dolphinscheduler1.3版本源码分析---API模块
API模块主要功能
api模块主要提供对外接口,界面上的对流程、定时的管理等相关操作都是通过调用API模块的接口实现的,API模块直接跟数据库打交道,不会与master和worker模块交互。
相关接口概览

同时由于api模块集成了swagger,我们可以通过访问 http://xxxx/dolphinscheduler/doc.html来查看详细的API说明
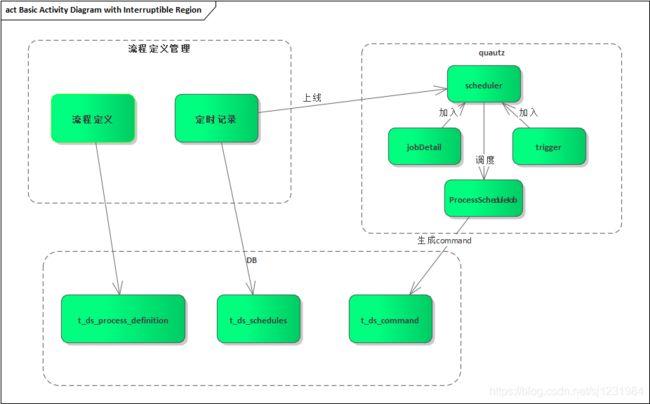
流程定时调度逻辑
当我们创建好流程,并对流程增加定时管理后,dolphin是如何定时去调度流程的呢?该部分逻辑其实也是在API模块,分析如下:
1.现在我们创建一个流程定义:并将流程上线
创建流程源码逻辑在
ProcessDefinitionController下的createProcessDefinition方法中,主要是在数据库表t_ds_process_definition中增加了一条记录
上线流程的源码逻辑在:
ProcessDefinitionController下的releaseProcessDefinition方法中,主要是更改记录的状态字段

2、对该流程创建一条定时记录并将定时记录上线,如下图:
创建定时记录的源码逻辑在SchedulerController类中的createSchedule中;上线定时记录的源码逻辑在SchedulerController的online中。

3、上线动作触发的调度
dolphin是通过quartz实现流程的调度的,我们知道quartz实现调度需要三个对象,分别是scheduler,jobDetail和trigger。
上线的源码里其实就是创建jobDetail和trigger并将这俩个对象加入到scheduler中的过程。
try {
switch (scheduleStatus) {
case ONLINE: {
logger.info("Call master client set schedule online, project id: {}, flow id: {},host: {}", project.getId(), processDefinition.getId(), masterServers);
setSchedule(project.getId(), id);
break;
}
case OFFLINE: {
logger.info("Call master client set schedule offline, project id: {}, flow id: {},host: {}", project.getId(), processDefinition.getId(), masterServers);
deleteSchedule(project.getId(), id);
break;
}
default: {
putMsg(result, Status.SCHEDULE_STATUS_UNKNOWN, scheduleStatus.toString());
return result;
}
}
} catch (Exception e) {
result.put(Constants.MSG, scheduleStatus == ReleaseState.ONLINE ? "set online failure" : "set offline failure");
throw new RuntimeException(result.get(Constants.MSG).toString());
}上图的中的判断如果为上线的操作则会走setSchedule方法,schedule方法如下
public void setSchedule(int projectId, int scheduleId) throws RuntimeException{
logger.info("set schedule, project id: {}, scheduleId: {}", projectId, scheduleId);
Schedule schedule = processService.querySchedule(scheduleId);
if (schedule == null) {
logger.warn("process schedule info not exists");
return;
}
Date startDate = schedule.getStartTime();
Date endDate = schedule.getEndTime();
String jobName = QuartzExecutors.buildJobName(scheduleId);
String jobGroupName = QuartzExecutors.buildJobGroupName(projectId);
Map dataMap = QuartzExecutors.buildDataMap(projectId, scheduleId, schedule);
QuartzExecutors.getInstance().addJob(ProcessScheduleJob.class, jobName, jobGroupName, startDate, endDate,
schedule.getCrontab(), dataMap);
} 最后一行的addJob为重点,前面的代码主要生成job的一些基本信息。下图为addJob方法中向scheduler中增加jobDetail的代码
public void addJob(Class clazz,String jobName,String jobGroupName,Date startDate, Date endDate,
String cronExpression,
Map jobDataMap) {
lock.writeLock().lock();
try {
JobKey jobKey = new JobKey(jobName, jobGroupName);
JobDetail jobDetail;
//add a task (if this task already exists, return this task directly)
if (scheduler.checkExists(jobKey)) {
jobDetail = scheduler.getJobDetail(jobKey);
if (jobDataMap != null) {
jobDetail.getJobDataMap().putAll(jobDataMap);
}
} else {
jobDetail = newJob(clazz).withIdentity(jobKey).build();
if (jobDataMap != null) {
jobDetail.getJobDataMap().putAll(jobDataMap);
}
scheduler.addJob(jobDetail, false, true);
logger.info("Add job, job name: {}, group name: {}",
jobName, jobGroupName);
} 下面的代码为向scheduler中增加trigger的方法,trigger对象使用了定时记录中的cron表达式字段的值
CronTrigger cronTrigger = newTrigger().withIdentity(triggerKey).startAt(startDate).endAt(endDate)
.withSchedule(cronSchedule(cronExpression).withMisfireHandlingInstructionDoNothing())
.forJob(jobDetail).build();
if (scheduler.checkExists(triggerKey)) {
// updateProcessInstance scheduler trigger when scheduler cycle changes
CronTrigger oldCronTrigger = (CronTrigger) scheduler.getTrigger(triggerKey);
String oldCronExpression = oldCronTrigger.getCronExpression();
if (!StringUtils.equalsIgnoreCase(cronExpression,oldCronExpression)) {
// reschedule job trigger
scheduler.rescheduleJob(triggerKey, cronTrigger);
logger.info("reschedule job trigger, triggerName: {}, triggerGroupName: {}, cronExpression: {}, startDate: {}, endDate: {}",
jobName, jobGroupName, cronExpression, startDate, endDate);
}
} else {
scheduler.scheduleJob(cronTrigger);
logger.info("schedule job trigger, triggerName: {}, triggerGroupName: {}, cronExpression: {}, startDate: {}, endDate: {}",
jobName, jobGroupName, cronExpression, startDate, endDate);
}至此任务和trigger都加入到scheduler中了,quartz会给我们管理具体的调度逻辑,当到cron表达式指定的时间时,会自动触发调用ProcessScheduleJob中的execute方法。
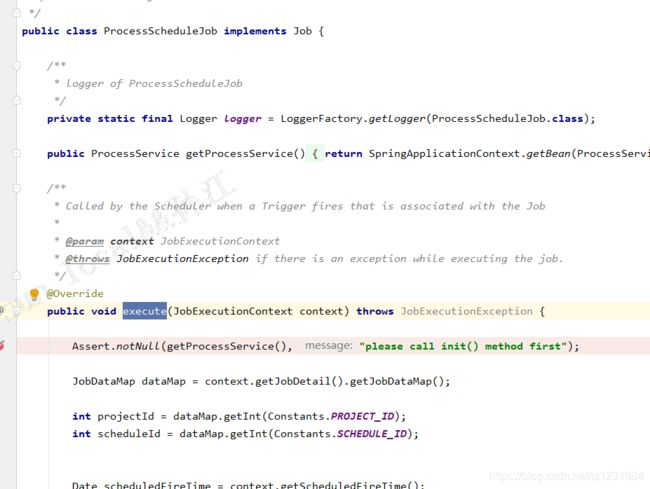
exccute方法中的主要逻辑其实就是生产一条command记录,保存到t_ds_command表中
ProcessDefinition processDefinition = getProcessService().findProcessDefineById(schedule.getProcessDefinitionId());
// release state : online/offline
ReleaseState releaseState = processDefinition.getReleaseState();
if (processDefinition == null || releaseState == ReleaseState.OFFLINE) {
logger.warn("process definition does not exist in db or offline,need not to create command, projectId:{}, processId:{}", projectId, scheduleId);
return;
}
Command command = new Command();
command.setCommandType(CommandType.SCHEDULER);
command.setExecutorId(schedule.getUserId());
command.setFailureStrategy(schedule.getFailureStrategy());
command.setProcessDefinitionId(schedule.getProcessDefinitionId());
command.setScheduleTime(scheduledFireTime);
command.setStartTime(fireTime);
command.setWarningGroupId(schedule.getWarningGroupId());
String workerGroup = StringUtils.isEmpty(schedule.getWorkerGroup()) ? Constants.DEFAULT_WORKER_GROUP : schedule.getWorkerGroup();
command.setWorkerGroup(workerGroup);
command.setWarningType(schedule.getWarningType());
command.setProcessInstancePriority(schedule.getProcessInstancePriority());
getProcessService().createCommand(command);至此我们就分析完了API模块的流程调度相关的逻辑,总结如下: