Python之爬虫初探
Python 爬虫初探
为什么选择Python?
- python爬虫具有先天优势,社区资源比较齐全,各种框架也完美支持,爬虫性能也得到极大提升。
- 语法简洁,底层库比较健全。
- 简单易学,代码重用性高,跨平台性。
我还不太会Python想借此学习一下
爬虫是什么?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
基础知识
概念
URL(协议(服务方式) + IP地址(包括端口号) + 具体地址),即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据。
URI 在电脑术语中,统一资源标识符(Uniform Resource Identifier,URI)是一个用于标识某一互联网资源名称的字符串。 该种标识允许用户对任何(包括本地和互联网)的资源通过特定的协议进行交互操作。URI由包括确定语法和相关协议的方案所定义。
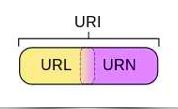
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过 DNS 服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了,其实就是一次http请求的过程
爬虫入门

常用爬虫lib
请求库:requests、selenium(自动化测试工具)+ChromeDrive(chrome 驱动器)、PhantomJS(无界面浏览器)
解析库: LXML(html、xml、Xpath方式)、BeautifulSoup(html、xml)、PyQuery(支持css选择器)、Tesserocr(光学字符识别,验证码)
数据库: mongo、mysql、redis
存储库: pymysql、pymongo、redispy、RedisDump(Redis 数据导入导出的工具)
web库: Flask(轻量级的 Web 服务程序)、Django
其它工具: Charles(网络抓包工具)
例子(都能运行 不行就换一下cookie)
基本例子
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
#请求头相关
print(myUrl)
req = request.Request(myUrl, headers=headers)
#调用库发送请求
myResponse = request.urlopen(req)
myPage = myResponse.read()
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
复杂一点的例子
爬取糗事百科网站,抠出来作者头像,作者名 ,内容
魔改自:https://blog.csdn.net/pleasecallmewhy/article/details/8932310?spm=1001.2014.3001.5501
# -*- coding: utf-8 -*-
import urllib
import _thread
import re
import time
from urllib import request
# ----------- 加载处理糗事百科 -----------
class Spider_Model:
def __init__(self):
self.page = 1
self.pages = []
self.enable = False
# 将所有的段子都扣出来,添加到列表中并且返回列表
def GetPage(self, page):
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
print(myUrl)
req = request.Request(myUrl, headers=headers)
myResponse = request.urlopen(req)
myPage = myResponse.read()
# print(myPage)
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
# 找出所有class="content"的div标记
# re.S是任意匹配模式,也就是.可以匹配换行符
# myItems = re.findall('(.*?) .*?(.*?)(.*?)
', unicodePage, re.S)
items = []
# print("~~~~~~~~~~~~~~~~~~~")
# print(content)
# print(len(content))
# print(content[1])
imageIcon = re.findall('.*?) ', unicodePage, re.S)
# print("~~~~~~~~~~~~~~~~~~~")
# print(imageIcon)
# print(len(imageIcon))
# print(imageIcon[0][0])
# print(imageIcon[0][1])
# print(imageIcon[1][0])
# print(imageIcon[1][1])
for index in range(min(len(content), len(imageIcon)) - 1):
items.append([content[index][0].replace("\n", "").replace("
', unicodePage, re.S)
# print("~~~~~~~~~~~~~~~~~~~")
# print(imageIcon)
# print(len(imageIcon))
# print(imageIcon[0][0])
# print(imageIcon[0][1])
# print(imageIcon[1][0])
# print(imageIcon[1][1])
for index in range(min(len(content), len(imageIcon)) - 1):
items.append([content[index][0].replace("\n", "").replace("
", ""), imageIcon[index][0], imageIcon[index][1]]) return items # 用于加载新的段子 def LoadPage(self): # 如果用户未输入quit则一直运行 while self.enable: # 如果pages数组中的内容小于2个 if len(self.pages) < 2: try: # 获取新的页面中的段子们 print(self.page) myPage = self.GetPage(str(self.page)) self.page += 1 self.pages.append(myPage) return except: print('无法链接糗事百科!') else: time.sleep(1) def ShowPage(self, nowPage, page): for items in nowPage: print(u'第%d页' % page) print("作者头像 = ", items[1]) print("作者名 = ", items[2]) print("内容 = ", items[0]) myInput = input() if myInput == "quit": self.enable = False break def Start(self): self.enable = True page = self.page print(u'正在加载中请稍候......') # 新建一个线程在后台加载段子并存储 _thread.start_new_thread(self.LoadPage, ()) # ----------- 加载处理糗事百科 ----------- while self.enable: # 如果self的page数组中存有元素 if self.pages: nowPage = self.pages[0] del self.pages[0] self.ShowPage(nowPage, page) page += 1 # ----------- 程序的入口处 ----------- print() u""" --------------------------------------- 程序:糗百爬虫 版本:0.3 作者:why 日期:2014-06-03 语言:Python 2.7 操作:输入quit退出阅读糗事百科 功能:按下回车依次浏览今日的糗百热点 --------------------------------------- """ print() u'请按下回车浏览今日的糗百内容:' input(' ') myModel = Spider_Model() myModel.Start() #
", ""), imageIcon[index][0], imageIcon[index][1]]) return items # 用于加载新的段子 def LoadPage(self): # 如果用户未输入quit则一直运行 while self.enable: # 如果pages数组中的内容小于2个 if len(self.pages) < 2: try: # 获取新的页面中的段子们 print(self.page) myPage = self.GetPage(str(self.page)) self.page += 1 self.pages.append(myPage) return except: print('无法链接糗事百科!') else: time.sleep(1) def ShowPage(self, nowPage, page): for items in nowPage: print(u'第%d页' % page) print("作者头像 = ", items[1]) print("作者名 = ", items[2]) print("内容 = ", items[0]) myInput = input() if myInput == "quit": self.enable = False break def Start(self): self.enable = True page = self.page print(u'正在加载中请稍候......') # 新建一个线程在后台加载段子并存储 _thread.start_new_thread(self.LoadPage, ()) # ----------- 加载处理糗事百科 ----------- while self.enable: # 如果self的page数组中存有元素 if self.pages: nowPage = self.pages[0] del self.pages[0] self.ShowPage(nowPage, page) page += 1 # ----------- 程序的入口处 ----------- print() u""" --------------------------------------- 程序:糗百爬虫 版本:0.3 作者:why 日期:2014-06-03 语言:Python 2.7 操作:输入quit退出阅读糗事百科 功能:按下回车依次浏览今日的糗百热点 --------------------------------------- """ print() u'请按下回车浏览今日的糗百内容:' input(' ') myModel = Spider_Model() myModel.Start() #
#
#
#
# 我喝过一次白酒。我哥送的茅台。我在家整出来。小酒杯喝了一杯。第二杯还没动(在地上喝的)然后就躺地上睡着了。我妈回来门反锁了。开不了门。夏天防盗门关了有纱网。大门没关。我妈就那么喊我一动不动。我妈以为我自杀了。整的一栋楼都知道又是报警又是救护车。。。前二年带着儿子回去。邻居大妈说这不是老方家自杀的那个丫头吗?[捂脸][捂脸]
#
#
#
#
# (.*?)(.*?)
#
#
#
#  #
#
#
#
����
 #
#
#
# .*?
还有一些例子:
破解头条加密的case:来自https://blog.csdn.net/fs1341825137/article/details/110854025
import requests
import json
from openpyxl import Workbook
import time
import hashlib
import os
import datetime
start_url = 'https://www.toutiao.com/api/pc/feed/?category=news_hot&utm_source=toutiao&widen=1&max_behot_time='
url = 'https://www.toutiao.com'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
cookies = {'tt_webid': '7002483637053900302'}# 此处cookies可从浏览器中查找,为了避免被头条禁止爬虫
# cookies = {'_ga': 'GA1.2.724393994.1619088212'}# 此处cookies可从浏览器中查找,为了避免被头条禁止爬虫
# 三个月的cookie
max_behot_time = '0' # 链接参数
title = [] # 存储新闻标题
source_url = [] # 存储新闻的链接
s_url = [] # 存储新闻的完整链接
source = [] # 存储发布新闻的公众号
media_url = {} # 存储公众号的完整链接
image_url = [] # 新闻的图片地址
def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js
zz = {}
now = round(time.time())
print(now) # 获取当前计算机时间
e = hex(int(now)).upper()[2:] # hex()转换一个整数对象为16进制的字符串表示
print('e:', e)
a = hashlib.md5() # hashlib.md5().hexdigest()创建hash对象并返回16进制结果
print('a:', a)
a.update(str(int(now)).encode('utf-8'))
i = a.hexdigest().upper()
print('i:', i)
if len(e) != 8:
zz = {'as': '479BB4B7254C150',
'cp': '7E0AC8874BB0985'}
return zz
n = i[:5]
a = i[-5:]
r = ''
s = ''
for i in range(5):
s = s + n[i] + e[i]
for j in range(5):
r = r + e[j + 3] + a[j]
zz = {
'as': 'A1' + s + e[-3:],
'cp': e[0:3] + r + 'E1'
}
print('zz:', zz)
return zz
def getdata(url, headers, cookies): # 解析网页函数
r = requests.get(url, headers=headers, cookies=cookies)
print(url)
data = json.loads(r.text)
return data
def savedata(title, s_url, source, media_url): # 存储数据到文件
# 存储数据到xlxs文件
wb = Workbook()
if not os.path.isdir(os.getcwd() + '/result'): # 判断文件夹是否存在
os.makedirs(os.getcwd() + '/result') # 新建存储文件夹
filename = os.getcwd() + '/result/result-' + datetime.datetime.now().strftime(
'%Y-%m-%d-%H-%m') + '.xlsx' # 新建存储结果的excel文件
ws = wb.active
ws.title = 'data' # 更改工作表的标题
ws['A1'] = '标题' # 对表格加入标题
ws['B1'] = '新闻链接'
ws['C1'] = '头条号'
ws['D1'] = '头条号链接'
for row in range(2, len(title) + 2): # 将数据写入表格
_ = ws.cell(column=1, row=row, value=title[row - 2])
_ = ws.cell(column=2, row=row, value=s_url[row - 2])
_ = ws.cell(column=3, row=row, value=source[row - 2])
_ = ws.cell(column=4, row=row, value=media_url[source[row - 2]])
wb.save(filename=filename) # 保存文件
def ok(now, baseUrl='https://p3.toutiaoimg.com/origin'):
now = now[now.rfind('/tos'):]
now = baseUrl + now
return now
def main(max_behot_time, title, source_url, s_url, source, media_url, image_url): # 主函数
for i in range(10): # 此处的数字类似于你刷新新闻的次数,正常情况下刷新一次会出现10条新闻,但夜存在少于10条的情况;所以最后的结果并不一定是10的倍数
ascp = get_as_cp() # 获取as和cp参数的函数
demo = getdata(
start_url + max_behot_time + '&max_behot_time_tmp=' + max_behot_time + '&tadrequire=true&as=' + ascp[
'as'] + '&cp=' + ascp['cp'], headers, cookies)
print(demo)
# time.sleep(1)
if 'has_more' in demo:
hasMore = demo['has_more']
else:
return
for j in range(len(demo['data'])):
if demo['data'][j]['title'] not in title:
title.append(demo['data'][j]['title']) # 获取新闻标题
source_url.append(demo['data'][j]['source_url']) # 获取新闻链接
source.append(demo['data'][j]['source']) # 获取发布新闻的公众号
if 'image_url' in demo['data'][j]:
image_url.append(ok(demo['data'][j]['image_url'])) # 获取新闻的图片地址
if demo['data'][j]['source'] not in media_url:
media_url[demo['data'][j]['source']] = url + demo['data'][j]['media_url'] # 获取公众号链接
print(max_behot_time)
max_behot_time = str(demo['next']['max_behot_time']) # 获取下一个链接的max_behot_time参数的值
print(max_behot_time)
for index in range(len(title)):
print('标题:', title[index])
if 'https' not in source_url[index]:
s_url.append(url + source_url[index])
print('新闻链接:', url + source_url[index])
else:
print('新闻链接:', source_url[index])
s_url.append(source_url[index])
# print('源链接:', url+source_url[index])
print('公众号链接:', media_url[source[index]])
# print('图片链接:', image_url[index])
print('头条号:', source[index])
print(len(title)) # 获取的新闻数量
# if not hasMore:
# return
if __name__ == '__main__':
main(max_behot_time, title, source_url, s_url, source, media_url, image_url)
savedata(title, s_url, source, media_url)
还有一个腾讯新闻的case:
import requests
import json
requests.packages.urllib3.disable_warnings()
'''
腾讯新闻广告数据爬取
'''
class news_qq():
def __init__(self,number):
self.session = requests.Session()
self.cur = 0
self.orders_info = []
self.current_rot_tmp = 0
self.current_rot_list = []
self.current_rot = ''
self.refresh_type = 1
self.seq = ''
self.seq_loid = ''
for num in range(number): # 这是控制循环次数的
self.payload = {
"adReqData": {
"chid": 6,
"ipv4": self.get_client_ip(),
"adtype": 0,
"pf": "aphone",
"uin": "",
"qq_openid": "",
"ams_openid": "",
"netstatus": "unknown",
"slot": [
{
"cur": self.cur,
"channel": "24h",
"loid": "1",
"orders_info": self.orders_info,
"current_rot": self.current_rot,
"article_id": "",
"refresh_type": self.refresh_type,
"seq": self.seq,
"seq_loid": self.seq_loid
}
],
"appversion": "190125",
"plugin_news_cnt": 10,
"plugin_page_type": "",
"plugin_tbs_version": 0,
"plugin_text_ad": False,
"plugin_bucket_id": "",
"plugin_osv": "5.0.0",
"wap_source": "default"
}
}
js = self.app() # 这个就是获取到的广告json数据
print(js)
# 获取本机IP地址
def get_client_ip(self):
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'ipv4.gdt.qq.com',
'Origin': 'https://xw.qq.com',
'Referer': 'https://xw.qq.com/m/24h',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
url = 'https://ipv4.gdt.qq.com/get_client_ip'
ip = self.session.get(url,headers=headers).text
return ip
# 构造提交数据
# orders_info等于返回值中的e.oid + "," + e.advertiser_id + "," + e.product_id + "," + e.product_type + "," + e.industry_id + "," + e.order_source + "," + e.act_type
def set_params(self,js):
self.cur += 11 if self.cur == 0 else 10
adlist = json.loads(js['adList'])
order_tmp = 0
order_source = adlist['index'][0]['stream']['order_source'].split(',')
for order in adlist['order']:
oid = order['oid']
advertiser_id = order['advertiser_id']
product_id = order['product_id']
product_type = order['product_type']
industry_id = order['industry_id']
act_type = order['act_type']
self.orders_info.append(','.join([oid,str(advertiser_id), str(product_id), str(product_type), str(industry_id),order_source[order_tmp],str(act_type)]))
order_tmp += 1
self.current_rot_tmp += 1
self.current_rot_list.append(str(self.current_rot_tmp))
self.current_rot = ','.join(self.current_rot_list)
self.refresh_type = 2
self.seq += adlist['index'][0]['stream']['seq'] if self.seq == '' else ',' + adlist['index'][0]['stream']['seq']
self.seq_loid += '1,1' if self.seq_loid == '' else ',' + '1,1'
# 获取广告数据
def app(self):
url = 'https://news.ssp.qq.com/app'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cache-Control': 'no-cache',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'news.ssp.qq.com',
'Origin': 'https://xw.qq.com',
'Referer': 'https://xw.qq.com/m/24h',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
response = self.session.post(url,headers=headers,data=json.dumps(self.payload),verify=False)
js = response.json()
self.set_params(js)
return js
if __name__ == '__main__':
news_qq(1000)
最后的思考
到目前为止在不涉及pyspider、scrapy以及数据库的情况下,解密js获取参数是否当前的难点,对于这个难点,我有一个大胆的想法!
通过postman写爬虫
先找到需要爬取的接口
一般是通过chrome的inspect中的NetWork选项,然后刷新对应的页面,定位到接口
使用postman
在上一步找到对应的接口后,右键选择Copy,然后选择Copy as cURL,然后在postman页面中点击inport,选择Raw text,粘贴之前copy的内容,然后点击Send,就可以看到对应的数据
生成相应的Code
在postman的右边,会有一个code按钮,点击之后,选择相应的语言,比如Axios,然后就会生成相应的代码,这样的代码只是可以运行,为了维护,还是需要自己修改,将相同的代码抽离到函数中
事实也是这样的!

如果这套能再自动化一点就完美了!
参考资料:
https://www.zhihu.com/question/20899988
https://www.cnblogs.com/dluo/p/10373829.html#!comments