(深度学习·笔记1)Python常用基础工具以及第三方库
笔记来源:飞桨深度学习学院《Python小白逆袭大神》·主要是针对于我个人的情况选择性摘录的!
——课节3:Day2-Python进阶
https://aistudio.baidu.com/aistudio/education/group/info/1224
——课节3:Day3-深度学习常用Python库介绍
https://aistudio.baidu.com/bdvgpu32g/user/620475/1457309/notebooks/1457309.ipynb
目录
一、Python数据结构-数字
1、Python math模块
二、Python面向对象
三、Python JSON
四、Python-Numpy
1、数组创建
2、数组的参数信息
3、数组的计算
4、数组的索引和切片
五、Python-Pandas
1、Series
2、DataFrame
六、Python-PIL
七、Python-Matplotlib
一、Python数据结构-数字
1、Python math模块
import math
print(math.ceil(4.1)) #返回数字的上入整数
print(math.floor(4.9)) #返回数字的下舍整数
print(math.fabs(-10)) #返回数字的绝对值
print(math.sqrt(9)) #返回数字的平方根
print(math.exp(1)) #返回e的x次幂
5
4
10.0
3.0
2.718281828459045二、Python面向对象
定义一个类Animals:
(1)init()定义构造函数,与其他面向对象语言不同的是,Python语言中,会明确地把代表自身实例的self作为第一个参数传入
(2)创建一个实例化对象 cat,init()方法接收参数
(3)使用点号 . 来访问对象的属性
class Animal:
def __init__(self,name):
self.name = name
print('动物名称实例化')
def eat(self):
print(self.name +'要吃东西啦!')
def drink(self):
print(self.name +'要喝水啦!')
cat = Animal('miaomiao')
print(cat.name)
cat.eat()
cat.drink()
动物名称实例化
miaomiao
miaomiao要吃东西啦!
miaomiao要喝水啦!三、Python JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
json.dumps 用于将 Python 对象编码成 JSON 字符串
import json
data = [ { 'b' : 2, 'd' : 4, 'a' : 1, 'c' : 3, 'e' : 5 } ]
json = json.dumps(data)
print(json)
[{"b": 2, "d": 4, "a": 1, "c": 3, "e": 5}]为了提高可读性,dumps方法提供了一些可选的参数。
- sort_keys=True表示按照字典排序(a到z)输出。
- indent参数,代表缩进的位数
- separators参数的作用是去掉,和:后面的空格,传输过程中数据越精简越好
import json
data = [ { 'b' : 2, 'd' : 4, 'a' : 1, 'c' : 3, 'e' : 5 } ]
json = json.dumps(data, sort_keys=True, indent=4,separators=(',', ':'))
print(json)
[
{
"a":1,
"b":2,
"c":3,
"d":4,
"e":5
}
]json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}'
text = json.loads(jsonData) #将string转换为dict
print(text)
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}四、Python-Numpy
Python科学计算库的基础。包含了强大的N维数组对象和向量运算。
numpy中文网:https://www.numpy.org.cn/
可以参考我之见做的转载的笔记:python-numpy 要点总结
1、数组创建
- array
- zeros
- ones
- empty
- arange
2、数组的参数信息
- .ndim:维度
- .shape:形状
- .size:个数
- .dtype:类型
3、数组的计算
- 基础运算:+ - * /
- 矩阵乘法:.dot
- 求和:sum
- 求最大值:max;索引:argmax
- 求最小值:min;索引:argmin
- 平均值:mean
4、数组的索引和切片
五、Python-Pandas
pandas是python第三方库,提供高性能易用数据类型和分析工具。
pandas基于numpy实现,常与numpy和matplotlib一同使用
pandas中文网:https://www.pypandas.cn/
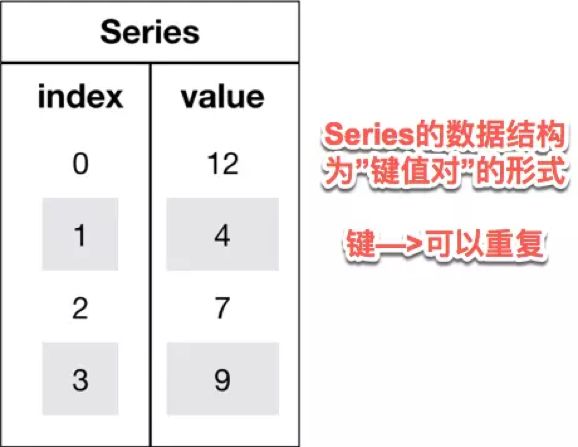

1、Series
Series是一种类似于一维数组的对象,它由一维数组(各种numpy数据类型)以及一组与之相关的数据标签(即索引)组成.
可理解为带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据
Seris中可以使用index设置索引列表。
与字典不同的是,Seris允许索引重复
import pandas as pd
import numpy as np
s = pd.Series(['a','b','c','d','e'])
print(s)
0 a
1 b
2 c
3 d
4 e
dtype: objects = pd.Series(['a','b','c','d','e'],index=[100,200,100,400,500])
print(s)
100 a
200 b
100 c
400 d
500 e
dtype: object与普通numpy数组相比,可以通过索引的方式选取Series中的单个或一组值
Series中最重要的一个功能是:它会在算术运算中自动对齐不同索引的数据
Series 和多维数组的主要区别在于, Series 之间的操作会自动基于标签对齐数据。因此,不用顾及执行计算操作的 Series 是否有相同的标签。
obj1 = pd.Series({"Ohio": 35000, "Oregon": 16000, "Texas": 71000, "Utah": 5000})
print(obj1)
obj2 = pd.Series({"California": np.nan, "Ohio": 35000, "Oregon": 16000, "Texas": 71000})
print(obj2)
print(obj1 + obj2)
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN(……这个我也不知道为啥)
dtype: float642、DataFrame
DataFrame是一个表格型的数据结构,类似于Excel或sql表
它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
用多维数组字典、列表字典生成 DataFrame,如果指定了列顺序,则DataFrame的列就会按照指定顺序进行排列
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five'])
print(frame2)
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN用 Series 字典或字典生成 DataFrame
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
print(pd.DataFrame(d))通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series,返回的Series拥有原DataFrame相同的索引
列可以通过赋值的方式进行修改,例如,给那个空的“delt”列赋上一个标量值或一组值
frame2['debt'] = np.arange(5.)
print(frame2)
year state pop debt new
one 2000 Ohio 1.5 0.0 24.75
two 2001 Ohio 1.7 1.0 28.05
three 2002 Ohio 3.6 2.0 59.40
four 2001 Nevada 2.4 3.0 39.60
five 2002 Nevada 2.9 4.0 47.85六、Python-PIL
PIL库是一个具有强大图像处理能力的第三方库。
图像的组成:由RGB三原色组成,RGB图像中,一种彩色由R、G、B三原色按照比例混合而成。0-255区分不同亮度的颜色。
图像的数组表示:图像是一个由像素组成的矩阵,每个元素是一个RGB值

Image 是 PIL 库中代表一个图像的类(对象)
- 读取图片:img = Image.open
- 显示图片:.show
- 图像的模式:.mode
- .size
- 图像的旋转:.rotate(β)
- 图片剪切:.crop(左上角点的x坐标,左上角点的y坐标,右下角点的x坐标,右下角点的y坐标)
- 保存图片:.save
- 缩放:.resize
- 左右镜像:.transpose(Image.FLIP_LEFT_RIGHT)
- 上下镜像:transpose(Image.FLIP_TOP_BOTTOM)
七、Python-Matplotlib
Matplotlib库由各种可视化类构成,内部结构复杂。
matplotlib.pylot是绘制各类可视化图形的命令字库
Matplotlib中文网:https://www.matplotlib.org.cn
- 绘制:.plot
- 显示:.show
- 分块显示:.figure
- 标签:xlabel;ylabel
- 只截取一段显示:.xlim;ylim
- 注释:.legend
- 散点图:.scatter
- 柱状图:.bar
- 图形标识:.text
