CPT104-Operating Systems Concepts
文章目录
- 1. Process Management
-
- 1.1 Process Concept
-
- 1.1.1 Process State
- 1.1.2 Process Control Block (PCB)
- 1.2 Process Scheduling
-
- 1.2.1 Schedulers
- 1.2.2 Representation of Process Scheduling
- 1.3 Operations on Processes
-
- 1.3.1 Process Creation
- 1.3.2 Process Termination
- 1.4 Inter-process Communication
-
- 1.4.1 Communications Models
- 2. Thread
-
- 2.1 Multicore Programming
-
- 2.1.1 Concurrency and Parallelism
- 2.2 Multithreading Models
- 2.3 Thread Libraries
- 2.4 Implicit threading
- 2.5 Threading issues / Designing multithreaded programs
-
- 2.5.1 Semantics of fork() and exec()
- 2.5.2 Signal Handling
- 2.5.3 Thread Cancellation
- 2.5.4 From Single-threaded to Multithreaded
- 3. Process Synchronization
-
- 3.1 The Critical-Section Problem
- 3.2 Types of solutions to CS problem
-
- 3.2.1 Software Solutions (Peterson’s Solution)
- 3.2.2 Hardware Solutions
- 3.2.3 Operating Systems and Programming Language Solutions
- 3.3 Classical Problems of Synchronization
-
- 3.3.1 The Bounded-Buffer / Producer-Consumer Problem
- 3.3.2 The Readers - Writers Problem
- 3.3.3 The Dining-Philosophers Problem
- 4. CPU Scheduling
-
- 4.1 Basic Concepts
-
- 4.1.1 CPU - I/O Burst Cycle
- 4.1.2 Types of Processes
- 4.1.3 The CPU scheduler
- 4.1.4 Dispatcher
- 4.2 Scheduling Criteria
- 4.3 Scheduling Algorithms
-
- 4.3.1 First - Come, First - Served (FCFS) Scheduling
- 4.3.2 Shortest Job First (SJF) NO preemption
- 4.3.3 Shortest-Remaining-Time-First (SRTF) SJF with preemption
- 4.3.4 Priority Scheduling
- 4.3.5 Round Robin (RR) Scheduling
- 4.3.6 Multilevel Queue Scheduling
- 4.3.7 Multilevel Feedback Queue Scheduling
- 4.4 Thread Scheduling / Contention scope
- 4.5 Multi-Processor Scheduling
-
- 4.5.1 Structure of Multi-Processor OSs
- 4.5.2 Processor Affinity
- 4.5.3 Load Balancing
- 4.5.4 Multicore Processors
- 4.5.5 Hyperthreading
- 4.6 Real-Time CPU Scheduling
- 4.7 Algorithm Evaluation
-
- 4.7.1 Deterministic Modeling
- 4.7.2 Queueing Models
- 4.7.3 Simulations
- 5. Deadlock
-
- 5.1 System Model
- 5.2 Deadlock Characterization
- 5.3 Methods for Handling Deadlocks
-
- 5.3.1 Deadlock Prevention
- 5.3.2 Deadlock Avoidance
- 5.3.3 Deadlock Detection
- 5.4 Recovery from Deadlock
- 6. Memory Management
-
- 6.1 Memory Management Unit (MMU)
-
- 6.1.1 Memory Management Requirements
- 6.2 Contiguous Memory Allocation
-
- 6.2.1 CONTIGUOUS ALLOCATION
- 6.2.2 Fragmentation
- 6.3 Non-Contiguous Memory Allocation
-
- 6.3.1 SEGMENTATION
- 6.3.2 PAGING
- 7. Virtual Memory
-
- 7.1 Background
- 7.2 Demand Paging
-
- 7.2.1 Issues related to the implementation
- 7.2.2 Performance of Demand Paging
- 7.3 Copy-on-Write (COW) in Operating System
- 7.4 Page Replacement
-
- 7.4.1 FIFO Algorithm
- 7.4.2 Optimal Algorithm
- 7.4.3 Least Recently Used (LRU) Algorithm
- 7.4.4 LRU Approximation Algorithms
- 7.4.5 Second-Chance (Clock) Algorithm
- 7.4.6 Counting Algorithms
- 7.5 Frame Allocation
- 8. Mass-Storage Systems
-
- 8.1 Disk Structure
- 8.2 Disk Attachment
- 8.3 Disk Scheduling
-
- 8.3.1 First-Come First-Served (FCFS) Algorithm
- 8.3.2 Shortest Seek time First (SSTF) Algorithm
- 8.3.3 SCAN (Elevator)
- 8.3.4 Circular-SCAN (C-SCAN)
- 8.3.4 LOOK
- 8.3.5 C-LOOK
- 8.4 Disk Management
- 8.5 Swap-Space Management
- 8.6 RAID Structure
-
- 8.6.1 RAID Level 0
- 8.6.2 RAID Level 1
- 8.6.3 RAID Level 2
- 8.6.4 RAID Level 3
- 8.6.5 RAID Level 4
- 8.6.6 RAID Level 5
- 8.6.7 RAID Level 6
- 8.6.8 RAID Level 0+1
- 8.6.9 RAID Level 1+0
- 9. File System
-
- 9.1 File System Interface
-
- 9.1.1 Access methods
- 9.1.2 Directory Structure
- 9.1.3 Protection
- 9.1.4 File-System Mounting
- 9.1.5 File Sharing
- 9.2 File System Implementation
-
- 9.2.1 Allocation and Free Space Management
-
- 1) On-disk for data storage
- 2) In-memory for data access
- 9.2.2 Directory Implementation
- 10. IO Systems
-
- 10.1 IO Hardware
-
- 10.1.1 IO communication techniques
- 10.2 Application IO Interface
- 10.3 Kernel IO Subsystem
- 10.4 Device Driver
- 10.5 Interrupt Handler
- 10.6 Streams
- 10.7 Improving Performance
- 11. Protection & Security
-
- 11.1 Protection
-
- 11.1.1 Principles of Protection
- 11.1.2 Access Matrix
- 11.1.3 Access Control Policy
- 11.2 Security
-
- 11.2.1 Cryptography as a Security Tool
- 11.2.2 User Authentication
- 11.2.3 Implementing Security Defenses
- 12. Virtual Machines & Distributed Systems
-
- 12.1 Virtual Machines
- 12.2 Distributed Systems
1. Process Management
Starting and stopping programs and sharing the CPU between them.
1.1 Process Concept
Process: a program in execution. process execution must progress in sequential fashion
An operating system executes a variety of programs:
- Batch system (批处理系统):
jobs - Time-shared system (分时系统):
user programsortasks
Process 和 Program 的关系
A process is considered an ‘active’ entity, a program is considered to be a ‘passive’ entity. Program becomes process when executable file loaded into memory.
Process in Memory
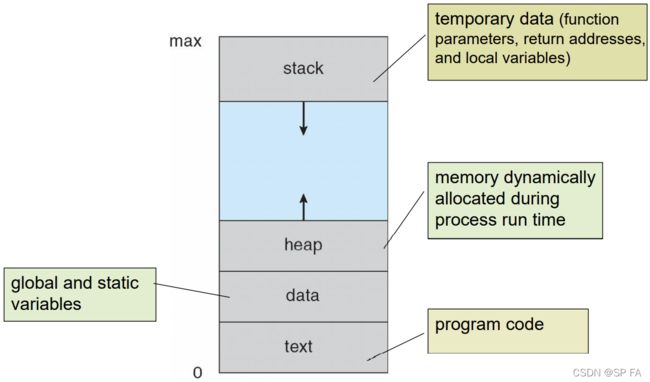
1.1.1 Process State
As a process executes, it changes state. The state of a process is defined in part by the current activity of that process
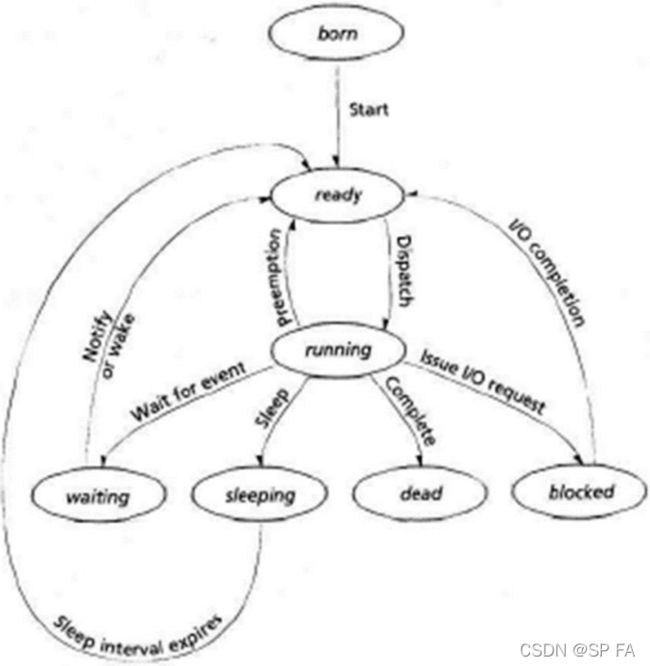
new: The process is being createdrunning: Instructions are being executedwaiting: The process is waiting for some event to occurready: The process is waiting to be assigned to a processorterminated: The process has finished execution
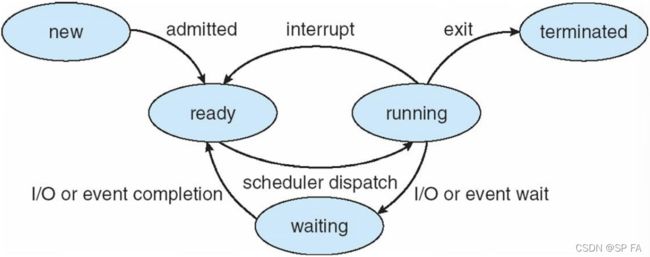
1.1.2 Process Control Block (PCB)
Process Control block is a data structure used for storing the information about a process, It is also called as context of the process
进程控制块是为了管理进程设置的一个数据结构。是系统感知进程存在的唯一标志。
Each & every process is identified by its own PCB

PCB of each process resides in the main memory
PCB of all the processes are present in a linked list
PCB is important in multiprogramming environment as it captures the information pertaining to the number of processes running simultaneously
1.2 Process Scheduling
Process scheduler selects from among the processes in memory that are ready to execute, and allocates the CPU to one of them
Maintains scheduling queues of processes:
Job queue: set of all processes in the systemReady queue: set of all processes residing in main memory, ready and waiting to executeDevice queues: set of processes waiting for an I/O device
1.2.1 Schedulers
Long-Term Scheduler: Also called Job Scheduler and is responsible for controlling the Degree of Multiprogramming
Short-Term Scheduler: Also known as CPU scheduler and is responsible for selecting one process from the ready state for scheduling it on the running state
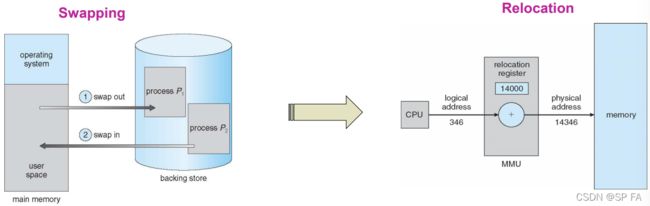
Medium-Term Scheduler: Responsible for swapping of a process from the Main Memory to Secondary Memory and vice-versa (mid-term effect on the performance of the system). It can be added if degree of multiple programming needs to decrease.
swapping: Remove process from memory, store on disk, bring back in from disk to continue execution

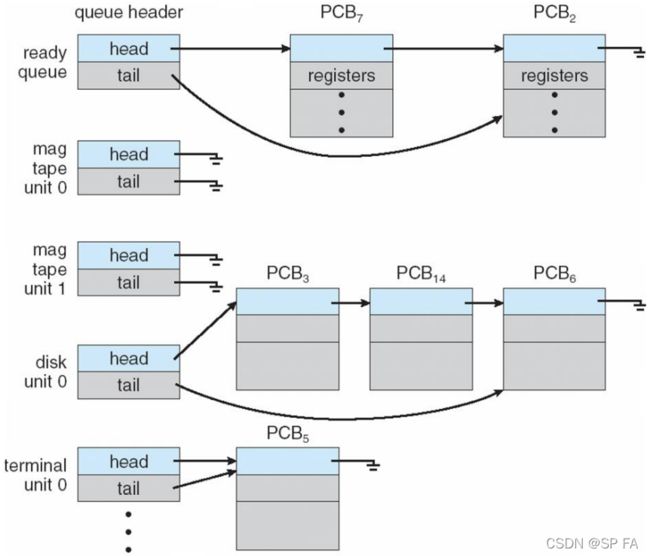
Queueing Diagram for Scheduling
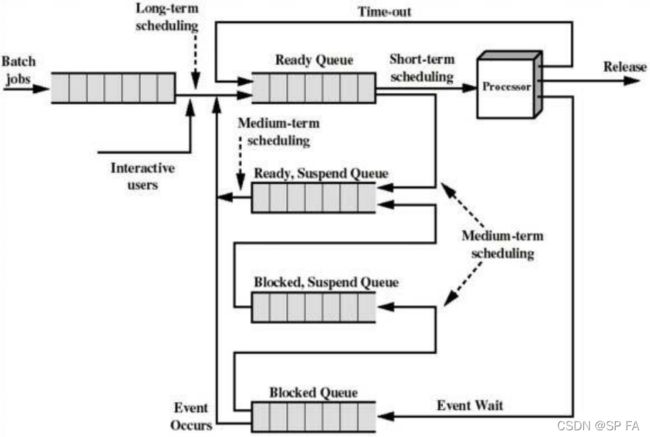
1.2.2 Representation of Process Scheduling
Queueing diagram represents queues, resources, flows
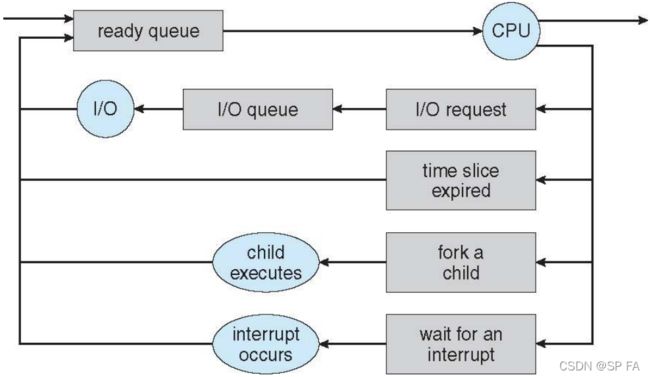
- Ready queue and various I/O device queues
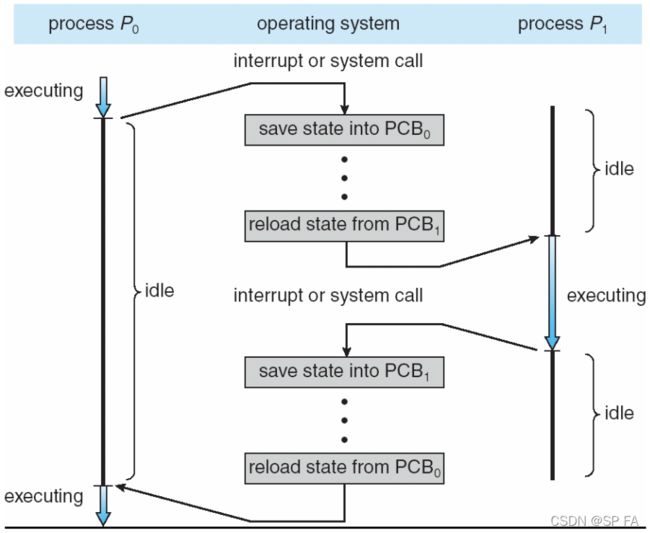
Context Switch
When CPU switches to another process, the system must save the state of the old process and load the saved state for the new process via a context switch. Context of a process represented in the PCB
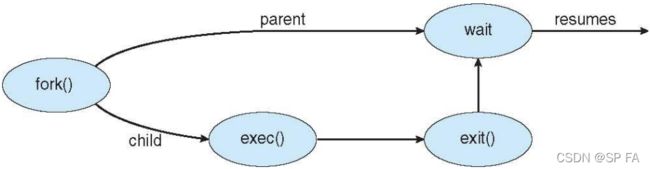
1.3 Operations on Processes
System must provide mechanisms for:
- process creation
- process termination
1.3.1 Process Creation
Parent process create children processes, which, in turn create other processes, forming a tree of processes
Resource sharing options:
- Parent and children share all resources
- Children share subset of parent’s resources
- Parent and child share no resources
Execution options:
- Parent and children execute concurrently
- Parent waits until children terminate
1.3.2 Process Termination
Process executes last statement and then asks the operating system to delete it using the exit() system call:
- Returns status data from child to parent
- Process’ resources are deallocated by operating system
Parent may wait terminate the execution of children processes.
1.4 Inter-process Communication
Independent Processes: neither affect other processes or be affected by other processesCooperating Processes: can affect or be affected by other processes. There are several reasons why cooperating processes are allowed:Information Sharing: Processes which need access to the same file for exampleComputation speedup: A problem can be solved faster if the problem can be broken down into sub-tasks to be solved simultaneouslyModularity: Break a system down into cooperating modules.Convenience: Even a single user may be multi-tasking, such as editing, compiling, printing, and running the same code in different windows
1.4.1 Communications Models
Message passing
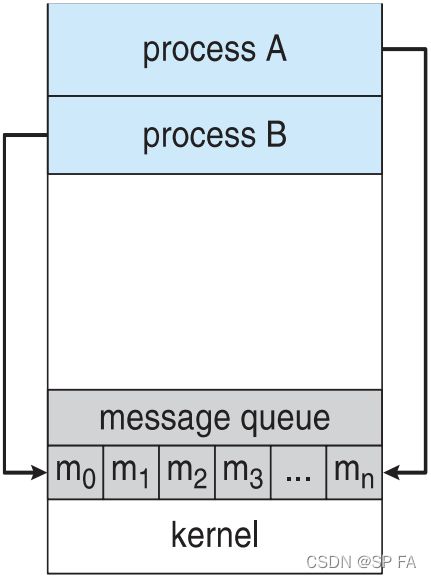
communication takes place by way of messages exchanged among the cooperating processes.
A message-passing facility provides at least two operations:
- send(message)
- receive(message)
The message size is either fixed or variable
If processes P and Q want to communicate, then a communication link must exist between them.
There are several methods for logically implementing a link and the send()/receive() operations:
-
Direct or indirect communication
Direct Communication: Processes must name each other explicitly. Direct Communication is implemented when the procsses use specific process identifier for the communication, but it is hard to identify the sender ahead of time. e.g.send(P, message)mains send a message to process PIndirect Communication: create a new mailbox (port), send and receive messages through mailbox, then destroy a mailbox. e.g.send(A, ,message)mains send a message to mailbox A. -
Synchronous or asynchronous communication
Message passing may be either
blockingornon-blocking. Blocking is considered synchronous: and non-blocking is considered asynchronous.- Blocking send: The sender is blocked until the message is received
- Blocking receive: The receiver is blocked until a message is available
- Non-blocking send: the sender sends the message and continue
- Non-blocking receive: the receiver receives a valid message or Null message
-
Automatic or explicit buffering
Shared-Memory Systems

a region of memory is shared by cooperating processes, processes can exchange information by reading and writing all the data to the shared region.
Two types of buffers can be used:
unbounded-buffer: places no practical limit on the size of the bufferbounded-buffer: assumes that there is a fixed buffer size
2. Thread
A thread is an independent stream of instructions that can be scheduled to run by the OS. (OS view)
A thread can be considered as a “procedure” that runs independently from the main program. (Software developer view)
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内可调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
协程 (cooperative routine, cooperative tasks):是一种比线程更加轻量级的存在。一个线程也可以拥有多个协程。其执行过程更类似于子例程,或者说不带返回值的函数调用。
例程:就是函数,笑死
进程 和 线程 的区别
- 地址空间:线程共享本进程的地址空间,而进程之间时独立的地址空间
- 资源:线程共享本进程的资源如内存、I/O、cpu 等,不利于资源的管理和保护,而进程之间的资源是独立的,能很好的进行资源管理和保护
- 健壮性:多进程要比多线程健壮,一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是线程崩溃会导致整个进程死掉
- 执行过程:每个独立的进程有一个程序运行的入口、顺序执行序列,执行开销大。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,执行开销小。
- 可并发性:都可
- 切换:进程切换时,消耗的资源大,效率低。所以涉及到频繁的切换时,使用线程要好于进程。同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程。
- 其它:线程是处理器调度的基本单位,但是进程不是。
python 多线程的问题
由于历史遗留的问题,严格说多个线程并不会同时执行(没法有效利用多核处理器,python 的并发只是在交替执行不同的代码)。多线程在 python 中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。所以 python 的多线程并发并不能充分利用多核,并发没有 java 的并发严格。(所以说 python 并不严谨)
原因:
原因就在于 GIL ,在 Cpython 解释器(python 语言的主流解释器)中,有一把全局解释锁(GIL, Global Interpreter Lock),在解释器解释执行 python 代码时,任何 python 线程执行前,都先要得到这把 GIL 锁。这个 GIL 全局锁实际上把所有线程的执行代码都给上了锁。
这意味着,其它线程要想获得 CPU 执行代码指令,就必须先获得这把锁,如果锁被其它线程占用了,那么该线程就只能等待,直到占有该锁的线程释放锁才有执行代码指令的可能。
什么时候 GIL 被释放?
- 当一个线程遇到 I/O 任务时,将释放 GIL。
- 计算密集型(CPU-bound)线程执行100次解释器的计步(ticks)时(计步可粗略看作
python虚拟机的指令),也会释放 GIL。即,每执行100条字节码,解释器就自动释放 GIL 锁,让别的线程有机会执行。
python 虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个 python 进程有各自独立的 GIL 锁,互不影响。
Benefits
- Takes less time to create a new thread than a process
- Less time to terminate a thread than a process
- Switching between two threads takes less time than switching between processes
- Threads enhance efficiency in communication between programs
Thread Control Block
Threads are scheduled on a processor, and each thread can execute a set of instructions independent of other processes and threads. Thread Control Block stores the information about a thread. It shares with other threads belonging to the same process its code section, data section and other operating-system resources, such as open files and signals.

Life Cycle
2.1 Multicore Programming
2.1.1 Concurrency and Parallelism
Concurrency means multiple tasks which start, run, and complete in overlapping time periods, in no specific order
A system is parallel if it can perform more than one task simultaneously.
并发和并行的区别
2.2 Multithreading Models
Multithreading can be supported by:
-
User level libraries (without Kernel being aware of it): Library creates and manages threads (user level implementation)
User thread is the unit of execution that is implemented by users and the kernel is not aware of the existence of these threads. User-level threads are much faster than kernel level threads. All thread management is done by the application by using a thread library. 用户级线程到底有什么用?
Advantages:
- Thread switching does not involve the kernel: no mode switching
- Therefore fast
- Scheduling can be application specific: choose the best algorithm for the situation.
- Can run on any OS. We only need a thread library
Disadvantages:
- Most system calls are blocking for processes. So, all threads within a process will be implicitly blocked
- The kernel can only assign processors to processes. Two threads within the same process cannot run simultaneously on two processors
-
Kernel level: Kernel creates and manages threads (kernel space implementation)
Kernel thread is the unit of execution that is scheduled by the kernel to execute on the CPU. are handled by the perating system directly and the thread management is done by the kernel.
Advantages:
- The kernel can schedule multiple threads of the same process on multiple processors
- Blocking at thread level, not process level, if a thread blocks, the CPU can be assigned to another thread in the same process
- Even the kernel routines can be multithreaded
Disadvantages:
4. Thread switching always involves the kernel. This means 2 mode switches per thread switch
5. So, it is slower compared to User Level Threads, but faster than a full process switch
A relationship must exist between user threads and kernel threads. That is, mapping user level threads to kernel level threads.
In a combined system, multiple threads within the same application can run in parallel on multiple processors.
Multithreading models are three types:
- Many - to - One: Many user-level threads are mapped to a single kernel thread. The process can only run one user-level thread at a time because there is only one kernel-level thread associated with the process. Thread management done at user space, by a thread library
- One - to - One: Each user thread mapped to one kernel thread. Kernel may implement threading and can manage threads, schedule threads. Kernel is aware of threads. Provides more concurrency, when a thread blocks, another can run.
- Many - to - Many: Allows many user level threads to be mapped to many kernel threads. Allows the operating system to create a sufficient number of kernel threads. Number of kernel threads may be specific to an either a particular application or a particular machine. The user can create any number of threads and corresponding kernel level threads can run in parallel on multiprocessor
2.3 Thread Libraries
No matter which thread is implemented, threads can be created, used, and terminated via a set of functions that are part of a Thread API
Thread library provides programmer with API for creating and managing threads. Programmer just have to know the thread library interface. Threads may be implemented in user space or kernel space. library may be entirely in user space or may get kernel support for threading
Three primary thread libraries: POSIX threads, Java threads, Win32 threads
Two approaches for implementing thread library:
- to provide a library entirely in user space with no kernel support.
all code and data structures for the library exist in user space. invoking a function in the library results in a local function call in user space and not a system call. - to implement a kernel-level library supported directly by the operating system.
code and data structures for the library exist in kernel space. invoking a function in the API for the library typically results in a system call to the kernel.
2.4 Implicit threading
Explicit threading: the programmer creates and manages threads.
Implicit threading: the compilers and run-time libraries create and manage threads.
Three alternative approaches for designing multithreaded programs:
- Thread pool: create a number of threads at process startup and place them into a pool, where they sit and wait for work.
- OpenMP: a set of compiler directives available for C, C++, and Fortran programs that instruct the compiler to automatically generate parallel code where appropriate.
- Grand Central Dispatch (GCD): an extension to C and C++ available on Apple’s MacOS X and iOS operating systems to support parallelism.
2.5 Threading issues / Designing multithreaded programs
There are a variety of issues to consider with multithreaded programming
2.5.1 Semantics of fork() and exec()
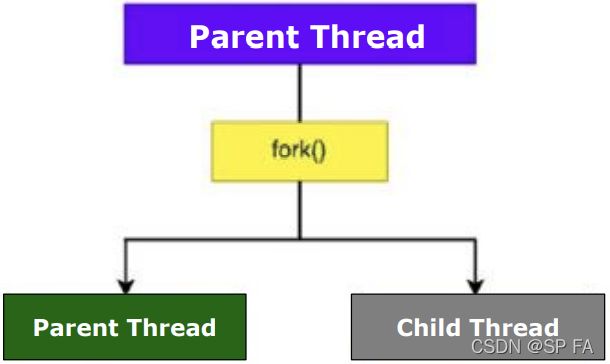
fork() system call
Creating a thread is done with a fork() system call. A newly created thread is called a child thread, and the thread that is initiated to create the new thread is considered a parent thread.
exec() system call
The exec() system call family replaces the currently running thread with a new thread. The original thread identifier remains the same, and all the internal details, such as stack, data, and instructions. Then the new thread replaces the executables
If exec() will be called after fork(), there is no need to duplicate the threads. They will be replaced anyway.
If exec() will not be called, then it is logical to duplicate the threads. so that the child will have as many threads as the parent has.
2.5.2 Signal Handling
A signal is a software interrupt, or an event generated by a Unix/Linux system in response to a condition or an action. There are several signals available in the Unix system. The signal is handled by a signal handler (all signals are handled exactly once).
asynchronous signal is generated from outside the process that receives it
synchronous signal is delivered to the same process that caused the signal to occur
2.5.3 Thread Cancellation
Terminating a thread before it has finished.
Two general approaches:
Asynchronous cancellation terminates the target thread immediately
Deferred cancellation allows the target thread to periodically check if it should be cancelled. Cancelled thread has sent the cancellation request
2.5.4 From Single-threaded to Multithreaded
Many programs are written as a single threaded process.
If we try to convert a single-threaded process to multi-threaded process, we have to be careful about the following:
- the global variables
- the library functions we use
3. Process Synchronization
PS is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources. Because concurrent access to shared data may result in data inconsistency.
Maintaining data consistency requires mechanisms to ensure the orderly execution of cooperating processes
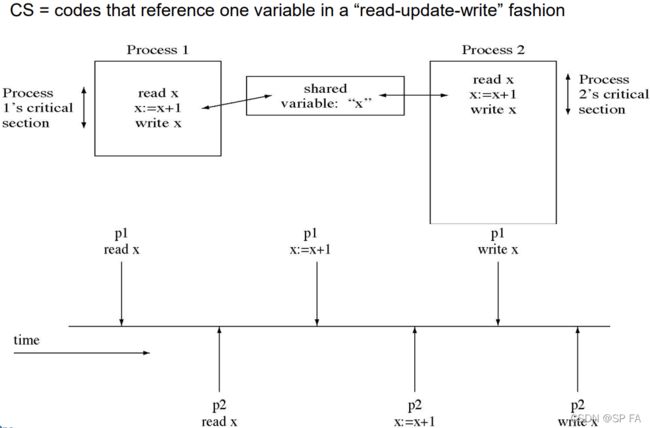
Race condition: The situation where several processes access and manipulate shared data concurrently. The final value of the shared data depends upon which process finishes last. To prevent race conditions, concurrent processes must be synchronized
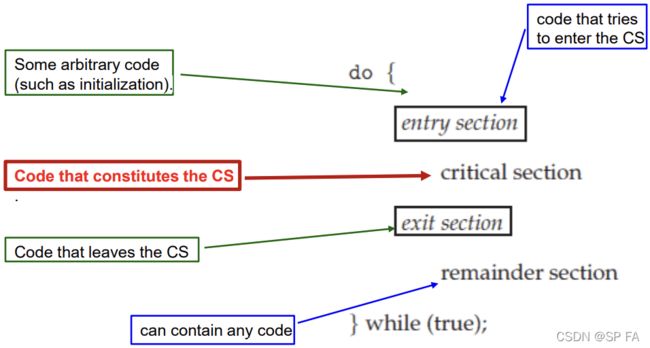
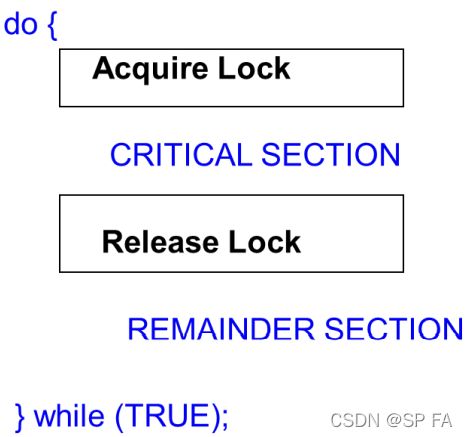
3.1 The Critical-Section Problem
Each (concurrent) process has a code segment, called Critical Section (CS), in which the shared data is accessed. When using critical sections, the code can be broken down into the following sections:
Race condition updating a variable
Critical section to prevent a race condition

Multiprogramming allows logical parallelism, uses devices efficiently but we lose correctness when there is a race condition. So, we forbid/deny logical parallelism inside critical section, so we lose some parallelism, but we regain correctness.
关于临界区
Solutions to CS problem
There are 3 requirements that must stand for a correct solution:
- Need for Mutual exclusion: When a process/thread is executing in its critical section, no other process/threads can be executing in their critical sections.
- Progress: If no process/thread is executing in its critical section, and if there are some processes/threads that wish to enter their critical sections, then one of these processes/threads will get into the critical section. It must be possible to negotiate who will proceed next into CS.
- Bounded waiting: No process/thread should have to wait forever to enter into the critical section. the waiting time of a process/thread outside a critical section should be Limited (otherwise the process/thread could suffer from starvation)
3.2 Types of solutions to CS problem
Framework for analysis of solutions
Each process executes at nonzero speed but no assumption on the relative speed of n processes. No assumptions about order of interleaved execution. The central problem is to design the entry and exit sections
3.2.1 Software Solutions (Peterson’s Solution)
It was formulated by Gary L. Peterson in 1981. Only 2 processes, P0 and P1
Processes may share some common variables to synchronize their actions.
int turn; // indicates whose turn it is to enter the critical section.
boolean flag[2]; // initialized to FALSE,
// indicates when a process wants to enter into their CS.
// flag[i] = true implies that process Pi is ready (i = 0,1)
NEED BOTH the turn and flag[2] to guarantee Mutual Exclusion, Boundedwaiting, and Progress.

Proof of Correctness
- Mutual Exclusion:
Mutual exclusion holds since for both P 0 P_0 P0 and P 1 P_1 P1 to be in their CS. That means both flag[0] and flag[1] must be true, and turn=0 and turn=1 at same time (impossible) - Progress:
Each process can only be blocked at the while if the other process wants to use the critical section and it is the other process’s turn to use the critical section. If both of those conditions are true, then the other process will be allowed to enter the critical section, and upon exiting the critical section, will set flag[1] to false, releasing process P0. The shared variable turn assures that only one process at a time can be blocked, and the flag variable allows one process to release the other when exiting their critical section. - Bounded Waiting:
As each process enters their entry section, they set the turn variable to be the other processes turn. Since no process ever sets it back to their own turn, this ensures that each process will have to let the other process go first at most one time before it becomes their turn again.
Drawbacks of Software Solutions
- Complicated to program
- Busy waiting (wasted CPU cycles)
- It would be more efficient to block processes that are waiting (just as if they had requested I/O). This suggests implementing the permission/waiting function in the Operating System
3.2.2 Hardware Solutions
Single-processor environment
could disable interrupts Effectively stops scheduling other processes. Currently running code would execute without preemption

satisfy the mutual exclusion requirement, but do not guarantee bounded waiting.
Multi-processor environment
modern machines provide special atomic hardware instructions. Atomic mean non-interruptable (i.e., the instruction executes as one unit)

Advantages
- Applicable to any number of processes on either a single processor or multiple processors sharing main memory
- Simple and easy to verify
- It can be used to support multiple critical sections, each critical section can be defined by its own variable
Disadvantages
Busy-waitingis employed, thus while a process is waiting for access to a critical section it continues to consume processor timeStarvationis possible when a process leaves a critical section, and more than one process is waitingDeadlockis possible if a low priority process has the critical region and a higher priority process needs, the higher priority process will obtain the processor to wait for the critical region
3.2.3 Operating Systems and Programming Language Solutions
Mutex Lock / Mutual exclusion
Mutex is a software tool. It allows multiple process / thread to access a single resource but not simultaneously.
To enforce mutex at the kernel level and prevent the corruption of shared data structures: disable interrupts for the smallest number of instructions is the best way.
To enforce mutex in the software areas: use the busy-wait mechanism. busy-wait mechanism or busy-looping or spinning is a technique in which a process/thread repeatedly checks to see if a lock is available.
using mutexes is to acquire a lock prior to entering a critical section, and to release it when exiting
Mutex object is locked or unlocked by the process requesting or releasing the resource.
This type of mutex lock is called a spinlock because the process “spins” while waiting for the lock to become available.
Semaphore
Semaphore was proposed by Dijkstra in 1965 which is a technique to manage concurrent processes by using a simple integer value. Semaphore is a integer variable which is non-negative and shared between threads.
This variable is used to solve the critical section problem and to achieve process synchronization in the multiprocessing environment. It is accessed only through two standard atomic operations: wait() and signal().

To allow k processes into CS at a time, simply initialize mutex to k.
There are two main types of semaphores:
-
COUNTING SEMAPHORE: allow an arbitrary resource count. Its value can range over an unrestricted domain. It is used to control access to a resource that has multiple instances.
The semaphore S is initialized to the number of available resources. Each process that wishes to use a resource performs a wait() operation on the semaphore. When a process releases a resource, it performs a signal() operation. When the count for the semaphore goes to 0, all resources are being used. After that, processes that wish to use a resource will block until the count becomes greater than 0. -
BINARY SEMAPHORE: This is also known as mutex lock. It can have only two values: 0 and 1. Its value is initialized to 1. It is used to implement the solution of critical section problem with multiple processes.
Starvation and Deadlock
Starvation and Deadlock are situations that occur when the processes that require a resource are delayed for a long
time.
Deadlock is a condition where no process proceeds for execution, and each waits for resources that have been acquired by the other processes. In Starvation, process with high priorities continuously uses the resources preventing low priority process to acquire the resources.
3.3 Classical Problems of Synchronization
3.3.1 The Bounded-Buffer / Producer-Consumer Problem

The mutex binary semaphore provides mutual exclusion for accesses to the buffer pool and is initialized to the value 1. The empty and full semaphores count the number of empty and full buffers. The semaphore empty is initialized to the value n, the semaphore full is initialized to the value 0.
生产者消费者问题
3.3.2 The Readers - Writers Problem
A data set is shared among a number of concurrent processes. Only one single writer can access the shared data at the same time, any other writers or readers must be blocked. Allow multiple readers to read at the same time, any writers must be blocked.
读者写者问题
3.3.3 The Dining-Philosophers Problem
How to allocate several resources among several processes. Several solutions are possible:
- Allow only 4 philosophers to be hungry at a time.
- Allow pickup only if both chopsticks are available.
- Odd: philosopher always picks up left chopstick first
- Even: philosopher always picks up right chopstick first
哲学家进餐问题
4. CPU Scheduling
4.1 Basic Concepts
4.1.1 CPU - I/O Burst Cycle
Process execution consists of a cycle of CPU execution and I/O wait. Process execution begins with a CPU burst, followed by an I/O burst, then another CPU burst .etc. An I/O-bound program would typically have many short CPU bursts, A CPU-bound program might have a few very long CPU bursts. This can help to select an appropriate CPU-scheduling algorithm.
The duration of these CPU burst have been measured.
4.1.2 Types of Processes
I/O bound
Has small bursts of CPU activity and then waits for I/O.
Affects user interaction (we want these processes to have highest priority)
CPU bound
Hardly any I/O, mostly CPU activity, useful to have long CPU bursts. Could do with lower priorities.
4.1.3 The CPU scheduler
The CPU scheduler is the mechanism to select which process has to be executed next and allocates the CPU to that process. Schedulers are responsible for transferring a process from one state to the other.
Basically, we have three types of schedulers:
- Long-Term Scheduler
- Short-Term Scheduler
- Medium-Term Scheduler
Scheduler triggered to run when timer interrupt occurs or when running process is blocked on I/O. Scheduler picks another process from the ready queue. Performs a context switch.
Preemptive scheduling
the system may stop the execution of the running process and after that, the context switch may provide the processor to another process. The interrupted process is put back into the ready queue and will be scheduled sometime in future, according to the scheduling policy
Non-preemptive scheduling
when a process is assigned to the processor, it is allowed to execute to its completion, that is, a system cannot take away the processor from the process until it exits.
Any other process which enters the queue has to wait until the current process finishes its CPU cycle
CPU scheduling takes place on 4 circumstances:
- When the process changes state from Running to Ready eg: when an interrupt occurs
- Changes state from Running to Waiting ex: as result of I/O request or wait()
- Changes state from Waiting to Ready ex: at completion of I/O.
- Process Terminates.
Scheduling under 2 and 4 is nonpreemptive - a new process must be selected. All other scheduling is preemptive (either continue running the current process or select a different one).
4.1.4 Dispatcher
Dispatcher module gives control of the CPU to the process selected by the short-term scheduler. This involves:
- switching context
- switching to user mode
- jumping to the proper location in the user program to restart that program
Dispatch latency: time it takes for the dispatcher to stop one process and start another running. Dispatcher is invoked during every process switch; hence it should be as fast as possible
4.2 Scheduling Criteria
- Max CPU utilization: keep the CPU as busy as possible
- Max Throughput: complete as many processes as possible per unit time
- Fairness: give each process a fair share of CPU
- Min Waiting time: process should not wait long in the ready queue
- Min Response time: CPU should respond immediately
4.3 Scheduling Algorithms
Order of scheduling matters
Terms the algorithms deal with:
- Arrival Time (AT): Time at which the process arrives in the ready queue.
- Completion Time: Time at which process completes its execution.
- Burst Time: Time required by a process for CPU execution.
- Turnaround Time (TT): the total amount of time spent by the process from coming in the ready state for the first time to its completion. Turnaround time = Exit time - Arrival time
- Waiting Time (WT): The total time spent by the process/thread in the ready state waiting for CPU.
- Response time: Time at which the process gets the CPU for the first time (自进程就绪至进程第一次获得CPU响应的时间)
4.3.1 First - Come, First - Served (FCFS) Scheduling
Poor in performance as average wait time is high
4.3.2 Shortest Job First (SJF) NO preemption
Advantages:
- Minimizes average wait time and average response time
Disadvantages:
- Not practical : difficult to predict burst time
- May starve long jobs
Determining Length of Next CPU Burst
No way to know exact length of process’s next CPU burst. But it can be estimated by using lengths of past bursts: next = average of all past bursts
Exponential averaging: next = average of (past estimate + past actual)
Let t n t_n tn = actual length of the n t h n^{th} nth burst. τ n \tau_n τn = predicted value for the next CPU burst. 0 ≤ a ≤ 1 0\le a\le1 0≤a≤1 = weighing factor. The estimate of the next CPU burst period is: τ n + 1 = a t n + ( 1 − a ) τ n \tau_{n+1}=at_n+(1-a)\tau_n τn+1=atn+(1−a)τn
Commonly, a = 1 2 a=\frac12 a=21. If a = 0 a=0 a=0, then recent history has no effect. If a = 1 a=1 a=1, then only the most recent CPU bursts matter.
4.3.3 Shortest-Remaining-Time-First (SRTF) SJF with preemption
If a new process arrives with a shorter burst time than remaining of current process, then schedule new process
Further reduces average waiting time and average response time
Context Switch - the context of the process is saved in the Process Control Block PCB when the process is removed from the execution and the next process is scheduled. This PCB is accessed on the next execution of this process.
4.3.4 Priority Scheduling
Each process is assigned a priority
The CPU is allocated to the process with the highest priority (smallest integer = highest priority)
Priorities may be:
- Internal priorities based on criteria within OS. Ex: memory needs.
- External priorities based on criteria outside OS. Ex: assigned by administrators.
problem:
low priority processes may never execute
solution:
Aging: as time progresses increase the priority of the process
4.3.5 Round Robin (RR) Scheduling
Each process gets a small unit of CPU time (time quantum or time-slice), usually 10-100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue Ready queue is treated as a circular queue
If there are n n n processes in the ready queue and the time quantum is q q q, then each process gets 1 n \frac1n n1 of the CPU time in chunks of at most q q q time units at once. No process waits more than ( n − 1 ) q (n-1)q (n−1)q time units
q q q large: RR scheduling = FCFS scheduling
q q q small: q q q must be large with respect to context switch, otherwise overhead is too high
4.3.6 Multilevel Queue Scheduling
Ready queue is partitioned into separate queues.
将系统中的进程就绪队列从一个拆分为若干个,将不同类型或性质的进程固定分配在不同的就绪队列,不同的就绪队列采用不同的调度算法,一个就绪队列中的进程可以设置不同的优先级,不同的就绪队列本身也可以设置不同的优先级。
多级队列调度算法由于设置多个就绪队列,因此对每个就绪队列就可以实施不同的调度算法,因此,系统针对不同用户进程的需求,很容易提供多种调度策略。
foreground (interactive) processes: May have externally defined priority over background processes
background (batch) processes: Process permanently associated to a given queue; no move to a different queue
There are two types of scheduling in multi-level queue scheduling:
- Scheduling among the queues.
- Scheduling between the processes of the selected queue.
Must schedule among the queues too (not just processes):
- Fixed priority scheduling (i.e., serve all from foreground then from background). Possibility of starvation.
- Time slice: each queue gets a certain amount of CPU time which it can schedule amongst its processes. 80% to foreground in RR, and 20% to background in FCFS
The various categories of processes can be:
- Interactive processes
- Non-interactive processes
- CPU-bound processes
- I/O-bound processes
- Foreground processes
- Background processes

4.3.7 Multilevel Feedback Queue Scheduling
automatically place processes into priority levels based on their CPU burst behavior
多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。UNIX 就是采取的这种算法。
I/O-intensive processes will end up on higher priority queues and CPU-intensive processes will end up on low priority queues. A process can move between the various queues (aging can be implemented this way).
A multilevel feedback queue uses two basic rules:
- A new process gets placed in the highest priority queue.
- If a process does not finish its quantum, then it will stay at the same priority level otherwise it moves to the next lower priority level
Multilevel-feedback-queue scheduler defined by the following parameters:
- number of queues
- scheduling algorithms for each queue
- method used to determine when to upgrade a process
- method used to determine when to demote a process
- method used to determine which queue a process will enter when that process needs service
e.g.
Three queues:
- Q 0 Q_0 Q0: RR with time quantum 8 milliseconds (Highest priority. Preempts Q 1 Q_1 Q1 and Q 2 Q_2 Q2 proc’s)
- Q 1 Q_1 Q1: RR time quantum 16 milliseconds (Medium priority. Preempts processes in Q 2 Q_2 Q2)
- Q 2 Q_2 Q2: FCFS (Lowest priority)
Scheduling:
- A new job enters queue Q 0 Q_0 Q0 which is served FCFS. When it gains CPU, job receives 8 milliseconds, if it does not finish in 8 milliseconds, job is moved to queue Q 1 Q_1 Q1
- At Q 1 Q_1 Q1 job is again served RR and receives 16 additional milliseconds, if it still does not complete, it is preempted and moved to queue Q2
FCFS, RR, Priority Scheduling 算法的 C++ 模拟实现:
#include 4.4 Thread Scheduling / Contention scope
The contention scope refers to the scope in which threads compete for the use of physical CPUs
There are two possible contention scopes:
- Process Contention Scope (PCS) (unbound threads): competition for the CPU takes place among threads belonging to the same process. Available on the many-to-one model
- System Contention Scope (SCS) (unbound threads): competition for the CPU takes place among all threads in the system. Available on the one-to-one model
- In an many-to-many thread model, user threads can have either system or process contention scope
4.5 Multi-Processor Scheduling
4.5.1 Structure of Multi-Processor OSs
Different inter-process communication and synchronization techniques are required.
In multiprocessing systems, all processors share a memory.
There are three structures for multi-processor OS:
-
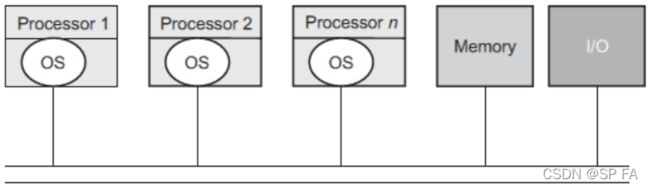
Separate Kernel Configuration: Each processor has its own I/O devices and file system. There is very little
interdependence among the processors. A process started on a processor runs to completion on that processor only.Disadvantage: parallel execution is not possible. A single task cannot be divided into sub-tasks and distributed among several processors, thereby losing the advantage of computational speed-up
-
Master-Slave Configuration (Asymmetric Configuration): One processor as master and other processors in the system as slaves. The master processor runs the OS and processes while slave processors run the processes only. The process scheduling is performed by the master processor.
Advantage: The parallel processing is possible as a task can be broken down into sub-tasks and assigned to various processors.

-
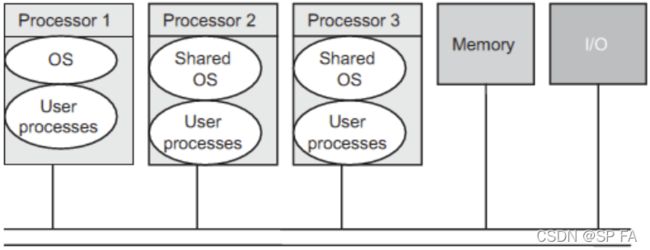
Symmetric Configuration (SMP): Any processor can access any device and can handle any interrupts generated on it. Mutual exclusion must be enforced such that only one processor is allowed to execute the OS at one time. Mutual exclusion must be enforced such that only one processor is allowed to execute the OS at one time.
4.5.2 Processor Affinity
Processor affinity is the ability to direct a specific task, or process, to use a specified core.
The idea behind: if the process is directed to always use the same core it is possible that the process will run more efficiently because of the cache re-use. (If a process migrates from one CPU to another, the old instruction and address caches become invalid, and it will take time for caches on the new CPU to become ‘populated’)
Soft affinity: OSs try to keep a process running on the same processor but not guaranteeing it will do so
Hard affinity: allows a process to specify a subset of processors on which it may run.
4.5.3 Load Balancing
When each processor has a separate ready queue, there can be an imbalance in the numbers of jobs in the queues.
Push migration: A system process periodically checks ready queues and moves (or push) processes to different queues, if need be.
Pull migration: If scheduler finds there is no process in ready queue so it raids another processor’s run queue and transfers a process onto its own queue so it will have something to run (pulls a waiting task from a busy processor).
4.5.4 Multicore Processors
A core executes one thread at a time
Memory stall: Single-core processor spends time waiting for the data to become available (slowing or stopping of a process)
Solution: to put multiple processor cores onto a single chip to run multiple kernel threads concurrently.
4.5.5 Hyperthreading
the physical processor is divided into two logical or virtual processors that are treated as if they are actually physical cores by the operating system (Simultaneous multithreading SMT). Hyper Threading allows multiple threads to run on each core of CPU
Techniques for multithreading:
- Coarse-grained multithreading: switching between threads only when one thread blocks (long latency event such as a memory stall occurs).
- Fine-grained multithreading: instructions “scheduling” among threads obeys a Round Robin policy.
4.6 Real-Time CPU Scheduling
A real-time system is one in which time plays an essential role. The RTOS schedules all tasks according to the deadline information and ensures that all deadlines are met.
- Hard real-time system: is one that must meet its deadline; otherwise, it will cause unacceptable damage or a fatal error to the system.
- Soft real-time system: an associated deadline that is desirable but not necessary; it still makes sense to schedule and complete the task even if it has passed its deadline
Aperiodic tasks (random time) has irregular arrival times and either soft or hard deadlines.
Periodic tasks (repeated tasks), the requirement may be stated as “once per period T” or “exactly T units apart.”
Issues
The major challenge for an RTOS is to schedule the real-time tasks.
Two types of latencies may delay the processing (performance):
- Interrupt latency: aka interrupt response time is the time elapsed between the last instruction executed on the current interrupted task and start of the interrupt handler.
- Dispatch latency: time it takes for the dispatcher to stop one process and start another running. To keep dispatch latency low is to provide preemptive kernels
Static scheduling: A schedule is prepared before execution of the application begins.
Priority-based scheduling: The priority assigned to the tasks depends on how quickly a task has to respond to the event.
Dynamic scheduling: There is complete knowledge of tasks set, but new arrivals are not known. Therefore, the schedule changes over the time
The timing constraints are in the form of period and deadline. The period is the amount of time between iterations of a regularly repeated task. Such repeated tasks are called periodic tasks. The deadline is a constraint of the maximum time limit within which the operation must be complete.
The scheduling criteria in a real-time system:
- The timing constraints of the system must be met.
- The cost of context switches, while preempting, must be reduced.
The scheduling in real-time systems may be performed in the following ways: pre-emptively, non-preemptively, statically, and dynamically.
- Rate-Monotonic Scheduling: 一种静态优先级调度算法,是经典的周期性任务调度算法。RMS 的基本思路是任务的优先级与它的周期表现为单调函数的关系,任务的周期越短,优先级越高;任务的周期越长,优先级越低。
Let t i = t_i= ti= the execution time and p i = p_i= pi= the period of process, the CPU utilization of a process p i p_i pi is t i p i \frac{t_i}{p_i} piti. To meet all the deadlines in the system, the following must be satisfied: ∑ i t i p i ≤ 1 \sum_i\frac{t_i}{p_i}\le1 ∑ipiti≤1. The worst-case processor utilization for scheduling processes may be given as the following: ∑ i t i p i ≤ n ( 2 1 n − 1 ) \sum_i\frac{t_i}{p_i}\le n(2^{\frac1n}-1) ∑ipiti≤n(2n1−1) - Earliest-Deadline-First Scheduling: 调度器从已就绪但没有处理完的任务中选择最早截止的任务。在有新任务到来时,正在运行的任务被剥夺,调度器从两个任务中选择截止最早的任务,若该任务不在周期内,就处理另一任务,若另一任务也不在周期内,就让 CPU 空跑到下一个周期任务。若该任务能在期限前完成,则运行到结束;否则,就运行到截止时间,然后抢回处理器。
- Proportional Share Scheduling: T T T shares are allocated among all processes in the system. An application receives N N N shares where N < T N
N<T . This ensures each application will receive N / T N/T N/T of the total processor time. 比例共享调度算法指基于 CPU 使用比例的共享式的调度算法,其基本思想就是按照一定的权重(比例)对一组需要调度的任务进行调度,让它们的执行时间与它们的权重完全成正比。比例共享调度算法的一个问题就是它没有定义任何优先级的概念;所有的任务都根据它们申请的比例共享CPU资源,当系统处于过载状态时,所有的任务的执行都会按比例地变慢。所以为了保证系统中实时进程能够获得一定的CPU处理时间,一般采用一种动态调节进程权重的方法。
4.7 Algorithm Evaluation
4.7.1 Deterministic Modeling
Takes a particular predetermined workload and defines the performance of each algorithm for that workload. What algorithm can provide the minimum average waiting time?

4.7.2 Queueing Models
If we define a queue for the CPU and a queue for each I/O device, we can test the various scheduling algorithms using queueing theory.
Little’s formula: processes leaving queue must equal processes arriving, thus: n = λ × W n=\lambda\times W n=λ×W n = n= n= average queue length
W = W= W= average waiting time in queue
λ = \lambda= λ= average arrival rate into queue
4.7.3 Simulations
We can use trace tapes. This is data collected from real processes on real machines and is fed into the simulation.
5. Deadlock
5.1 System Model
System consists of resources.
Resource types R 1 , R 2 , ⋯ , R m R_1, R_2, \cdots, R_m R1,R2,⋯,Rm. (CPU cycles, memory space, I/O devices)
Each resource type R i R_i Ri has W i W_i Wi instances.
Each process utilizes a resource as follows: request, use, release.
5.2 Deadlock Characterization
Deadlock can be defined as the permanent blocking of a set of processes that compete for system resources
Deadlock can arise if four conditions hold simultaneously:
- MUTUAL EXCLUSION: only one process at a time can use a resource.
- HOLD AND WAIT: a process holding at least one resource is waiting to acquire additional resources held by other processes
- NO PREEMPTION: a resource can be released only voluntarily by the process holding it, after that process has completed its task.
- CIRCULAR WAIT: a closed chain of processes exists, such that each process holds at least one resource needed by the next process in the chain.
Resource-Allocation Graph
A set of vertices V V V and a set of edges E E E, V V V is partitioned into two types:
- P = { P 1 , P 2 , ⋯ , P n } P=\{P_1,P_2,\cdots,P_n\} P={P1,P2,⋯,Pn}, the set consisting of all the processes in the system
- R = { R 1 , R 2 , ⋯ , R m } R=\{R_1,R_2,\cdots,R_m\} R={R1,R2,⋯,Rm}, the set consisting of all resource types in the system
and two types of E E E:
- request edge: directed edge P i → R j P_i\to R_j Pi→Rj
- assignment edge: directed edge R j → P i R_j\to P_i Rj→Pi
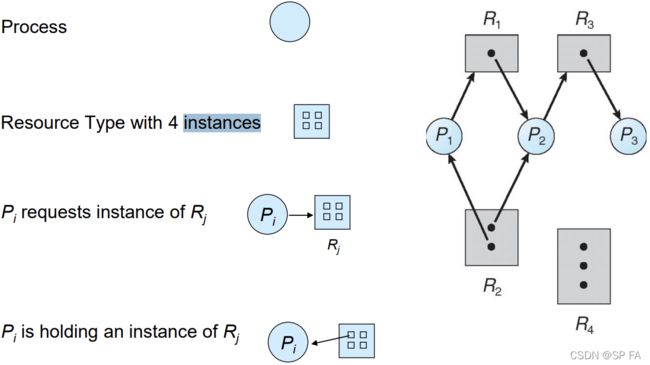
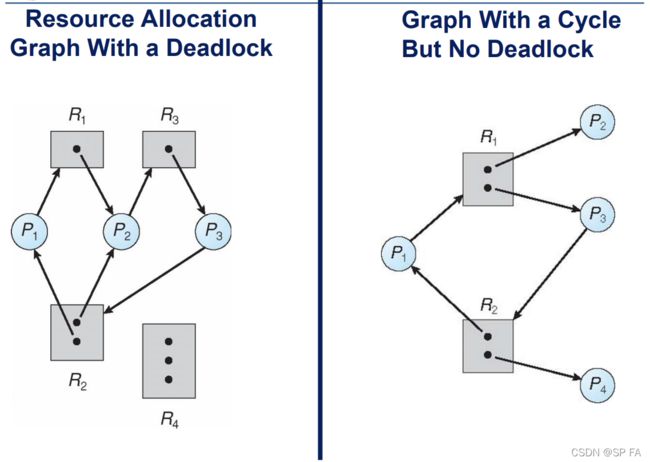
Basic Facts
If graph contains no cycles ⇒ \Rightarrow ⇒ no deadlock
If graph contains a cycle ⇒ \Rightarrow ⇒ if only one instance per resource type, then deadlock, if several instances per resource type, possibility of deadlock.
5.3 Methods for Handling Deadlocks
Ensure that the system will never enter a deadlock state
To deal with the deadlock, the following three approaches can be used:
5.3.1 Deadlock Prevention
adopting a policy that eliminates one of the conditions
- Mutual Exclusion: In general, the first of the four conditions cannot be disallowed. If access to a resource requires mutual exclusion, then mutual exclusion must be supported by the OS.
- Hold and Wait: must guarantee that whenever a process requests a resource, it does not hold any other resources. Require process to request and be allocated all its resources before it begins execution or allow process to request resources only when the process has none allocated to it. Low resource utilization, starvation possible
- No Preemption: can be prevented in several ways. if a process holding certain resources is denied a further request, that process must release its original resources and, if necessary, request them again together with the additional resource. If a process requests a resource that is currently held by another process, the OS may preempt the second process and require it to release its resources.
- Circular Wait: can be prevented by defining a linear ordering of resource types. If a process has been allocated resources of type R, then it may subsequently request only those resources of types following R in the ordering.
5.3.2 Deadlock Avoidance
we constrain resource requests to prevent at least one of the four conditions of deadlock.
Two approaches to deadlock avoidance:
- Do not start a process if its demands might lead to deadlock.
- Do not grant an incremental resource request to a process if this allocation might lead to deadlock.
A safe state is one in which there is at least one sequence of resource allocations to processes that does not result in a deadlock. If a system is in safe state, it implies no deadlocks. If a system is in unsafe state, it possibility of deadlock.
The avoidance approach requires the knowledge of:
- Max needs: total amount of each resource in the system
- Available resources: total amount of each resource not allocated to any process
- Need / resources needed: future requests of the process i i i for resource j j j
- Allocation / Current allocated resources: the resources allocated presently to process i i i
A resource request is feasible, only if the total number of allocated resources of a resource type does not exceed the total number of that resource type in the system.
Two approaches to deadlock avoidance:
-
Single Instance of Resources: Where every resource type has a single instance of resource, the RAG can be used. Claim edge P i → R j P_i\rightarrow R_j Pi→Rj indicated that process P i P_i Pi may request resource R j R_j Rj, represented by a dashed line. After the cycle check, if it is confirmed that there will be no circular wait, the claim edge is converted to a request edge. Otherwise, it will be rejected. Request edge converted to an assignment edge when the resource is allocated to the process. When a resource is released by a process, assignment edge reconverts to a claim edge.
-
Multiple Instances of Resources: Banker’s Algorithm
Let n n n= number of processes, and m m m= number of resources types.- Available: Vector of length m m m. If A v a i l a b l e [ j ] = k Available[j]=k Available[j]=k there are k k k instances of resource type R j R_j Rj available.
- Max: n × m n\times m n×m matrix. If M a x [ i , j ] = k Max[i,j]=k Max[i,j]=k, then process P i P_i Pi may request at most k k k instances of resource type R j R_j Rj.
- Allocation: n × m n\times m n×m matrix. If A l l o c a t i o n [ i , j ] = k Allocation[i,j]=k Allocation[i,j]=k then P i P_i Pi is currently allocated k k k instances of R j R_j Rj
- Need: n × m n\times m n×m matrix. If N e e d [ i , j ] = k Need[i,j]=k Need[i,j]=k, then P i P_i Pi may need k k k more instances of R j R_j Rj to complete its task. N e e d [ i , j ] = M a x [ i , j ] − A l l o c a t i o n [ i , j ] Need[i,j]=Max[i,j]-Allocation[i,j] Need[i,j]=Max[i,j]−Allocation[i,j]
- Request: R e q u e s t [ i ] Request[i] Request[i] = request vector for process P i P_i Pi. If R e q u e s t [ i , j ] = k Request[i,j]=k Request[i,j]=k then process P i P_i Pi wants k k k instances of resource type R j R_j Rj
The banker’s algorithm has two parts:
- Safety Test algorithm: that checks the current state of the system for its safe state.
Let W o r k Work Work and F i n i s h Finish Finish be vectors of length m m m and n n n, respectively.
- Initialize W o r k = A v a i l a b l e Work=Available Work=Available and F i n i s h = F a l s e Finish=False Finish=False.
- Find an i i i such that both: F i n i s h [ i ] = F a l s e Finish[i]=False Finish[i]=False and N e e d [ i ] ≤ W o r k Need[i]\le Work Need[i]≤Work. If no such i i i exists, go to step 4.
- W o r k + = A l l o c a t i o n [ i ] Work+=Allocation[i] Work+=Allocation[i], F i n i s h [ i ] = T r u e Finish[i]=True Finish[i]=True, go to step 2.
- If F i n i s h = = T r u e Finish==True Finish==True, then the system is in a safe state.
- Resource request algorithm: that verifies whether the requested resources, when allocated to the process, affect the safe state. If it does, the request is denied.
- If R e q u e s t [ i ] ≤ N e e d [ i ] Request[i]\le Need[i] Request[i]≤Need[i] go to step 2. Otherwise, raise error condition, since process has exceeded its maximum claim.
- If R e q u e s t [ i ] ≤ A v a i l a b l e Request[i]\le Available Request[i]≤Available, go to step 3. Otherwise, P i P_i Pi must wait, since resources are not available.
- Pretend to allocate requested resources to P i P_i Pi by: A v a i l a b l e − = R e q u e s t [ i ] Available-=Request[i] Available−=Request[i], A l l o c a t i o n [ i ] + = R e q u e s t [ i ] Allocation[i]+= Request[i] Allocation[i]+=Request[i], N e e d [ i ] − = R e q u e s t [ i ] Need[i]-=Request[i] Need[i]−=Request[i]. If safe, then the resources are allocated to P i P_i Pi, else the old state is restored.
Banker’s Algorithm 的 C++ 实现:
#include 5.3.3 Deadlock Detection
Ignore the problem and pretend that deadlocks never occur in the system (used by most operating systems, including UNIX)
Deadlock detection has two parts:
-
Detection of single instance of resource
Resource-Allocation Graph and Wait-for Graph:

Maintain wait-for graph:- Nodes are processes
- P i → P j P_i\rightarrow P_j Pi→Pj if P i P_i Pi is waiting for P j P_j Pj
- an edge exists between the processes, only if one process waits for another.
Periodically invoke an algorithm that searches for a cycle in the graph. If there is a cycle, there exists a deadlock. An algorithm to detect a cycle in a graph requires an order of n 2 n^2 n2 operations, where n n n is the number of vertices in the graph
-
Detection of mutiple instances of resources
- Available: A vector of length m m m indicates the number of available resources of each type.
- Allocation: An n × m n\times m n×m matrix defines the number of resources of each type currently allocated to each process
- Request: An n × m n\times m n×m matrix indicates the current request of each process.
The detection algorithm investigates every possible allocation sequence for the processes that remain to be completed. Algorithm requires an order of O ( m × n 2 ) O(m\times n^2) O(m×n2) operations to detect whether the system is in deadlocked state.
- Let W o r k Work Work and F i n i s h Finish Finish be vectors of length m m m and n n n, W o r k = A v a i l a b l e Work=Available Work=Available and if A l l o c a t i o n [ i ] ≠ 0 Allocation[i]\ne0 Allocation[i]=0, then F i n i s h [ i ] = f a l s e Finish[i]=false Finish[i]=false.
- Then, find an index i i i such that both F i n i s h [ i ] = = f a l s e Finish[i]==false Finish[i]==false and R e q u e s t [ i ] ≤ W o r k Request[i]\le Work Request[i]≤Work. If no such i i i exists, go to step 4.
- W o r k + = A l l o c a t i o n [ i ] Work+=Allocation[i] Work+=Allocation[i] and F i n i s h [ i ] = t r u e Finish[i]=true Finish[i]=true, go to step 2.
- If F i n i s h [ i ] = = f a l s e Finish[i]==false Finish[i]==false, then the system is in deadlock state, P i P_i Pi is deadlocked.
Detection-Algorithm Usage
If detection algorithm is invoked arbitrarily, there may be many cycles in the resource graph and so we would not be able to tell which of the many deadlocked processes “caused” the deadlock.
5.4 Recovery from Deadlock
There are two options for breaking a deadlock:
- Process Termination
There are two methods: 1.Abort all deadlock processes. 2.Abort one process at a time until the deadlock cycle is eliminated.
Many factors may affect which process is chosen:- Priority of the process
- How long process has computed, and how much longer to completion
- Resources the process has used
- Resource’s process needs to complete
- How many processes will need to be terminated
- Is process interactive or batch?
- Resource Preemption
Three issues need to be addressed:- Select a victim: a process, whose execution has just started and requires many resources to complete, will be the right victim for preemption (minimize cost).
- Rollback: return the process to some safe state (safe checkpoint), restart it from that state
- Starvation: it may be possible that the same process is always chosen for resource preemption, resulting in a starvation situation. Thus, it is important to ensure that the process will not starve. This can be done by fixing the number of times a process can be chosen as a victim.
6. Memory Management
6.1 Memory Management Unit (MMU)
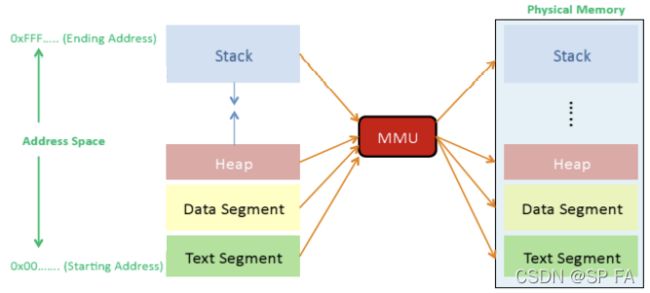
Processes access memory using a virtual address (logical address), which generated by the CPU. The OS (hardware MMU) translates the virtual address into the physical RAM address. Each memory reference is passed through the MMU
6.1.1 Memory Management Requirements
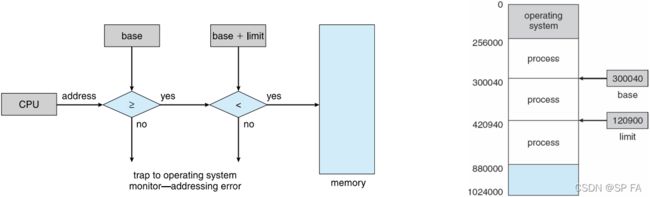
- Protection: OS needs to be protected from user processes, and user processes need to be protected from each other. Usually supported by the hardware (limit registers), because most languages allow memory addresses to be computed at run-time.
A pair of base and limit registers define the logical address space.
- Relocation: The ability to move process around in memory without affecting its execution. In MMU scheme, the value in the relocation register is added to every address generated by a user process at the time it is sent to memory. The base register is now termed a relocation register, whose value is added to every memory request at the hardware level.
- Sharing: OS has to allow sharing, while at the same time ensure protection.
- Logical Organization of memory: Main memory in a computer system is organized as a linear, address space, consisting of a sequence of bytes or words.
- Physical Organization of memory: Main memory provides fast access at relatively high cost. Secondary memory is slower and cheaper, large capacity can provide for long-term storage.
6.2 Contiguous Memory Allocation
assigns consecutive memory blocks to a process.
6.2.1 CONTIGUOUS ALLOCATION
Fixed/Static Partitioning
Fixed partitions can be of equal or unequal sizes. Assign each process to their own partition.

Variable/Dynamic Partitioning
The operating system keeps a table indicating which parts of memory are available and which are occupied. List of free memory blocks (holes) to find a hole of a suitable size whenever a process needs to be loaded into memory.
- First-fit: Allocate the first hole that’s big enough
- Best-fit: Allocate the smallest hole that’s big enough
- Worst-fit: Allocate the largest hole
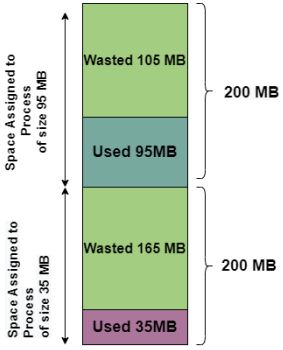
6.2.2 Fragmentation
Internal fragmentation
occurs in fixed size blocks, because the last allocated process is not completely filled.
Solution: can be reduced by using variable sized memory blocks rather than fixed sized.
External fragmentation
occurs with variable size segments, because some holes in memory will be too small to use.
Solutions:
- Compaction: moving all occupied areas of storage to one end of memory. This leaves one big hole.
- Non-contiguous memory allocation: Segmentation and Paging.
6.3 Non-Contiguous Memory Allocation
assigns different blocks of memory in a nonconsecutive manner to a process.
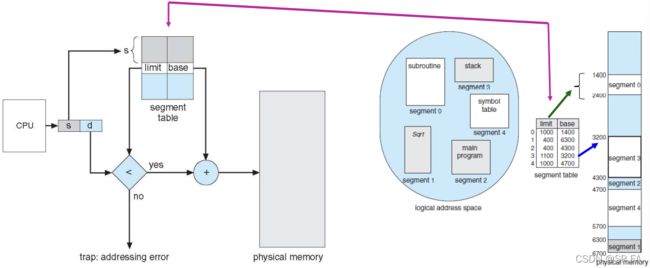
6.3.1 SEGMENTATION
The segments are logical divisions of a program, and they may be of different sizes. Each segment has a name and a length. A logical address space is a collection of segments.
Logical address consists of a two tuple:
Segment table maps two-dimensional logical address to one-dimensional physical address. Each table entry has:
- base: contains the starting physical address where the segments reside in memory
- limit: the length of the segment
6.3.2 PAGING
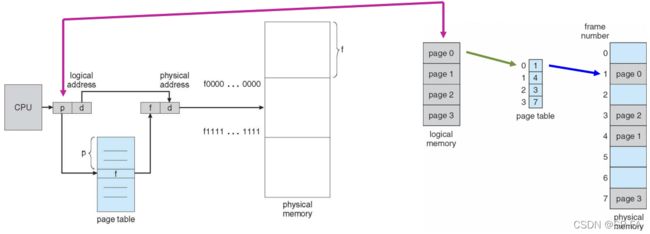
Memory is divided into equal-size partitions called frames. Logical address is divided into blocks of same size as frames called pages of a process. All the pages of the process to be executed are loaded into any available frame in the memory.
Size of a page is between 512 bytes and 1GB
Logical Address generated by CPU is divided into:
Logical Address = Page number + Page offset
Physical Address = (Frame * Page size) + Offset
For given logical address space 2 m 2^m 2m and page size 2 n 2^n 2n, page number is m − n m-n m−n and page offset is n n n
Page table is a data structure and maps the page number referenced by the CPU to the frame number where that page is stored. The address of a page table is stored in the memory, is also stored in the PCB of the process.
segmentation 和 page 的区别:
- 目的:页是信息的物理单位,分页是为实现离散分配方式,以消减内存的 external fragmentation,提高内存的利用率。或者说,分页是出于系统管理的需要而不是用户需要。段是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了更好地满足用户的需要。
- 长度:页的大小固定而且由系统决定,是由机器硬件实现的,因而在系统中只能有一种大小的页面。段的长度不固定,决定于用户所编写的程序,通常由编译程序在对程序进行编译时,根据信息的性质来划分。
- 地址空间:页的地址空间是一维的,即单一的线形地址空间,程序员只要利用一个记忆符就可以表示一个地址。段地址空间是二维的,程序员在标识一个地址时,既需要给出段名,又需给出段内地址。
- 碎片:分页有内部碎片无外部碎片,分段有外部碎片无内部碎片
- 共享和动态连接:分页不容易实现,分段容易实现
Implementation of Page Table
Page table is kept in main memory. Page-table base register (PTBR) points to the page table. Page-table length register (PTLR) indicates size of the page table
Whenever a process is scheduled to be executed, the page table address from its PCB is loaded into PTBR, and the corresponding page table is accessed in the memory. When the current process is suspended or terminated, and another process is scheduled to execute, then the PTBR entry is replaced with the page table address of a new process (context switch). The two-memory access problem can be solved by the use of a special fast-lookup hardware cache called Translation Look-aside Buffer (TLB)
Total memory access time = Time to access page table + Time to access memory location
Paging Hardware With TLB
转译后备缓冲器,也被翻译为页表缓存、转址旁路缓存,为 CPU 的一种缓存,用于改进虚拟地址到物理地址的转译速度。TLB具有固定数目的空间槽,用于存放将虚拟地址映射至物理地址的标签页表条目。为典型的结合存储(content-addressable memory,CAM)。其搜索关键字为虚拟内存地址,其搜索结果为物理地址。如果请求的虚拟地址在 TLB 中存在,将给出一个非常快速的匹配结果,之后就可以使用得到的物理地址访问存储器。如果请求的虚拟地址不在 TLB 中,就会使用标签页表进行虚实地址转换,而标签页表的访问速度比 TLB 慢很多。有些系统允许标签页表被交换到次级存储器,那么虚实地址转换可能要花非常长的时间。
A translation look-aside buffer (TLB) is a memory cache that stores the recent translations of virtual memory to physical memory.
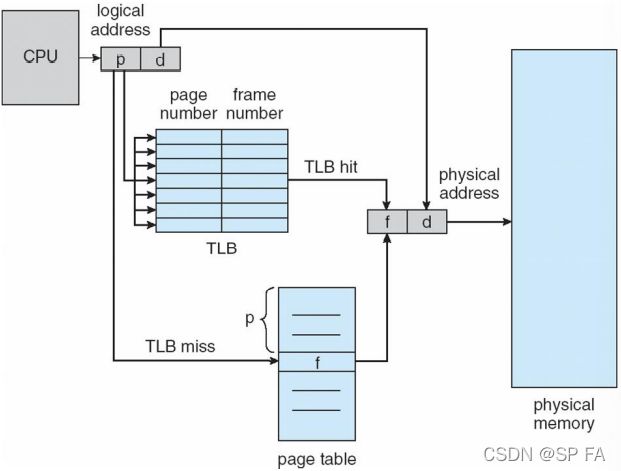
The percentage of times that the page number of interest is found in the TLB is called the hit ratio.
Let E E E = TLB lookup time, M M M = memory access time, A A A = hit ratio. Effective memory-access time (EAT) = estimation of the impact of the TLB on the execution speed of the computer.
E A T = A ( E + M ) + ( 1 − A ) ( E + 2 × M ) EAT=A(E+M)+(1-A)(E+2\times M) EAT=A(E+M)+(1−A)(E+2×M)
Memory Protection
Memory protection implemented by associating protection bit with each frame
- valid: the associated page is in the process logical address space, and is thus a legal page/indicates page is in the main memory
- invalid: indicates that the page is not in the process’ logical address space
Shared Pages
Motivation for page sharing:
- Efficient communication: Processes communicate by write to shared pages
- Memory efficiency: One copy of read-only code/data shared among processes
Only one copy of the editor need be kept in physical memory. Each user’s page table maps onto the same physical copy of the editor. But data pages are mapped onto different frames.
Structure of the Large Page Table
- Hierarchical Paging: break up virtual address space into multiple page tables at different levels. (2 level page table)
The page number has being made up of two parts: p1 and p2.- p1: used by the hardware to access into the first-level page table.
- p2: used to access within the second-level page table. This entry will be the frame number for the page number
- Hashed Page Tables: the virtual page number is hashed into a page table. This page table contains a chain of elements hashing to the same location (Common in address spaces > 32 bits)
The page number is hashed into a page table. This page table contains a chain of elements hashing to the same location. Each entry in the hash table consists of three fields:- the page number
- the value of the mapped page frame
- a pointer to the next
- Inverted Page Tables: stores a process ID of each process to identify its address space uniquely.
Each process having a page table and keeping track of all possible logical pages, track all physical pages. Entry consists of the virtual address of the page stored in that real memory location, with information about the process that owns that page. TLB can accelerate access
7. Virtual Memory
7.1 Background
Virtual memory (VM) is a method that manages the exceeded size of larger processes as compared to the available space in the memory.
Virtual memory - separation of user logical memory from physical memory.
- Only part of the program needs to be in memory for execution.
- The components of a process that are present in the memory are known as resident set of the process
- Need to allow pages/segments to be swapped in and out.
The implementation of a VM system requires both hardware and software components. The software implementing the VM system is known as VM handler. The hardware support is the memory management unit built into the CPU.
The VM system realizes a huge memory only due to the hard disk. With the help of the hard disk, the VM system is able to manage larger-size processes or multiple processes in the memory. For this purpose, a separate space known as swap space is reserved in the disk. Swap space requires a lot of management so that the VM system woks smoothly.
7.2 Demand Paging
The concept of loading only a part of the program (page) into memory for processing.
when the process begins to run, its pages are brought into memory only as they are needed, and if they’re never needed, they’re never loaded.
Lazy swapper: never swaps a page into memory unless page will be needed. Swapper that deals with pages is a pager.
7.2.1 Issues related to the implementation
How to recognize whether a page is present in the memory?
- set to “valid”: the associated page is both legal and in memory.
- set to “invalid”: the page either is not valid (not in the logical address space of the process) or is valid but is currently on the disk.
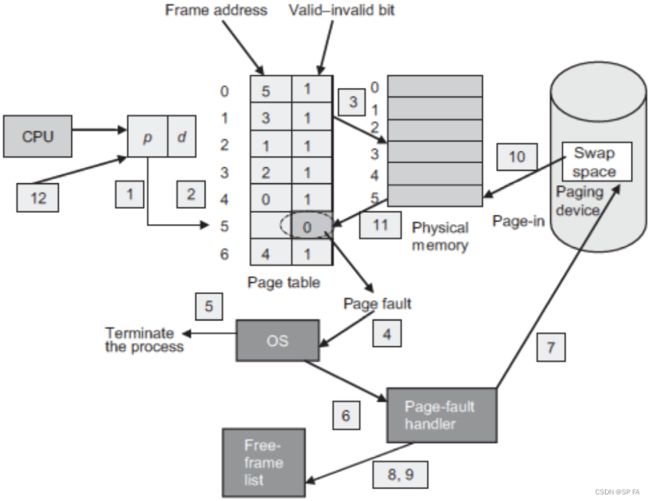
What happens if the process tries to access a page that is not in the memory?
When the page referenced is not present in the memory: page fault.
While translating the address through the page table notices that the page-table entry has an invalid bit. It causes a trap to the OS so that a page fault can be noticed.
What happens if there is no free frame?
The existing page in the memory needs to be paged-out.
Which page will be replaced? page-replacement algorithms.
Steps in Handling a Page Fault
7.2.2 Performance of Demand Paging
No page fault: the effective access time = the memory access time.
Have page fault:
Let p p p be the probability of a page fault. The effective access time (EAT) is:
E A T = ( 1 − p ) × M e m o r y A c c e s s T i m e + p × P a g e F a u l t T i m e EAT=(1-p)\times Memory Access Time+p\times Page Fault Time EAT=(1−p)×MemoryAccessTime+p×PageFaultTime
Major components of the page-fault service time:
- Service the page-fault interrupt.
- Read in the page.
- Restart the process.
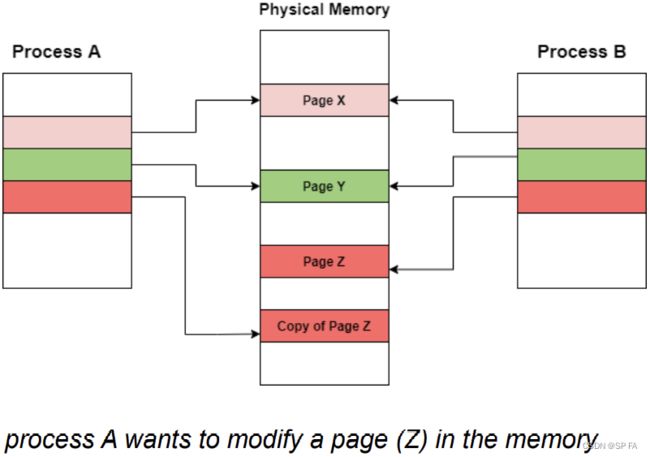
7.3 Copy-on-Write (COW) in Operating System
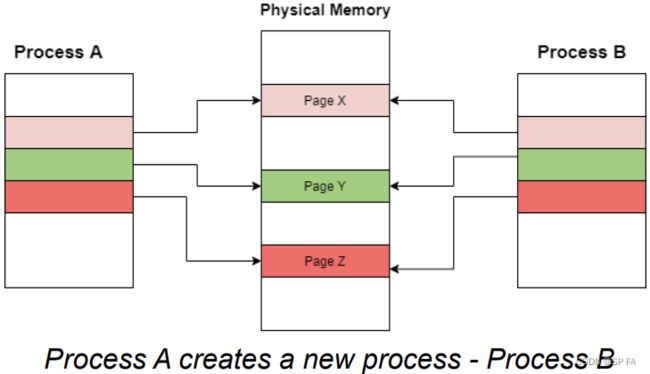
Only pages that are written need to be copied.
Process creation using the fork() system call may (initially) bypass the need for demand paging by using a technique similar to page sharing.
Copy-on-write = strategy that those pages that are never written need not be copied. Only the pages that are written need be copied.
The parent and child process to share the same pages of the memory initially. If any process either parent or child modifies the shared page, only then the page is copied.
7.4 Page Replacement
When a page fault occurs during the execution of a process, a page needs to be paged into the memory from the disk.
The degree of multiprogramming increases result in over-allocating memory which implies no free frames on the free frame list, all memory is in use.
A good replacement algorithm achieves:
- a low page fault rate: Ensure that heavily used pages stay in memory. The replaced page should not be needed for some time.
- a low latency of a page fault: Efficient code. Replace pages that do not need to be written out. a special bit called the modify (dirty) bit can be associated with each page.
Basic Page Replacement
- Find the location of the desired page on disk
- Find a free frame:
- If there is a free frame: use it
- If there is no free frame: use a page replacement algorithm to select a victim frame.
- Check the modify (dirty) bit with each page or frame. If the bit is set, the page has been modified. If the bit is not set, the page has not been modified. It need not be paged-out for replacement and can be overwritten.
- Bring the desired page into the (newly) free frame; update the page and frame tables.
- Continue the process by restarting the instruction that caused the trap.
An algorithm is evaluated by running it on a particular string of memory references and computing the number of page faults. Record a trace of the pages accessed by a process.
Reference string: the sequence of pages being referenced.
7.4.1 FIFO Algorithm
When a page must be replaced, the oldest page is chosen.

7.4.2 Optimal Algorithm
Replace page that will not be used for longest period of time. It cannot be implemented, because there is no provision in the OS to know the future memory references. The idea is to predict future references based on the past data.
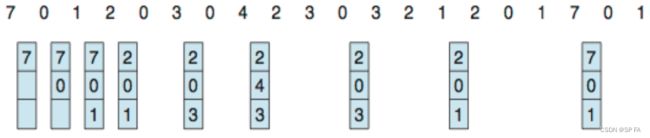
7.4.3 Least Recently Used (LRU) Algorithm
when a page fault occurs, throw out the page that has been unused for the longest time.

How to find out a page that has not been used for the longest time:
- Counter implementation: associate with each page-table entry a time-of-use field or a counter; every time page is referenced through this entry, copy the clock into the counter. When a page needs to be changed, look at the counters to find the smallest value. replace the page with the smallest time value.
- Stack implementation: whenever a page is referenced, it is removed from the stack and put on the top. the most recently used page is always at the top of the stack and the least recently used page is always at the bottom.
7.4.4 LRU Approximation Algorithms
LRU needs special hardware and still slow.
Reference bit: will say whether the page has been referred in the last clock cycle or not. Reference bits are associated with each entry in the page table. The reference bit for a page is set by the hardware whenever that page is referenced (either a read or a write to any byte in the page).
7.4.5 Second-Chance (Clock) Algorithm
keeps a circular list of pages in memory, with the iterator pointing to the last examined page frame in the list.
Iterator Scan:
- If page’s reference bit (RB) = 1, set to 0, then skip.
- Else if RB = 0, remove.
7.4.6 Counting Algorithms
Keep a counter of the number of references that have been made to each page.
Least Frequently Used (LFU) Algorithm replaces page with smallest count.
Most Frequently Used (MFU) Algorithm is based on the argument that the page with the smallest count was probably just brought in and has yet to be used.
7.5 Frame Allocation
The two algorithms commonly used to allocate frames to a process:
- Equal allocation: In a system with x frames and y processes, each process gets equal number of frames
- Proportional allocation: Frames are allocated to each process according to the process size. Let s i s_i si stands for size of process p − i p-i p−i, S = ∑ s i S=\sum s_i S=∑si, m m m is the total number of frames, a i a_i ai is the allocation for p i p_i pi a i = s i S × m a_i=\frac{s_i}{S}\times m ai=Ssi×m
Thrashing: A process is busy swapping pages in and out.
If a process does not have “enough” pages, the page-fault rate is very high. This leads to:
- Low CPU utilization.
- Operating system thinks that it needs to increase the degree of multiprogramming.
- Another process added to the system.
8. Mass-Storage Systems
Types of Secondary Storages:
- Sequential access devices: store records sequentially, one after the other. Relatively permanent and holds large quantities of data but access time slow.
- ** Direct access devices**: store data in discrete and separate location with a unique address. Nonvolatile memory used like a hard drive. Less capacity but much faster than HDDs
Moving-head Disk Mechanism
- Cylinder: Group of tracks.
- Platters: Made of Aluminum with magnetic coating.
- Sectors: A track is logically divided into sectors. It is the smallest unit of data that a disk drive will transfer.
Disk address can be specified by the cylinder, head and sector numbers, or CHS addressing.
Disk speed
- Transfer time: the time for data transfer / the time between the start of the transfer and the completion of the transfer.
- Seek time: the time taken by the disk head to move from one cylinder to another / the time it will take to reach a track.
- Rotational latency: the time taken to rotate the platter and bring the required disk sector under the read-write head.
- Positioning time / Random access time: seek time + rotational latency
- Disk access time: seek time + rotational latency + transfer time
8.1 Disk Structure
Disk is addressed as a one-dimension array of logical sectors. Disk controller maps logical sector to physical sector identified by track, surface and sector.
8.2 Disk Attachment
Computer systems can access disk storage in two ways:
- via I/O ports: This is common on small systems. Host-attached storage. The most common interfaces are Integrated Drive Electronics IDE, Advanced Technology Attachment ATA, USB each of which allow up to two drives per host controller.
- via a remote host: Always in a distributed file systems.
- Storage Area Network: fibre channels the most common interconnect, and InfiniBand (high speed connection)
- Network-Attached Storage: connection over TCP/IP, UDP/IP or host attached protocol like ISCSI)
8.3 Disk Scheduling
Goal: minimize the positioning time. Scheduling is performed by both O.S. and disk itself
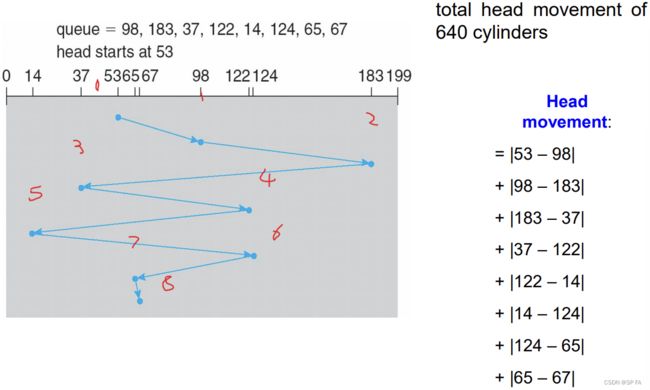
8.3.1 First-Come First-Served (FCFS) Algorithm
works well with light loads; but as soon as the load grows, service time becomes unacceptably long.
8.3.2 Shortest Seek time First (SSTF) Algorithm
quite popular and intuitively appealing. It works well with moderate loads but has the problem of localization under heavy loads.
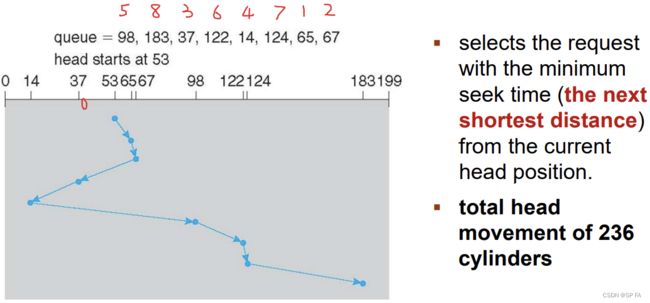
8.3.3 SCAN (Elevator)
works well with light to moderate loads and eliminates the problem of indefinite postponement. SCAN is similar to SSTF in throughput and mean service times.

8.3.4 Circular-SCAN (C-SCAN)
works well with moderate to heavy loads and has a verysmall variance in service times.

8.3.4 LOOK
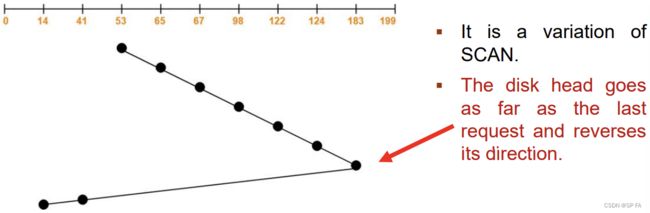
8.3.5 C-LOOK

8.4 Disk Management
Low-level formatting, or physical formatting — create sectors on a blank platter. Each sector can hold header information, plus data, plus error correction code (ECC). Usually, 512 bytes of data but can be selectable
Partition organize disk in one or more groups of cylinders
Logical formatting write file system data structures
Boot block initializes system: The bootstrap is stored in ROM. Bootstrap loader program stored in boot blocks of boot partition.
8.5 Swap-Space Management
Swap-space: Virtual memory uses disk space as an extension of main memory
Configure Swap-space:
- on a swap file in a file system. Changing the size of a swap file is easier.
- on a separate swap partition. swap partition is faster but difficult to set it up (how much swap space your system requires?)
Solution: start with a swap file and create a swap partition when it knows what the system requires. Kernel uses swap maps to track swap-space use
8.6 RAID Structure
RAID: Redundant Arrays of Independent Disks.
RAID is a system of data storage that uses multiple hard disk drives to store data. RAID is a set of physical drives viewed by the operating system as a single logical drive.
RAID controller is used for controlling a RAID array. It may be hardware- or software-based.
There are three main techniques used in RAID:
- Mirroring is copying data to more than one drive. If one disk fails, the mirror image preserves the data from the failed disk.
- Striping breaks data into “chunks” that are written in succession to different disks. Striping provides high data-transfer rates, this improves performance because your computer can access data from more than one disk simultaneously.
- Error correction redundant data is stored, allowing detection and possibly fixing of errors.
There are several different storage methods, named levels.
8.6.1 RAID Level 0
Level 0 does not provide redundancy. It treats multiple disks as a single partition. Files are Striped across disks, no redundant info.
High read throughput but any disk failure results in data loss.
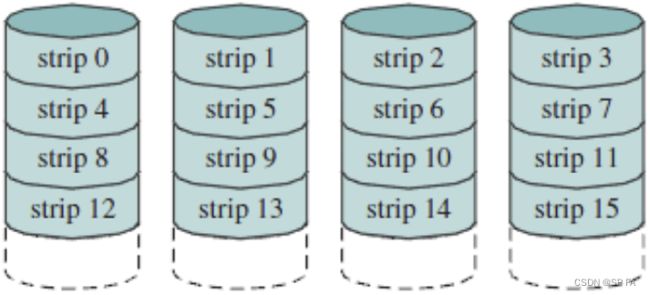
8.6.2 RAID Level 1
- Disk mirroring
- Uses striping
- is called a mirrored configuration because it provides redundancy by having a duplicate set of all data in a mirror array of disks, which acts as a backup system in the event of hardware failure.
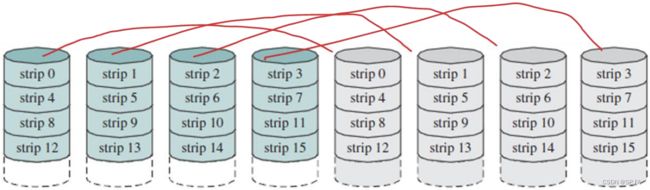
8.6.3 RAID Level 2
- memory-style error-correcting-code organization
- an error-correcting code is calculated across corresponding bits on each data disk, and the bits of the code are stored in the corresponding bit positions on multiple parity disks.
- uses very small strips (often the size of a word or a byte)
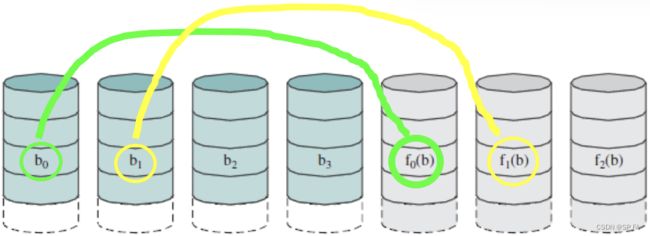
8.6.4 RAID Level 3
bit-interleaved parity organization is a modification of Level 2 and requires only a single redundant disk, no matter how large the disk array.
single parity bit can be used for error correction / detection for each strip, and it is stored in the dedicated parity disk.
Suppose, strip X = {1010}, the parity bit is 0 as there are even number of 1s.
Suppose X = {1110}, the parity bit here is 1 as there are odd number of 1s.
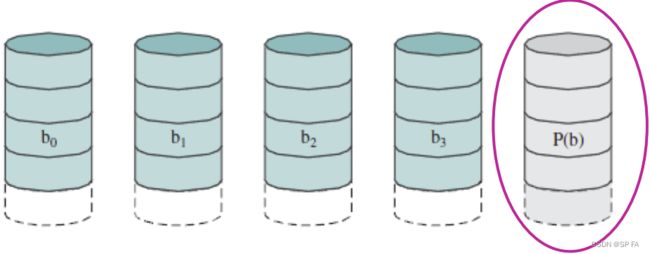
8.6.5 RAID Level 4
- block-interleaved parity organization uses large-sized strips, and the data is striped as fixed-sized blocks.
- one block in size is 512 bytes by default but can be specified otherwise.
- provides block-level striping (the same strip scheme found in Levels 0 and 1) and stores a parity block on a dedicated disk.
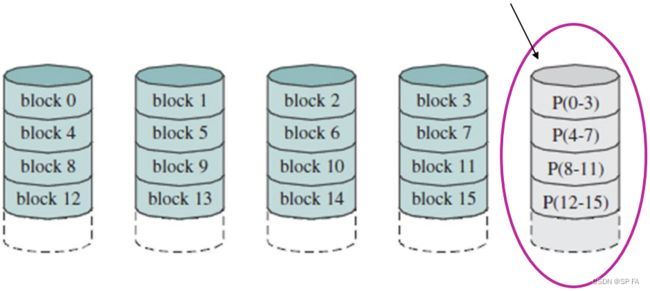
8.6.6 RAID Level 5
block-interleaved distributed parity is a modification of Level 4.
the parity bits are not stored in a single disk, distributes the parity strips across the disks.
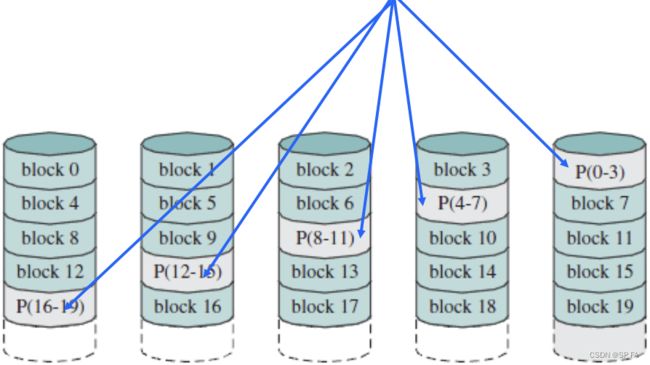
8.6.7 RAID Level 6
- P + Q redundancy scheme - independent data disks with double (dual) parity - extra degree of error detection and correction (parity and Reed-Solomon codes).
- one calculation is the same as that used in Levels 4 and 5.
- the other is an independent data-check algorithm.
- Both parities are distributed on separate disks across the array. The double parity allows for data restoration even if two disks fail.
- RAID level 6 may suffer in performance due to two parity disks.
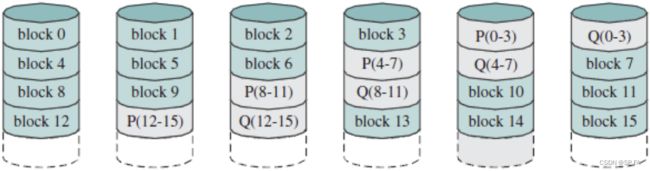
8.6.8 RAID Level 0+1
- “a mirror of stripes”: is a combination of the striping of RAID 0 (a set of disks are striped) and mirroring of RAID 1 (the stripe is mirrored to another).
- a set of n n n disks are striped, and then the stripe is mirrored on n n n redundant disks.

8.6.9 RAID Level 1+0
- “a stripe of mirrors”: combines the mirroring of RAID 1 (disks are mirrored for redundancy) with the striping of RAID 0 (stripes across disks for higher performance).
- The advantage in 1 + 0 is that in case of failure of a single disk, the mirror copy of the whole disk is available.
- Is ideal for highly utilized database servers or any server that’s performing many write operations.
- gives the best performance, but it is also costly (requires twice as many disks as other RAID levels).
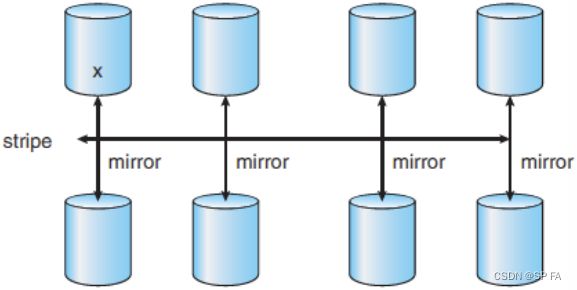
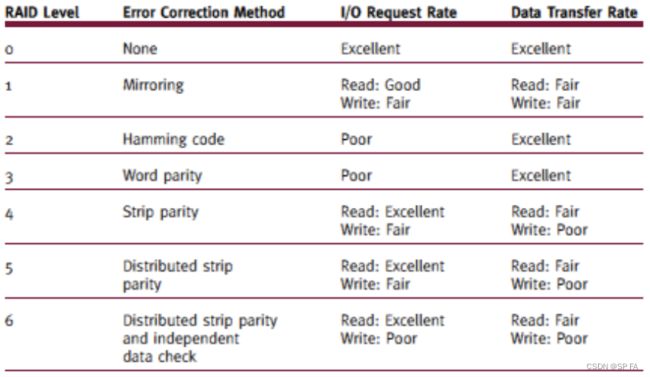
Conclusion
RAID is secure because mirroring duplicates all your data.
RAID is fast because the data is striped across multiple disks; chunks of data can be read and written to different disks simultaneously.
RAID is not a backup. A backup is a copy of data, which is stored somewhere else and is detached from the original data both in space and time
9. File System
What are file systems
Everything is stored as files in a computer system. The files can be data files or application files. A file is a named, linear region of bytes that can grow and shrink. The operating system performs this management with the help of a program called File System.
Different operating systems use different file systems:
- Windows: NTFS (New Technology File System), exFAT (Extended File Allocation Table)
- Linux: ext2, ext3, ext4, JFS, ReiserFS, XFS, and Btrfs.
- Mac: Mac OS Extended File System or HFS+ (Hierarchical File System).
- Apple: APFS, for Mac OS X, iPhones, iPads and other iOS devices
9.1 File System Interface
The user level of the file system (more visible)
Attributes of a File
A file is a named, linear region of bytes that can grow and shrink.
- Name: The user visible name.
- Type: The file is a directory, a program image, a user file, a link, etc.
- Location: Device and location on the device where the file header is located.
- Size: Number of bytes/words/blocks in the file.
- Position: Current next-read/next-write pointers. In Memory Only
- Protection: Access control on read/write/execute/delete/append/list.
- Usage: Open count. In Memory Only
- Usage: Time of creation/access, etc.
Basic File Operations
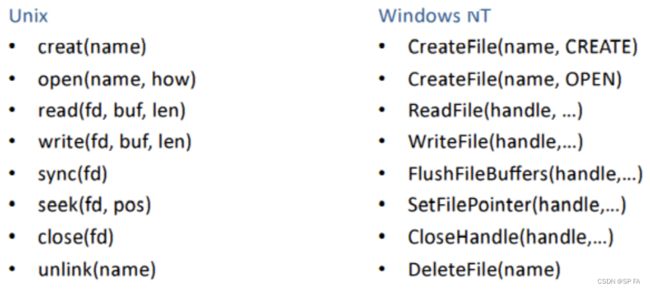
File systems break files down into two logical categories:
- Shareable vs. Unsharable files: Whether can be accessed locally and by remote hosts.
- Variable vs. Static files: Whether can be changed at any time.
Open File Table
Since the open operation fetches the attributes of the file to be opened, the OS uses a data structure known as open file table (OFT), to keep the information of an opened file.
9.1.1 Access methods
When it is used, the information must be accessed and read into computer memory.
The information in the file can be accessed in several ways:
- Sequential Access
- Data is accessed one record right after the last.
- Reads cause a pointer to be moved ahead by one.
- Writes allocate space for the record and move the pointer to the new End Of File.
- Such a method is reasonable for tape.
- Direct Access
- Method useful for disks.
- The file is viewed as a numbered sequence of blocks or records.
- There are no restrictions on which blocks are read/written in any order.
- Indexed Access
- Uses multiple indexes.
- An index block says what’s in each remaining block or contains pointers to blocks containing particular items.
- Suppose a file contains many blocks of data arranged by name alphabetically.
9.1.2 Directory Structure
Disk Structure - Storage Structure
A disk can be used in its entirety for a file system. A disk can be broken up into multiple partitions, slices, or mini-disks, each can have its own filesystem.
Disk/partition is partitioned into Blocks or Sectors. Modern disks have 512-byte or more sectors. File Systems usually work in block sizes of 4 KB
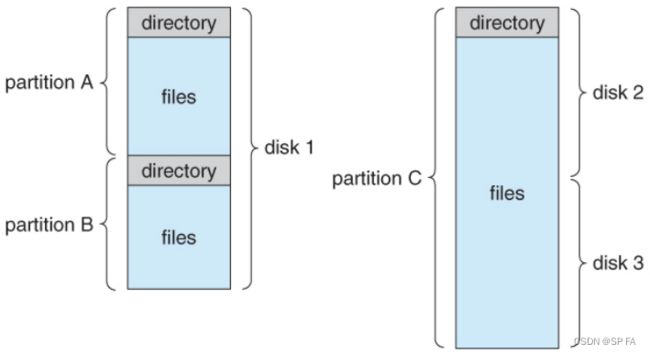
Directory - Operations Performed on Directory
The directories are used to maintain the structure of a file system.
Directories serve two purposes:
- For User: they provide a structured way to organize files.
- For the File System: they provide a convenient naming interface that allows the implementation to separate logical file organization from physical file placement on the disk.
Operations:
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system: to access every directory and every file within a directory structure.
Schemes of logical structure of a directory
- Single-Level Directory: root director, and all the files are stored only under it
- Two-Level Directory: separate directories for each user, there are two levels: master directory and user directory
- Hierarchical / Tree-Structured Directories: Two types of paths: absolute path and relative path
- Acyclic-Graph Directories: the directory structure must allow sharing of files or sub-directories.
9.1.3 Protection
Protection mechanisms provide controlled access by limiting the types of file access that can be made.
File owner/creator should be able to control:
- what can be done
- by whom
9.1.4 File-System Mounting
Mounting = attaching portions of the file system into a directory structure.
- The directory where the device is attached, is known as a mount point.
- Similarly, unmounting is done to remove the device from the mount point.
In Windows, the devices and/or partition can be accessed by opening My Computer on the desktop.
Access-Control List and Groups
general scheme to implement identity dependent access is to associate with each file and directory an access-control list (ACL) specifying usernames and the types of access allowed for each user.
Mode of access: read, write, execute (R, W, X)
The classifications:
- owner access: the user who created the file is the owner.
- group access: a set of users who are sharing the file and need similar access is a group, or work group.
- public access / universe: all other users in the system constitute the universe
9.1.5 File Sharing
Sharing must be done through a protection scheme
May use networking to allow file system access between systems
- Manually via programs like FTP or SSH
- Automatically, seamlessly using distributed file systems
- Semi automatically via the world wide web
Client-server model allows clients to mount remote file systems from servers
- Server can serve multiple clients
- Client and user-on-client identification is insecure or complicated
- NFS (Network File System) is standard UNIX client-server file sharing protocol
- CIFS (Common Internet File System) is standard Windows protocol
- Standard operating system file calls are translated into remote calls
Distributed Information Systems implement unified access to information needed for remote computing (LDAP, DNS, NIS, Active Directory).
9.2 File System Implementation
The OS level of the file system.
9.2.1 Allocation and Free Space Management
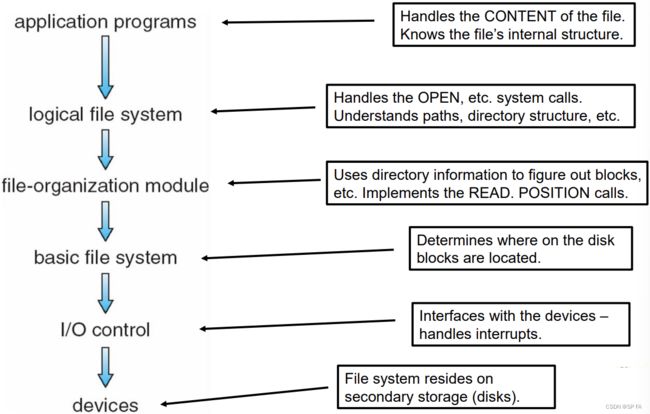
File system needs to maintain on-disk or in-memory structures
1) On-disk for data storage
On disk, the file system may contain information about how to boot an operating system stored there, the total number of blocks, the number and location of free blocks, the directory structure, and individual files.
- Boot control block is the first block of volume, and it contains information needed to boot an operating system.
- File Control Block (FCB per file) contains details about file, and it has a unique identifier number to allow association with directory entry. It is also known as Inode (Index node).
- Volume control block / Superblock contains volume/partition details: no. of blocks in the partition, block size, free block count, block pointers, etc.
- Files and Directory Structure stores file names and associated file names.
File mapping through FCB
The file system uses the logical position in a file stored by the FCB to map it to a physical location on the disk. The FCB contains a list of blocks of a file and their corresponding disk block addresses. To retrieve the data at some position in a file, the file system first translates the logical position to a physical location in the disk.

2) In-memory for data access
The in-memory information is used for both file-system management and performance improvement via caching.
- Mount table stores file system mounts, mount points, file system types.
- Directory (structure cache) holds information of recently accessed directories.
- SOFT (System-wide open-file table) maintains the information about the open files in the system.
- OFT (Per-process open-file table) maintains the detail of every file opened by a process and an entry in the OFT points to a SOFT.
- Buffer area is a temporary storage area in the memory for assisting in the reading/writing of information from/to disk.
9.2.2 Directory Implementation
A directory is a container which contains file and folder.
We can store the list of files as:
- Linear list: all the files in a directory are maintained as singly lined list. Each file contains the pointers to the data blocks which are assigned to it and the next file in the directory. It is simple to program but time-consuming to execute.
- Hash Table: linear list with hash data structure. Decreases directory search time and fixed size.
Allocation methods
There are three major allocation strategies of storing files on disks:
-
Contiguous Allocation: Each file occupies a set of contiguous blocks on the disk.
- Simple: only starting location (block #) and length (number of blocks) are required
- Random access
- Wasteful of space
- Files cannot grow
- external fragmentation, need for compaction off-line (downtime) or on-line
-
linked: each file is a linked list of disk blocks. Only efficient for sequential access files, random access requires starting at the beginning of the list for each new location access.
-
indexed: Each file has its own index block(s) of pointers to its data blocks. Brings all pointers together into the index block.
- Need index table
- Random access
- Dynamic access
Unix Inode
Unix uses an indexed allocation structure. An inode (indexed node) stores both the attributes (infos) and the pointers to disk blocks. Typically, an inode contains 15 pointers as follows:
- 12 direct pointers: that point directly to blocks
- 1 indirect pointer: point to indirect blocks; each indirect block contains pointers that point directly to blocks
- 1 double indirect pointer: that point to doubly indirect blocks, which are blocks that have pointers that point to additional indirect blocks
- 1 triple indirect pointer
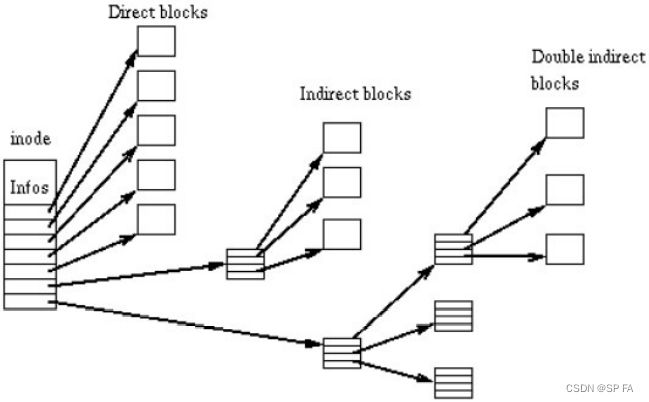
How big the index block should be? and How it should be implemented?
There are several approaches: - Linked Scheme: An index block is one disk block, which can be read and written in a single disk operation. The first index block contains some header information, the first N block addresses, and if necessary, a pointer to additional linked index blocks.
- ** Multi-Level Index**: The first index block contains a set of pointers to secondary index blocks, which in turn contain pointers to the actual data blocks.
- ** Combined Scheme**
Free-Space Management
Disk management maintains free-space list to track available blocks / free space.
- Bit Vector each bit represents a disk block, set to 1 if free or 0 if allocated.
- Linked List: link together all the free disk blocks, keeping a pointer to the first free block.
- Grouping: stores the addresses of n free blocks in the first free block.
- Counting: the number of contiguous free blocks.
- Space Maps: free-space list is implemented as a bit map, bit maps must be modified both when blocks are allocated and when they are freed
10. IO Systems
I/O management is a major component of operating system design and operation
- Important aspect of computer operation
- IO devices vary greatly
- Various methods to control them
- Performance management
- New types of devices frequent
The IO devices are classified:
- Human-readable and machine-readable: The human-readable devices are mouse, keyboard, and so on, and the machine-readable devices are sensors, controllers, disks, etc.
- Transfer of data:
- character-oriented device: accepts and delivers the data as a stream of characters/bytes
- block-oriented device: accepts and delivers the data as fixed-size blocks
- Type of access: Sequential device such as a tape drive. Random access device, such as a disk.
Network device: to send or receive data on a network.
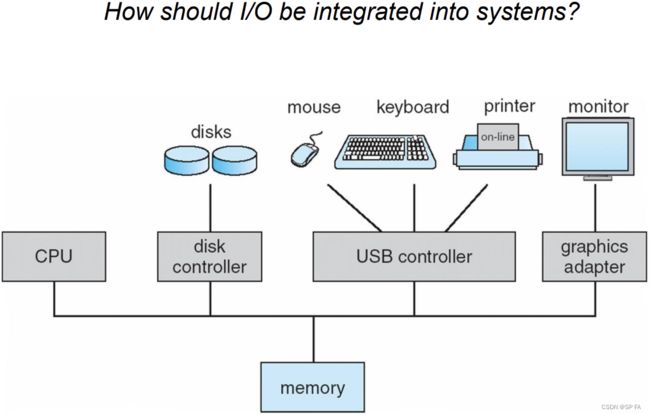
10.1 IO Hardware
Common concepts: signals from IO devices interface with computer
- Port: Connection point for device
- Bus: Daisy chain or shared direct access
- PCI: bus common in PCs and servers, PCI Express (PCIe)
- expansion bus: connects relatively slow devices
- Controller (host adapter): electronics that operate port, bus, device
- Sometimes integrated
- Sometimes separate circuit board (host adapter)
- Contains processor, microcode, private memory, bus controller, etc. A controller could have its own processor, memory, etc. (E.g.: SCSI controller)
Each controller has registers that are used for communicating with the CPU. There are data buffer that the operating system can read and write. Each IO port (device) is identified by a unique port address.
Each IO port consists of 4 registers (1-4 bytes in size):
- data-in register: data registers to get data from IO device.
- data-out register: data registers to pass data to the device.
- status register: can be read to see the current status of the device.
- control register: to tell the device to perform a certain task.
how to address a device:
- Port-mapped IO:
- Use different address space from memory
- Access by special IO instruction
- Memory-mapped IO:
- Reserve specific memory space for device
- Access by standard data-transfer instruction: More efficient for large memory I/O (e.g. graphic card). Vulnerable to accidental modification, error
10.1.1 IO communication techniques
Three techniques by which an IO operation can be performed on a device:
-
Polling: The data transfer is initiated by the instructions written in a computer program. CPU executes a busy-wait loop periodically checking status of the device to see if it is time for the next I/O operation (tests the channel status bit). CPU stays in a loop until the I/O device indicates that it is ready for data transfer. Polling can be very fast and efficient, if both the device and the controller are fast and if there is significant data to transfer. It keeps the processor busy needlessly and leads to wastage of the CPU cycles
-
Interrupt-driven IO: In pooling the processor time is wasted ⇒ \Rightarrow ⇒ a hardware mechanism: interrupt. the CPU has an interrupt-request line that is sensed after every instruction. Interrupts allow devices to notify the CPU when they have data to transfer or when an operation is complete. The CPU transfers control to the interrupt handler. Most CPUs have two interrupt-request lines:
- Non-maskable: for critical error conditions.
- Maskable: used by device controllers to request / the CPU can temporarily ignore during critical processing.
How does the processor know when the I/O is complete?
Through an interrupt mechanism. when the operation is complete, the device controller generates an interrupt to the processor. NB: the processor checks for the interrupt after every instruction cycle. after detecting an interrupt, the processor will perform a context switch, by executing the appropriate Interrupt Service Routine. Interrupt handler receives interrupts the processor then performs the data transfer for the I/O operation.Interrupt Driven IO Cycle

The basic protocol to interact with an I/O device
Wait for drive to be ready. Read Status Register until drive is not busy and READY. Write parameters to control registers. Write the sector count, logical block address (LBA) of the sectors to be accessed, and drive number. Start the IO. by issuing read/write to Control register. Data transfer (for writes): Wait until drive status is READY and DRQ (drive request for data); write data to data port. Handle interrupts. In the simplest case, handle an interrupt for each sector transferred; more complex approaches allow one final interrupt when the entire transfer is complete. Error handling. After each operation, read the status register. If the ERROR bit is on, read the error register for details. -
Direct Memory Access: when the data are large, interrupt driven IO is not efficient. Instead of reading one character at a time through the processor, a block of characters is read at a time. Bypasses CPU to transfer data directly between IO device and memory. DMA hardware generates an interrupt when the IO transaction is complete. Requires DMA controller. Version that is aware of virtual addresses can be even more efficient: Direct Virtual Memory Access DVMA.
To read or write a block, the processor sends the command to the DMA controller. The processor passes the following information to the DMA controller:- The type of request (read or write).
- The address of the IO device to which IO operation is to be carried out.
- The start address of the memory, where the data need to be written or read from, along with the total number of words.
- The DMA controller then copies this address and the word count to its registers.
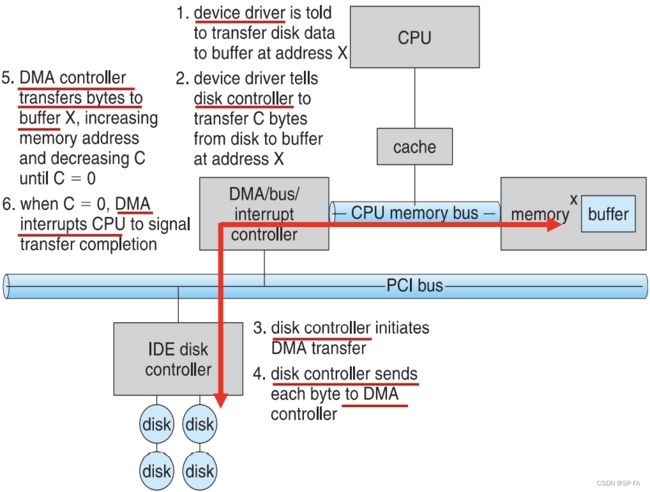
Layered structure of IO
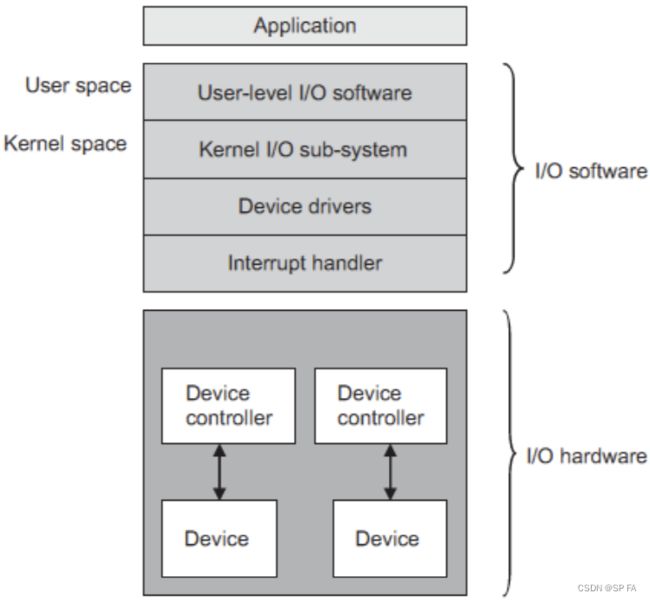
10.2 Application IO Interface
User application access to a wide variety of different devices. Device-driver layer hides differences among I/O controllers from kernel
Devices vary in many dimensions:
- Character-stream or block:
- Block devices are accessed a block at a time. Include disk drives. Commands include read, write, seek
Raw IO (accessing blocks on a hard drive directly)
Direct IO (uses the normal filesystem access)
Memory-mapped file I/O - Character devices are accessed one byte at a time. Include keyboards, mice, serial ports. Commands include get(), put(). Supported by higher-level library routines.
- Block devices are accessed a block at a time. Include disk drives. Commands include read, write, seek
- Network Devices: Varying enough from block and character to have own interface. Linux, Unix, Windows and many others include socket interface. socket acts like a cable or pipeline connecting two networked entities. Approaches vary widely (pipes, FIFOs, streams, queues, mailboxes)
- Clocks and Timers:
Three types of time services are commonly needed in modern systems:- Get the current time of day.
- Get the elapsed time since a previous event.
- Set a timer to trigger event X at time T.
A Programmable Interrupt Timer, PIT can be used to trigger operations and to measure elapsed time.
ioctl() (on UNIX) covers odd aspects of I/O such as clocks and timers
- Blocking and Non-blocking IO:
- Blocking: process suspended (move it in the waiting queue) until I/O completed
- Nonblocking: the IO request returns immediately, whether the requested IO operation has (completely) occurred or not. This allows the process to check for available data without getting blocked completely. variation of the non-blocking IO is the asynchronous IO.
- Vectored IO: known as scatter/gather IO. Scatter/gather refers to the process of gathering data from, or scattering data into, the given set of buffers. Read from or write to multiple buffers at once. Allows one system call to perform multiple IO operations. For example, Unix readve() accepts a vector of multiple buffers to read into or write from.
10.3 Kernel IO Subsystem
This part is provided in the kernel space. The user interacts with this layer to access any device.
There are different functions:
- Uniform Interface: There are different device drivers for various devices. UI makes uniform the interface, such that all the drivers’ interface through a common interface.
- Scheduling: Some IO request ordering via per-device queue. Some OSs try fairness.
- Buffering: Store data in memory while transferring between devices. A buffer is an area where the data, being read or written, are copied in it, so that the operation on the device can be performed with its own speed.
- Single buffering: kernel and user buffers, varying sizes.
- Double buffering: two copies of the data. Permits one set of data to be used while another is collected.
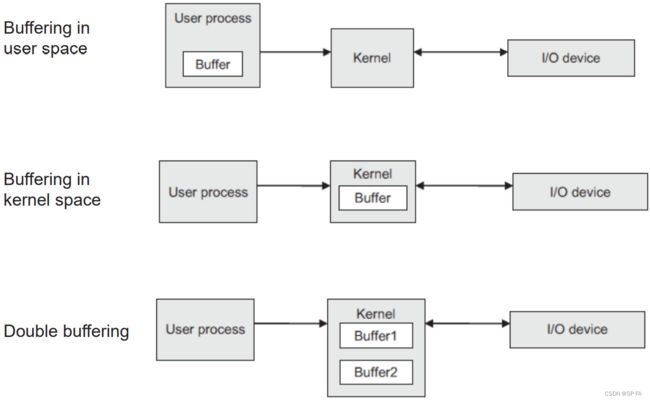
- Caching: faster device holding copy of data. Involves keeping a copy of data in a faster-access location than where the data is normally stored. Buffering and caching use often the same storage space.
- Spooling and Device reservation: (SPOOL = Simultaneous Peripheral Operations On-Line) buffers data for devices that cannot support interleaved data streams. device can serve only one request at a time. spool queues can be general or specific.
- IO protection: provides exclusive access to a device. All IO instructions defined to be privileged. IO must be performed via system calls that must be performed in kernel mode. Memory-mapped and IO port memory locations must be protected by the memory management system.
- Error Handling: an operating system that uses protected memory can guard against many kinds of hardware and application errors. I/O requests can fail for many reasons, either momentary (buffers overflow) or permanent (disk crash). IO requests usually return an error bit ( or more ) indicating the problem. UNIX systems also set the global variable errno
10.4 Device Driver
At the lowest level, a piece of software in the OS must know in detail how a device works. We call this piece of software a device driver, and any specifics of device interaction are encapsulated within.
The functions of a device driver are to:
- accept the IO requests from the kernel /O subsystem
- control the IO operation.
10.5 Interrupt Handler
The device driver communicates with the device controllers, and then the device, with the help of the interrupt-handling mechanism.
The Interrupt Service Routine (ISR) is executed in order to handle a specific interrupt for an IO operation.
10.6 Streams
a full-duplex communication channel between a user-level process and a device in Unix System V and beyond.
A STREAM consists of:
- The user process interacts with the stream head. User processes communicate with the stream head using either read() and write()
- The device driver interacts with the device end.
- zero or more stream modules between
Each module contains a read queue and a write queue. Message passing is used to communicate between queues. Flow control can be optionally supported. Without flow control, data is passed along as soon as it is ready.
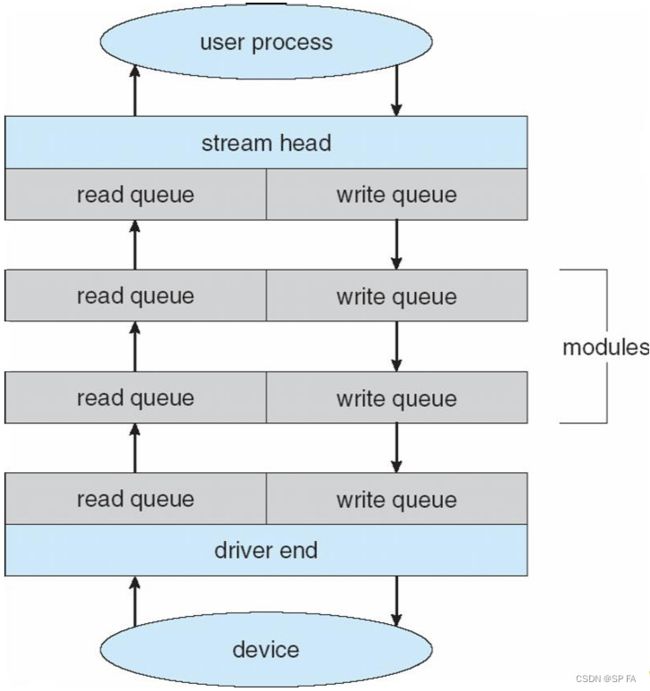
10.7 Improving Performance
- Reduce number of context switches.
- Reduce data copying
- Reduce interrupts by using large transfers, smart controllers, polling
- Use DMA
- Use smarter hardware devices
- Balance CPU, memory, bus, and IO performance for highest throughput
11. Protection & Security
11.1 Protection
Protection refers to a mechanism which controls the access of programs, processes, or users to the resources defined by a computer system.
Goals of Protection
- To prevent the access of unauthorized users
- To ensure that each active programs or processes in the system uses resources only as the stated policy
- To ensure that errant programs cause the minimal amount of damage possible
- To improve reliability by detecting latent errors
11.1.1 Principles of Protection
Principle of least privilege
The principle of least privilege dictates that programs, users, and systems be given just enough privileges to perform their tasks.
Can be static (during life of system, during life of process), or dynamic (changed by process as needed) – domain switching, privilege escalation
11.1.2 Access Matrix
View protection as a matrix (access matrix)
- Rows represent domains (a domain is a set of object and right pairs)
- Columns represent objects (resources)
- Access(i,j) is the set of operations that a process executing in D o m a i n i Domain_i Domaini can invoke on O b j e c t j Object_j Objectj
11.1.3 Access Control Policy
Role-based access control (RBAC) is a security feature for controlling user access to tasks that would normally be restricted to the root user.
RBAC, assigns first the roles and then all the permissions are assigned.
- A user can be assigned multiple roles
- Multiple users can be assigned the same role
- A role can have multiple access rights

11.2 Security
Security is the practice of the confidentiality, integrity, and availability of data
Security Violation Categories
- Breach of confidentiality: Unauthorized reading of data
- Breach of integrity: Unauthorized modification of data
- Breach of availability: Unauthorized destruction of data
- Theft of service: Unauthorized use of resources
- Denial of service (DOS): Prevention of legitimate use
Security Violation Methods
- Masquerading (breach authentication): attacker pretends to be an authorized user to escalate privileges
- Replay attack: attacker delays, replays, or repeats data transmission between the user and the site
- Man-in-the-middle attack: intruder sits in data flow, masquerading as sender to receiver and vice versa
- Hijacking: type of network security attack in which the attacker takes control of computer systems, software programs etc.
Security Measure Levels
To protect a system, we must take security measures at four levels:
- Physical: Data centers, servers, connected terminals
- Human: Avoid social engineering, phishing (involves sending an innocent-looking email), dumpster diving (searching the trash or other locations for passwords), password cracking.
- Operating System: System must protect itself from accidental or purposeful security breaches: runaway processes (DOS denial of service), memory-access violations, stack overflow violations, the launching of programs with excessive privileges, etc.
- Network: protecting the network itself from attack and protecting the local system from attacks coming in through the network (intercepted communications, interruption, DOS, etc).
11.2.1 Cryptography as a Security Tool
Cryptography is a technique to hide the message using encryption.
Encryption
Encryption is a process of encoding a message so that its meaning cannot be easily understood by unauthorized people
Symmetric Encryption
Same key used to encrypt and decrypt.
Data Encryption Standard (DES) was most commonly used symmetric block-encryption algorithm. Triple-DES considered more secure.
Advanced Encryption Standard (AES)
Rivest Cipher RC4 is most common symmetric stream cipher, but known to have vulnerabilities
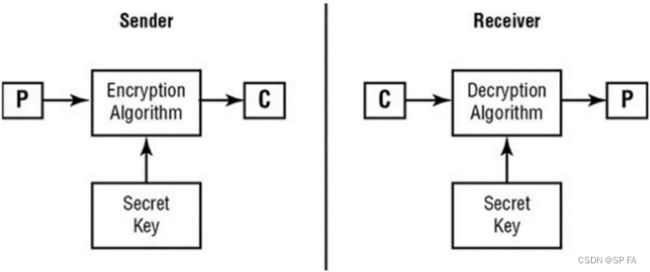
Asymmetric Encryption
Public-key encryption based on each user having two keys:
- public key: published key used to encrypt data
- private key: key known only to individual user used to decrypt data
Most common is RSA (RSA = Ron Rivest, Adi Shamir and Leonard Adleman) based on prime numbers

Digital Certificates
A digital certificate is a mechanism that allows users to verify the authenticity of a key / document.
- Proof of who or what owns a public key
- Public key digitally signed a trusted party
- Trusted party receives proof of identification from entity and certifies that public key belongs to entity
- Certificate authority are trusted party, their public keys included with web browser distributions
Key Distribution Management
Keys in Symmetric encryption is a major problem. One option is to send them Out-of-band, say via paper or a confidential conversation or One-time pad
Keys in Asymmetric encryption, the public keys are not confidential. The key-ring can be easily stored and managed (key-ring is simply a file with keys in it.).
Even asymmetric key distribution needs care, because of man-in-the-middle attack
11.2.2 User Authentication
When a user logs into a computer, the OS needs to determine the identity of the user.
The user authentication has two steps:
- Identification: a unique identifier is specified to the user to authenticate. A Signing function produces an authenticator: a value to be used to authenticate a user.
- Verification of a user: performed against the unique identifier, that is, it confirms the binding between the user and the identifier. a Verification function produces a value of “true” if the authenticator was created from the user, and “false” otherwise.
There are two main authentication algorithms:
- Message Authentication Code (MAC): uses symmetric encryption. a cryptographic checksum is generated from the message using a secret key.
- Digital-signature algorithm: uses asymmetric encryption. A person can encrypt signature related data with the use of a private key. One can give the public key to anyone who needs verification of the signer’s signature.
Common forms of user authentication
- passwords:
- Securing Passwords: modern systems do not store passwords in clear-text form.
- One-time passwords: resist shoulder surfing and other attacks
- Biometrics: involve a physical characteristic of the user. Multifactor authentication is better.
11.2.3 Implementing Security Defenses
The major methods, tools, and techniques that can be used to improve security:
-
Security Policy
-
Vulnerability Assessment: Periodically examine the system to detect vulnerabilities.
- Port scanning
- Check for bad passwords
- Unauthorized programs in system directories
- Incorrect permission bits set
- Program checksums / digital signatures which have changed
- Unexpected or hidden network daemons
- New entries in startup scripts, shutdown scripts or other system scripts or configuration files
- New unauthorized accounts
-
Intrusion Detection
-
Virus Protection
-
Auditing, Accounting, and Logging
12. Virtual Machines & Distributed Systems
12.1 Virtual Machines
Virtualization is technology that allows to create multiple simulated environments or dedicated resources from a single, physical hardware system.
Software called a hypervisor connects directly to that hardware and allows to split a system into separate, distinct, and secure environments known as virtual machines (VMs).
Virtual machine manager (VMM) or hypervisor – creates and runs virtual machines by providing interface that is identical to the host (except in the case of paravirtualization)
Virtual machine implementations involve several components
- Host: the physical hardware equipped with a hypervisor.
- Guest: an operating system
- Single physical machine can run multiple operating systems concurrently, each in its own virtual machine
the hypervisor provides a layer between the hardware (the physical host machine) and the Virtual Machines (guest machines)

Implementation of VMMs
Types of virtual machine manager VMMs:
- Type 0 hypervisors: Hardware-based solutions that provide support for virtual machine creation and management via firmware. No need an embedded host OS to support virtualization, runs in an “Un-Hosted” environment. IBM LPARs and Oracle LDOMs are examples.
- Type 1 hypervisors: Operating-system-like software built, is a layer of software run directly on the system hardware. Including VMware ESX, Joyent SmartOS, and Citrix XenServer Including Microsoft Windows Server with HyperV and RedHat Linux with KVM.
- Type 2 hypervisors: allows users to run multiple operating systems simultaneously on a single platform. Including VMware Workstation and Fusion, Parallels Desktop, and Oracle VirtualBox
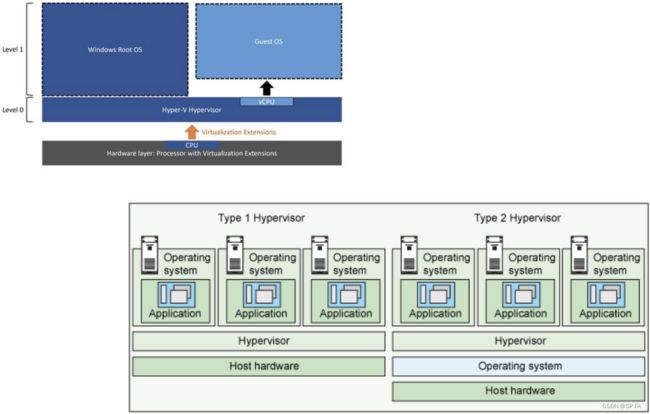
Benefits
-
the ability to share the same hardware yet run several different execution different operating systems concurrently.
-
Host system protected from VMs, VMs protected from each other:
- against virus: less likely to spread
- each virtual machine is almost completely isolated from all other virtual machines
- (Disadvantage of isolation is that it can prevent sharing of resources.)
-
a perfect for operating-system research and development
-
virtualized workstation allows for rapid porting and testing of programs in varying environments
-
Consolidation involves taking two or more separate systems and running them in virtual machines on one system
-
can improve resource utilization and resource management
-
Live migration: move a running VM from one host to another
12.2 Distributed Systems
Distributed system is a loosely-coupled architecture, wherein processors are inter-connected by a communication network. The processors and their respective resources for a specific processor in a distributed system are remote, while its own resources are considered as local.
Processors variously called nodes, computers, machines, hosts.
Reasons for Distributed Systems
- Resource sharing
- Sharing and printing files at remote sites
- Processing information in a distributed database
- Using remote specialized hardware devices
- Computation speedup: load sharing or job migration (are distributed and run concurrently on various nodes on the system)
- Reliability: detect and recover from site failure, function transfer, reintegrate failed site; may utilize an alternative path in the network, in case of any failure
- Communication: exchange information at geographically-distant nodes
- Economy and Incremental growth: a number of cheap processors together provide a highly cost-effective solution for a computation-intensive application. The DS may be increased with the introduction of any new hardware or software resources.
Types of Network-oriented OS
- Network Operating Systems
- Remote logging into the appropriate remote machine (telnet, ssh)
- Remote File Transfer: transferring data from remote machines to local machines, via the File Transfer Protocol (FTP) mechanism.
- Users must establish a session
- Distributed Operating Systems
- Data Migration: transfer data by transferring entire file, or transferring only those portions of the file necessary for the immediate task
- Computation Migration: transfer the computation, rather than the data, across the system
- Process Migration: execute an entire process, or parts of it, at different sites