STM32CubeMX开发STM32F103:串口+DMA,定时器内部中断、PWM输出、输入捕获,ADC+DMA,GPIO
目录
- 本文介绍
- 波特率计算
- Keil工程文件结构
- Cube介绍
- 基本设置
- 设置GPIO
- 串口设置
- 定时器
- ADC设置
- 中断优先级设置
- STM32-上位机串口通信
- 开发阶段功能测试记录
- 程序改进方向
本文介绍
最近在开发一个STM32程序,涉及很多功能模块(如文题所示),一个特点是利用DMA进行串口收发,实现高速通信,同时不阻塞主程序。现在把开发记录放这里。
网盘代码: https://pan.baidu.com/s/1qZDiGkAPxYsNvYY6pf6eQA?pwd=2jpr
提取码: 2jpr
波特率计算
STM32发送给上位机的数据帧:
2字节帧头+3维×2字节角度+2字节编码器10字节
波特率921600,每字节加上头尾共10bit,1字节传输时间=1/92160s=0.011ms,10字节传输时间0.11ms.
编码器数据是从STM32直接读取的,没有滞后。
角度数据是从IMU串口传输来的,波特率也为921600,三维角度消息帧占11字节,因此IMU到上位机的滞后为0.11*(1+11/10)ms=0.23ms。
不同波特率对应的角度滞后、编码器滞后时间:
| 串口波特率 | 单片机到上位机滞后 ms | IMU到上位机滞后 ms |
|---|---|---|
| 921600 | 0.11 | 0.23 |
| 460800 | 0.22 | 0.46 |
| 230400 | 0.44 | 0.92 |
| 115200 | 0.88 | 1.85 |
Keil工程文件结构
程序项目名称为FlapBird_Cube,ioc文件可用Cube打开:
Keil入口在FlapBird_Cube/MDK-ARM中:
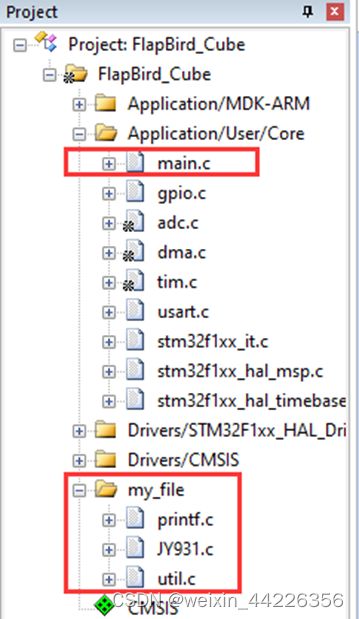
自己添加的驱动文件在FlapBird_Cube/MDK-arm/my_file中:

编程时主要编辑main.c和my_file中的文件,main.c下面的驱动文件是由Cube自动生成的,一般不动:
Cube介绍
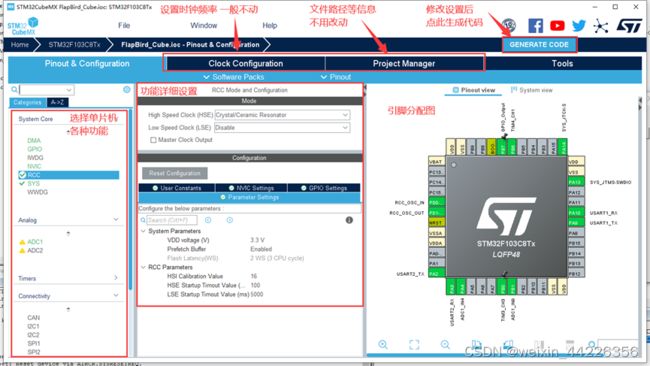
自己添加代码一定要放在Cube指定的用户代码区,否则下次生成代码后,放错位置的代码会被清除。下图中红框是可以写代码的地方。
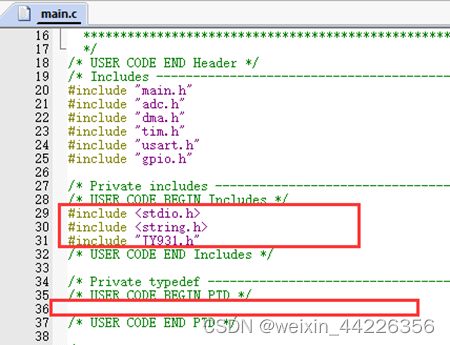
基本设置
设置外部晶振为震荡源

设置串行下载方式(DIO和CLK两根线),把Timebase设为TIM1。
Timebase默认是Systick,如果还要在程序中使用Systick进行微秒级别延时,会相互冲突,导致程序卡死,所以要改为TIM1。

代码中用HAL_Delay()函数进行毫秒级延时。
设置GPIO
直接在右边引脚分配图中单击需要的引脚,选择GPIO_Output:

生成代码后,用HAL_GPIO_WritePin函数进行控制: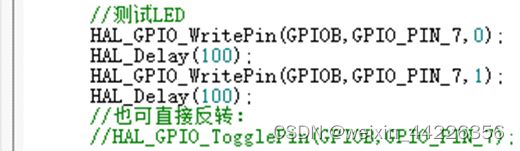
第三个参数填1或0,控制引脚的高低电平。
串口设置
串口1用来和上位机通信,串口2用来和IMU模块WT931通信。
串口1设置方法:Mode设为异步,波特率设为需要的值。如果波特率比115200大,最好是成倍增加,比如230400,460800,921600,否则可能不兼容。

在DMA页面中,给串口1的发送和接收分别增加DMA通道。DMA是直接内存访问功能,可以节省CPU资源。
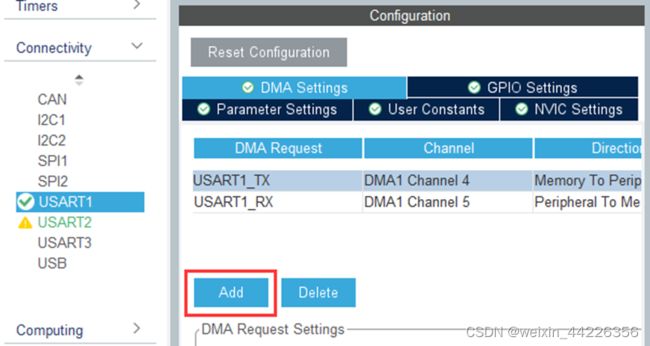
在NVIC页面中勾选串口1的全局中断

串口2的设置与串口1相似,区别是串口2接收的DMA模式选择为Circular(循环模式)。

串口通信编程:
首先在main函数中,Cube生成的初始化函数之前,手动添加一行DMA初始化函数。这是Cube本身的问题,自动生成的初始化代码顺序错误。

串口发送的几种方式:
printf(); //该功能需要在代码中重写的fputc函数(在printf.c文件中),并且在Keil选项中勾选Use Micro LIB。printf会阻塞程序。
HAL_UART_Transmit(&huart1,(uint8_t\*)str,strlen(str),0xffff); //直接发送,会阻塞程序
HAL_UART_Receive_IT(&huart1,(uint8_t\*)str,strlen(str),0xffff); // 中断发送,不阻塞程序
HAL_UART_Receive_DMA(&huart1,(uint8_t\*)str,strlen(str),0xffff); // DMA方式发送,不阻塞程序,速度最快
串口接收:也分为直接接收、中断接收、DMA接收三种方式。为了不阻塞程序,采用DMA接收方式。做法:
在main.c中定义全局数组,作为串口接收的缓存区:

在主函数while前的初始化代码中开始接收:
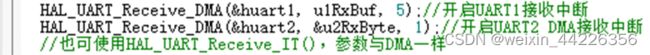
三个参数含义为:串口号,缓存数组指针,接收长度(字节)。
在main.c中主函数之外,定义串口接收回调函数,注意需要在Cube注释指定的位置添加。也可以在自己新建的c文件中添加回调。

在接收到了前面指定长度的数据后,就会触发回调函数,可以在回调函数中处理缓存中的数据。
对于串口1,需要在回调中再次调用接收函数,以便接收下条消息。串口2不需要,因为前面在Cube中把串口2的DMA设为了循环模式,开启一次后就会循环接收,每次接收完成都会调用一下回调函数。
串口2的循环DMA模式适合持续接收IMU数据的需求。经过测试,如果串口2也使用和串口1一样的接收方式,会导致IMU数据出现很多噪点。
定时器
TIM2产生周期性内部中断,用于PID控制,TIM3产生PMW波,TIM4用来对编码器脉冲进行计数。
TIM2设置:选择时钟源为内部时钟,设置分频倍率Prescaler和计数值Counter Peroid:
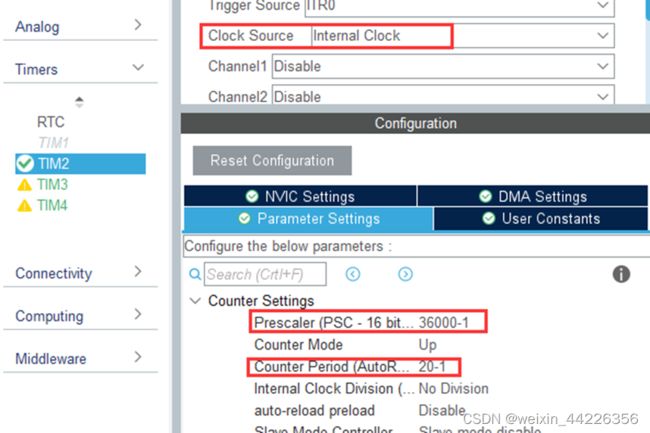
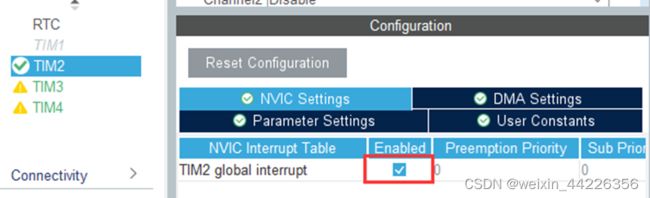
开启全局中断:
TIM3设置:
把通道3设为PWM输出,设置分频和计数周期,底部的Pulse可以设置PWM的初始宽度。PWM占空比=Pulse / Counter Period。

TIM4设置:
通道1设置为输入捕获模式:
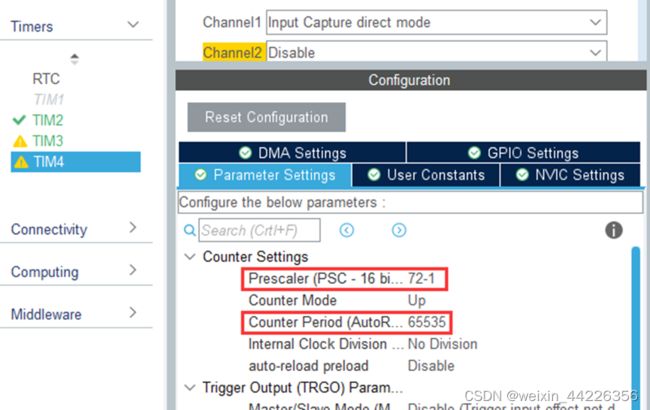
开启中断:

定时器编程:
在主函数初始化代码中需要开启各个定时器对应的功能,否则不运转:

对于内部循环定时TIM2,需要用到PeriodElapsedCallback,每当有定时器计数溢出时,调用一次。由于前面在Cube中把Timebase设为了TIM1,所以Cube已经自动添加了溢出回调,可以在其中指定的用户代码区加入TIM2的处理代码:

对于TIM3,使用以下函数修改PWM占空比:
![]()
参数pwm对应前面Cube中的脉宽pulse。
对于TIM4,需要添加一个输入捕获回调函数,在回调中对脉冲进行计数:

ADC设置
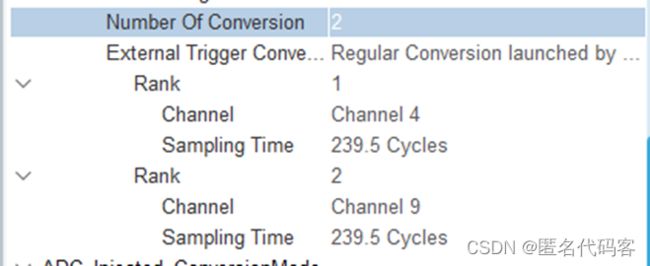
在ADC1页面勾选需要的检测通道(4和9);
连续转换模式Continuous Conversion Mode保持默认的Disable,后面有需要可改为Enable;
转换数量设为2.

下面每个Rank对应一个转换通道,设置每个通道的采样时间为239.5个循环。
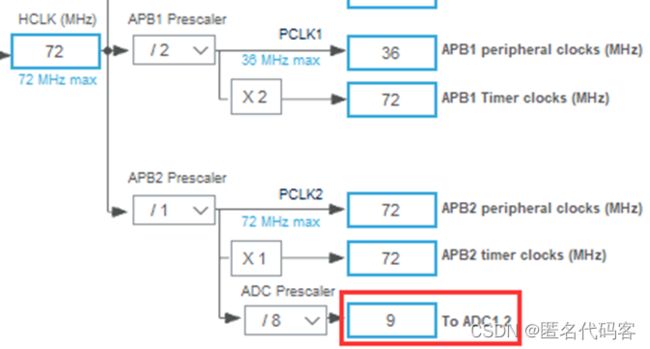
ADC采样速度计算
ADC的转换时间=ADC的采样时间+12.5周期=239.5+12.5=252个周期.
在Cube时钟树页面看到ADC频率为9MHz,因此转换时间=252/9000,000 s=28us, 如果持续采样,频率为35.7kHz.
添加一个DMA通道。

ADC的编程:
在main.c中定义缓存数组:

在TIM2的溢出回调中,开启DMA转换,以此实现周期性的ADC采样:

添加ADC回调函数,可在其中处理缓存中的转换结果。两个ADC通道的采样结果被存放到了缓存数组的两个元素中。STM32的ADC是12位的,因此采样结果应该在0~4095范围内。

中断优先级设置
实验发现,如果在TIM2溢出回调中添加一些控制代码,会导致IMU数据出现尖刺。
一个可能的原因是TIM2中断和UART2接收中断冲突。在Cube中打开NVIC优先级页面:
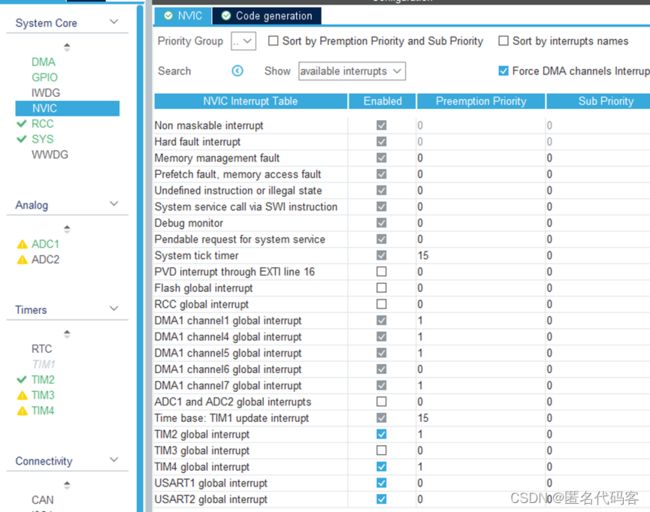
目前只调整主要优先级Preemption Priority,0是最高优先,数值越大优先级越低。
把UART2接收对应的DMA通道6优先级设置为最高,就基本解决了前面的问题。
STM32-上位机串口通信
STM32发送:
STM32在每次收到IMU角度数据时,向上位机发送一条消息,一条消息包括:
2字节帧头+6字节角度数据+2字节编码器计数值
其中帧头为0x0A 0x05, 角度数据包括三个2字节整型角度值(可能为负数)。
STM32接收(未实现):
为了便于编程,STM32接收消息固定为5字节。
开发阶段功能测试记录
使用定时器输入捕获功能,对编码器脉冲计数:
IMU测试
ADC测试
程序改进方向
其他改善程序稳定性的方法:
- 降低串口波特率
- 减少IMU发送的数据量。WT931默认发送三维加速度、角速度、角度和磁场数据。可以在IMU配套上位机中取消发送不需要的数据,减轻STM32的负担。
- 提高UART2 DMA接收的数据长度。目前STM32一次仅接收1个字节的IMU数据,如果把接收长度调整为一个IMU数据帧的长度(11字节),可以大大降低中断访问频率。需要设计好帧头对齐机制。
- 对IMU数据帧进行和校验,排除错误数据
- 对串口发送状态进行标记,避免前一条消息发送之前开始下一次请求