是所有的模板参数都特化。
template<class T1, class T2>
class A
{//...};
template<>
class A<int, char> //关于int和char的特化版本
{//...};
主要来说一下偏特化。可以有单种类型的偏特化,
template<class T1, class T2>
class A
{};
template<class T2>
class A<int, T2> //第一个参数为int的A对象都会用这个类
{};
template<class T1>
class A<T1, char> //同上,第二个参数类型为char的对象用这个类
{};
还可以有指针和引用的特化,
template<class T1, class T2>
class A
{};
template<class T1, class T2>
class A<T1*,T2*> //两个指针的特化
{};
template<class T1, class T2>
class A<T1&,T2&> //两个引用的特化
{};
2.3 模板的分离编译
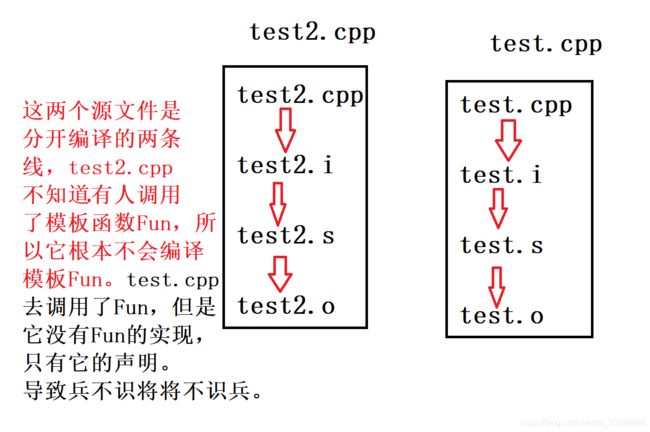
一个项目由多个源文件组成,每个源文件单独编形成目标文件,通过链接将所有目标文件链接在一起形成可执行文件,就称为分离编译。
在项目中我们大多用分离编译,因为这样便于维护代码。我们尝试对模板进行分离编译,将模板的声明写在template.h头文件中,模板的实现写在test2.cpp源文件中,最后将模板的调用写在test.cpp源文件中。但是我们发现编译不过。


编译器会报一个链接错误,那么为什么呢?这时候我们想一想编译器将代码变成可执行程序之前干了什么。
预编译:去掉注释,展开头文件,完成条件编译,宏替换和展开。此时test2.cpp和test.cpp生成test2.i和 test.i两个文件。
编译:检查语法语义,生成符号表,生成汇编代码。test2.i和test.i生成 test2.s 和test.s两个文件。
汇编:将汇编代码翻译成二进制指令,出现test2.o和 test.o两个文件。
链接:将两个源文件链接到一起。
问题就出在链接。我们知道,在编译时函数/类只要求声明就可以编译通过,它会产生一句call Fun(?)的代码,这就好像你去买房问你哥们借钱,他给你你个承诺你就可以去买了。但是真正链接的时候,编译器在符号表里找不到Fun的地址,为什么呢?因为test2.cpp的Fun是个模板!!test2.cpp的编译和test.cpp是分开的,它根本就不知道有函数调用了它,所以它根本不会去编译模板。 这就好像兵不识将,将不识兵。
解决方法是这样的:
在test2.cpp中直接显式的实例化,让它实例化出一份指定的函数/类出来。
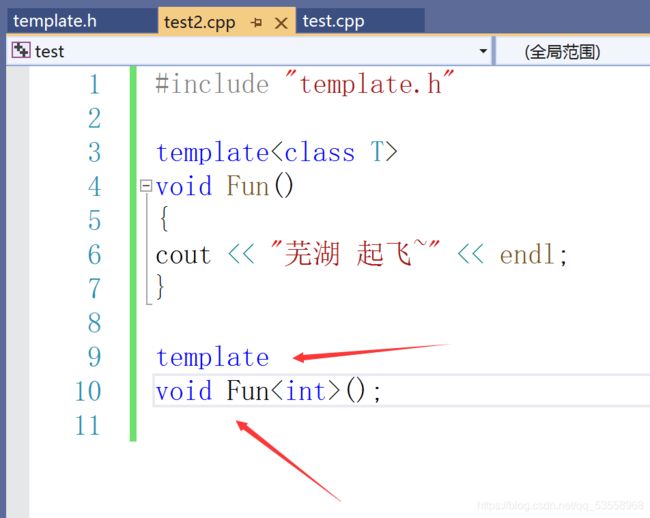
这样的问题也显然易见,只生成了一份int型的,如果我想要double型的呢?我还得再写一个显式实例化,麻烦的一比。
所以我们对于模板,一般不用分离编译。
三、模板的优缺点
优点:
模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
增强了代码的灵活性。
缺点
模板会导致代码膨胀问题,也会导致编译时间变长。
出现模板编译错误时,错误信息非常凌乱,不易定位错误(这点你模板用多了就能感受到痛苦了。)