从裸机启动开始运行一个C++程序(一)
前言
对于一个C++程序员来说,可能更多是是每天都在跟各种上层语义、设计模式、软件方法等等在打交道。但对于「一个C++程序是如何运行在机器上的」这件事可能会比较陌生。有时,遇到一些问题,在宏观角度看起来可能比较难以解释,但其实从底层出发,就能发现这个问题其实根本不算问题。类似的问题有:
- 空指针到底能不能访问?(
int *p = nullptr; *p = 5;) - 给一个变量取地址,取到的是不是物理地址?(
int a; std::cout << &a;) - 操作一个常数地址是否合法?(
*(int *)0xa0000 = 0x41;) - 全局变量、静态局部变量、字符串字面量等在内存中是如何布局的?
- C/C++程序如何编译为内核代码,运行在内核态程序上?
- gdb过程中,看到的寄存器是否是真实的?
上面这些疑问,有一些是被读者问到的,还有一些是笔者曾经思考过,但没有很快解决的。与此同时,笔者发现,中层、通用性的教程比比皆是,但高层和底层的、专精型的教程却是少之又少。很多问题可能其实很简单,但就是搜不到相关的教程。笔者也曾尝试到一些系统讲解底层的书籍中寻找答案,但也发现,它们在各自突出的领域中讲解地很详细,但对于上下层串联的部分却总是有缺失,导致各个领域的知识是破碎的,难以关联在一起,以建立一个更加宏观的体系。
于是在经过了一系列研究和实验之后,笔者决定起笔这一个系列的文章。在这个系列文章中将会介绍:
- x86体系的结构和启动过程
- 如何编写一个简单的MBR(Master Boot Record),然后进入内核程序
- 如何从用C/C++来生成内核程序(包括编译、链接、转载的方法)
- 站在内核的角度看到的内存结构是怎样的
- C/C++程序的内存分布是怎样的,各部分加载到内存中的形态是怎样的
- C代码和C++代码编译方式的异同
关于本系列文章,有以下几点说明:
- 本文的底层逻辑以x86体系为例,C/C++代码也会生成x86体系的机器码。
- 虽然我们的项目是x86架构的,但即便你使用的是ARM架构的设备(例如搭载苹果自研M系列芯片的Mac)也没有关系,笔者会介绍可以在ARM版macOS上编译和运行x86程序的方法,会使用跨平台运行的模拟器。
- 本文使用到的工具都是业界通用的、能轻易在网上下载到并且很容易找到对应说明文档的软件,不会使用笔者自研的黑盒程序,并且会详细介绍每一种工具的部署、使用方法,保证读者可以完成实验
- 对于一些历史发展历程,和一些历史遗留问题的诞生,笔者会花一部分篇幅来「讲故事」,如果读者不感兴趣,则可以跳过相关的篇幅,直接看结论即可。
如果你准备好了的话,我们马上开始!
x86体系架构
相信读者对x86这个词肯定不陌生,那么它到底指的是什么呢?
指令集
对于一个CPU来说,其实就是一个高集成的逻辑电路。如果你玩过数字电路的话,一定会知道所谓的「与」「或」「非」门电路,用这些门电路组合起来,我们就可以实现更多更复杂的功能。
不过逻辑电路再复杂,无非也就是把「一组输入的电信号」转换为「一组输出的电信号」,这就是它最基本的功能。比如说,某一个芯片有3个输入引脚,2个输出引脚,当我给输入引脚分别给「高电平,高电平,低电平」的时候,它能在输出引脚给我「低电平,高电平」这样的信号。在刚才这段描述中,「芯片的输入、输出引脚个数」称为「芯片的接口规模」,而「当给XXX输入信号的时候,能给我YYY输出信号」则称为「芯片的逻辑功能」。
因此,我们把那些「可以用来输出的信号」就称作「指令」,而这个芯片能够支持的所有「指令」的集合,就称为「指令集」。因此,一个CPU的指令集直接决定了它的原始功能。
而x86体系架构使用的这种指令集,我们就可以叫他x86指令集,用来描述所有x86体系架构的CPU能够支持哪些指令。
当然,除了最核心的指令集以外,「体系架构」自然还包括CPU的其他部件要有哪些,以及跟外部硬件应当如何交互。总之,我们可以认为这是一套协议标准,当我们使用了x86体系的CPU以后,它一定会含有哪些部件、怎么给它指令它就能正常运行、外部的硬件应当如何布局等等这些问题就已经确定了。我们只需要按照它所规定的协议来编写程序,就可以在这个体系上正常运行了。
为什么叫x86?
解释完x86是什么了以后,相信一定会有读者好奇,这种架构为什么叫这个名字?它和我们现在市面上主流的硬件设备是什么样的关系?
故事要从1978年开始说起。1978年,Intel公司推出了一款CPU,型号叫8086(至于为啥叫这个数字,估计只能问Intel了……)。其实在当年,这款CPU也没激起多大的浪花,我们现在大家都去研究它,也不过是幸存者偏差罢了。所以我们只需要知道,20世纪70年代末,一个姓英的公司(英特尔)发布了一款芯片,型号为8086。
8086芯片没有太大的动静,这有一个非常关键的问题,就是它太贵了!因为它要卖360美元一个。注意!这仅仅是CPU的价钱,没有算其他的硬件。所以能用得起的一般都是极个别的企业,个人用户可谓望尘莫及了。而真正让这个系列的芯片火起来的是8088。
8088我们可以认为是8086的一个精简版,或者我们可以戏称为「8086 SE」~。1981年,IBM使用了8088芯片,生产了面相个人的PC,价格亲民,因此在全球范围内火了起来,也就带动了这个系列的芯片的销量。
此后,Intel就开始了这个架构的CPU的研发迭代,后续又推出了80186、80286、80386。它们都兼容8086的工作模式,但在这个过程中还是出现了一些小插曲(或者可以理解为小bug,这个后续章节会涉及)。
由于这个系列都以86结尾,因此就管这个系列叫做「x86」系列。但注意,「x86架构」则是专指80386以及以后的芯片,而不包括8086、80186和80286,原因我们会在后续章节解释。
直到1992年,本应叫「80586」的CPU诞生之前,Intel因为一些商标版权的问题,使得这个系列不得不改名,当时的80586上市时,名为「Pentium」,中文译作「奔腾」。
后续Intel又发布了「Celeron(赛扬)」系列,还有「Core(酷睿)」系列,以及「Xeon(至强)」系列,都沿用了x86架构,Intel将其称为「IA-32架构」,它们都保持着向下兼容。
x64和x86的关系
故事的转折点在2001年,那个时候有人觉得x86架构有缺陷,不应该继续沿用,于是推出了一款全新的架构,称之为「IA-64」架构,并推出了这个架构的处理器——「Itanium(安腾)」系列。
这里的IA指的是Intel Architecture,而64表示它的指令字长(后续会重点解释)。本来这个命名的目的也很明确,曾经的是「IA-32」,现在重新设计以后叫做「IA-64」。但是因为它并没有向下兼容IA-32,并且价格昂贵,因此在个人PC领域并没有溅起水花。而它主打的服务器领域则是没有拼过IBM的PowerPC,所以也没有太多市场。这也导致了安腾系列的CPU至今都不是很出名。
IA-64不成功,但另一个64位架构却火了,这就是AMD公司在1999年首次推出的AMD64架构。后续AMD64架构被广泛用于个人PC上。那么,AMD64的魅力在哪?其实就在于,它兼容了IA-32架构,并在此之上进行了扩展。因此,AMD64架构也被称为「x86-64」架构,也就是扩展64位的x86架构。
所以这里就有一个很有意思的现象,IA-64作为IA-32的继承者,并没有兼容IA-32,并且没落了。反而是AMD64夺得了王冠,向下兼容IA-32。由于AMD64架构的成功,后续也被Intel所使用,并将其命名为Intel 64。
其实Intel 64和AMD64基本没有区别,主要还是商业竞争中刻意区分了它们。但是硬件厂商的这些商业竞争,对于这些软件公司来说无足轻重,他们只关心,我的软件适配哪种架构,就够了。因此,他们无论描述为「AMD64」还是「Intel 64」,都似乎有站队的嫌疑,而又因为Intel 64和AMD64其实就是同一套架构,因此这些软件厂商又把这种架构称为「x64架构」,其中「x」你自己脑补把,Intel也行,AMD也行。
因此我们总结一下:
- x86架构又叫IA-32架构,是从Intel 80386芯片开始所使用的架构,向下兼容8086和80286架构
- IA-64架构不兼容IA-32,仅用于Intel Itanium系列
- x86-64架构向下兼容IA-32架构,又被称为AMD64架构和Intel 64架构,进而合称x64架构,目前市面上绝大多数的个人PC使用的就是这种架构(包括Intel的酷睿、至强,AMD的锐龙系列)
值得注意的是,由于x64是向下兼容x86的,因此在很多人口中,并不会区分它们,又因为x86架构已经过时很久了,现在很少有设备会去使用。因此有时我们听到「x86」其实指的就是x64架构,尤其是跟ARM架构放在一起描述的时候(比如我们经常会说,苹果从x86转向了ARM,但其实这里的x86指的是x64,而非真正的IA-32架构)。
所以为了避免混淆,笔者在本系列文章中,统一用「IA-32架构」和「AMD64」架构的名称,而不使用「x86」这种可能有二义性的词汇。
为什么选择AMD64架构?
因为这是当前市面上使用最多的架构。随处可见的Intel Core处理器,AMD Ryzen处理器使用的都是AMD64架构。并且,最常用作服务器的Intel Xeon处理器也是这个架构的,所以我们了解最主流的架构自然是不亏的。
另一方面,也正是因为这是目前的主流架构,因此它的相关资料也是最全、最好找的,黑盒较少,比较透明,所以学习门槛较低。计算机底层专业课程的各主流教材也都是选用了这个架构为例进行讲解的。
既然我们是为了理清程序的构建和运行相关知识,那么架构这里就不要让它成为我们的极大困难点,于是,笔者「毅然决然地」选择了它。(偷笑,其实是因为别无选择~)
搭建虚拟环境
了解完这个架构的情况以后,我们接下来要做的就是找机器,然后进行开发了。
硬件环境
既然是要给AMD64架构的设备进行开发,那么首先,我们得先有一个AMD64架构的硬件设备才行。首先最容易想到的,就是真实地搞一台AMD64架构的电脑。
这方法最直接,但是成本有点高,而且装载程序可能没那么方便。当然了,如果你手边正好有空闲的设备,或者已经不用的老设备,那自然无可厚非。你可以把程序直接运行在真机上,也会有一个不一样的体会,而且满满的仪式感,很酷!
虚拟环境
如果没有,那也没关系,因为我们可以用虚拟机。关于虚拟机的运行,通常有两种方式:
- 通过虚拟化(Virtualization)技术运行
- 通过软件模拟(Simulation)运行
这里~翻译必须出来背个锅了!Virtualization和Simulation是完全不同的两种虚拟技术,但这里的翻译似乎完全没有把它们区分开,「虚拟化」和「模拟」到底什么区别?反正,从字面上……我是区别不开…………
那么这两者究竟指什么呢?首先我们要知道,要想通过软件的方式模拟一台硬件设备,那这个「软件」应当是运行在已经良好运行的操作系统上了。换句话说,我们要用操作系统开启一个应用程序,然后在这个应用程序中,模拟出硬件设备的各种部件,再利用这种模拟出的部件来执行指令。
软件模拟方式
那么最容易想到的就是用「纯软件」的方式来模拟。比如说我设置一个变量,用来表示rax寄存器,设置另一个变量来表示rip寄存器。再设置一片内存空间来表示模拟器的内存空间。之后,当我接收到类似于「把0x10内存空间的值写到rax寄存器中」这样的指令时,就把对应内存空间中,偏移量是0x10的值,赋值给用于表示rax寄存器的变量中。大致上用简单的代码来表示就是:
uint64_t rax; // 用于模拟rax寄存器
std::byte mem[1024 * 1024]; // 用于模拟1MB的内存
// 执行将内存数据读取到rax中的指令
void load_mem_to_rax(std::ptrdiff_t address) {
rax = *reinterpret_cast<uint64_t *>(mem + address);
}
由此方法,模拟出所有硬件部件和所有指令集中的指令,那么自然就可以模拟出硬件设备的运行情况。
上面这种模拟方式就称为「Simulation」方式,或者叫「软件模拟」方式。
这种方式的优点非常明显:
- 不受目标机器架构的影响,也就是说,我们可以在ARM架构的电脑上运行AMD64架构的模拟器,反之亦然。
- 可以实时观测和修改模拟硬件的值。这种优势更加明显,由于CPU的微指令更改的仅仅是CPU内部部件的值(比如说寄存器)或者内存某个数据的值。这些更改如果不能显示到屏幕上的话,我们就没法观测到。但如果我们用的是纯软件模拟的机器,那观察这些值就变得无可厚非了,因为它们本质上只是这个进程当中的变量而已。这个优点甚至是我们使用真机都无法比拟的。
当然,它的缺点也非常明显,那就是性能底下。试想,一条软件模拟的「内存读入寄存器」的指令,被软件模拟成了不同变量之间的赋值,这过程还有不少程序逻辑,还有本身OS的调度算法等等。中间隔了这么多层,CPU真实运行的指令早都不知道被扩大成多少条了。因此,这种方式的模拟器,它的性能下降幅度是指数型的。
虚拟化方式
随着虚拟机的使用越来越普遍,市面上主流的OS都开始重视了这个问题。因此,从OS层就已经包装了用于虚拟化的API。然后,「虚拟机」这个APP直接调用OS提供的虚拟化API来完成模拟。
这种技术并不是再完全使用软件模拟硬件情况了,而是会「尽可能多地」直接使用硬件。例如虚拟机中要执行「内存0x10数据读取到rax寄存器中」这样的指令,通过虚拟化API,CPU会真实地执行一条从内存中读取数据放到寄存器中的指令。只不过这片内存空间并非0x10(OS会做一层映射),这个寄存器也可能不是rax。
因此,通过虚拟化API运行的虚拟机软件,会被OS认为是一种特殊的进程,对内部执行的指令仅仅做简单的映射,就直接交给硬件去执行。但所以一条指令对于CPU来说可能只是会变成几条指令而已。它的性能下降幅度是线性的,如果优化的好的话,这种下降幅度可能会非常小。
由于这种方式依赖于OS所提供的「虚拟化API」,因此这种方式被称为「虚拟化」方式。
对比软件模拟方式,虚拟化方式的优点非常明显,那就是性能显著提升。但与之相对的就都是它的劣势了,比如说它不能跨架构模拟,也不容易直接观测到硬件的状态。
静态转义方式
其实还有一种模拟方式,它介于前面介绍的两种之间,适用于跨架构模拟。更准确地来说,并不是「模拟」,而是「转义」。
举例来说,我希望在ARM架构上运行AMD64架构的程序。那么在运行之前,我先读一遍原程序,比如说当它出现「把数据加载到rax寄存器中」指令的时候,我就想,嗯……虽然我的ARM架构中没有rax寄存器,但是,我可以用其他的寄存器来代替,比如说x0。那我就把所有要给rax中写数据的指令,都翻译成给x0寄存器中写数据。
形象点来说,就是在运行一个程序之前,先「读懂」这个程序,然后翻译成当前架构的新程序,然后再去运行。
这种模拟方式,性能损耗在「模拟」和「虚拟化」之间,如果优化的好也可以获得不错的性能。但它最大的缺点就在于,对这个「翻译软件」的要求太高了!通常只适用于运行APP,而不能用于运行OS。并且「翻译软件」不仅要对翻译前后的架构指令非常清楚,还要对OS的调度方式了如指掌才行。
这种方式有一个非常典型的例子,就是苹果公司的Rosetta,也只有苹果公司能够同时对新旧指令架构和macOS都了如指掌,所以他能做出Rosetta也就不足为奇了。
在主流平台上搭建虚拟环境
了解完虚拟环境之后,试问读者,我们应当用哪一种呢?
首先,咱们只是写一些非常简单的程序,目的是学习和梳理底层的知识,所以远到不了考虑虚拟机性能折损的情况。
其次,咱们需要观测到硬件的执行情况,需要随时了解寄存器和内存当中的数据。
最后,我相信还有不少小伙伴跟我一样,用的是苹果自研芯片的Mac,这玩意本身就不是AMD64架构或者IA-32架构的机器,必须进行跨架构模拟。
那么结论就显而易见了,我们将会使用「软件模拟」方式。用到的软件是bochs,这是一款AMD64模拟器,并且支持非常强大的调试指令,非常适合我们当前的诉求。接下来就为大家介绍如何在macOS和Windows系统上配置bochs。
在macOS上配置bochs
bochs是一个AMD64模拟器,我们可以在它上面运行AMD64架构、IA-32架构、80286架构甚至是8086架构的程序。但bochs本身是跨平台的软件,因此,无论你用的是Intel芯片的Mac还是苹果自研芯片的Mac,都可以安装bochs。
虽然我们也可以从bochs官网下载源工程然后构建安装,但是环境配置以及各种依赖软件搞起来太麻烦了,所以我们选取一种最简便的方式,使用Home Brew。
Home Brew是Mac上的开源软件管理器,类似于Debian中的apt-get和RedHat中的yum。但它并没有集成在macOS中,所以我们需要先安装它。
这是Home Brew的官网,但由于众所周知的原因,它的默认资源在中国大陆是访问不到的,所以我们需要使用镜像资源。有一个国内的大神制作了一个安装Home Brew,并将资源库替换为镜像资源的一个脚本,我们可以直接使用。
打开终端,执行下列命令:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
会自动下载这个脚本,然后依据提示指定一个镜像源,输入系统密码,然后安装Home Brew。
由于Home Brew所在github的DNS有过一起污染事件,所以如果当你使用时出现类似于下面的这种报错时:
Warning: No remote 'origin' in /opt/homebrew/Library/Taps/homebrew/homebrew-cask, skipping update!
这时我们可以执行下面的指令来解决:
git config --global --add safe.directory /opt/homebrew/Library/Taps/homebrew/homebrew-core
git config --global --add safe.directory /opt/homebrew/Library/Taps/homebrew/homebrew-cask
git config --global --add safe.directory /opt/homebrew/Library/Taps/homebrew/homebrew-services
当安装好Home Brew以后,就可以通过下面的指令来安装bochs:
brew install bochs
安装完毕之后,我们执行:
bochs --help
如果能顺利打印出帮助信息,那么恭喜,bochs已经安装成功!
在Windows上安装bochs
同样地,由于bochs是跨架构、跨平台软件,因此也可以在Windows上正常运行,也包括了ARM架构的Windows(例如搭载了骁龙8cx芯片的电脑,就是ARM架构的)。下面介绍在Windows上安装bochs的方法。
首先在SourceForge网站上下载bochs的安装包。
下载完毕后双击进行安装。
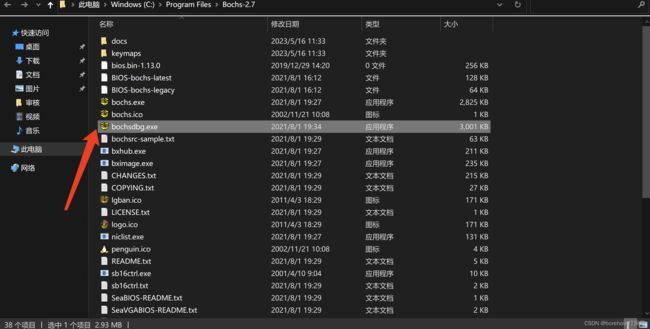
安装过程中的选项保持默认即可。等安装完毕后,可以在开始菜单中找到bochs,这里我们不要直接运行,而是选择下面的Folder文件夹打开。

打开后我们选择bochsdbg.exe打开。注意,在Windows中的bochs默认是不带调试功能的,必须要运行bochsdbg才可以进行调试。本文后续所有要求运行bochs的地方,对于使用Windows的读者,都要换成bochsdbg。(包括命令行、makefile中填写的也应当是bochsdbg而不是bochs,请读者一定要注意!)
打开之后,可以选择左侧Load按钮加载bochsrc配置文件运行,后续如果我们用命令行加-f参数后则无需手动加载。现在暂时也可以不用加载配置文件,直接用默认方式执行,点击右侧的Start即可看到运行效果。
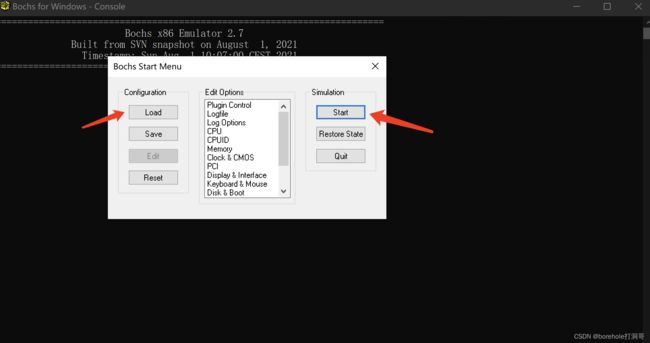
之后便可以看到bochs的运行状态,左侧是用于调试的命令行,右侧是虚拟机的显示效果。
小结
到目前为止,我们的「硬件」环境(虽然是模拟的)就已经就绪了,下一篇将会介绍8086的启动方式,并手写一个MBR来驱动我们的(模拟)设备。
从裸机启动开始运行一个C++程序(二)