TStor CSP文件存储在大模型训练中的实践
业务背景
大模型作为人工智能领域的重要发展趋势,正在逐渐改变人们的生活和工作方式。随着近年来大模型领域技术的突破,各类语言模型、图像模型、视频模型快速演进,国内外市场也不断涌现出优秀的大模型研究及商业化平台,预期通过对模型效果的持续优化和产品方案层面的持续包装,共同推动推动国内各行各业的产业升级。
在大模型技术的快速演进中也暴露了若干挑战。比如聚焦在大模型平台的存储领域,如何管理海量的大模型训练物料、如何提升存储系统的性能、如何做好数据安全和信息合规等等,这些问题已成为领域内的火热话题,也成为了国内大模型工程领域能否更上一层楼的关键因素。
本文围绕了大模型训练的存储场景,分享TStor CSP作为腾讯内外部大模型训练场景的存储底座的心得和最佳实践。
TStor CSP大模型存储解决方案架构
在大模型预训练阶段,工程平台会围绕海量语料从零开始进行无监督的训练,通过迭代N个epoch从而得到一个基座大模型;业务通过对基座模型进行有监督的微调得到满足业务场景的专业模型。在这个过程,TStor CSP作为大模型工程平台的存储底座,支持了语料的存储和读取、CheckPoint的写入和清除等操作环节,并提供百GB级别的读写带宽和高可用性。
下图描述了训练过程中算力节点和存储集群的主要的交互路径。
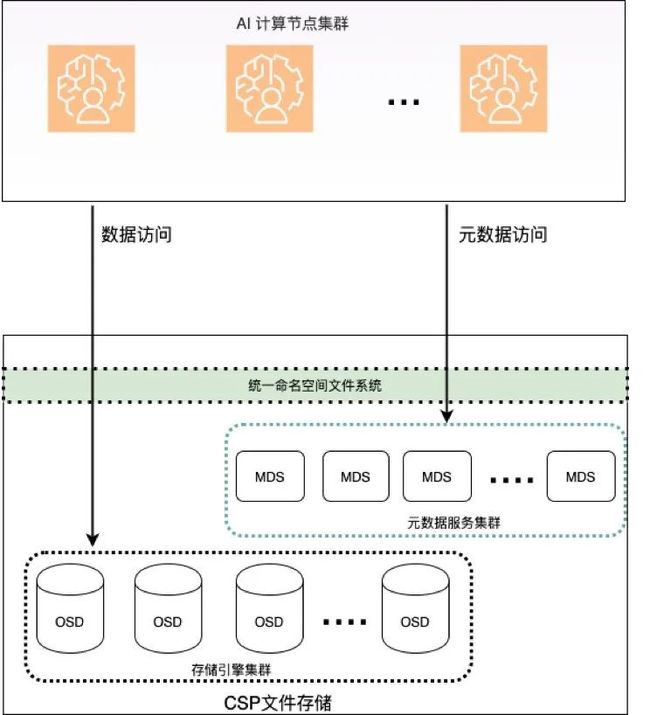
【图1. 训练架构】
在整个训练过程中,我们从如下几个方面进一步剖析TStor CSP的实现方案:
一、高速读写CheckPoint
对于大模型分布式训练任务来说,模型CheckPoint的读写是训练过程中的关键路径。在训练过程中,模型每完成一个 epoch迭代就有需要对CheckPoint进行保存。在这个CheckPoint保存过程中,GPU算力侧需要停机等待。这对于CheckPoint是否能快速写入存储系统提出了很高的挑战。换而言之,如果文件写入慢了,GPU停机等待时间就会拉长,平台整体工作的效率就会被拉低。
而在TStor CSP所支持的案例中,对于175B参数的大模型,其CheckPoint文件总大小为2TB,TStor CSP文件存储可以在30秒完成CheckPoint文件的写入,顺利地满足了业务的需求。
TStor CSP是如何抗住如此高的性能尖峰呢?这得益于多年来CSP文件存储在存储引擎设计和性能的优化。
分布式存储
存储引擎OSD以分片的方式存储数据,将数据块存储在多个OSD节点上,当业务读写一个文件时,读写请求会分发到多个存储节点并行处理,大大提高了系统的响应速度和处理能力。单个节点的网络带宽和磁盘性能不再成为瓶颈。
负载均衡
存储引擎采用受控复制的分布式hash算法,数据分片的存储位置是计算出来而不是通过去查询元数据服务器;同时也解决了常规hash算法在添加删除存储节点时带来的数据迁移问题。该算法能有效地将数据分片均衡映射到不同的存储节点,从而实现数据的均衡分布;避免节点过载和数据的热点问题。提高系统的性能和吞吐量。
直接管理存储设备
大模型存储设备的磁盘介质都是高容量和高性能的NVMe盘,我们在创建存储池时存储引擎直接管理磁盘,绕过本地文件系统,不再需要把数据分片转化为本地文件系统能够识别的文件。从而使得IO路径大大缩短,提高了存储引擎的读写性能。当集群处于高水位,集群的读写性能并不会衰减,而使用本地磁盘文件系统管理磁盘时,常常会遇到性能衰减问题。
快速数据访问
充分利用大模型存储设备的内存大的优势,通过合理分配文件数据和文件元数据内存占用实现数据的读取和写入加速操作。进一步提高数据访问性能。
二、高可用和高可靠
可用性是存储系统亘古不变的命脉,如果系统稳定性不足,不仅会影响系统连续性,还会造成数据丢失带来的业务风险。在大模型系统中同样如此,存储系统的IO中断或数据丢失会直接影响模型训练效果,严重者会导致近几个epoch任务需要推倒重做,大大影响了业务效率。
在TStor CSP存储方案提供多副本和EC纠删码的数据存储策略,同时支持配置不同的故障域级别(支持节点,机柜,机房等级别的故障域),屏蔽服务器故障、机架级别故障等对存储可用性的影响,保障存储服务高可用。同时,同时提供动态调整数据副本恢复速度的能力,保证业务在读写高峰时不受影响。并且,TStor CSP集群中的各组件也都实现了高可靠,整体系统不存在单点问题。
在耗时几个月的大模型训练过程中,TStor CSP未出现一例故障,严格保障了系统可用性和数据可靠性。
TStor CSP文件系统除了能保证在扩容和故障恢复时业务高可用,同时也提供了很多系统内部检测和诊断的机制,通过及时检测潜在故障并上报告警,通知运维人员及时处理潜在风险。
网络丢包检测
当网络丢包不严重时,集群仍然可用;但网络丢包会导致数据传输的延迟和重传,降低集群性能。丢包严重时,会造成集群震荡影处于亚健康状态。TStor CSP会周期性的检测集群中节点之间的网络丢包情况,及时处理。

【图2. 丢包告警】
慢盘检测
慢盘指的是在存储节点中某些磁盘介质性能较低,读写速度慢。慢盘会对集群造成性能下降,因为慢盘的读写速度慢,它会成为数据读写的瓶颈,导致整个集群的吞吐量和响应时间变差。TStor CSP提供了慢盘检测功能。

【图3. 慢盘告警】
三、强安全保障
大模型的CheckPoint和训练产出结果是业务侧的重要资产,为保证业务数据模型的安全和不同业务目录隔离,TStor CSP提供一系列存储安全相关能力:
● 基于路径的IP白名单管理
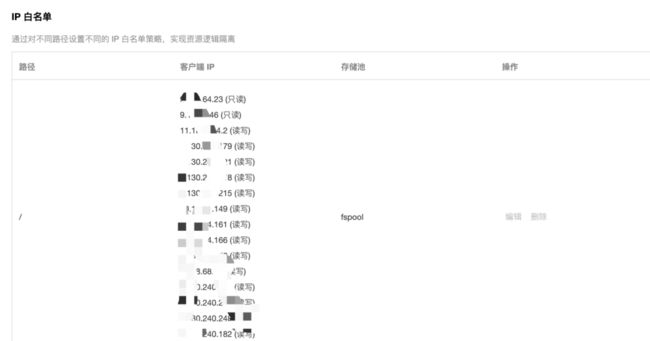
【图4. IP白名单】
业务管理员可以在TStor CSP控制台上限制只有特定的IP地址或者IP地址范围访问某个业务路径。
基于路径的keyring管理业务管理员可以在TStor CSP控制台上为某个路径创建出一个用户,TStor CSP为该用户生成一个keyring. 用户就可以凭借该keyring挂载授权的路径。
● 审计日志
通过开启审计日志并上报到智研日志汇,业务可分析日常训练中的异常挂载,客户端对文件系统的修改操作(创建,删除,遍历目录等)。同时为大模型训练场景提供了全量客户端列表保障客户端挂载实时在监控范围内。

【图5. 客户端删除文件日志】
四、海量弹性的容量空间
为了支撑大模型训练的需要,文件存储通常提供PB级别的可容容量来支撑并发的训练任务以及保存历史CheckPoint的需求。TStor CSP提供横向扩展的能力,在业务无感知情况下通过渐进调权的方式进行扩容,添加存储节点动态扩容。
以近期我们遇到的若干大模型客户为例,选用的存储机型的磁盘规格是7.68T*24 大容量磁盘,当集群水位比较高扩容时,涉及大量的数据需要向新节点迁移,对业务有一定影响。TStor CSP产品在最初设计时就考虑了扩容对集群的影响,通过异步渐进调权的方式增加扩容节点磁盘的权重,数据迁移在受控的方式下进行避免对业务造成影响。同时允许配置高峰时段,普通时段高速迁移,高峰期自动减速。
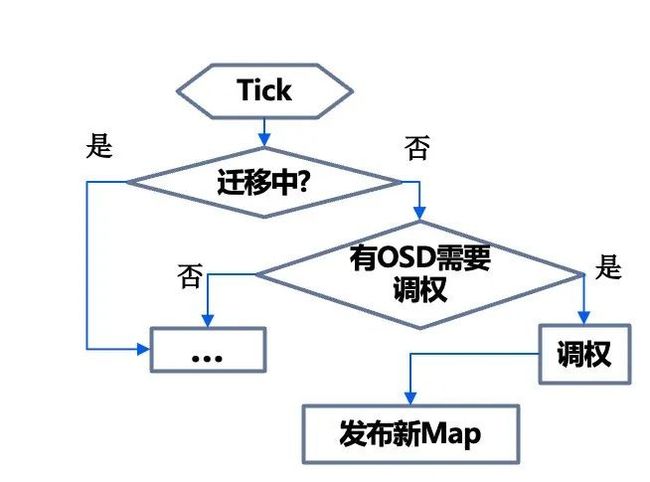
【图6. 集群渐进式扩容流程】
五、可运维性
任何技术都不是万能的,只有设置合理的约束,并搭配便捷的运维管控能力,才能更好地支持业务。TStor CSP在支撑大模型训练场景中不断优化自身的运维管控能力,顺利支持了多套大模型业务的复杂运维需求。
图形化运维
集群创建,扩容以及后期的运维都可以通过在CSP控制台操作完成。
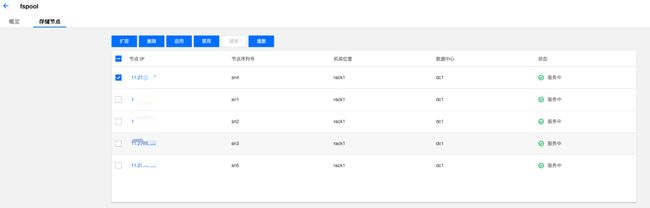
【图7. 存储节点管理】
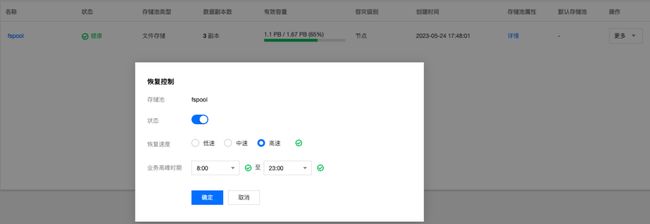
【图8. 数据恢复速度控制】
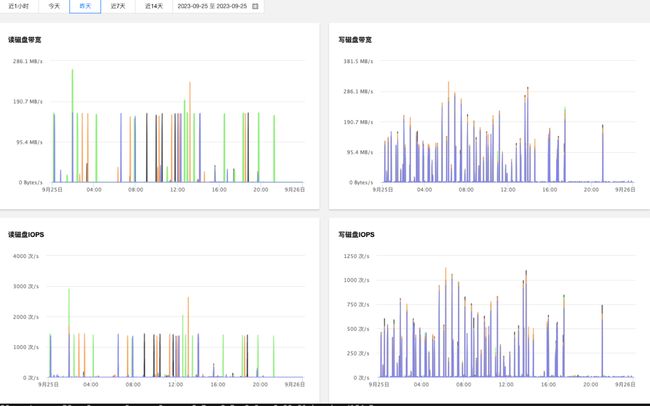
【图9. 存储节点磁盘性能数据】
-
告警管理
通过消息网关把集群容量数据和故障告警实时推送到微信和企业微信,保证了故障第一时间呈现出来及时修复;避免故障累积,造成集群不可用。
大模型预训练业务的使用量和配额通过企业微信实时地推送到业务负责人,避免业务因超过配额写入失败,造成训练中断。
未来规划
TStor CSP企业服务已上线多年,目前市场上多个训练平台都已接入TStor CSP 文件存储。
TStor CSP也会在未来持续演进,并在如下方面进行规划和布局:
性能优化:支持海量小文件,超大目录等方面进行优化,提高元数据操作的性能。
成本优化:支持高密,低成本大容量磁盘方面进行优化,降低客户使用的总TCO。
运维优化:更加细致化的状态监控,告警,故障自动修复方面进行迭代,优化运维管理界面的交互体验,降低客户使用的复杂度。
希望TStor CSP可以帮助您进行更好的数据存储和管理,完成存储系统的升级。