AttributeError:module ‘torch.nn.parameter‘ has no attribute ‘UninitializedParameter‘
解决在使用torch-geometric构建图神经网络出现module ‘torch.nn.parameter’ has no attribute 'UninitializedParameter’错误。如下图
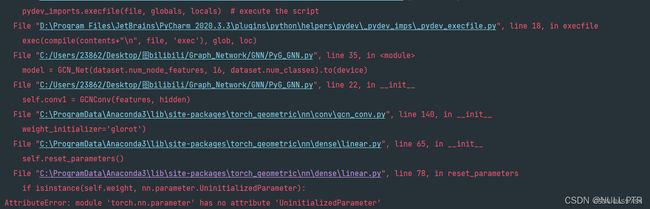
基本版本情况
torch 1.6.0
cuda 10.1
python 3.7.4
torch-geometric 2.0.3
torch-geometric依赖包版本
torch-scatter 2.0.5
torch-sparse 0.6.7
错误原因
可以看到报错的地方在于torch,所以这是版本不对应的问题。
在torch 1.6.0版本中 ‘torch.nn.parameter’ 没有’UninitializedParameter’这个属性,查阅了相关文档发现这个属性在1.8.0加入的。因此将torch升级到>=1.8.0版本就可以解决这个问题?(理论如此,我没尝试)下面是我的解决方案。
解决方法
这个方法其实是由torch-geometric官网提供的方法,官网有很多人提到此问题,所以在两周前,他们给出了解决方法[点击此处查看],看下图源代码也能发现他们做了改动(https://github.com/pyg-team/pytorch_geometric/pull/4086/files/b57dc8ec75f6ce8dd1ce399c2a0c3fdab672b3a8…43702e47c89cf0194dfadcc66de2e5cedf796ce1)
简单来说就是将torch_geometric\nn\dense\linear.py这个文件的代码稍微做了改动,不会用到 ‘torch.nn.parameter’ 的’UninitializedParameter’属性了,因此修改后就不会报错了,如下图
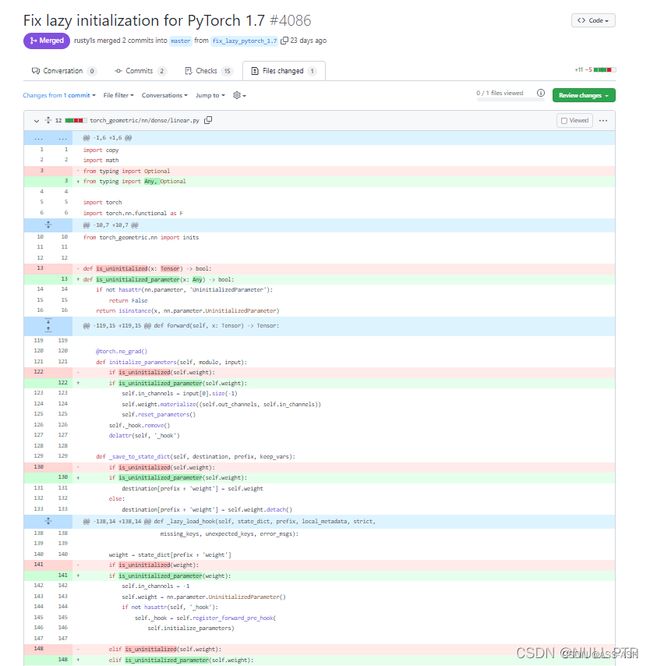
改动的地方如我上图框的部分,“-”所指的那行就代表你删除它,“+”所指的那行你就添加上即可。然后你就把这两处改了就解决问题啦。(当然,直接更新最新版本应该也可以解决问题)
Liner.py文件
下面是我修改后整个文件
import copy
import math
from typing import Optional
from typing import Any, Optional
import torch
import torch.nn.functional as F
from torch import Tensor, nn
from torch.nn.parameter import Parameter
from torch_geometric.nn import inits
def is_uninitialized_parameter(x: Any) -> bool:
if not hasattr(nn.parameter, 'UninitializedParameter'):
return False
return isinstance(x, nn.parameter.UninitializedParameter)
class Linear(torch.nn.Module):
r"""Applies a linear tranformation to the incoming data
.. math::
\mathbf{x}^{\prime} = \mathbf{x} \mathbf{W}^{\top} + \mathbf{b}
similar to :class:`torch.nn.Linear`.
It supports lazy initialization and customizable weight and bias
initialization.
Args:
in_channels (int): Size of each input sample. Will be initialized
lazily in case it is given as :obj:`-1`.
out_channels (int): Size of each output sample.
bias (bool, optional): If set to :obj:`False`, the layer will not learn
an additive bias. (default: :obj:`True`)
weight_initializer (str, optional): The initializer for the weight
matrix (:obj:`"glorot"`, :obj:`"uniform"`, :obj:`"kaiming_uniform"`
or :obj:`None`).
If set to :obj:`None`, will match default weight initialization of
:class:`torch.nn.Linear`. (default: :obj:`None`)
bias_initializer (str, optional): The initializer for the bias vector
(:obj:`"zeros"` or :obj:`None`).
If set to :obj:`None`, will match default bias initialization of
:class:`torch.nn.Linear`. (default: :obj:`None`)
Shapes:
- **input:** features :math:`(*, F_{in})`
- **output:** features :math:`(*, F_{out})`
"""
def __init__(self, in_channels: int, out_channels: int, bias: bool = True,
weight_initializer: Optional[str] = None,
bias_initializer: Optional[str] = None):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.weight_initializer = weight_initializer
self.bias_initializer = bias_initializer
if in_channels > 0:
self.weight = Parameter(torch.Tensor(out_channels, in_channels))
else:
self.weight = nn.parameter.UninitializedParameter()
self._hook = self.register_forward_pre_hook(
self.initialize_parameters)
if bias:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self._load_hook = self._register_load_state_dict_pre_hook(
self._lazy_load_hook)
self.reset_parameters()
def __deepcopy__(self, memo):
out = Linear(self.in_channels, self.out_channels, self.bias
is not None, self.weight_initializer,
self.bias_initializer)
if self.in_channels > 0:
out.weight = copy.deepcopy(self.weight, memo)
if self.bias is not None:
out.bias = copy.deepcopy(self.bias, memo)
return out
def reset_parameters(self):
if self.in_channels <= 0:
pass
elif self.weight_initializer == 'glorot':
inits.glorot(self.weight)
elif self.weight_initializer == 'uniform':
bound = 1.0 / math.sqrt(self.weight.size(-1))
torch.nn.init.uniform_(self.weight.data, -bound, bound)
elif self.weight_initializer == 'kaiming_uniform':
inits.kaiming_uniform(self.weight, fan=self.in_channels,
a=math.sqrt(5))
elif self.weight_initializer is None:
inits.kaiming_uniform(self.weight, fan=self.in_channels,
a=math.sqrt(5))
else:
raise RuntimeError(f"Linear layer weight initializer "
f"'{self.weight_initializer}' is not supported")
if self.bias is None or self.in_channels <= 0:
pass
elif self.bias_initializer == 'zeros':
inits.zeros(self.bias)
elif self.bias_initializer is None:
inits.uniform(self.in_channels, self.bias)
else:
raise RuntimeError(f"Linear layer bias initializer "
f"'{self.bias_initializer}' is not supported")
def forward(self, x: Tensor) -> Tensor:
r"""
Args:
x (Tensor): The features.
"""
return F.linear(x, self.weight, self.bias)
@torch.no_grad()
def initialize_parameters(self, module, input):
if is_uninitialized_parameter(self.weight):
self.in_channels = input[0].size(-1)
self.weight.materialize((self.out_channels, self.in_channels))
self.reset_parameters()
self._hook.remove()
delattr(self, '_hook')
def _save_to_state_dict(self, destination, prefix, keep_vars):
if is_uninitialized_parameter(self.weight):
destination[prefix + 'weight'] = self.weight
else:
destination[prefix + 'weight'] = self.weight.detach()
if self.bias is not None:
destination[prefix + 'bias'] = self.bias.detach()
def _lazy_load_hook(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
weight = state_dict[prefix + 'weight']
if is_uninitialized_parameter(weight):
self.in_channels = -1
self.weight = nn.parameter.UninitializedParameter()
if not hasattr(self, '_hook'):
self._hook = self.register_forward_pre_hook(
self.initialize_parameters)
elif is_uninitialized_parameter(self.weight):
self.in_channels = weight.size(-1)
self.weight.materialize((self.out_channels, self.in_channels))
if hasattr(self, '_hook'):
self._hook.remove()
delattr(self, '_hook')
def __repr__(self) -> str:
return (f'{self.__class__.__name__}({self.in_channels}, '
f'{self.out_channels}, bias={self.bias is not None})')
class HeteroLinear(torch.nn.Module):
r"""Applies separate linear tranformations to the incoming data according
to types
.. math::
\mathbf{x}^{\prime}_{\kappa} = \mathbf{x}_{\kappa}
\mathbf{W}^{\top}_{\kappa} + \mathbf{b}_{\kappa}
for type :math:`\kappa`.
It supports lazy initialization and customizable weight and bias
initialization.
Args:
in_channels (int): Size of each input sample. Will be initialized
lazily in case it is given as :obj:`-1`.
out_channels (int): Size of each output sample.
num_types (int): The number of types.
**kwargs (optional): Additional arguments of
:class:`torch_geometric.nn.Linear`.
Shapes:
- **input:**
features :math:`(*, F_{in})`,
type vector :math:`(*)`
- **output:** features :math:`(*, F_{out})`
"""
def __init__(self, in_channels: int, out_channels: int, num_types: int,
**kwargs):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.lins = torch.nn.ModuleList([
Linear(in_channels, out_channels, **kwargs)
for _ in range(num_types)
])
self.reset_parameters()
def reset_parameters(self):
for lin in self.lins:
lin.reset_parameters()
def forward(self, x: Tensor, type_vec: Tensor) -> Tensor:
r"""
Args:
x (Tensor): The input features.
type_vec (LongTensor): A vector that maps each entry to a type.
"""
out = x.new_empty(x.size(0), self.out_channels)
for i, lin in enumerate(self.lins):
mask = type_vec == i
out[mask] = lin(x[mask])
return out
def __repr__(self) -> str:
return (f'{self.__class__.__name__}({self.in_channels}, '
f'{self.out_channels}, bias={self.lins[0].bias is not None})')