一次完整的JVM堆外内存泄漏故障排查记录
前言
记录一次线上JVM堆外内存泄漏问题的排查过程与思路,其中夹带一些JVM内存分配机制以及常用的JVM问题排查指令和工具分享,希望对大家有所帮助。
在整个排查过程中,我也走了不少弯路,但是在文章中我仍然会把完整的思路和想法写出来,当做一次经验教训,给后人参考,文章最后也总结了下内存泄漏问题快速排查的几个原则。
本文的主要内容:
- 故障描述和排查过程
- 故障原因和解决方案分析
- JVM堆内内存和堆外内存分配原理
- 常用的进程内存泄漏排查指令和工具介绍和使用
文章撰写不易,请大家多多支持我的原创技术公众号:后端技术漫谈
故障描述
8月12日中午午休时间,我们商业服务收到告警,服务进程占用容器的物理内存(16G)超过了80%的阈值,并且还在不断上升。

监控系统调出图表查看:
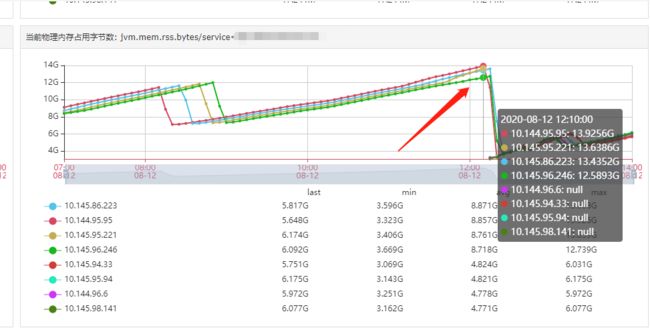
像是Java进程发生了内存泄漏,而我们堆内存的限制是4G,这种大于4G快要吃满内存应该是JVM堆外内存泄漏。
确认了下当时服务进程的启动配置:
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=80
虽然当天没有上线新代码,但是当天上午我们正在使用消息队列推送历史数据的修复脚本,该任务会大量调用我们服务其中的某一个接口,所以初步怀疑和该接口有关。
下图是该调用接口当天的访问量变化:
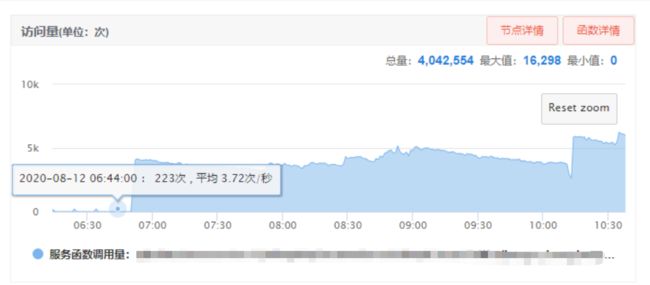
可以看到案发当时调用量相比正常情况(每分钟200+次)提高了很多(每分钟5000+次)。
我们暂时让脚本停止发送消息,该接口调用量下降到每分钟200+次,容器内存不再以极高斜率上升,一切似乎恢复了正常。
接下来排查这个接口是不是发生了内存泄漏。
排查过程
首先我们先回顾下Java进程的内存分配,方便我们下面排查思路的阐述。
以我们线上使用的JDK1.8版本为例。JVM内存分配网上有许多总结,我就不再进行二次创作。
JVM内存区域的划分为两块:堆区和非堆区。
- 堆区:就是我们熟知的新生代老年代。
- 非堆区:非堆区如图中所示,有元数据区和直接内存。
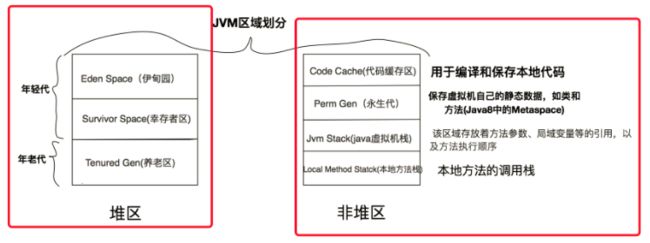
这里需要额外注意的是:永久代(JDK8的原生去)存放JVM运行时使用的类,永久代的对象在full GC时进行垃圾收集。
复习完了JVM的内存分配,让我们回到故障上来。
堆内存分析
虽说一开始就基本确认与堆内存无关,因为泄露的内存占用超过了堆内存限制4G,但是我们为了保险起见先看下堆内存有什么线索。
我们观察了新生代和老年代内存占用曲线以及回收次数统计,和往常一样没有大问题,我们接着在事故现场的容器上dump了一份JVM堆内存的日志。
堆内存Dump
堆内存快照dump命令:
jmap -dump:live,format=b,file=xxxx.hprof pid
画外音:你也可以使用jmap -histo:live pid直接查看堆内存存活的对象。
导出后,将Dump文件下载回本地,然后可以使用Eclipse的MAT(Memory Analyzer)或者JDK自带的JVisualVM打开日志文件。
使用MAT打开文件如图所示:
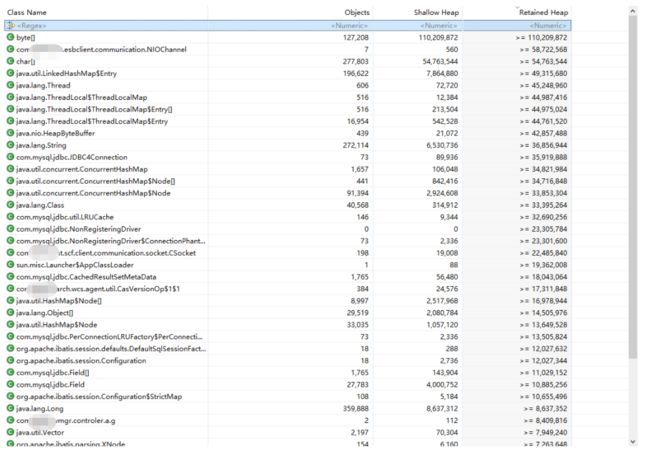
可以看到堆内存中,有一些nio有关的大对象,比如正在接收消息队列消息的nioChannel,还有nio.HeapByteBuffer,但是数量不多,不能作为判断的依据,先放着观察下。
下一步,我开始浏览该接口代码,接口内部主要逻辑是调用集团的WCS客户端,将数据库表中数据查表后写入WCS,没有其他额外逻辑
发觉没有什么特殊逻辑后,我开始怀疑WCS客户端封装是否存在内存泄漏,这样怀疑的理由是,WCS客户端底层是由SCF客户端封装的,作为RPC框架,其底层通讯传输协议有可能会申请直接内存。
是不是我的代码出发了WCS客户端的Bug,导致不断地申请直接内存的调用,最终吃满内存。
我联系上了WCS的值班人,将我们遇到的问题和他们描述了一下,他们回复我们,会在他们本地执行下写入操作的压测,看看能不能复现我们的问题。
既然等待他们的反馈还需要时间,我们就准备先自己琢磨下原因。
我将怀疑的目光停留在了直接内存上,怀疑是由于接口调用量过大,客户端对nio使用不当,导致使用ByteBuffer申请过多的直接内存。
画外音:最终的结果证明,这一个先入为主的思路导致排查过程走了弯路。在问题的排查过程中,用合理的猜测来缩小排查范围是可以的,但最好先把每种可能性都列清楚,在发现自己深入某个可能性无果时,要及时回头仔细审视其他可能性。
沙箱环境复现
为了能还原当时的故障场景,我在沙箱环境申请了一台压测机器,来确保和线上环境一致。
首先我们先模拟内存溢出的情况(大量调用接口):
我们让脚本继续推送数据,调用我们的接口,我们持续观察内存占用。
当开始调用后,内存便开始持续增长,并且看起来没有被限制住(没有因为限制触发Full GC)。
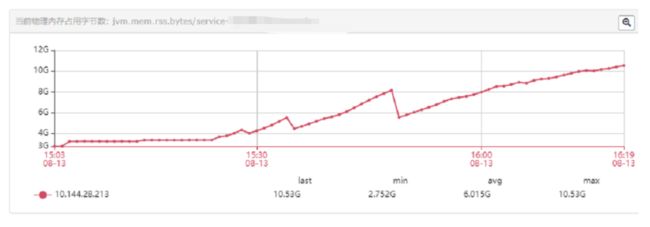
接着我们来模拟下平时正常调用量的情况(正常量调用接口):
我们将该接口平时正常的调用量(比较小,且每10分钟进行一次批量调用)切到该压测机器上,得到了下图这样的老生代内存和物理内存趋势:
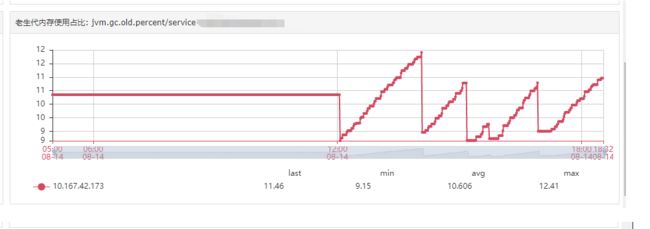
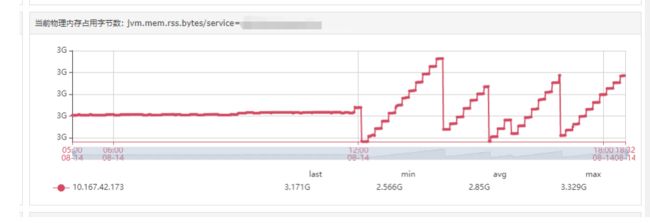
问题来了:为何内存会不断往上走吃满内存呢?
当时猜测是由于JVM进程并没有对于直接内存大小进行限制(-XX:MaxDirectMemorySize),所以堆外内存不断上涨,并不会触发FullGC操作。
上图能够得出两个结论:
- 在内存泄露的接口调用量很大的时候,如果恰好堆内老生代等其他情况一直不满足FullGC条件,就一直不会FullGC,直接内存一路上涨。
- 而在平时低调用量的情况下, 内存泄漏的比较慢,FullGC总会到来,回收掉泄露的那部分,这也是平时没有出问题,正常运行了很久的原因。
由于上面提到,我们进程的启动参数中并没有限制直接内存,于是我们将-XX:MaxDirectMemorySize配置加上,再次在沙箱环境进行了测验。
结果发现,进程占用的物理内存依然会不断上涨,超出了我们设置的限制,“看上去”配置似乎没起作用。
这让我很讶异,难道JVM对内存的限制出现了问题?
到了这里,能够看出我排查过程中思路执着于直接内存的泄露,一去不复返了。
画外音:我们应该相信JVM对内存的掌握,如果发现参数失效,多从自己身上找原因,看看是不是自己使用参数有误。
直接内存分析
为了更进一步的调查清楚直接内存里有什么,我开始对直接内存下手。由于直接内存并不能像堆内存一样,很容易的看出所有占用的对象,我们需要一些命令来对直接内存进行排查,我有用了几种办法,来查看直接内存里到底出现了什么问题。
查看进程内存信息 pmap
pmap - report memory map of a process(查看进程的内存映像信息)
pmap命令用于报告进程的内存映射关系,是Linux调试及运维一个很好的工具。
pmap -x pid 如果需要排序 | sort -n -k3**
执行后我得到了下面的输出,删减输出如下:
..
00007fa2d4000000 8660 8660 8660 rw--- [ anon ]
00007fa65f12a000 8664 8664 8664 rw--- [ anon ]
00007fa610000000 9840 9832 9832 rw--- [ anon ]
00007fa5f75ff000 10244 10244 10244 rw--- [ anon ]
00007fa6005fe000 59400 10276 10276 rw--- [ anon ]
00007fa3f8000000 10468 10468 10468 rw--- [ anon ]
00007fa60c000000 10480 10480 10480 rw--- [ anon ]
00007fa614000000 10724 10696 10696 rw--- [ anon ]
00007fa6e1c59000 13048 11228 0 r-x-- libjvm.so
00007fa604000000 12140 12016 12016 rw--- [ anon ]
00007fa654000000 13316 13096 13096 rw--- [ anon ]
00007fa618000000 16888 16748 16748 rw--- [ anon ]
00007fa624000000 37504 18756 18756 rw--- [ anon ]
00007fa62c000000 53220 22368 22368 rw--- [ anon ]
00007fa630000000 25128 23648 23648 rw--- [ anon ]
00007fa63c000000 28044 24300 24300 rw--- [ anon ]
00007fa61c000000 42376 27348 27348 rw--- [ anon ]
00007fa628000000 29692 27388 27388 rw--- [ anon ]
00007fa640000000 28016 28016 28016 rw--- [ anon ]
00007fa620000000 28228 28216 28216 rw--- [ anon ]
00007fa634000000 36096 30024 30024 rw--- [ anon ]
00007fa638000000 65516 40128 40128 rw--- [ anon ]
00007fa478000000 46280 46240 46240 rw--- [ anon ]
0000000000f7e000 47980 47856 47856 rw--- [ anon ]
00007fa67ccf0000 52288 51264 51264 rw--- [ anon ]
00007fa6dc000000 65512 63264 63264 rw--- [ anon ]
00007fa6cd000000 71296 68916 68916 rwx-- [ anon ]
00000006c0000000 4359360 2735484 2735484 rw--- [ anon ]
可以看出,最下面一行是堆内存的映射,占用4G,其他上面有非常多小的内存占用,不过通过这些信息我们依然看不出问题。
堆外内存跟踪 NativeMemoryTracking
Native Memory Tracking (NMT) 是Hotspot VM用来分析VM内部内存使用情况的一个功能。我们可以利用jcmd(jdk自带)这个工具来访问NMT的数据。
NMT必须先通过VM启动参数中打开,不过要注意的是,打开NMT会带来5%-10%的性能损耗。
-XX:NativeMemoryTracking=[off | summary | detail]
# off: 默认关闭
# summary: 只统计各个分类的内存使用情况.
# detail: Collect memory usage by individual call sites.
然后运行进程,可以使用下面的命令查看直接内存:
jcmd VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB]
# summary: 分类内存使用情况.
# detail: 详细内存使用情况,除了summary信息之外还包含了虚拟内存使用情况。
# baseline: 创建内存使用快照,方便和后面做对比
# summary.diff: 和上一次baseline的summary对比
# detail.diff: 和上一次baseline的detail对比
# shutdown: 关闭NMT
我们使用:
jcmd pid VM.native_memory detail scale=MB > temp.txt
得到如图结果:
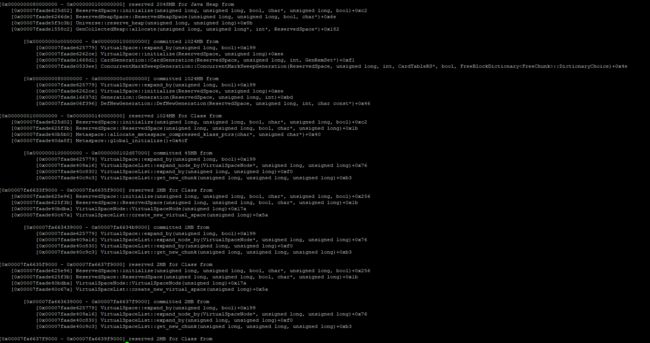
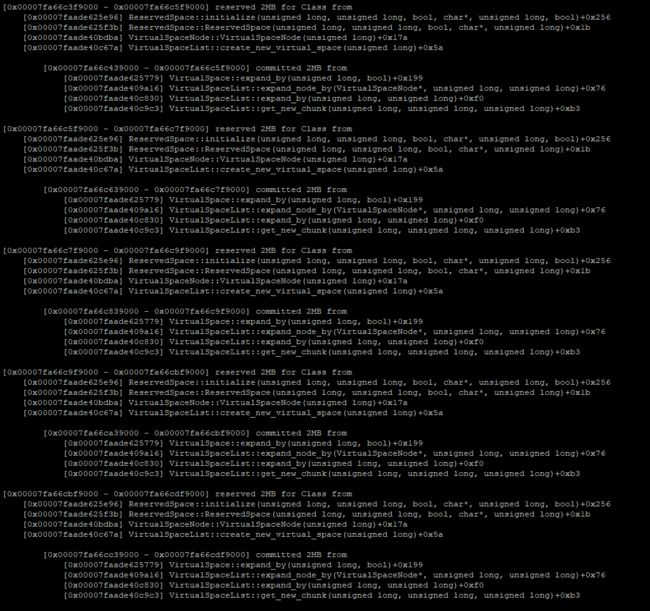
上图中给我们的信息,都不能很明显的看出问题,至少我当时依然不能通过这几次信息看出问题。
排查似乎陷入了僵局。
山重水复疑无路
在排查陷入停滞的时候,我们得到了来自WCS和SCF方面的回复,两方都确定了他们的封装没有内存泄漏的存在,WCS方面没有使用直接内存,而SCF虽然作为底层RPC协议,但是也不会遗留这么明显的内存bug,否则应该线上有很多反馈。
查看JVM内存信息 jmap
此时,找不到问题的我再次新开了一个沙箱容器,运行服务进程,然后运行jmap命令,看一看JVM内存的实际配置:
jmap -heap pid
得到结果:
Attaching to process ID 1474, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.66-b17
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 2147483648 (2048.0MB)
MaxNewSize = 2147483648 (2048.0MB)
OldSize = 2147483648 (2048.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 1932787712 (1843.25MB)
used = 1698208480 (1619.5378112792969MB)
free = 234579232 (223.71218872070312MB)
87.86316621615607% used
Eden Space:
capacity = 1718091776 (1638.5MB)
used = 1690833680 (1612.504653930664MB)
free = 27258096 (25.995346069335938MB)
98.41346682518548% used
From Space:
capacity = 214695936 (204.75MB)
used = 7374800 (7.0331573486328125MB)
free = 207321136 (197.7168426513672MB)
3.4349974840697497% used
To Space:
capacity = 214695936 (204.75MB)
used = 0 (0.0MB)
free = 214695936 (204.75MB)
0.0% used
concurrent mark-sweep generation:
capacity = 2147483648 (2048.0MB)
used = 322602776 (307.6579818725586MB)
free = 1824880872 (1740.3420181274414MB)
15.022362396121025% used
29425 interned Strings occupying 3202824 bytes
输出的信息中,看得出老年代和新生代都蛮正常的,元空间也只占用了20M,直接内存看起来也是2g…
嗯?为什么MaxMetaspaceSize = 17592186044415 MB?看起来就和没限制一样。
再仔细看看我们的启动参数:
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=80
配置的是-XX:PermSize=256m -XX:MaxPermSize=512m,也就是永久代的内存空间。而1.8后,Hotspot虚拟机已经移除了永久代,使用了元空间代替。 由于我们线上使用的是JDK1.8,所以我们对于元空间的最大容量根本就没有做限制,-XX:PermSize=256m -XX:MaxPermSize=512m 这两个参数对于1.8就是过期的参数。
下面的图描述了从1.7到1.8,永久代的变更:
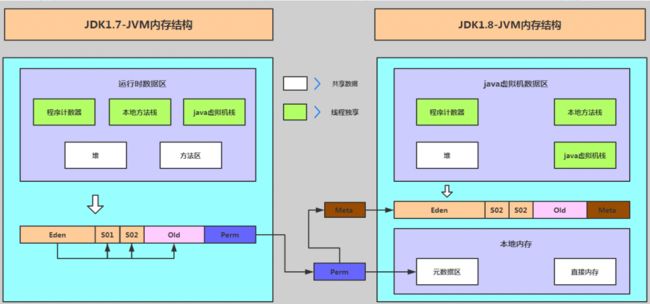
那会不会是元空间内存泄露了呢?
我选择了在本地进行测试,方便更改参数,也方便使用JVisualVM工具直观的看出内存变化。
使用JVisualVM观察进程运行
首先限制住元空间,使用参数-XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m,然后在本地循环调用出问题的接口。
得到如图:
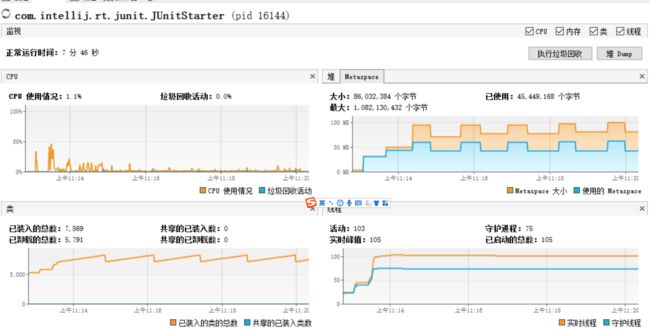
可以看出,在元空间耗尽时,系统出发了Full GC,元空间内存得到回收,并且卸载了很多类。
然后我们将元空间限制去掉,也就是使用之前出问题的参数:
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=80 -XX:MaxDirectMemorySize=2g -XX:+UnlockDiagnosticVMOptions
得到如图:
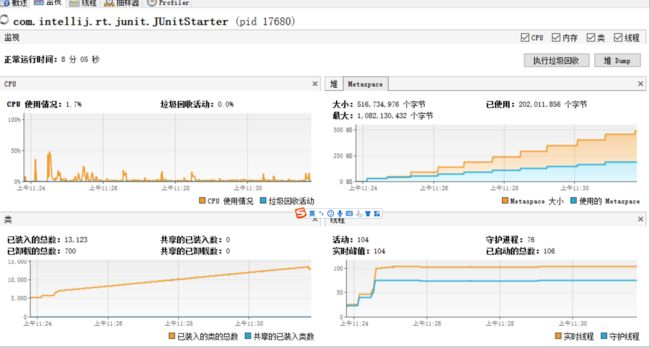
可以看出,元空间在不断上涨,并且已装入的类随着调用量的增加也在不断上涨,呈现正相关趋势。
柳暗花明又一村
问题一下子明朗了起来,随着每次接口的调用,极有可能是某个类都在不断的被创建,占用了元空间的内存。
观察JVM类加载情况 -verbose
在调试程序时,有时需要查看程序加载的类、内存回收情况、调用的本地接口等。这时候就需要-verbose命令。在myeclipse可以通过右键设置(如下),也可以在命令行输入java -verbose来查看。
-verbose:class 查看类加载情况
-verbose:gc 查看虚拟机中内存回收情况
-verbose:jni 查看本地方法调用的情况
我们在本地环境,添加启动参数-verbose:class循环调用接口。
可以看到生成了无数com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto:
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
当调用了很多次,积攒了一定的类时,我们手动执行Full GC,进行类加载器的回收,我们发现大量的fastjson相关类被回收。
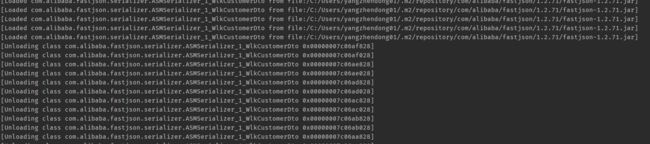
如果在回收前,使用jmap查看类加载情况,同样也可以发现大量的fastjson相关类:
jmap -clstats 7984
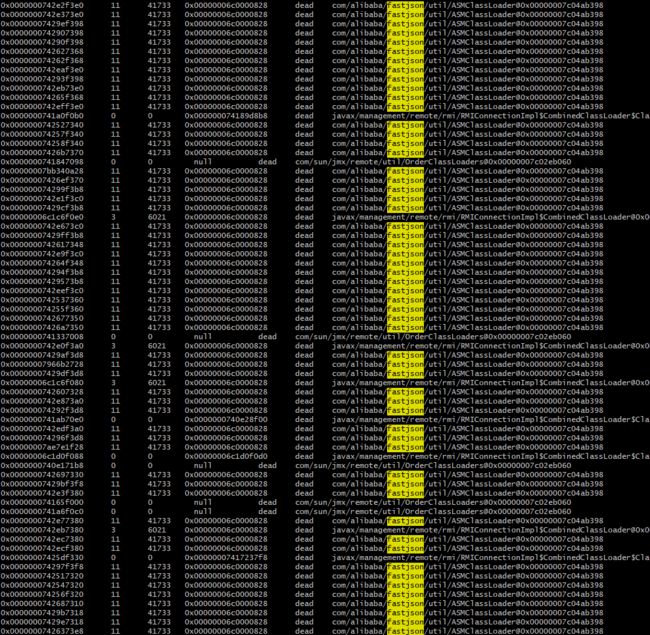
这下有了方向,这次仔细排查代码,查看代码逻辑里哪里用到了fastjson,发现了如下代码:
/**
* 返回Json字符串.驼峰转_
* @param bean 实体类.
*/
public static String buildData(Object bean) {
try {
SerializeConfig CONFIG = new SerializeConfig();
CONFIG.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;
return jsonString = JSON.toJSONString(bean, CONFIG);
} catch (Exception e) {
return null;
}
}
问题根因
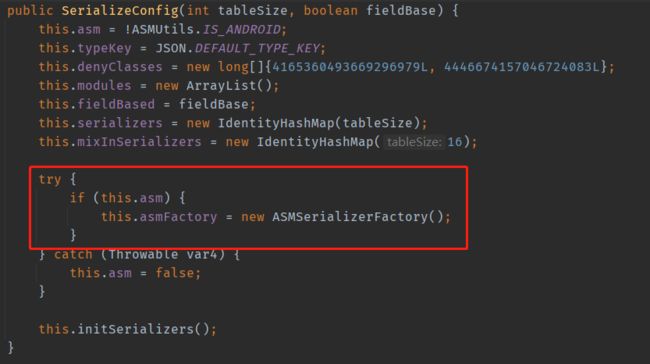
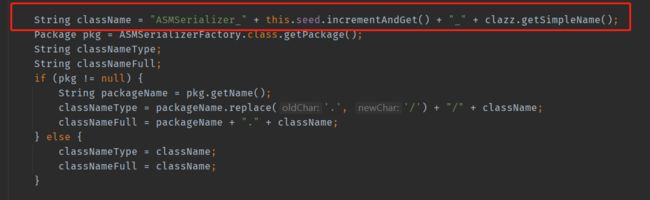
我们在调用wcs前将驼峰字段的实体类序列化成下划线字段,**这需要使用fastjson的SerializeConfig,而我们在静态方法中对其进行了实例化。SerializeConfig创建时默认会创建一个ASM代理类用来实现对目标对象的序列化。也就是上面被频繁创建的类com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto,如果我们复用SerializeConfig,fastjson会去寻找已经创建的代理类,从而复用。但是如果new SerializeConfig(),则找不到原来生成的代理类,就会一直去生成新的WlkCustomerDto代理类。
下面两张图时问题定位的源码:
我们将SerializeConfig作为类的静态变量,问题得到了解决。
private static final SerializeConfig CONFIG = new SerializeConfig();
static {
CONFIG.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;
}
fastjson SerializeConfig 做了什么
SerializeConfig介绍:
SerializeConfig的主要功能是配置并记录每种Java类型对应的序列化类(ObjectSerializer接口的实现类),比如Boolean.class使用BooleanCodec(看命名就知道该类将序列化和反序列化实现写到一起了)作为序列化实现类,float[].class使用FloatArraySerializer作为序列化实现类。这些序列化实现类,有的是FastJSON中默认实现的(比如Java基本类),有的是通过ASM框架生成的(比如用户自定义类),有的甚至是用户自定义的序列化类(比如Date类型框架默认实现是转为毫秒,应用需要转为秒)。当然,这就涉及到是使用ASM生成序列化类还是使用JavaBean的序列化类类序列化的问题,这里判断根据就是是否Android环境(环境变量"java.vm.name"为"dalvik"或"lemur"就是Android环境),但判断不仅这里一处,后续还有更具体的判断。
理论上来说,每个SerializeConfig实例若序列化相同的类,都会找到之前生成的该类的代理类,来进行序列化。们的服务在每次接口被调用时,都实例化一个ParseConfig对象来配置Fastjson反序列的设置,而未禁用ASM代理的情况下,由于每次调用ParseConfig都是一个新的实例,因此永远也检查不到已经创建的代理类,所以Fastjson便不断的创建新的代理类,并加载到metaspace中,最终导致metaspace不断扩张,将机器的内存耗尽。
升级JDK1.8才会出现问题
导致问题发生的原因还是值得重视。为什么在升级之前不会出现这个问题?这就要分析jdk1.8和1.7自带的hotspot虚拟机的差异了。
从jdk1.8开始,自带的hostspot虚拟机取消了过去的永久区,而新增了metaspace区,从功能上看,metaspace可以认为和永久区类似,其最主要的功用也是存放类元数据,但实际的机制则有较大的不同。
首先,metaspace默认的最大值是整个机器的物理内存大小,所以metaspace不断扩张会导致java程序侵占系统可用内存,最终系统没有可用的内存;而永久区则有固定的默认大小,不会扩张到整个机器的可用内存。当分配的内存耗尽时,两者均会触发full gc,但不同的是永久区在full gc时,以堆内存回收时类似的机制去回收永久区中的类元数据(Class对象),只要是根引用无法到达的对象就可以回收掉,而metaspace判断类元数据是否可以回收,是根据加载这些类元数据的Classloader是否可以回收来判断的,只要Classloader不能回收,通过其加载的类元数据就不会被回收。这也就解释了我们这两个服务为什么在升级到1.8之后才出现问题,因为在之前的jdk版本中,虽然每次调用fastjson都创建了很多代理类,在永久区中加载类很多代理类的Class实例,但这些Class实例都是在方法调用是创建的,调用完成之后就不可达了,因此永久区内存满了触发full gc时,都会被回收掉。
而使用1.8时,因为这些代理类都是通过主线程的Classloader加载的,这个Classloader在程序运行的过程中永远也不会被回收,因此通过其加载的这些代理类也永远不会被回收,这就导致metaspace不断扩张,最终耗尽机器的内存了。
这个问题并不局限于fastjson,只要是需要通过程序加载创建类的地方,就有可能出现这种问题。尤其是在框架中,往往大量采用类似ASM、javassist等工具进行字节码增强,而根据上面的分析,在jdk1.8之前,因为大多数情况下动态加载的Class都能够在full gc时得到回收,因此不容易出现问题,也因此很多框架、工具包并没有针对这个问题做一些处理,一旦升级到1.8之后,这些问题就可能会暴露出来。
总结
问题解决了,接下来复盘下整个排查问题的流程,整个流程暴露了我很多问题,最主要的就是对于JVM不同版本的内存分配还不够熟悉,导致了对于老生代和元空间判断失误,走了很多弯路,在直接内存中排查了很久,浪费了很多时间。
其次,排查需要的一是仔细,二是全面,,最好将所有可能性先行整理好,不然很容易陷入自己设定好的排查范围内,走进死胡同不出来。
最后,总结一下这次的问题带来的收获:
- JDK1.8开始,自带的hostspot虚拟机取消了过去的永久区,而新增了metaspace区,从功能上看,metaspace可以认为和永久区类似,其最主要的功用也是存放类元数据,但实际的机制则有较大的不同。
- 对于JVM里面的内存需要在启动时进行限制,包括我们熟悉的堆内存,也要包括直接内存和元生区,这是保证线上服务正常运行最后的兜底。
- 使用类库,请多注意代码的写法,尽量不要出现明显的内存泄漏。
- 对于使用了ASM等字节码增强工具的类库,在使用他们时请多加小心(尤其是JDK1.8以后)。
文章撰写不易,请大家多多支持我的原创技术公众号:后端技术漫谈
参考
观察程序运行时类加载的过程
blog.csdn.net/tenderhearted/article/details/39642275
Metaspace整体介绍(永久代被替换原因、元空间特点、元空间内存查看分析方法)
https://www.cnblogs.com/duanxz/p/3520829.html
java内存占用异常问题常见排查流程(含堆外内存异常)
https://my.oschina.net/haitaohu/blog/3024843
JVM源码分析之堆外内存完全解读
http://lovestblog.cn/blog/2015/05/12/direct-buffer/
JVM 类的卸载
https://www.cnblogs.com/caoxb/p/12735525.html
fastjson在jdk1.8上面开启asm
https://github.com/alibaba/fastjson/issues/385
fastjson:PropertyNamingStrategy_cn
https://github.com/alibaba/fastjson/wiki/PropertyNamingStrategy_cn
警惕动态代理导致的Metaspace内存泄漏问题
https://blog.csdn.net/xyghehehehe/article/details/78820135
关注我
我是一名后端开发工程师。主要关注后端开发,数据安全,爬虫,物联网,边缘计算等方向,欢迎交流。
各大平台都可以找到我
- 微信公众号:后端技术漫谈
- Github:@qqxx6661
- CSDN:@蛮三刀把刀
- 知乎:@后端技术漫谈
- 简书:@蛮三刀把刀
- 掘金:@蛮三刀把刀
- 腾讯云+社区:@后端技术漫谈
原创文章主要内容
- 后端开发实战
- Java面试知识
- 设计模式/数据结构/算法题解
- 读书笔记/逸闻趣事/程序人生
个人公众号:后端技术漫谈

如果文章对你有帮助,不妨点赞,收藏起来~