C语言string.h函数详解及部分模拟实现
文章目录
- string.h函数大全
- 一、字符串函数
-
- 1.1 strlen
-
- strlen模拟
- 1.2 strcpy
-
- strcpy模拟
- 1.3 strcat
-
- strcat模拟
- 1.4 strcmp
-
- strcmp模拟
- 1.5 strncpy
-
- strncpy模拟
- 1.6 strncat
-
- strncat模拟
- 1.7 strncmp
- 1.8 strstr
-
- strstr模拟
- 1.9 strchr/strrchr
-
- 1.9.1 strchr
- 1.9.2 strrchr
- 2.1strspn
- 2.2 strcspn
- 2.3 strpbrk
- 2.4 strtok
- 2.5 strerror
- 二、内存操作函数
-
- 3.1 memset
- 3.2 memcpy
- memcpy模拟
- 3.3 memmove
-
- memmove模拟
- 3.4 memcmp
- 补充(不常用)
-
- 2.6 strcoll
- 2.7 strxfrm
string.h函数大全
string.h是一个C标准库头文件,包含了字符串处理函数、字符分类函数、数值转换函数、内存管理函数等操作字符串的函数。
查询:string.h头文件
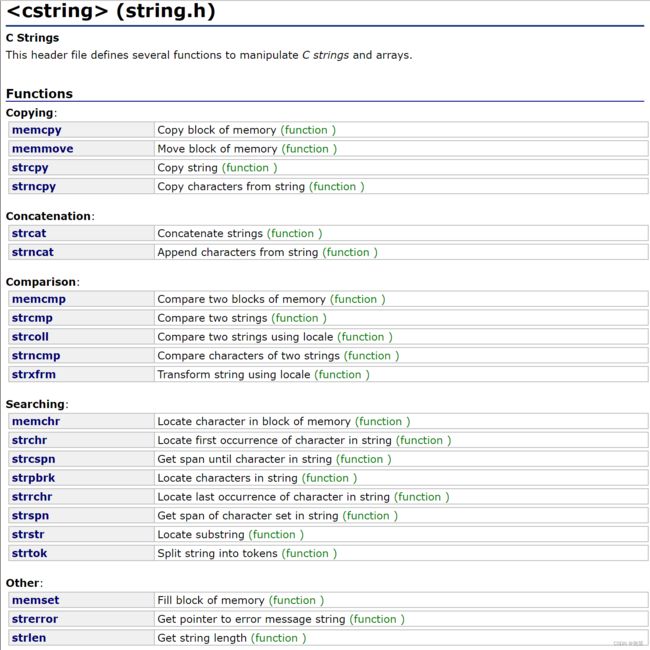
一、字符串函数
1.1 strlen
size_t strlen ( const char * str );
- 功能: strlen函数用于求字符串长度
- strlen函数 以’\0’ 作为结束标志,返回的是在字符串中 ‘\0’ 前面出现的字符个数(不包含 ‘\0’ )
例如:
#define _CRT_SECURE_NO_WARNINGS 1
#include 输出结果:

- 注意函数的返回值为size_t,是无符号的
例如:
#define _CRT_SECURE_NO_WARNINGS 1
#include 很多人第一次做这一题认为输出的是“<”,但实际上:
原因:strlen返回的类型是size_t,也就是无符号整型,无符号整型-无符号整型得到的还是无符号整型,也就是说,它们相减得到的值并不是-3,而应该是:

ps:
1.%zu打印size_t类型;
2.不要将strlen与sizeof混淆,strlen返回字符串长度,sizeof返回数组元素个数。
strlen模拟
#define _CRT_SECURE_NO_WARNINGS
#include 1.2 strcpy
char* strcpy(char * destination, const char * source );
- 功能:复制字符串
- 参数:
destination-指向要复制内容的目标数组的指针
source-要复制的源字符串
注意事项:
-
源字符串必须以 ‘\0’ 结束(必须要有‘\0’);
-
会将源字符串中的 ‘\0’ 拷贝到目标空间;
eg.

调试看看:

的确复制到了‘\0’ -
目标空间必须足够大,以确保能存放源字符串(目标空间要比源字符串空间大);
-
目标空间必须可变(不能是常量字符串);
eg.
char* p="abcdef"; char arr[]="zxy"; strcpy(p,arr);
会报错
strcpy模拟
了解了strcpy如何使用,我们再来试试模拟实现;
前面已经说过,strcpy函数会将‘\0’也复制到目标空间,那么我们就可以认为,strcpy将源函数从起始位置复制到’\0’结束,而复制本身就是覆盖的过程,上代码
#define _CRT_SECURE_NO_WARNINGS
#include 1.3 strcat
char * strcat ( char * destination, const char * source );
- 功能:字符串追加,将源字符串追加到目标字符串之后
注意事项:
- 源字符串必须以 ‘\0’ 结束(同strcpy);
- 目标空间必须有足够的大,能容纳下源字符串的内容(同strcpy);
- 目标空间必须可修改(同strcpy);
- 自己给自己追加字符串:在不同编译器上源码不同,在VS上可以成功,但在其他编译器不一定,因此不推荐使用strcat,推荐使用memmove(下面有讲)。
strcat模拟
strcat怎样模拟?既然是追加,自然要从目标字符串的‘\0’位置开始。代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include 1.4 strcmp
int strcmp ( const char * str1, const char * str2 );
-
功能:比较字符串
-
标准规定:
str1大于第str2,则返回大于0的数字
str1等于str2,则返回0
str1小于str2,则返回小于0的数字
总结:返回值大于0则前面大,小于0则前面小 -
一个误区:
一些初学者认为,哪一个字符串长哪一个就大(大错特错!) -
字符串大小并不是由长度来判断,而是根据字符的ASCII值判断,从两个字符串的第一个字符开始,前面的大就返回大于0的数字,前面的小就返回小于0的数字,相等就比较下一个字符。
-
如果两个字符串相等,则比较到’\0’停止。
例:
#define _CRT_SECURE_NO_WARNINGS 1
#include );
else
printf("str1=str2\n");
}
输出:

strcmp模拟
一个一个比较即可
#define _CRT_SECURE_NO_WARNINGS
#include 1.5 strncpy
刚刚讲的strcpy、strcat、strcmp都是长度不受限制的字符串函数,现在来讲讲长度受限制的字符串函数。
顾名思义,与之前讲的函数相比,接下来讲的几个函数的功能与前面的完全相同,只不过多了一个参数来限制,这大大提高了代码的安全性,避免了越界问题。
char * strncpy ( char * destination, const char * source, size_t num );
注意点:
- 拷贝num个字符从源字符串到目标空间。
- 如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
其他方面与strcpy完全相同,在此就不一一赘述。
strncpy模拟
#define _CRT_SECURE_NO_WARNINGS
#include 1.6 strncat
char * strncat ( char * destination, const char * source, size_t num );
注意点:
- 追加num个字符从源字符串到目标空间。
- 如果源字符串的长度小于num,则追加完源字符串之后,在目标的后边追加0,直到num个。
- 其他同strcat。
例:

strncat模拟
大致思路同strncpy
#define _CRT_SECURE_NO_WARNINGS
#include 1.7 strncmp
int strncmp ( const char * str1, const char * str2, size_t num );
- 比较到出现另个字符不一样或者一个字符串结束或者num个字符全部比较完;
- 其余同strcmp。
例:
#include 1.8 strstr
char * strstr ( const char *str1, const char * str2);
- 功能:字符串查找(在目标字符串中找源字符串);
- 返回str1中第一次出现str2的起始位置的地址,如果str1中找不到str2则返回空指针NULL;
例:
/* strstr example */
#include 运行结果:

返回的地址应该是:

验证一下:
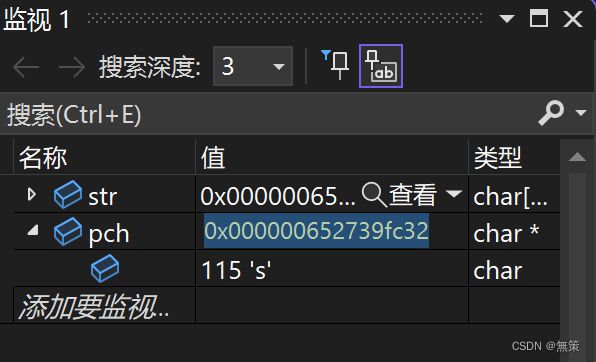
strstr模拟
s1和s2判断字符串是否相等,cp保存目标字符串中的每个元素的地址
#define _CRT_SECURE_NO_WARNINGS
#include 1.9 strchr/strrchr
之所以将这两个函数放在一块,是因为它们的功能都是查找字符。
1.9.1 strchr
const char * strchr ( const char * str, int character );
- 功能:查找一个字符
- 返回第一次出现‘character’字符的地址,如果str中找不到则返回空指针NULL;
- 第二个参数为int型,但在使用时可以写为字符型(转换为ASCII 值)。至于为什么是int,纯粹是由于历史原因。
例:
/* strchr example */
#include 1.9.2 strrchr
const char * strrchr ( const char * str, int character );
- 功能:查找一个字符
- 唯一与strchr的不同点在于,其返回最后<一次出现‘character’字符的地址,如果str中找不到则返回空指针NULL
- 也就是说,strchr是从前往后(从左向右)查找,而strrchr是从后往前(从右向左)查找。
/* strrchr example */
#include 模拟较为简单,不做演示。
2.1strspn
size_t strspn ( const char * str1, const char * str2 );
- 功能:strspn()从参数str1 字符串的开头计算连续的字符,而这些字符都完全是str2 所指字符串中的字符。简单的说,若strspn()返回的数值为n,则代表字符串str1 开头连续有n 个字符都是属于字符串str2内的字符;
- 返回字符串中第一个不在指定字符串中出现的字符下标,也是字符串str1开头连续包含字符串str2内的字符数目。
代码理解:
/* strspn example */
#include 输出:
The initial number has 3 digits.
strtext中,连续3个字符“129”能在cset中找到,故返回3,也是‘t’的下标。
2.2 strcspn
size_t strcspn ( const char * str1, const char * str2 );
- 功能:与strspn完全相反,strcspn()从参数str1字符串的开头计算连续的字符,而这些字符都完全不在参数str2所指的字符串中。简单地说, 若strcspn()返回的数值为n,则代表字符串str1开头连续有n 个字符都不含字符串str2内的字符。
返回值:返回字符串str1开头连续不含字符串str2内的字符数目,或字符串中第一个在指定字符串中出现的字符下标。
用一段代码来解释:
#define _CRT_SECURE_NO_WARNINGS 1
#include 
上述代码中,输出结果为6,因为从s开头到第一个在字母表(letters)中的字符‘e’为止,“12345H”共6个字符不在letters中,故返回值为6,也是‘e’的下标。既然如此,那么,num+1就可以得到s中第一个在字母表中的字符‘e’的位置。
2.3 strpbrk
const char * strpbrk ( const char * str1, const char * str2 );
- 功能:strpbrk函数返回一个指针,它指向字符串str2中的任意字符第一次出现在字符串str1中的位置,如果str1没有与str2中相同的字符,则返回NULL
- 总结:str1从前往后,如果某个字符在str2中出现了,就返回这个字符的地址,直到’\0’就返回NULL。
代码解释:
/* strpbrk example */
#include 输出:
Vowels in ‘This is a sample string’: i i a a e i
2.4 strtok
char * strtok ( char * str, const char * delimiters );
- 功能:字符分割函数,分解字符串为一组字符串。str为要分解的字符串,delim为分隔符字符(如果传入字符串,则传入的字符串中每个字符均为分割符)。
- 首次调用时,str指向要分解的字符串,之后再次调用要把str设成NULL。
- 返回值:从str开头开始的一个个被分割的串的地址。当str中的字符查找到末尾时,返回NULL。
如果查找不到delim中的字符时,返回当前strtok的字符串的指针。
所有delim中包含的字符都会被滤掉,并将被滤掉的地方设为一处分割的节点。 - strtok函数会破坏被分解字符串的完整,调用前和调用后的s已经不一样了。如果要保持原字符串的完整,可以使用strchr和sscanf的组合等。
例:
/* strtok example */
#include 输出:
Splitting string “- This, a sample string.” into tokens:
This
a
sample
string
2.5 strerror
char * strerror ( int errnum );
- 功能:获取指向错误消息字符串的指针
通过标准错误的标号,获得错误的描述字符串 ,将单纯的错误标号转为字符串描述,方便用户查找错误。 - 参数:
errnum:错误标号,通常用errno(标准错误号,定义在errno.h中//自行查阅) - 头文件:
#include
#include
例子:
/* strerror example : error list */
#include 二、内存操作函数
3.1 memset
void * memset ( void * ptr, int value, size_t num );
- 功能:memset是计算机中C/C++语言初始化函数。作用是将某一块内存中的内容全部设置为指定的值, 这个函数通常为新申请的内存做初始化工作。
- 函数解释:将 ptr 中当前位置后面的num个字节(typedef unsigned int size_t )用 value 替换并返回 ptr 。
- 常用于对较大的结构体或数组进行清零操作。
- 常见错误:
1.memset函数按字节对内存块进行初始化,所以不能用它将int数组初始化为0和-1之外的其他值(除非该值高字节和低字节相同)
2.value实际范围应该在0~~255,因为该函数只能取value的后八位赋值给你所输入的范围的每个字节
/* memset example */
#include 输出:
------ every programmer should know memset!
3.2 memcpy
void * memcpy ( void * destination, const void * source, size_t num );
- 功能:同strncpy,不过不局限于字符串。函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
- 这个函数在遇到 ‘\0’ 的时候并不会停下来。
- 如果source和destination有任何的重叠,复制的结果都是未定义的。
memcpy模拟
#include 3.3 memmove
void * memmove ( void * destination, const void * source, size_t num );
- 功能:同memcpy
- 和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
- 如果源空间和目标空间出现重叠,就得使用memmove函数处理(原理见模拟)
memmove模拟
为什么源空间和目标空间出现重叠用memmove,这是因为在其他函数中,前面已经被覆盖的位置会再次拿来被使用,如下面的代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include 这里的理想结果应该是“121234589”,但实际上却是“121212189”(当然VS上函数优化过可行,但其他编译器不能保证),因为复制到第三个字符时,已经将第3,4个字符修改为‘1’,‘2’,所以会循环往复。
那改怎么修改呢?
先复制要被改的内容
如果目标位置在起始位置后,就从后往前复制
如果目标位置在起始位置前,就从前往后复制
#define _CRT_SECURE_NO_WARNINGS
#include 3.4 memcmp
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
- 功能:同strncmp,比较从ptr1和ptr2指针开始的num个字节(不局限于字符串)
- 返回值如下:

例:
/* memcmp example */
#include memcmp模拟根据strncmp仿照memcpy即可。
补充(不常用)
2.6 strcoll
int strcoll ( const char * str1, const char * str2 );
- 说明:
默认情况下(LC_COLLATE为"POSIX"或"C")和strcmp一样根据ASCII比较字符串大小。
对于设置了LC_COLLATE语言环境的情况下,则根据LC_COLLATE设置的语言排序方式进行比较。例如:汉字,根据拼音进行比较。 - 用法:同strcmp。
2.7 strxfrm
size_t strxfrm ( char * destination, const char * source, size_t num );
- 功能:strxfrm()函数把字符串 src 转换成另外 一种形式,用 strcmp() 来比较两个转换后的字符串 与用 strcoll() 来比较它们转换前的字符串 的返回值是一样的。转换后的字符串的前n个字符会存放于 dest 中。 它是根据程序 当前的区域选项中的LC_COLLATE来转换的。
- 返回值:返回值转换后的字符串的长度,不包括终止的null字符。
- 注意:如果区域选项是 “POSIX” 或者 “C”, 那么 strxfrm() 同用 strncpy() 来 拷贝字符串是等价的。
ps:可能有人发现后面没有前面详细了,那是因为实在肝不动了…
感谢支持,欢迎指正