haproxy+keepalived搭建高可用k8s集群
高可用集群技术细节
高可用集群技术细节如下所示:

- keepalived:配置虚拟ip,检查节点的状态
- haproxy:负载均衡服务【类似于nginx】
- apiserver:
- controller:
- manager:
- scheduler:
高可用集群步骤
我们采用2个master节点,一个node节点来搭建高可用集群(机器资源有限)
| 角色 | IP | 安装步骤 |
| ---------------- | -------------- ------ | ------------------------------------------------------------------------------------------------------------- |
| master1 | 192.168.44.155 | 1.部署keepalived 2.部署haproxy 3.kubeadm初始化操作 4.安装docker和网络插件 |
| master2 | 192.168.44.156 | 1.部署keepalived 2.部署haproxy 3.添加master2到集群 4.安装docker和网络插件 |
| node1 | 192.168.44.157 | 1.加入到集群中 2.安装docker和网络插件 |
| VIP | 192.168.44.100 | |
这里机器配置不够了,只能演示2台master,一般推荐3台master以上
在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统 CentOS7.x-86_x64
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多(测试2g内存会装不上,建议3g内存以上吧)
- 可以访问外网,需要拉取镜像,如果服务器不能上网,需要提前下载镜像并导入节点
- 禁止swap分区
系统环境初始化操作
我们需要在这三个节点上进行操作
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
# 根据规划设置主机名
hostnamectl set-hostname
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.44.100 master.k8s.io k8s-vip
192.168.44.155 master01.k8s.io master1
192.168.44.156 master02.k8s.io master2
192.168.44.157 node01.k8s.io node1
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.ipv4.tcp_tw_recycle = 0
vm.swappiness = 0 #禁止使用swap空间,只有当系统oom时才允许使用它
vm.overcommit_memory = 1 #不检查物理内存是否够用
vm.panic_on_oom = 0 #开启oom
fs.inotify.max_user_instances = 8192
fs.inotify.max_user_watches = 1048576
fs.file-max = 52706963
fs.nr_open = 52706963
net.ipv6.conf.all.disable_ipv6 = 1
net.netfilter.nf_conntrack_max = 2310720
EOF
sysctl --system # 生效
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
#安装ipvs软件
yum install ipvsadm ipset sysstat conntrack libseccomp -y
#开启ipvs模块
cat > /etc/sysconfig/modules/ipvs.modules <
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules ;bash /etc/sysconfig/modules/ipvs.modules ;lsmod | grep -e ip_vs -e nf_conntrack
部署keepAlived+haproxy
下面我们需要在所有的master节点【master1和master2】上部署keepAlived+haproxy
# 安装keepalived
yum install -y keepalived haproxy配置master节点
添加master1的配置
cat > /etc/keepalived/keepalived.conf <添加master2的配置
cat > /etc/keepalived/keepalived.conf <启动和检查
在两台master节点都执行
systemctl start keepalived.service;systemctl enable keepalived.service;systemctl status keepalived.service
启动后查看master的网卡信息ip a
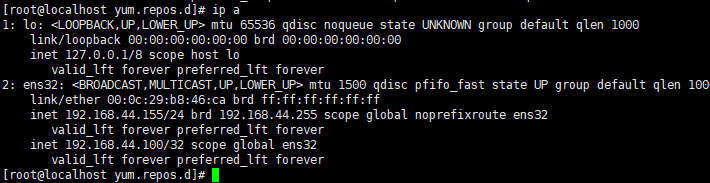
配置haproxy
haproxy主要做负载的作用,将我们的请求分担到不同的node节点上
两台master节点的配置均相同,配置中声明了后端代理的两个master节点服务器,指定了haproxy运行的端口为16443等,因此16443端口为集群的入口
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server master01.k8s.io 192.168.44.155:6443 check
server master02.k8s.io 192.168.44.156:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
EOF
# 启动并开机自启 haproxy
systemctl start haproxy ;systemctl enable haproxy
启动后,我们查看对应的端口是否包含 16443
netstat -tunlp | grep haproxy

安装Docker、Kubeadm、kubectl
所有节点安装Docker/kubeadm/kubelet ,Kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker
安装Docker
首先拉一下Docker的阿里yum源
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo然后yum方式安装docker
# yum安装
yum -y install docker-ce-18.06.1.ce-3.el7
# 查看docker版本
docker --version
# 启动docker
systemctl enable docker && systemctl start docker配置docker的镜像源
cat >> /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF然后重启docker
systemctl restart docker
安装kubeadm,kubelet和kubectl
然后我们还需要配置一下yum的k8s软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
由于版本更新频繁,这里指定版本号部署:
# 安装kubelet、kubeadm、kubectl,同时指定版本
yum install -y kubelet-1.16.3 kubeadm-1.16.3 kubectl-1.16.3
# 设置开机启动
systemctl enable kubelet部署Kubernetes Master【master节点】
创建kubeadm配置文件
在具有vip的master上进行初始化操作,这里为master1
# 创建文件夹
mkdir /usr/local/kubernetes/manifests -p
# 到manifests目录
cd /usr/local/kubernetes/manifests/
# 导出默认yaml文件
kubeadm config print init-defaults > kubeadm-config.yaml
vi kubeadm-config.yamlyaml内容如下所示:
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.44.155 #本机的ip地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.44.100:16443" #连接apiserver的地址通过haproxy代理的
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers #仓库替换国内的
kind: ClusterConfiguration
kubernetesVersion: v1.16.0 #集群的版本
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 #pod的ip分配地址段
serviceSubnet: 10.1.0.0/16 #svc的ip地址段
scheduler: {}
然后我们在 master1 节点执行
kubeadm init --config kubeadm-config.yaml这里出现报错: cannot execute 'kubelet --version': fork/exec /usr/bin/kubelet: cannot allocate memory
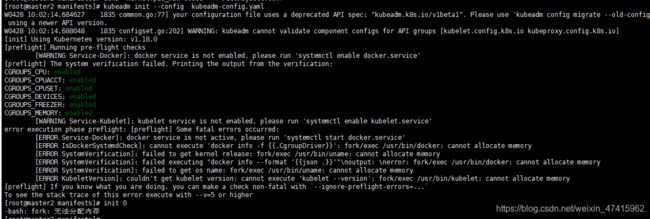
内存不足导致,随时把虚拟机加到了3g内存
初始化成功就出现如图下:

按照提示配置环境变量,使用kubectl工具
# 执行下方命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 查看节点
kubectl get nodes
# 查看pod
kubectl get pods -n kube-system按照提示保存以下内容,一会要使用:
kubeadm join 192.168.44.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:518f0ab771cbf896972ef146177eb1fc8fbbb9605c87bd6f865d99a107e6d53a \
--control-plane
--control-plane : 只有在添加master节点的时候才有
安装集群网络
从官方地址获取到flannel的yaml,在master1上执行
# 创建文件夹
mkdir flannel
cd flannel
# 下载yaml文件
wget -c https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml安装flannel网络
kubectl apply -f kube-flannel.yml 检查
kubectl get pod -Amaster2节点加入集群
复制密钥及相关文件
从master1复制密钥及相关文件到master2
#在master2创建目录
# mkdir -p /etc/kubernetes/pki/etcd
#把master1相关文件scp过去
# scp /etc/kubernetes/admin.conf [email protected]:/etc/kubernetes
# scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} [email protected]:/etc/kubernetes/pki
# scp /etc/kubernetes/pki/etcd/ca.* [email protected]:/etc/kubernetes/pki/etcdmaster2加入集群
执行在master2上init后输出的join命令,需要带上参数--control-plane表示把master控制节点加入集群
kubeadm join 192.168.44.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:518f0ab771cbf896972ef146177eb1fc8fbbb9605c87bd6f865d99a107e6d53a \
--control-plane检查状态
kubectl get node
kubectl get pod -A加入Kubernetes Node
在node1上执行
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
kubeadm join 192.168.44.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:518f0ab771cbf896972ef146177eb1fc8fbbb9605c87bd6f865d99a107e6d53a在master删除node节点,然后在node节点上重置kubeadm reset后在重新加入集群(如果加入有错,建议排查错误了重新加入,不然有坑)
kubectl drain node1 --delete-local-data --force --ignore-daemonsets
kubectl delete node node1加入成功后:

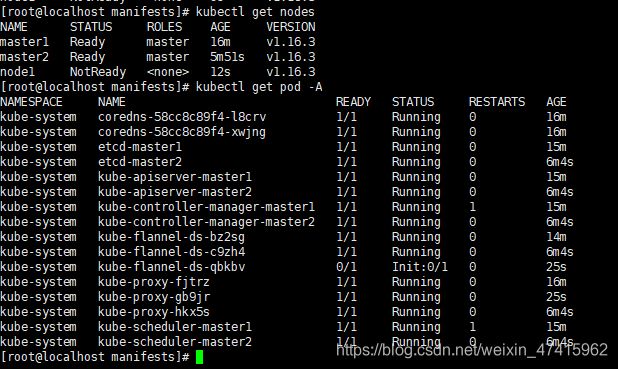
由于集群网络flannel是DaemonSet,新加节点会自动加入网络,不需要额外安装。等待网络init后检查状态
kubectl get node
kubectl get pod -A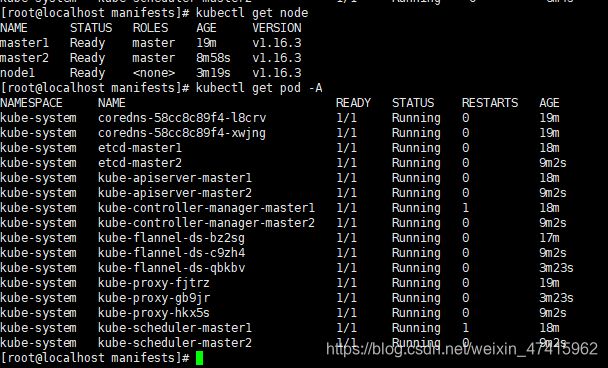
测试kubernetes集群
在Kubernetes集群中创建一个pod,验证是否正常运行:
# 创建nginx deployment
kubectl create deployment nginx --image=nginx
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看状态
kubectl get pod,svc然后我们通过任何一个节点,都能够访问我们的nginx页面
总结:etcd节点必须是单数部署(1.3.5),如果2台挂1台etcd和apiserver就不停重启。后来在github上找到了脚本自动化安装集群,省事点就脚本装贼舒服:https://github.com/TimeBye/kubeadm-ha