手写一个PrattParser基本运算解析器1: 编译原理概述

点击查看 基于Swift的PrattParser项目
编译原理概述
编译原理是我们每一个程序猿必须要了解的技能, 编译原理实际上并没有啥高深的技术, 我们如果在做业务开发, 也很少会用到编译开发的知识, 但是编译原理又是我们必备的基础知识之一. 所以我们需要对编译原理的内容有一个大概的了解.
其实我自己写这一个系列的起因, 一个是我恶补编译原理的相关内容, 另外一个就是看到了B站熊爷的技术去魅篇- 手写一个普拉特解析器, 感觉这个对我辅助理解遍历原理的一个很好的方案. 所以才会有这一个系列的博客.
首先就是编译过程中的基本组成结构单元. 如下图所示.
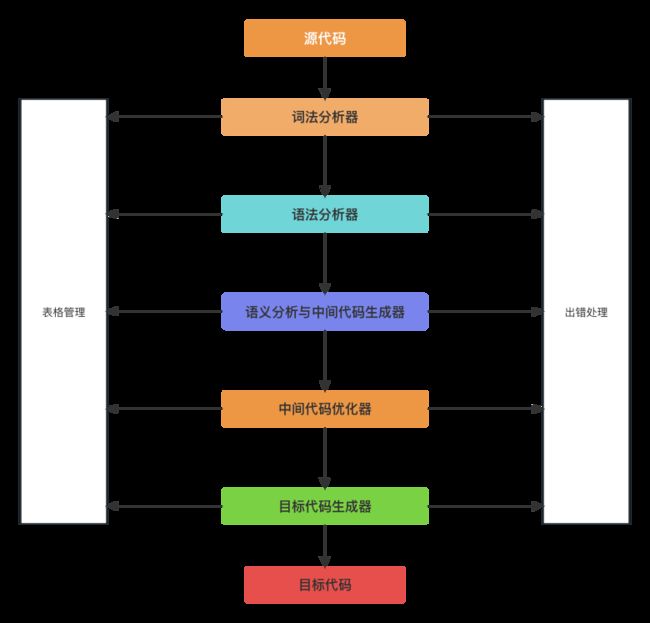
基本组成结构主要有 词法分析, 语法分析, 语义分析, 中间代码生成, 代码优化, 目标代码生成, 符号表管理, 错误管理.
下面, 我们就以下运算代码(以 Clang 作为编译器为例)为示例, 写一些伪过程来了解整个编译过程.
1 + 3 * 2
-
词法分析(Lexical Analysis)
词法分析主要是将源代码分解为词法单元(tokens),如关键字、标识符、运算符等。词法分析器负责读取字符流,根据语法规则识别和分类词法单元。
使用下面的命令(需要安装Mac xcode, 以提供
Clang编译前端环境)clang -Xclang -dump-tokens helloworld.c上面的运算代码会被划分成如下的词法单元. (会报错, 但不影响)

numeric_constant '1' [StartOfLine] Loc=plus '+' [LeadingSpace] Loc=numeric_constant '3' [LeadingSpace] Loc=star '*' [LeadingSpace] Loc=numeric_constant '2' [LeadingSpace] Loc=eof '' Loc=Loc代表着词法单元在源文件中的位置, 所以实际上1 + 3 * 2被划分成以下的词法单元.
-
语法分析(Syntax Analysis)
将词法单元流转换为抽象语法树(Abstract Syntax Tree,AST)。语法分析器负责检查和验证语法结构,根据语法规则构建语法树,以便后续的语义分析和代码生成。
上一个步骤我们已经把源文件划分成了一个个的词法单元, 但是执行顺序呢? 因为在数学运算过程中 乘法 要比 加法 优先级高, 所以我们在
1 + 3 * 2的运算过程中. 需要先计算3 * 2而不是1 + 3, 我们由于有数学基础, 一眼就知道应该先计算谁, 但程序是如何知道应该先计算谁呢? 所以我们需要构建AST语法树, 为什么要构建AST语法树, 我们实际操作一下你就明白了.注: 由于
1 + 3 * 2构建语法树不是很直观, 我们把helloworld.c中的内容改为int a = 1 + 3 * 2;使用下面的命令来构建AST语法树.
clang -Xclang -ast-dump -fsyntax-only helloworld.c抛去一些别的构建树节点, 我们会发现如下的结构.

`-VarDecl 0x7fb69188e200上面看着很杂乱, 我们稍微改造一下, 再看一下, 整体如下图所示.
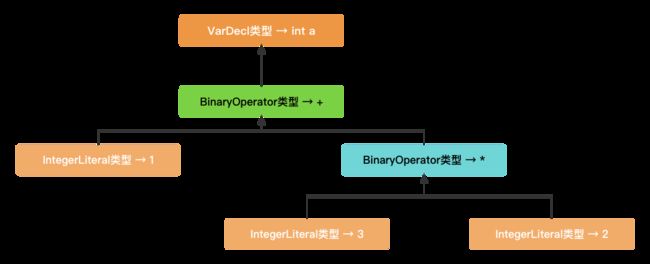
通过上图, 我们就知道AST语法树实际上是类似于二叉树的结构. 我们可以通过生成的AST语法树知道, 如果想要执行
图中的加法运算, 就必须先执行图中的乘法运算, 这也就是为什么计算机能通过AST语法树知道操作的优先级.
-
语义分析(Semantic Analysis)
对语法树进行语义检查,包括类型检查、作用域检查等。语义分析器负责分析语句和表达式的含义和关联,确保程序在运行时不会出现语义错误。
在iOS开发过程中, 语义分析也叫做静态分析. 计算机做的操作也是包括
类型检查、实现检查(某个类是否存在某个方法)、变量使用,还会有一些复杂的检查.例如在 Objective-C 中,给某一个对象发送消息(调用某个方法),检查这个对象的类是否声明这个方法(但并不会去检查这个方法是否实现,这个错误是在运行时进行检查的),如果有什么错误就会进行提示。
-
中间代码生成(Intermediate Code Generation)
将语法树转换为中间表示形式,如三地址码、虚拟指令等。中间代码生成器负责将高级语言的语法结构转换成较低级的表示形式,以便后续的优化和目标代码生成。
在Clang编译前端编译代码过程中, 中间代码的形式为 LLVM IR的形式输出的.
我们使用如下终端指令, 来生成
LLVM IR形式的中间代码.clang -S -emit-llvm helloworld.c -o helloworld.ll生成的中间代码如下所示.
; ModuleID = 'helloworld.c' source_filename = "helloworld.c" target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-apple-macosx13.0.0" @a = global i32 7, align 4 !llvm.module.flags = !{!0, !1, !2, !3, !4} !llvm.ident = !{!5} !0 = !{i32 2, !"SDK Version", [2 x i32] [i32 13, i32 3]} !1 = !{i32 1, !"wchar_size", i32 4} !2 = !{i32 7, !"PIC Level", i32 2} !3 = !{i32 7, !"uwtable", i32 2} !4 = !{i32 7, !"frame-pointer", i32 2} !5 = !{!"Apple clang version 14.0.3 (clang-1403.0.22.14.1)"}我们发现全局变量
int a的结果已经被计算出来了, 如下所示.@a = global i32 7, align 4
-
代码优化(Code Optimization)
对中间代码进行优化,以提高程序的性能和效率。代码优化器负责分析和优化中间代码,如常量折叠、循环展开、函数内联等优化技术,以减少执行时间和内存占用。
我们可以通过 -O 参数来优化生成的中间代码.
clang -O3 -S -emit-llvm helloworld.c -o helloworld.ll这时候, 我们会得到如下的中间代码.
; ModuleID = 'helloworld.c' source_filename = "helloworld.c" target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-apple-macosx13.0.0" @a = local_unnamed_addr global i32 7, align 4 !llvm.module.flags = !{!0, !1, !2, !3, !4} !llvm.ident = !{!5} !0 = !{i32 2, !"SDK Version", [2 x i32] [i32 13, i32 3]} !1 = !{i32 1, !"wchar_size", i32 4} !2 = !{i32 7, !"PIC Level", i32 2} !3 = !{i32 7, !"uwtable", i32 2} !4 = !{i32 7, !"frame-pointer", i32 2} !5 = !{!"Apple clang version 14.0.3 (clang-1403.0.22.14.1)"}那么
-O3是什么含义呢? 下面, 我整理了 Clang 遍历过程中所有的优化参数的具体定义.-
优化级别 O0 :这是最低级别的优化,默认情况下会开启。在这个级别下,编译器将进行最少的优化,以保持代码的简单性和可读性。
-
优化级别 O1 :这个级别会应用一些轻量级的优化,以提高代码的执行速度和空间效率。编译时间通常较短,但优化效果有限。
-
优化级别 O2 :这是默认的优化级别。它会开启更多的优化选项,包括内联函数、循环展开、变量替代等,以提高代码的执行速度。编译时间可能会比 O1 长一些。
-
优化级别 O3 :这个级别会比 O2 应用更多的优化,但可能会导致编译时间显著增加。它会更加注重代码的性能优化,可能会牺牲一些可读性和可维护性。
-
优化级别 Os :这个级别的优化旨在减小生成的可执行文件的大小,而不是提高执行速度。它可以通过减小代码的体积来节省内存和存储空间。
-
优化级别 Oz :这是一个综合了优化级别
O2和优化级别Os的级别。它会尽量减小代码的体积,并使用更多的性能优化。
同时, 在 Xcode 编译项目工程时, 我们也是可以通过
Build Settings→Optimization Level调整中间代码的优化级别.
上述步骤就是编译前端做的工作, 下面来说一下编译后端都做了哪些工作.
-
-
目标代码生成(Code Generation)
将优化后的中间代码转换为目标机器代码(可执行代码)。代码生成器负责将中间代码转换为目标机器的指令序列,包括寄存器分配、指令选择和指令调度等。
对于iOS来说, 我们主要根据不同架构的CPU转换成汇编代码, 然后再生成对应的可执行文件. 这样CPU就可以执行了.
生成汇编代码, 我们主要利用到以下指令
clang -S -o - helloworld.c | open -f这时候, 汇编代码生成结果如下所示.
.section __TEXT,__text,regular,pure_instructions .build_version macos, 13, 0 sdk_version 13, 3 .section __DATA,__data .globl _a ## @a .p2align 2 _a: .long 7 ## 0x7 .subsections_via_symbols
-
可执行文件的生成(Create Mach-O File)
这一个步骤应该算在
目标代码生成的一部分, 在生成目标平台的机器代码后,Clang还需要进行链接操作,将生成的机器代码与所需的库文件和其他依赖项进行链接,以生成最终的Mach-O可执行文件。注: 由于
helloworld.c中的内容为int a = 1 + 3 * 2;, 并不能执行, 所以我们要在helloworld.c写一个完整的C语言main函数. 如下所示.#includeint main(int argc, char *argv[]) { printf("Hello World!\n"); return 0; } 我们可以通过下面终端指令生成
Mach-O文件.clang helloworld.c -o helloworld.out然后, 我们可以在终端使用
./helloworld.out正常调用Mach-O文件了.shenjingsaodong@Mac Desktop % ./helloworld.outHello World!然后, 我们可以通过 otool 工具可以查看生成的可执行文件的
section和segment, 这里我就不懂了… GGSegment __PAGEZERO: 0x100000000 (zero fill) (vmaddr 0x0 fileoff 0) Segment __TEXT: 0x4000 (vmaddr 0x100000000 fileoff 0) Section __text: 0x2c (addr 0x100003f70 offset 16240) Section __stubs: 0x6 (addr 0x100003f9c offset 16284) Section __cstring: 0xe (addr 0x100003fa2 offset 16290) Section __unwind_info: 0x48 (addr 0x100003fb0 offset 16304) total 0x88 Segment __DATA_CONST: 0x4000 (vmaddr 0x100004000 fileoff 16384) Section __got: 0x8 (addr 0x100004000 offset 16384) total 0x8 Segment __LINKEDIT: 0x4000 (vmaddr 0x100008000 fileoff 32768) total 0x10000c000
-
符号表管理(Symbol Table Management)
维护符号表,记录程序中定义的变量、函数、常量等符号的信息。符号表包括符号名称、类型、作用域等信息,用于语义分析和代码生成阶段的符号查找和类型检查。
当在编译过程中发生错误时, 我们是可以利用
符号表来定位到报错位置在源文件中的位置的.通过, 我们在项目上线后, 当线上发生事故异常时, 我们也是可以利用
符号表来确定问题所在的.基于Clang编译器,符号表管理的过程如下:
-
符号表的组织
Clang使用哈希表、树等数据结构来实现符号表。哈希表可以提供快速的查找和插入操作,树结构可以支持符号作用域的嵌套和查找。
-
符号的添加
在词法分析和语法分析过程中,当遇到变量、函数、类型定义等符号的声明和定义时,Clang将根据符号的属性创建一个符号表项,并将其添加到符号表中。符号表项包括符号名称、类型、作用域、存储位置等信息。
-
符号的查找
在进行语义分析和代码生成时,Clang需要查找符号表来获取符号的属性信息,如类型、存储位置等。通过符号名称和作用域,Clang可以在符号表中快速定位到符号表项,以提供相应的属性信息。
-
符号的作用域
符号表管理也涉及符号的作用域管理。Clang会维护一个作用域栈来跟踪当前有效的作用域。当进入一个新的作用域时,例如函数、循环或块作用域,Clang会将该作用域压入作用域栈中,并将内部的符号添加到符号表中。当离开作用域时,Clang会将该作用域从作用域栈中弹出。
-
符号的重定义和重复定义检查
Clang会检查符号表中是否存在重复定义或重定义的符号。如果发现重定义或重复定义的符号,Clang会生成相应的错误信息。
-
-
错误管理(Error Management)
在编译过程难免会遇到编译错误, 这时候, 出错管理体现着无与伦比的作用, 它帮助程序员发现和解决代码中的错误. 提高代码的可靠性和质量。在编译器的实现中,错误管理需要综合考虑准确性、恢复能力和用户友好性,以提供有效的错误处理和提示信息。
以下是编译过程中的错误管理部分:
-
错误检测(Error Detection)
编译器在进行词法分析、语法分析、语义分析等阶段会检测代码中的语法错误、类型错误和其他语义错误。一旦检测到错误,编译器会生成相应的错误消息。
-
错误报告(Error Reporting)
编译器在检测到错误后,会将错误信息记录下来,并向用户报告。错误报告通常包括错误类型、错误位置和错误描述等信息,以帮助程序员找出和解决错误。
-
错误恢复(Error Recovery)
当编译器遇到错误后,可以尝试进行错误恢复来继续编译。错误恢复策略可以包括跳过错误部分、补全缺失部分、重新同步语法等,以尽可能提供更多的错误信息和继续编译的机会。
-
总结
这一篇博客还是比较偏向于理论知识的, 下一篇博客, 我们就着 词法分析 语法分析 语义分析 中间代码生成 这几个前端过程来构建我们的 PrattParser 解释器. 如果有任何问题, 欢迎留言. 欢迎持续关注骚栋.
点击查看 基于Swift的PrattParser项目
