基于YOLOv8的多目标检测与自动标注软件【python源码+PyqtUI界面+exe文件】【深度学习】
基本功能演示
摘要:
YOLOv8是YOLO系列最新的版本,支持多种视觉任务。本文基于YOLOv8的基础模型实现了80种类别的目标检测,可以对图片进行批量自动标注,并将检测结果保存为YOLO格式便于后续进行其他任务训练。本文给出完整的Python实现代码,并且通过PyQT5实现了UI界面,更方便进行功能的展示,并且提供了可执行的exe文件。该软件支持图片、视频以及摄像头进行目标检测,并保存检测结果;支持图片自动标注保存;支持检测类别选择。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
- 基本功能演示
- 前言
- 一、软件核心功能介绍及效果演示
-
- 软件主要功能
- 80个目标检测类别说明
- (1)图片检测演示
- (2)视频检测演示
- (3)摄像头检测演示
- (4)保存检测结果与自动标注标签文件
- 二、YOLOv8目标检测的基本原理
-
- 1.基本原理
- 2.核心功能代码实现
-
- 2.1 YOLOv8检测图片代码
- 2.2 YOLOv8检测视频代码
- 【获取方式】
- 结束语
点击跳转至文末《完整相关文件及源码》获取
前言
YOLOv8是一种前沿的计算机视觉技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性。这种模型属于Ultralytics平台,它的优势在于速度快且准确率高,这得益于其"You Only Look Once"(你仅需看一遍)的工作原理。不仅如此,YOLOv8不仅限于检测任务,还拓展到了分类、分割、跟踪,甚至姿态估计等多个领域。
目标检测作为计算机视觉的重要任务之一,具有广泛的应用价值。例如,在交通管理中,可以通过实时车辆检测和跟踪来更好地管理交通流量;在智能监控中,可以用于识别异常行为或危险情况等。因此,YOLOv8这类高效准确的目标检测模型在各领域的应用具有重要意义。
博主根据YOLOv8的目标检测技术,基于python与Pyqt5开发了一款简洁的支持80个类别的目标检测与自动化标注软件,可支持图片、视频以及摄像头目标检测,同时支持检测类型选择与图片的批量自动标注,并将检测结果保存为YOLO格式的文件,用于后续训练。
软件基本界面如下图所示:

觉得不错的小伙伴,感谢点赞、关注加收藏!如果大家有任何建议或意见,欢迎在评论区留言交流!
一、软件核心功能介绍及效果演示
软件主要功能
1. 支持80个类别的目标检测,详细目标类别见下方说明;
2. 支持图片、视频及摄像头进行检测,并显示目标位置、目标总数,保存检测结果;
3. 支持图片批量检测与自动标注,并将结果保存为YOLO格式文件,用于后续模型训练;
4. 支持单个类别的目标选择与检测,并保存检测结果与YOLO标签文件。
80个目标检测类别说明
本文是基于YOLOv8的基础训练模型进行开发的,模型使用的是COCO数据集。支持80个类别的目标检测,具体目标类别名称如下:
[ '人','自行车', '汽车', '摩托车', '飞机', '公共汽车', '火车',
'卡车', '船', '交通灯', '消防栓', '停车标志', '停车收费表',
'长凳', '鸟', '猫', '狗', '马', '羊', '牛', '大象', '熊',
'斑马', '长颈鹿', '背包', '雨伞','手袋', '领带', '手提箱',
'飞盘', '雪橇', '滑雪板', '运动球', '风筝', '棒球棒',
'棒球手套', '滑板', '冲浪板', '网球拍', '瓶子', '酒杯', '杯子',
'叉子', '刀', '汤匙', '碗', '香蕉', '苹果', '三明治', '橙子',
'西兰花', '胡萝卜', '热狗', '披萨', '甜甜圈', '蛋糕', '椅子',
'沙发', '盆栽植物', '床', '餐桌', '马桶', '电视', '笔记本电脑',
'鼠标', '遥控器', '键盘', '手机', '微波炉', '烤箱', '烤面包机',
'水槽', '冰箱', '书', '时钟', '花瓶', '剪刀', '泰迪熊', '吹风机', '牙刷']
包含了常见的人、汽车、公共汽车、交通灯等。
(1)图片检测演示
点击图片图标,选择需要检测的图片,或者点击文件夹图标,选择需要批量检测图片所在的文件夹,操作演示如下:
1. 点击选择类别下拉框后,会只对图片指定类别进行检测【默认检测全部类别】。
2. 点击保存按钮,会同时保存指定类别检测结果图片与其对应的YOLO标签文件。
(2)视频检测演示
点击视频图标,选择需要检测的视频,就会自动显示检测结果。也可以通过下拉框选择指定类别进行检测。点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
(3)摄像头检测演示
点击摄像头图标,可以打开摄像头进行检测,同样可以通过下拉框选择指定类别进行检测。
(4)保存检测结果与自动标注标签文件
点击保存按钮后,对于图片,会同时保存指定类别检测结果图片与其对应的YOLO标签文件;对于视频,只会保存指定类别检测结果视频。
检测的图片与视频结果会存储在save_data目录下:

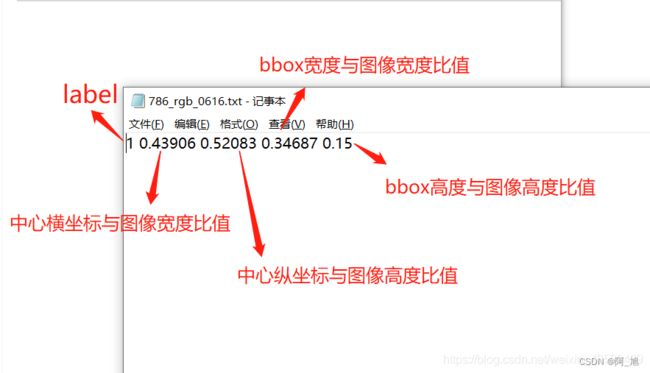
对于图片,会将指定检测目标的结果存储为目标检测中YOLO格式,方便后续进行模型进行训练使用,存储路径为:save_data/yolo_labels。结果如下图所示:

自动标注的存储格式为YOLO目标检测格式说明如下:【保存的文件名与图片名称相同】
二、YOLOv8目标检测的基本原理
1.基本原理
YOLOv8是一种前沿的目标检测技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性。主要的创新点包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
YOLOv8不仅限于检测任务,还拓展到了分类、分割、跟踪,甚至姿态估计等多个领域。比如,通过使用已经训练好的yolov8x-seg.pt模型,可以实现对输入图像的实例分割操作,从而得到图像中不同物体的分割结果。此外,利用YOLOv8还可以实现实时车辆检测、车辆跟踪、实时车速检测,以及检测车辆是否超速等功能。
其主要网络结构如下:
本文基于YOLOv8的基础的目标检测模型,该多目标检测与自动标注软件的开发。支持80种类型目标的检测与结果保存,同时能批量将图片的检测结果保存为YOLO格式,便于后续模型训练的使用。
2.核心功能代码实现
2.1 YOLOv8检测图片代码
from ultralytics import YOLO
import cv2
# 加载预训练模型
model = YOLO("yolov8n.pt", task='detect')
# model = YOLO("yolov8n.pt") task参数也可以不填写,它会根据模型去识别相应任务类别
# 检测图片
results = model("./ultralytics/assets/bus.jpg")
res = results[0].plot()
cv2.imshow("YOLOv8 Inference", res)
cv2.waitKey(0)
2.2 YOLOv8检测视频代码
import cv2
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
print('111')
# Open the video file
video_path = "1.mp4"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
以上便是关于YOLOv8的多目标检测与自动标注原理与代码介绍。针对以上内容,博主基于python与Pyqt5开发了一个可视化的YOLOv8多目标检测与自动标注软件,能够很好的支持图片、视频及摄像头的目标检测,支持检测类型的选择,同时支持自动标注文件保存为YOLO格式。
关于该YOLOv8多目标检测与自动标注软件涉及到的完整源码、UI界面代码以及可执行的exe【win10,64位】等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
关注下方名片G-Z-H:【阿旭算法与机器学习】,回复【目标检测】即可获取下载方式
本文涉及到的完整全部程序文件:包括python源码、UI文件、可执行的exe文件等(见下图),获取方式见文末:

注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,MainProgram.exe为可执行文件,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
关注下方名片GZH:【阿旭算法与机器学习】,回复【目标检测】即可获取下载方式
结束语
以上便是博主开发的关于YOLOv8多目标检测与自动标注软件的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!