GEE代码修改替换内容-毕设版
文章目录
-
- 修改内容
- 数据名称梳理&思路
- 代码的核心部分
- ArcGIS部分操作
修改内容
-
【MCD43A4.061】之前那个deprecated了,网友说可以用,但是我还是不用了。

-
【研究区范围】NEChina→MLYR_China(替换数据)
-
【作物底图】cornimage→CHN_Maize_2019(替换数据)
-
【时间】2017、2018、2019、2020分别改为2019、2020、2021、2022。(VI计算是用2017-2019,那就不改,只把2020年改成2022年)
-
【修改代码】(change和sensitivity都是imagecollection,不能直接subtract做差)(已改)。
-
【DOY】用8天最大值合成法生成植被指数各年的影像的话,在计算基准年多年平均值、异常值的时候可以改成16天或者是月 。【师兄的指导:不同时间尺度(8,16,月)合成的目的是为了更好的分析时间序列的变化,时间尺度越细,所能看到的动态变化过程就约精细,当然有时候也不是时间尺度越细越好,所以你说的使用不同时间尺度进行合成分析也是合理的】
-
【相对变化率绝对值很大的像元】根据数据砍掉。【我的想法:如果相对变化率绝大部分的绝对值介于0和100%之间,则剔除100%之外的。如果还有小部分介于100%-200%,剔除200%之外的,这样合理嘛?——师兄认为合理】
数据名称梳理&思路
【• import数据:
MLYR_China:行政边界。
CHN_Maize_2019:作物底图。image
imageCollection:MODIS的数据集
• ndvi、evi、nirv、lswi都是波段的组合,添加进了一个新图像img中。
• Collection2022:ImageCollection;有150张image(5月11-10月11每天四个波段)
• Composites_2022(8天最大值合成法生成2022年131-284d的影像):ImageCollection;有20张image;4个bands,如ndvi_max
• MultiMean(2019-2021年的多年平均值):ImageCollection;有20张image;4个bands,如ndvi_max_mean
• change(Composites_2022与MultiMean对应日期的差值):ImageCollection;有20张image;1个band,ndvi_max_mean或其它
• change_divided(change与MultiMean的比值):ImageCollection;有20张image;1个band,ndvi_max_mean或其它】
代码的核心部分
var Composites_2022 = ee.ImageCollection(ee.List.sequence(131,284,8).map(function(doy){
var doy = ee.Number(doy)
var t = start.advance(doy, 'day').millis();
var filtered = Collection2022.filter(ee.Filter.calendarRange(doy, doy.add(7), 'day_of_year')).reduce(ee.Reducer.max());
var bandLength = filtered.bandNames().length();
return filtered
.set('system:time_start',start.advance(doy, 'day'),'doy',doy,'t',t,'length',bandLength);
}));
print(Composites_2022,'Composites_2022');
//Multi mean compoiste;计算2019-2021年这些8天合成影像的平均值并print
var Composites_1921 = Composites_2019.merge(Composites_2020).merge(Composites_2021)
var MultiMean = ee.ImageCollection(ee.List.sequence(131,284,8).map(function(doy){
var doy = ee.Number(doy);
var t = start.advance(doy, 'day').millis();
var filtered =Composites_1921.filter(ee.Filter.eq('doy',doy)).reduce(ee.Reducer.mean())
var bandLength = filtered.bandNames().length();
return filtered
.set('system:time_start',start.advance(doy, 'day'),'doy',doy,'t',t,'length',bandLength);
}));
var change = ee.ImageCollection(ee.List.sequence(131, 284, 8).map(function(doy) {
var doy = ee.Number(doy);
var t = start.advance(doy, 'day').millis();
var filtered = Composites_2022.filter(ee.Filter.eq('doy', doy))
.reduce(ee.Reducer.mean());
var bandLength = filtered.bandNames().length();
var changeImg = filtered.subtract(MultiMean.filterMetadata('doy', 'equals', doy)
.first())
//.select(filtered.bandNames().get(0))
.select(["ndvi_max_mean"])
.set('system:time_start', start.advance(doy, 'day'))
.set('doy', doy)
.set('t', t)
.set('length', bandLength);
return changeImg;
}));
var change_divided = change.map(function(img) {
var doy = img.get('doy');
var ndvi_max_mean = MultiMean.filterMetadata('doy', 'equals', doy)
.first()
.select('ndvi_max_mean');
return img.divide(ndvi_max_mean)
.set('system:time_start', img.get('system:time_start'))
.set('doy', doy)
.set('t', img.get('t'))
.set('length', img.get('length'))
//.set('ndvi_max_mean', ndvi_max_mean);
});

对时间序列数据进行标准差计算的意义在于,可以了解研究区在不同时间段内的数据变化情况。当时间序列数据的标准差较大时,说明影像在这段时间内动态变化较大,可能代表着一些随时间变化的现象,例如植被状况、灌溉情况、陆地覆盖变化等。
标准差也可以用于判断数据中是否存在异常值。如果数据值超出了平均值(或中位数)加减两倍的标准差范围内,那么该数据点可能是一个异常值。
3月30日
终于把后两句代码搞出来了,但是输出的值很奇怪,提问chatgpt(为什么最后算出来的change_divided的image的value基本是正负几十的浮点值?你认为这合理吗?他不应该是个大于-1并且小于1的小数吗?),答复如下:
【可能是因为在计算过程中存在误差或者不合理的计算方式。比如,在change_divided中的代码中,img除以了ndvi_max_mean,但是在MultiMean中的filtered可能存在0的值,从而导致除法计算中出现了错误的结果。另外,在change和MultiMean两个ImageCollection的计算中,可能存在噪声和异常值的影响,也可能存在其他的计算误差。因此,你可以检查一下代码中的计算方式,看是否存在可以优化的地方,另外,也可以考虑对数据进行一些预处理,例如去除异常值等。】
0409更新:
老师建议取一个pixel,生成它的时间序列曲线从而验证分析。我搜了个代码:https://www.jianshu.com/p/8a96ae988cf0
ArcGIS部分操作
【作物底图:融合2019、2020、2021年三年水稻、玉米、小麦的种植分布数据
先对水稻的三年数据取交集,再对玉米、小麦……;再合并它们三。
1、clip:用MLYR的边界裁剪
2、Reclassify:将无作物的value设置为NoData
3、属性表中分别add fields,设置玉米为1,水稻为2
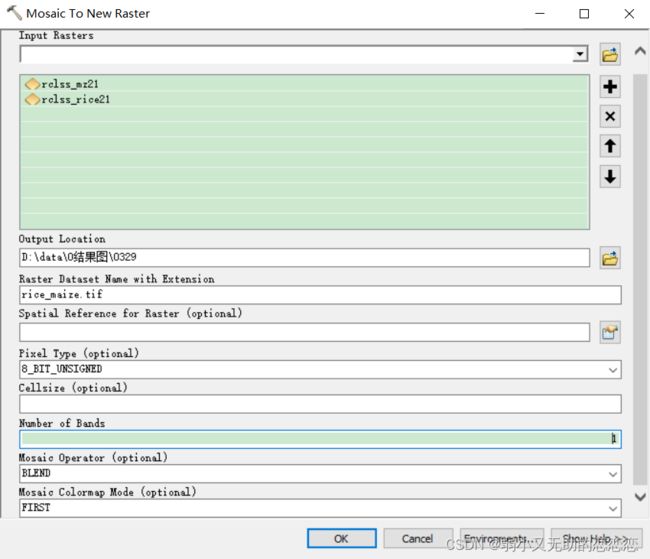
4、Mosaic To New Raster:{有两个栅格数据,都是以value字段显示,都有A字段,我想合并它们取交集并且以A字段进行合并,怎么做?}
Mosaic To New Raster / raster calculator /
Con((“rclss_mz21” > 0) & (“rclss_rice21” > 0), 1, 0), Join(“pixel”, “rclss_mz21”, “pixel”, “rclss_rice21”)
GEE上取交集再取并集的代码:https://code.earthengine.google.com/89711cded8be62ad07f91fae12b4e517】
【师兄论文里有一句“考虑到MODIS 数据的低分辨率(500m),研究将 10 米空间分辨率玉米分布底图聚合到500 米空间分辨率的玉米的面积比例图,以匹配 MODIS 数据……筛选出玉米比例超过50%的像素。“
如何实现?
1)Aggregate工具;聚合半径输入500米空间分辨率到10米空间分辨率的缩放比例(例如:50)。运行工具,得到基于500米空间分辨率的玉米聚合数据。
2)“Zonal Statistics as Table”工具或“栅格计算器”工具,计算得到面积比例图层。
Zonal Statistics as Table——输入栅格:10米空间分辨率的玉米分布底图;输入分区数据:聚合后的500米空间分辨率图;统计类型为“SUM”——注意,这里输出的是一个表格,表格sum字段中的数值即为每个500米空间分辨率区域内玉米的面积总和。
将表格连接到500m分辨率的图的属性表上;剔除<50%的像元;分类渲染得到面积比例图。
消除细碎斑块:http://www.360doc.com/content/17/0420/02/25010725_646980356.shtml】
【行政边界的外边界:某地区的行政区划shp数据有3个省,属性表有3个元素,在arcgis里消除它们的内部边界,只留下外部大边界——属性表里新建字段“border”,文本型,赋值相同文本(比如“1”),选中这3个元素,editor–start editing–merge–选择一个要素。即可得到外部边界(注意这个修改是直接改属性表的,原始数据直接被覆盖,因此建议做好数据备份!)】