经点面试题:mybatis的执行流程
回答这个问题前我们先来看一下mybatis的架构图,从架构图中可以简略的知道其执行流程(由接口层->数据处理层->基础支持层),实际上操作数据库时候的执行过程也是要经过这几个层的。
下面部分部分文字和图片参考大神的,大神连接
MyBatis 最上面是接口层,接口层就是开发人员在 Mapper 或者是 Dao 接口中的接口定义,是查询、新增、更新还是删除操作;中间层是数据处理层,主要是配置 Mapper -> XML 层级之间的参数映射,SQL 解析,SQL 执行,结果映射的过程。上述两种流程都由基础支持层来提供功能支撑,基础支持层包括连接管理,事务管理,配置加载,缓存处理等。
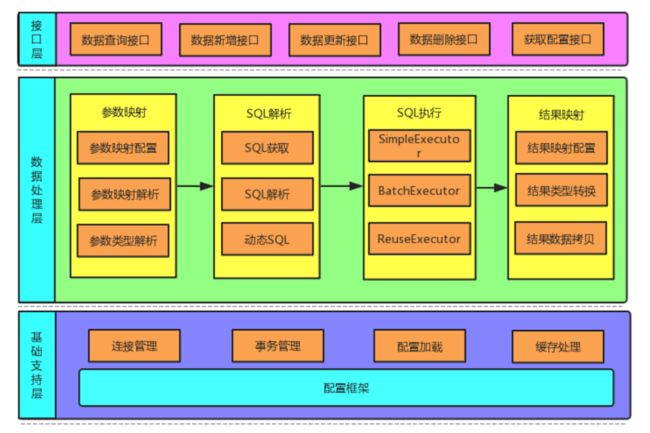
接口层
主要面向程序员操作数据库数据的接口API
InputStream is = Resources.getResourceAsStream("myBatis-config.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(is);
sqlSession = factory.openSession();SqlSessionFactory和SqlSession是mybatis的核心接口,尤其是 SqlSession,这个接口是MyBatis 中最重要的接口,这个接口能够让你执行命令,获取映射,管理事务。
数据处理层
1、配值解析
mybatis在启动的时候会加载mybatis-config.xml文件,并解析此文件,解析后的文件放进configuration对象中,configuration对象中的属性几乎和mybatis-config.xml文件中各个节点名字一样。之后会创建SqlSessionFactory对象,可以通过此对象创建出Sql Session对象如接口层代码那样。
2、SQL解析和scripting模块
Mybatis 实现的动态 SQL 语句,几乎可以编写出所有满足需要的 SQL。Mybatis 中 scripting 模块会根据用户传入的参数,解析映射文件中定义的动态 SQL 节点,形成数据库能执行的SQL 语句。
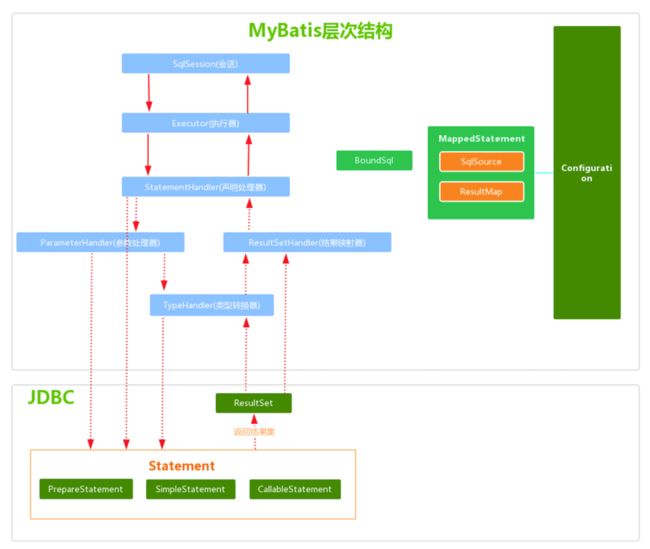
3、SQL执行
SQL 语句的执行涉及多个组件,包括 MyBatis 的四大核心。他们是:
Executor、StatementHandler、ParameterHandler、ResultSetHandler
sql执行流程如下图:
基础支持层
反射,类型转换,缓存,日志,事务,这些功能都在这一层
mybatis中的重要组件如下:
SqlSession: ,它是 MyBatis 核心 API,主要用来执行命令,获取映射,管理事务。接收开发人员提供 Statement Id 和参数。并返回操作结果。Executor:执行器,是 MyBatis 调度的核心,负责 SQL 语句的生成以及查询缓存的维护。StatementHandler: 封装了JDBC Statement 操作,负责对 JDBC Statement 的操作,如设置参数、将Statement 结果集转换成 List 集合。ParameterHandler: 负责对用户传递的参数转换成 JDBC Statement 所需要的参数。ResultSetHandler: 负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合。TypeHandler: 用于 Java 类型和 JDBC 类型之间的转换。MappedStatement: 映射文件的select,insert等标签都解析成此对象SqlSource: 表示从 XML 文件或注释读取的映射语句的内容,它创建将从用户接收的输入参数传递给数据库的 SQL。Configuration: MyBatis 所有的配置信息都维持在 Configuration 对象之中。
下面从源码的角度来看看这些组件如何初始化和工作的。
配值文件:
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(is);进入build方法:

接着跟进parse方法,
//在创建XMLConfigBuilder时,它的构造方法中解析器XPathParser已经读取了配置文件
//3. 进入XMLConfigBuilder 中的 parse()方法。
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
//parser是XPathParser解析器对象,读取节点内数据,是MyBatis配置文件中的顶层标签
parseConfiguration(parser.evalNode("/configuration"));
//最后返回的是Configuration 对象
return configuration;
}
//4. 进入parseConfiguration方法
//此方法中读取了各个标签内容并封装到Configuration中的属性中。
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
根据配值文件,我们的代码会在 environmentsElement(root.evalNode("environments"));进去此函数:
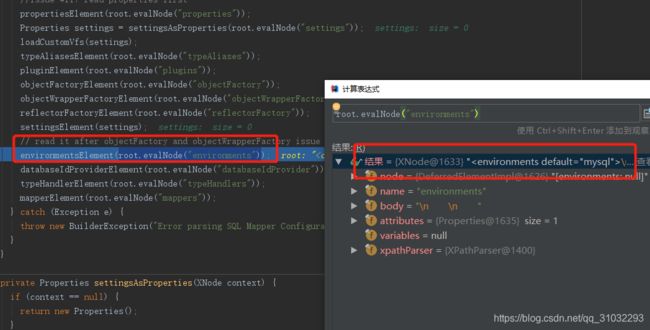
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
第一次进入肯定为null,得到mybatis的数据库环境是mysql的还是其其他的
if (environment == null) {
environment = context.getStringAttribute("default");
}
遍历 节点的子节点即节点,这里可返回源码一开始分析的xml文件看看有哪些子节点
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) {
//解析节点
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
//解析节点
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
将解析到的对象封装成configuration的属性environment
configuration.setEnvironment(environmentBuilder.build());
}
}
}
} 上面函数执行完毕后返回parseConfiguration函数,然后继续向下执行typeHandlers标签在上面已经详细讲过。

接下来我们看解析
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
//遍历子标签,子标签有好几种写法,这边对应好几种判断,上面提到过子标签的几种写法
for (XNode child : parent.getChildren()) {
// 对应一步步到了mapperParser.parse();这个函数,我们重点分析,他是如何把xml的节点转换成mybatis的数据结构的。
先看看映射文件中的顶级标签
SQL 映射文件有很少的几个顶级元素(按照它们应该被定义的顺序)
1 cache 给定命名空间的缓存配置
2 cache-ref 其他命名空间的缓存配置的引用
3 resultMap 是最富复杂也是最强大的元素,是用来描述如何从数据库结果集中来加载对象
4 sql – 可被其他语句引用的可重用语句块
5 insert – 映射插入语句
6 update – 映射更新语句
7 delete – 映射删除语句
8 select – 映射查询语句
public void parse() {
// 检测映射文件是否已经被解析过
if (!configuration.isResourceLoaded(resource)) {
// 解析 mapper 节点
configurationElement(parser.evalNode("/mapper"));
// 添加资源路径到“已解析资源集合”中
configuration.addLoadedResource(resource);
// 通过命名空间绑定 Mapper 接口
bindMapperForNamespace();
}
// 处理未完成解析的节点
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}如上,映射文件解析入口逻辑包含三个核心操作,分别如下:
- 解析 mapper 节点
- 通过命名空间绑定 Mapper 接口
- 处理未完成解析的节点
进入解析mapper节点的函数,解析之前先看看映射文件的结构
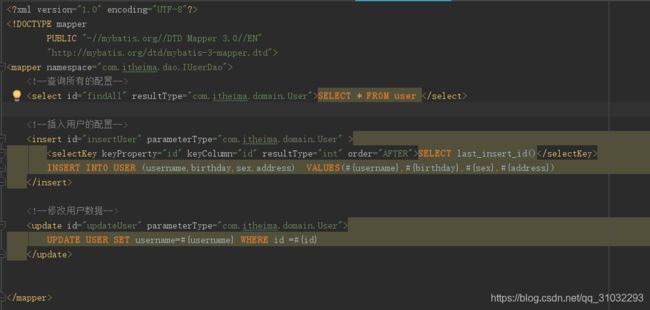
上面是一个比较简单的映射文件,还有一些的节点没有出现在上面。以上每种配置中的每种节点的解析逻辑都封装在了相应的方法中,这些方法由 XMLMapperBuilder 类的 configurationElement 方法统一调用
private void configurationElement(XNode context) {
try {
// 获取 mapper 命名空间
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 设置命名空间到 builderAssistant 中
builderAssistant.setCurrentNamespace(namespace);
// // 解析 节点
cacheRefElement(context.evalNode("cache-ref"));
// 解析 节点,MyBatis 提供了一、二级缓存,其中一级缓存是 SqlSession 级别的,默认为开启状态。二级缓存配置在映射文件中,使用者需要显示配置才能开启
cacheElement(context.evalNode("cache"));
// 已废弃配置,这里不做分析
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析 节点
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析 节点
sqlElement(context.evalNodes("/mapper/sql"));
// 解析 我们只针对我们的映射文件里的节点做重点介绍,
解析 节点(虽然文件中没出现,但是还是看一下)
resultMap 是 MyBatis 框架中常用的特性,主要用于映射结果。resultMap 元素是 MyBatis 中最重要最强大的元素,它可以把大家从 JDBC ResultSets 数据提取的工作中解放出来。通过 resultMap 和自动映射,可以让 MyBatis 帮助我们完成 ResultSet → Object 的映射
private ResultMap resultMapElement(XNode resultMapNode, List additionalResultMappings) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
// 获取 id 和 type 属性
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
// 获取 extends 和 autoMapping
String extend = resultMapNode.getStringAttribute("extends");
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
//通过反射获取类型
Class typeClass = resolveClass(type);
Discriminator discriminator = null;
List resultMappings = new ArrayList();
// 获取并遍历 的子节点列表
resultMappings.addAll(additionalResultMappings);
List resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
// 解析 constructor 节点,并生成相应的 ResultMapping
if ("constructor".equals(resultChild.getName())) {
processConstructorElement(resultChild, typeClass, resultMappings);
// 解析 discriminator 节点
} else if ("discriminator".equals(resultChild.getName())) {
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
List flags = new ArrayList();
// 添加 ID 到 flags 集合中
if ("id".equals(resultChild.getName())) {
flags.add(ResultFlag.ID);
}
// 解析 id 和 property 节点,并生成相应的 ResultMapping
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
// 根据前面获取到的信息构建 ResultMap 对象
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
} 上面的代码比较多,看起来有点复杂,这里总结一下:
- 获取
节点的各种属性 - 遍历
的子节点,并根据子节点名称执行相应的解析逻辑 - 构建 ResultMap 对象
- 若构建过程中发生异常,则将 resultMapResolver 添加到 incompleteResultMaps 集合中
如上流程,第1步和最后一步都是一些常规操作,无需过多解释。第2步和第3步则是接下来需要重点分析的操作,这其中,鉴别器 discriminator 不是很常用的特性,我觉得大家知道它有什么用就行了,所以就不分析了。下面先来分析
解析
在
private ResultMapping buildResultMappingFromContext(XNode context, Class resultType, List flags) throws Exception {
String property;
// 根据节点类型获取 name 或 property 属性
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
property = context.getStringAttribute("name");
} else {
property = context.getStringAttribute("property");
}
// 获取其他各种属性
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String nestedSelect = context.getStringAttribute("select");
/*
* 解析 resultMap 属性,该属性出现在 和 节点中。
* 若这两个节点不包含 resultMap 属性,则调用 processNestedResultMappings 方法
* 解析嵌套 resultMap。
*/
String nestedResultMap = context.getStringAttribute("resultMap",
processNestedResultMappings(context, Collections. emptyList()));
String notNullColumn = context.getStringAttribute("notNullColumn");
String columnPrefix = context.getStringAttribute("columnPrefix");
String typeHandler = context.getStringAttribute("typeHandler");
String resultSet = context.getStringAttribute("resultSet");
String foreignColumn = context.getStringAttribute("foreignColumn");
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
Class javaTypeClass = resolveClass(javaType);
@SuppressWarnings("unchecked")
Class> typeHandlerClass = (Class>) resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
} 上面的方法主要用于获取
第一种配置方式是通过 resultMap 属性引用其他的
第二种配置方式是采取 resultMap 嵌套的方式进行配置,如下:
如上配置,
private String processNestedResultMappings(XNode context, List resultMappings) throws Exception {
// 判断节点名称
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
if (context.getStringAttribute("select") == null) {
// resultMapElement 是解析 ResultMap 入口方法
ResultMap resultMap = resultMapElement(context, resultMappings);
// 返回 resultMap id
return resultMap.getId();
}
}
return null;
} 如上,
关于嵌套 resultMap 的解析逻辑就先分析到这,下面分析 ResultMapping 的构建过程。
public ResultMapping buildResultMapping(
Class resultType,
String property,
String column,
Class javaType,
JdbcType jdbcType,
String nestedSelect,
String nestedResultMap,
String notNullColumn,
String columnPrefix,
Class> typeHandler,
List flags,
String resultSet,
String foreignColumn,
boolean lazy) {
/*
* 若 javaType 为空,这里根据 property 的属性进行解析。关于下面方法中的参数,
* 这里说明一下:
* - resultType:即 composites = parseCompositeColumnName(column);
// 通过建造模式构建 ResultMapping
return new ResultMapping.Builder(configuration, property, column, javaTypeClass)
.jdbcType(jdbcType)
.nestedQueryId(applyCurrentNamespace(nestedSelect, true))
.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true))
.resultSet(resultSet)
.typeHandler(typeHandlerInstance)
.flags(flags == null ? new ArrayList() : flags)
.composites(composites)
.notNullColumns(parseMultipleColumnNames(notNullColumn))
.columnPrefix(columnPrefix)
.foreignColumn(foreignColumn)
.lazy(lazy)
.build();
}
// -☆- ResultMapping.Builder
public ResultMapping build() {
// 将 flags 和 composites 两个集合变为不可修改集合
resultMapping.flags = Collections.unmodifiableList(resultMapping.flags);
resultMapping.composites = Collections.unmodifiableList(resultMapping.composites);
// 从 TypeHandlerRegistry 中获取相应 TypeHandler
resolveTypeHandler();
validate();
return resultMapping;
} ResultMapping 的构建过程不是很复杂,首先是解析 javaType 类型,并创建 typeHandler 实例。然后处理复合 column。最后通过建造器构建 ResultMapping 实例。关于上面方法中出现的一些方法调用,这里接不跟下去分析了,大家可以自己看看。
ResultMap 对象构建过程分析
private ResultMap resultMapElement(XNode resultMapNode, List additionalResultMappings) throws Exception {
// 获取 resultMap 节点中的属性
// ...
// 解析 resultMap 对应的类型
// ...
// 遍历 resultMap 节点的子节点,构建 ResultMapping 对象
// ...
// 创建 ResultMap 解析器
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend,
discriminator, resultMappings, autoMapping);
try {
// 根据前面获取到的信息构建 ResultMap 对象
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
} 如上,ResultMap 的构建逻辑分装在 ResultMapResolver 的 resolve 方法中,下面我从该方法进行分析。
// -☆- ResultMapResolver
public ResultMap resolve() {
return assistant.addResultMap(this.id, this.type, this.extend, this.discriminator, this.resultMappings, this.autoMapping);
}
上面的方法将构建 ResultMap 实例的任务委托给了 MapperBuilderAssistant 的 addResultMap,我们跟进到这个方法中看看。
// -☆- MapperBuilderAssistant
public ResultMap addResultMap(
String id, Class type, String extend, Discriminator discriminator,
List resultMappings, Boolean autoMapping) {
// 为 ResultMap 的 id 和 extend 属性值拼接命名空间
id = applyCurrentNamespace(id, false);
extend = applyCurrentNamespace(extend, true);
if (extend != null) {
if (!configuration.hasResultMap(extend)) {
throw new IncompleteElementException("Could not find a parent resultmap with id '" + extend + "'");
}
ResultMap resultMap = configuration.getResultMap(extend);
List extendedResultMappings = new ArrayList(resultMap.getResultMappings());
// 为拓展 ResultMappings 取出重复项
extendedResultMappings.removeAll(resultMappings);
boolean declaresConstructor = false;
// 检测当前 resultMappings 集合中是否包含 CONSTRUCTOR 标志的元素
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
declaresConstructor = true;
break;
}
}
/*
* 如果当前 节点中包含 子节点,
* 则将拓展 ResultMapping 集合中的包含 CONSTRUCTOR 标志的元素移除
*/
if (declaresConstructor) {
Iterator extendedResultMappingsIter = extendedResultMappings.iterator();
while (extendedResultMappingsIter.hasNext()) {
if (extendedResultMappingsIter.next().getFlags().contains(ResultFlag.CONSTRUCTOR)) {
extendedResultMappingsIter.remove();
}
}
}
// 将扩展 resultMappings 集合合并到当前 resultMappings 集合中
resultMappings.addAll(extendedResultMappings);
}
// 构建 ResultMap
ResultMap resultMap = new ResultMap.Builder(configuration, id, type, resultMappings, autoMapping)
.discriminator(discriminator)
.build();
configuration.addResultMap(resultMap);
return resultMap;
} 上面的方法主要用于处理 resultMap 节点的 extend 属性,extend 不为空的话,这里将当前 resultMappings 集合和扩展 resultMappings 集合合二为一。随后,通过建造模式构建 ResultMap 实例。过程如下:
// -☆- ResultMap
public ResultMap build() {
if (resultMap.id == null) {
throw new IllegalArgumentException("ResultMaps must have an id");
}
resultMap.mappedColumns = new HashSet();
resultMap.mappedProperties = new HashSet();
resultMap.idResultMappings = new ArrayList();
resultMap.constructorResultMappings = new ArrayList();
resultMap.propertyResultMappings = new ArrayList();
final List constructorArgNames = new ArrayList();
for (ResultMapping resultMapping : resultMap.resultMappings) {
/*
* 检测 或 节点
* 是否包含 select 和 resultMap 属性
*/
resultMap.hasNestedQueries = resultMap.hasNestedQueries || resultMapping.getNestedQueryId() != null;
resultMap.hasNestedResultMaps =
resultMap.hasNestedResultMaps || (resultMapping.getNestedResultMapId() != null && resultMapping.getResultSet() == null);
final String column = resultMapping.getColumn();
if (column != null) {
// 将 colum 转换成大写,并添加到 mappedColumns 集合中
resultMap.mappedColumns.add(column.toUpperCase(Locale.ENGLISH));
} else if (resultMapping.isCompositeResult()) {
for (ResultMapping compositeResultMapping : resultMapping.getComposites()) {
final String compositeColumn = compositeResultMapping.getColumn();
if (compositeColumn != null) {
resultMap.mappedColumns.add(compositeColumn.toUpperCase(Locale.ENGLISH));
}
}
}
// 添加属性 property 到 mappedProperties 集合中
final String property = resultMapping.getProperty();
if (property != null) {
resultMap.mappedProperties.add(property);
}
// 检测当前 resultMapping 是否包含 CONSTRUCTOR 标志
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 添加 resultMapping 到 constructorResultMappings 中
resultMap.constructorResultMappings.add(resultMapping);
// 添加属性(constructor 节点的 name 属性)到 constructorArgNames 中
if (resultMapping.getProperty() != null) {
constructorArgNames.add(resultMapping.getProperty());
}
} else {
// 添加 resultMapping 到 propertyResultMappings 中
resultMap.propertyResultMappings.add(resultMapping);
}
if (resultMapping.getFlags().contains(ResultFlag.ID)) {
// 添加 resultMapping 到 idResultMappings 中
resultMap.idResultMappings.add(resultMapping);
}
}
if (resultMap.idResultMappings.isEmpty()) {
resultMap.idResultMappings.addAll(resultMap.resultMappings);
}
if (!constructorArgNames.isEmpty()) {
// 获取构造方法参数列表,篇幅原因,这个方法不分析了
final List actualArgNames = argNamesOfMatchingConstructor(constructorArgNames);
if (actualArgNames == null) {
throw new BuilderException("Error in result map '" + resultMap.id
+ "'. Failed to find a constructor in '"
+ resultMap.getType().getName() + "' by arg names " + constructorArgNames
+ ". There might be more info in debug log.");
}
// 对 constructorResultMappings 按照构造方法参数列表的顺序进行排序
Collections.sort(resultMap.constructorResultMappings, new Comparator() {
@Override
public int compare(ResultMapping o1, ResultMapping o2) {
int paramIdx1 = actualArgNames.indexOf(o1.getProperty());
int paramIdx2 = actualArgNames.indexOf(o2.getProperty());
return paramIdx1 - paramIdx2;
}
});
}
// 将以下这些集合变为不可修改集合
resultMap.resultMappings = Collections.unmodifiableList(resultMap.resultMappings);
resultMap.idResultMappings = Collections.unmodifiableList(resultMap.idResultMappings);
resultMap.constructorResultMappings = Collections.unmodifiableList(resultMap.constructorResultMappings);
resultMap.propertyResultMappings = Collections.unmodifiableList(resultMap.propertyResultMappings);
resultMap.mappedColumns = Collections.unmodifiableSet(resultMap.mappedColumns);
return resultMap;
} 以上代码看起来很复杂,实际上这是假象。以上代码主要做的事情就是将 ResultMapping 实例及属性分别存储到不同的集合中,仅此而已。ResultMap 中定义了五种不同的集合,下面分别介绍一下这几种集合。

把 ResultMap 的大致轮廓画出来。如下
