“智源-MagicSpeechNet 家庭场景中文语音数据集挑战赛”上线

2019 年 12 月,北京智源人工智能研究院联合爱数智慧和数据评测平台 Biendata,共同发布了“智源 MagicSpeechNet 家庭场景中文语音数据集”,其中包含数百小时的真实家庭环境中的双人对话,每段对话基于多种平台进行录制,并已完全转录和标注。
Biendata同步开放了“智源 — MagicSpeechNet 家庭场景语音数据集挑战赛”(2019 年 12 月 — 次年 2 月),总奖金为10 万元。参赛者需要使用比赛提供的数据训练并优化模型。本次比赛由北京爱数智慧科技有限公司提供数据集。今年的“智源— MagicSpeechNet 家庭场景中文语音数据集挑战赛”旨在提升模型在家庭环境的对话语音识别效果,比赛和数据复制下方链接查看,或点击“阅读原文”。
比赛地址:
https://www.biendata.com/competition/magicdata/
赛事背景
随着互联网、智能硬件的普及,智能音箱和语音助手已经深入人们的日常生活,极大地提高了生活的便利性。家居场景下的语音识别技术成为了企业和研究机构研发的一大重点。
从语音识别的角度出发,家庭场景具有较强的多样性:不同的墙体和内装材料以及房间大小和构造会导致房间的声学参数的多样化。与此同时,语音识别产品的载体具有极大的差异性:语音助手一般搭载于用户的手机和智能音箱,不同的载体型号同样会影响声音信号的拾取和呈现。模型对于不同场景和不同设备的适应情况和识别效果极大地影响用户体验,考验着研发者的专业实力。因此可以说,家庭场景是语音识别领域内最典型也最具挑战的应用场景之一。
比赛任务
比赛希望优化语音识别的机器学习模型,可以根据真实家庭场景多设备多通道的录音数据以及对应的标注文本,实现语音识别模型在家庭场景下的性能提升。比赛结果对于智能家居领域下AI语音交互产品的研发的深入普及具有不容忽视的影响力。
比赛分为初赛与复赛两阶段,初赛于2019年12月23日开启,biendata 平台同步发布训练集、开发集、测试集,并开放初赛提交。2020年2月1日,初赛报名和组队时间截止。由于每日提交存在次数限制,请感兴趣的选手尽量选择提前参赛,以获得更多验证提交次数和优化模型的机会。
比赛数据
比赛数据分为训练集、开发集和测试集三部分,具体规模信息如下表所示:
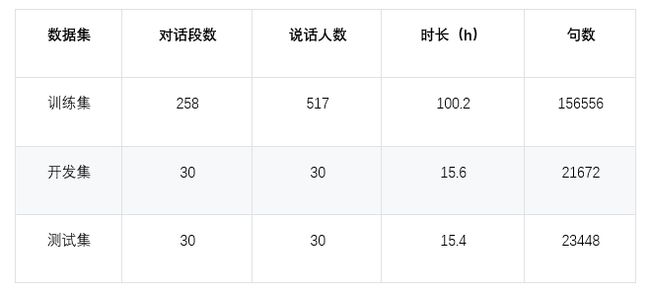
在训练集中,每段对话包括一个音频文件(.wav)和对应的标注文件(.json),如音频“MDT_F2F_001.wav”对应“MDT_F2F_001.json”。
在开发集中,每段对话有 5 个通道的同步录音,包括 3 个远讲通道和 2 个近讲通道。远讲通道包括由安卓平台、iOS 平台,录音笔录制的文件,如:
MDT_Conversation_001_Android.wav
MDT_Conversation_001_IOS.wav
MDT_Conversation_001_Recorder.wav
近讲数据使用高保真麦克风录制,根据不同讲话人区分,如:
MDT_Conversation_001_SPK001.wav
MDT_Conversation_001_SPK002.wav
在开发集中的标注文件(.json)中,“start_time”表示该音频片段的开始时间,“end_time”表示音频片段的终止时间,“words”表示转录的文本,“speaker”表示音频的讲话人,“location”表示音频录制的地点,“room_info”表示录制房间的信息,包括长、宽、高、混响时间(s),“devices_type”表示录制设备信息,“session_id”表示音频片段所在的整段音频 ID。

图:开发集标注文件样例
测试集数据为需要识别的音频文件,每段音频分为安卓平台、iOS 平台,录音笔录制的三个文件。为便于选手分割每段音频,比赛提供了标明起始和结束时间点信息的 json 文件,选手需使用模型识别音频中的对话,并根据 json 中对应的 uttid 提交相应的文本。
智源MagicSpeechNet 家庭场景中文语音数据集
智源 MagicSpeechNet 家庭场景中文语音数据集的语言材料来自于真实家居环境中的双人对话。基于多种平台进行录制,并已完全转录和标注。相较于国内外同类多通道语音识别比赛,本比赛数据在数量、场景、声音特性等方面具有以下优势。
(1)大量的对话数据
国内的语音识别比赛基本使用朗读类型的语音数据,而本比赛使用的数据为真实的对话数据。数据为完全真实场景的对话,说话人以放松和无脚本的方式,围绕所选主题自由对话。相比基于对话数据的国际同类比赛,在数据量方面仍旧具有极大的优势。同时,合理的说话人语音交叠更真实地体现日常家庭场景下的语音识别难度。
(2)场景真实多样
本数据集采集于3个真实的家庭场景,说话人以放松和无脚本的方式,围绕所选主题自由对话。不同的采集环境丰富了数据的多样性,同时增强了比赛的难度。
(3)近讲与多平台远讲数据结合
每段对话有 5 个通道的同步录音,包括 3 个远讲通道和2 个近讲通道。远讲通道分别由多个型号的安卓手机,苹果手机和录音笔录制,充分体现多平台录音数据的特性;近讲数据使用高保真麦克风录制,与说话人的嘴保持10 cm 的距离。
(4)丰富均衡的声音特性
本数据集拥有丰富均衡的声音特性。录制本数据集的说话人来自中国大陆不同地域,存在一定的普通话口音。同时,说话人选自不同年龄段,性别均衡。
参赛方式
点击阅读原文链接或扫描下图中的二维码直达赛事页面,注册网站-下载数据,即可参赛。

▶友情提示,因涉及到数据下载,强烈建议大家登录 PC 页面报名参加。
智源人工智能系列竞赛
2019 年 9 月,智源人工智能算法大赛正式启动。本次比赛由北京智源人工智能研究院主办,爱数智慧、清华大学、北京大学、中科院计算所、旷视、知乎等协办,总奖金超过 100 万元,旨在以全球领先的科研数据集与算法竞赛为平台,选拔培育人工智能创新人才。
北京智源人工智能研究院院长、北京大学教授黄铁军介绍:智源的中心任务是在北京建成全球最优的人工智能创新生态,核心是选拔培育人工智能顶尖人才和发展潜力大的青年学术英才。研究院副院长刘江也表示:“我们希望不拘一格来支持人工智能真正的标志性突破,即使是本科生,如果真的是好苗子,我们也一定支持。”而人工智能大赛就是发现有潜力的年轻学者的重要途径。
本次智源人工智能算法大赛有两个重要的目的,一是通过发布数据集和数据竞赛的方式,推动基础研究的进展。特别是可以让计算机领域的学者参与到其它学科的基础科学研究中。二是可以通过比赛筛选、锻炼相关领域的人才。截止到目前,智源人工智能系列大赛已开展 5 场,分别涵盖了神经生物学、自然语言处理、机器视觉等领域。在年底前,智源研究院还将陆续发布 3 道赛题,敬请大家期待!
目前正在角逐的比赛:
智源-知乎2019看山杯专家算法发现大赛
https://www.biendata.com/competition/zhihu2019/
智源-超高清晰电镜图像分割挑战赛 神经元识别大赛
https://www.biendata.com/competition/urisc/
智源-高能对撞粒子分类挑战赛
https://www.biendata.com/competition/jet/
- 往期文章 -



