Python学习笔记——从面试题出发学习Python
Python学习笔记——从面试题出发学习Python
- Python学习笔记——从面试题出发学习Python
-
- 1. 可变数据类型与不可变数据类型,深拷贝与浅拷贝,函数参数的传递机制
-
- 1.1 变量与对象
- 1.2 可变数据类型与不可变数据类型
- 1.3 深拷贝与浅拷贝
- 1.4 函数参数的传递机制
- 1.5 is和==的区别
- 2. Python的内存管理机制,Python是否会存在内存泄漏的情况
-
- 2.1 内存池机制
- 2.2 垃圾回收机制
-
- 2.2.1 标记-清除机制
- 2.2.2 分代回收机制
- 2.3 Python内存泄漏
- 3. 闭包与装饰器
-
- 3.1 Python的作用域
- 3.2 闭包
- 3.3 装饰器
- 4. 迭代器与生成器
-
- 4.1 惰性计算
- 4.1 迭代器
- 4.2 生成器
- 5. 正则表达式
-
- 5.1 元字符和语法
- 5.2 re模块函数
- 5.3 re模块变量
- 6. Python中的魔法方法类别有哪些?__init__和__new__的区别是什么?
-
- 6.1 魔法方法
- 6.2 __ init__和__ new__的区别
- 7. 多重继承中的MRO机制
-
- 7.1 新式类和旧式类的区别
- 7.2 多重继承带来的问题
- 7.3 MRO机制
- 7.4 super()作用
- 8. Python中为什么没有重载?
-
- 8.1 为什么没有重载
- 8.2 Python函数可变参数
- 9. Python内建模块
-
- 9.1 collections模块的用法
- 9.2 functools模块的用法
- 9.3 itertools模块的用法
- 10 协程
-
- 10.1 GIL的概念
- 10.2 协程的概念
Python学习笔记——从面试题出发学习Python
1. 可变数据类型与不可变数据类型,深拷贝与浅拷贝,函数参数的传递机制
1.1 变量与对象
- 对象指的是内存中存储数据的实体,具有明确的类型,在 Python 中一切都是对象,包括函数。
- 变量作为对象的引用/别名,实质保存着所指对象的内存地址。
1.2 可变数据类型与不可变数据类型
在Python中类型属于对象,变量没有类型,仅仅是对一个对象的引用。而赋值语句改变的是变量所执的对对象的引用,故一个变量可指向各种数据类型的对象。
- 从现象上看:不可变数据类型更改值后,内存地址发生改变;可变数据类型更改值后,内存地址不发生改变。
- 从本质上看:不可变数据类型对象相应内存中的值不可改变,但变量对对象的引用或指向关系仍是可变的,指向原不可变对象的变量被改变为指向新对象时,Python 会开辟一块新的内存区域,并令变量指向这个新内存,并通过 “垃圾回收机制” 回收原对象;可变数据类型对象的内存地址处的值可改变,因此指向可变对象的变量若发生改变,则该可变对象亦随之改变,即发生原地 (in-place) 修改
- 可变数据类型:list(列表)、dict(字典)
- 不可变数据类型:数值类型(int、float、bool)、string(字符串)、tuple(元组)
1.3 深拷贝与浅拷贝
对于不可变对象,无论深、浅拷贝,内存地址都是一成不变,对于可变对象,需要分情况讨论:
-
直接赋值:仅拷贝了对可变对象的引用,故前后变量均未隔离,任一变量 / 对象改变,则所有引用了同一可变对象的变量都作相同改变。
-
浅拷贝:使用 copy(x) 函数,拷贝可变对象最外层对象并实现隔离,但内部的嵌套对象仍是未被隔离的引用关系。下面这段代码说明这个问题:
>>> import copy >>> x = [555, 666, [555, 666]] >>> z = copy.copy(x) # 浅拷贝 >>> zz = x[:] # 也是浅拷贝, 等同于使用 copy() 函数的 z >>> z [555, 666, [555, 666]] >>> zz [555, 666, [555, 666]] # 改变变量 x 的外围元素, 不会改变浅拷贝变量 >>> x.append(777) >>> x [555, 666, [555, 666], 777] # 只有自身改变, 增加了外围元素 777 >>> z [555, 666, [555, 666]] # 未改变 >>> zz [555, 666, [555, 666]] # 未改变 # 改变变量 x 的内层元素, 则会改变浅拷贝变量 >>> x[2].append(888) >>> x [555, 666, [555, 666, 888], 777] # 同时发生改变, 增加了内层元素 888 >>> z [555, 666, [555, 666, 888]] # 同时发生改变, 增加了内层元素 888 >>> zz [555, 666, [555, 666, 888]] # 同时发生改变, 增加了内层元素 888 # 浅拷贝变量的外围元素改变不会相互影响 >>> z.pop(0) 555 >>> x [555, 666, [555, 666, 888], 777] # 未改变 >>> z [666, [555, 666, 888]] # 只有自身改变, 弹出了外围元素 555 >>> zz [555, 666, [555, 666, 888]] # 未改变 # 浅拷贝变量的内层元素改变会相互影响 >>> z[1].pop() 888 >>> x [555, 666, [555, 666], 777] # 同时发生改变, 弹出了内层元素 888 >>> z [666, [555, 666]] # 同时发生改变, 弹出了内层元素 888 >>> zz [555, 666, [555, 666]] # 同时发生改变, 弹出了内层元素 88 -
深拷贝:使用 deepcopy(x) 函数,拷贝可变对象的“外围+内层”而非引用,实现对前后变量不论深浅层的完全隔离。此外需要注意的是深拷贝递归对象 (直接或间接包含对自身引用的复合对象) 可能会导致递归循环。
1.4 函数参数的传递机制
Python参数传递采用的是“传对象引用”的方式,结合上面我们对可变对象和不可变对象、深拷贝以及浅拷贝的解析,我们应该可以得到如下结论:
- 如果函数收到的是一个可变对象的引用,就能修改对象的原始值,相当于通过**“传引用”**来传递对象。
- 如果函数收到的是一个不可变对象的引用,就不能直接修改原始对象,相当于通过**“传值’**来传递对象。
1.5 is和==的区别
- is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等
- a is b 相当于 id(a)==id(b),id() 能够获取对象的内存地址。
- Python出于对性能的考虑,但凡是不可变对象,在同一个代码块中的对象,只有是值相同的对象,就不会重复创建,而是直接引用已经存在的对象。
2. Python的内存管理机制,Python是否会存在内存泄漏的情况
2.1 内存池机制
- 当创建大量消耗小内存的对象时,频繁调用new/malloc会导致大量的内存碎片,致使效率降低。内存池的作用就是预先在内存中申请一定数量的,大小相等的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给这个需求,不够之后再申请新的内存。这样做最显著的优势就是能够减少内存碎片,提升效率。
- Python的对象管理主要位于Level+1~Level+3层,
Level+3层:对于Python内置的对象(比如int,dict等)都有独立的私有内存池,对象之间的内存池不共享,即int释放的内存,不会被分配给float使用
Level+2层:当申请的内存大小小于256KB时,内存分配主要由 Python 对象分配器实施
Level+1层:当申请的内存大小大于256KB时,由Python原生的内存分配器进行分配,本质上是调用C标准库中的malloc/realloc等函数
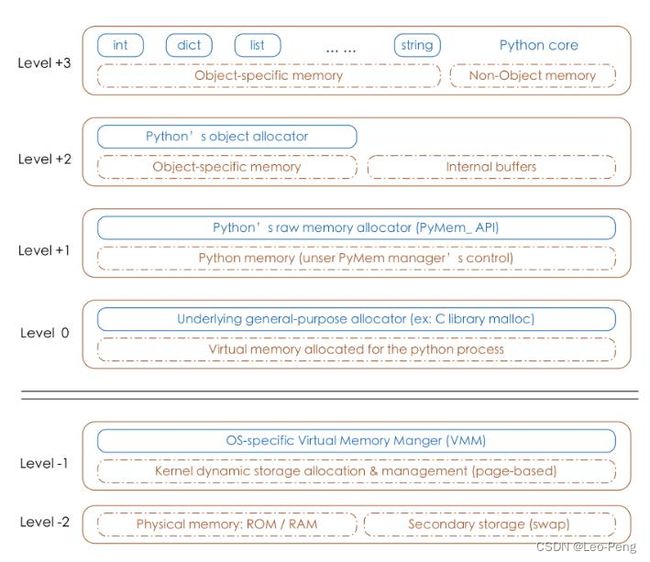
3. 关于释放内存方面,当一个对象的引用计数变为0时,Python就会调用它的析构函数。调用析构函数并不意味着最终一定会调用free来释放内存空间,频繁地申请、释放内存空间会使Python的执行效率大打折扣。在析构时也采用了内存池机制,从内存池申请到的内存会被归还到内存池中,以避免频繁地申请和释放动作
2.2 垃圾回收机制
- Python 通过引用计数和一个能够检测和打破循环引用的循环垃圾回收器来执行垃圾回收。可用 gc 模块控制垃圾回收器。具体而言,对每个对象维护一个 ob_refcnt 字段,用于记录该对象当前被引用的次数。每当有新引用指向该对象时,该对象的引用计数 ob_refcnt +1;每当该对象的引用失效时,该对象的引用计数 ob_refcnt -1;一旦对象的引用计数 ob_refcnt = 0,该对象列入垃圾回收队列,进而进行内存释放。
- 引用计数垃圾回收机制的优点在于,能够自动清理不用的内存空间,甚至能够随意新建对象引用而无需考虑手动释放内存空间的问题,故相比于 C 或 C++ 这类静态语言更“省心”。
- 引用计数垃圾回收机制的缺点是需要额外空间资源维护引用计数。
2.2.1 标记-清除机制
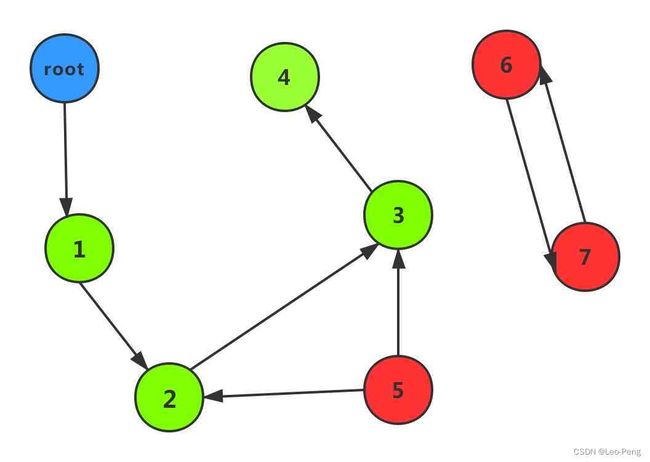
- 标记-清除用来解决引用计数机制产生的循环引用,进而导致内存泄漏的问题 。 循环引用只有在容器对象(包含对其它对象的引用的对象)才会产生,比如字典,元组,列表等。
- 标记阶段,从root节点遍历所有的对象,如果是可达的,也就是还有对象引用它,那么就标记该对象为可达。
- 清除阶段,从root节点出发再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收。如下图中蓝色即为可达对象,红色即为不可达对象,将会被清除。
2.2.2 分代回收机制
分代回收建立标记清除的基础之上,是一种以空间换时间的操作方式,即控制内存回收频次。
- 分代回收,根据内存中对象的存活时间将他们分为3代,新生的对象放入到0代,如果一个对象能在第0代的垃圾回收过程中存活下来,则将其放入到1代中,同理,则会进入到2代。
- 能够活着成为第2代的对象,必然是那些使用频繁的对象,而且他们已经存活很久的时间了,大概率的,还会存活很久,因此,2代回收的就不那么频繁。
- Python中可以通过设置阈值来改变分代回收的触发条件:
import gc gc.set_threshold(600, 10, 5) print(gc.get_threshold())
2.3 Python内存泄漏
Python内存泄漏通常有如下几种情况:
- 所用到的用 C 语言开发的底层模块中出现了内存泄露。
- 代码中用到了全局的 list、 dict 或其它容器,不停的往这些容器中插入对象,而忘记了在使用完之后进行删除回收。
- 有引用循环并且被循环引用的对象定义了__del__方法,就会发生内存泄露。原因是重载__del__方法后垃圾回收模块不知道应该先调用哪个对象的__del__方法,因此gc.collect()方法就默认不对重载了__del__方法的循环引用对象进行回收,而对象的状态也会从unreachable转变为uncollectable。要解决这种情况造成内存泄漏的话,只能显式调用其中某个对象的__del__方法。
3. 闭包与装饰器
3.1 Python的作用域
在学习闭包概念之前,有必要先了解下Python的作用域相关概念
- Python的定义是程序创建、访问、改变一个变量时,都是在一个保存该变量的空间内进行,这个空间为命名空间,即作用域。
- Python的作用域可以概括为LEGB四种作用域:
L(Local):在函数与类中,每当调用函数时都会创建一个局部作用域,局部变量域像一个栈,仅仅是暂时的存在,依赖创建该局部作用域的函数是否处于活动的状态;
E(Enclosing):一般出现在函数中嵌套了一个函数,在外围的函数中的作用域;主要目的是实现闭包;
G(Global):模块文件顶层声明的变量具有全局作用域,从外部看来,模块的全局变量就是一个模块对象的属性;仅限于单个模块文件中;
B(Built-in): 系统内解释器定义的变量,如预定义在builtin 模块内的变量;解释器在则在,解释器亡则亡; - 只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)不会引入新的作用域的,如下代码:
上述打印结果为4,4,4,而不是0,2,4,原因是在往flist中添加func的时候并没有形成作用域,也就没有保存i的值,而是在执行f(2)的时候去取,此时循环已经结束,i的值固定为2,输出结果为4,4,4,如果需要输出0,2,4的话,可以进行如下修改形成闭包即可:flist = [] for i in xrange(3): def func(x): return x*i flist.append(func) for f in flist: print(f(2))
下面我们来看闭包的定义和使用方法。flist = [] for i in xrange(3): def makefunc(i) def func(x): return x*i return func flist.append(makefunc(i)) for f in flist: print(f(2))
3.2 闭包
闭包并不是Python的独有概念,闭包在维基百科上的定义如下:
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。
闭包的两个作用主要是:
- 可以读取外层函数的变量;
- 使得外层函数内的局部变量的值始终保持在内存中,不会在外层函数调用后自动被清除;
局部变量无法共享和长久的保存,而全局变量可能造成变量污染,其中上述第二种作用可以使得我们既可以长久保存变量又不会造成全局污染,但是使用闭包有两点需要注意几点:
-
闭包无法改变外部函数局部变量指向的内存地址,如下所示:
def outfun(): x = 0 def infun(): x = 1 print(x) # 打印1 print(x) # 打印0 infun() print(x) # 打印0 outfun()上述函数打印结果为010,很多博客将这一特性描述为闭包无法改变外部函数的局部变量,但这一描述是不准确的,如果x为可变对象,上述代码就会表现为闭包改变了外部函数的局部变量的值。
-
返回闭包时,返回函数不要引用任何循环变量,或者后续会发生变化的变量,这条规则可以参考上述3.1节第3点展示的例子,具体原因是因为循环无法形成作用域,对应的循环变量无法保存,因此会造成与预期不符的结果。
-
可以通过closure属性判断一个函数是否是闭包。
3.3 装饰器
-
装饰器的定义和作用:装饰器本质上是一个Python函数,装饰器的返回值也是一个函数对象。它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,基于此可以抽离出大量与函数功能本身无关的雷同代码并继续重用,例如插入日志、性能测试、事务处理、缓存、权限校验等。
-
装饰器的实现:简单装饰器实现如下:
def use_logging(func): def wrapper(): logging.warn("%s is running" % func.__name__) return func() # 把 foo 当做参数传递进来时,执行func()就相当于执行foo() return wrapper def foo(): print('i am foo') foo = use_logging(foo) # 因为装饰器 use_logging(foo) 返回的时函数对象 wrapper,这条语句相当于 foo = wrapper foo()基于@语法糖的实现如下:
def use_logging(func): def wrapper(): logging.warn("%s is running" % func.__name__) return func() return wrapper @use_logging def foo(): print("i am foo") foo()带参数的装饰器实现如下:
def use_logging(level): def decorator(func): def wrapper(*args, **kwargs): if level == "warn": logging.warn("%s is running" % func.__name__) elif level == "info": logging.info("%s is running" % func.__name__) return func(*args) return wrapper return decorator @use_logging(level="warn") def foo(name='foo'): print("i am %s" % name) foo()还有一个与装饰器相关的库函数functools.wraps,其作用主要是将原函数f(x)的元信息拷贝到装饰器的func函数中,使得装饰器中的func函数和原函数f(x)一样的元信息:
from functools import wraps def logged(func): @wraps(func) def with_logging(*args, **kwargs): print func.__name__ # 输出 'f' print func.__doc__ # 输出 'does some math' return func(*args, **kwargs) return with_logging @logged def f(x): """does some math""" return x + x * x当我们理解闭包后,会发现装饰器的实现并不难理解。
4. 迭代器与生成器
4.1 惰性计算
- 惰性计算又称为惰性求值(Lazy Evaluation),是一个计算机编程中的概念,它的目的是要最小化计算机要做的工作,尽可能延迟表达式求值。
- 延迟求值特别用于函数式编程语言中。在使用延迟求值的时候,表达式不在它被绑定到变量之后就立即求值,而是在该值被取用的时候求值。
- 惰性计算的最重要的好处是它可以构造一个无限的数据类型。
4.1 迭代器
-
迭代器的作用:迭代器可以像列别一样迭代获取其中每一个元素,但是它不像列表将所有元素一次性加载到内存,而是以一种延迟计算方式返回元素。当我们获取的元素数据量特别大时,列表会占用几百兆的内存,而迭代器只需要几十个字节的空间,这就是迭代器的作用。
-
将一个类作为迭代器需要实现两个方法 __ iter__() 与 __ next__():
__ iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __ next__() 方法并通过 StopIteration 异常标识迭代的完成。可迭代对象需要提供 iter()方法,否则不能被 for 语句处理。
__ next__() 方法会返回下一个迭代器对象。
如下是一个斐波拉契数列的迭代器:class Fibonacci(object): def __init__(self, all_num): self.all_num = all_num self.current_num = 0 a = 0 b = 1 def __iter__(self): return self def __next__(self): if self.current_num < self.all_num: result = self.a self.a, self.b = self.b, self.a + self.b self.current_num += 1 return result else: raise StopIteration fibo = Fibonacci(10) for i in fibo: print(i)
4.2 生成器
生成器通常两种方式:生成器表达式(generator expression)和生成器函数(generator function)。
-
生成器表达式:在生成列表和字典时,可以通过推导表达式完成。只要把推导表达式中的中括号换成小括号就成了生成器表达式,如下
# 列表: a = [x * x for x in range(3)] print(a) # 0,1,4 # 生成器表达式: b = (x * x for x in range(3)) print(next(b)) # 0 print(next(b)) # 1 print(next(b)) # 4 print(next(b)) # 触发 StopIteration 异常 # 通常我们使用时不会调用next()方法,而是使用for循环 c = (x * x for x in range(3)) for i in c: print(i) -
生成器函数:如果一个函数定义中包含 yield 表达式,那么这个函数就不再是一个普通函数,而是一个生成器函数。yield 语句类似 return 会返回一个值,但它会记住这个返回的位置,下次 next() 迭代就从这个位置下一行继续执行。通过生成器表达式来进行表达式推到是有局限的,复杂的处理需要生成器函数完成。如下斐波拉契数列的生成器:
def Fibonacci(n): a, b = 0, 1 while(i < n): yield a a, b = b, a + b fibo = Fibonacci(5) for i in fibo : print(i, end=' ') # 0 1 1 2 3 print(type(fibo)) # 输出print(type(Fibonacci(5))) # 输出 从这里我们可以看出:
- 生成器函数和相同功能相比的迭代器要简洁不少;
- 生成器函数并不是生成器,其运行返回后的结果才是生成器;
-
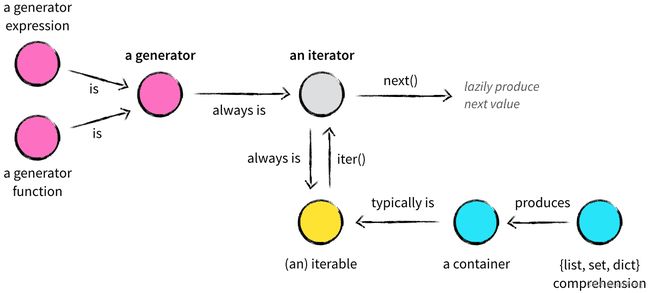
生成器的本质:生成器表达式和生成器函数产生生成器时,会自动生成名为 __ iter__ 和 __ next__ 的方法。也就是说生成器是一种迭代器。对于迭代器和生成器的区别,可以从下图进行理解:
5. 正则表达式
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同。这里我们对其实现原理我们不做深究,主要以思维导图的方式整理了下正则表达式的各种语法和函数。
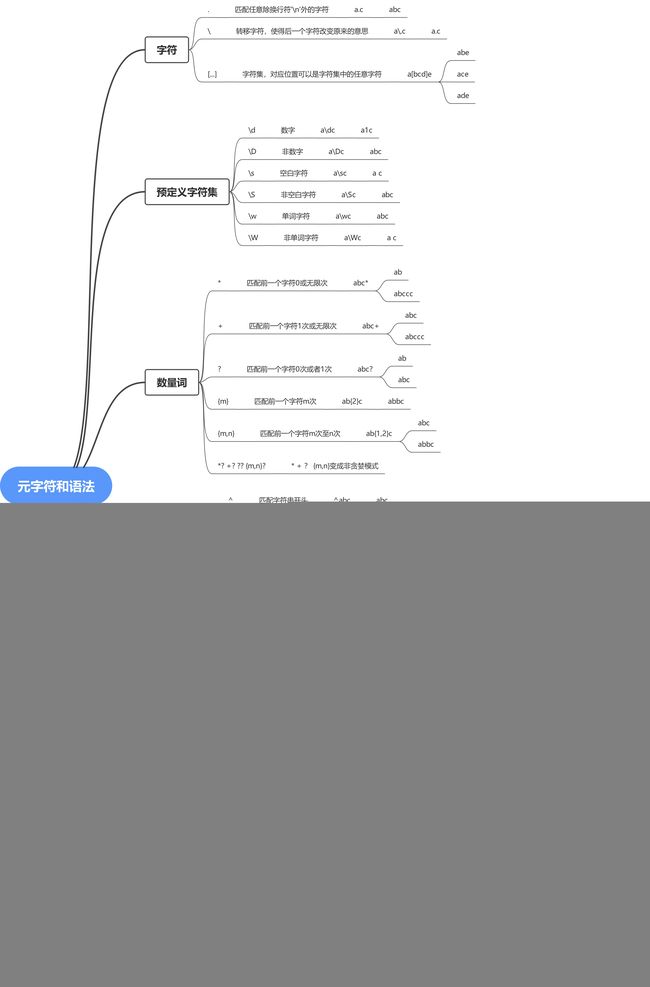
5.1 元字符和语法
如下列出来Python支持的正则表达式元字符和语法
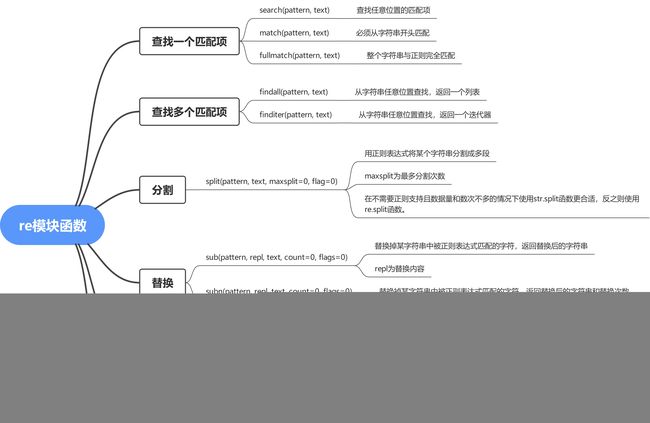
5.2 re模块函数
Python通过re模块提供对正则表达式的支持,如下列出来re模块函数:
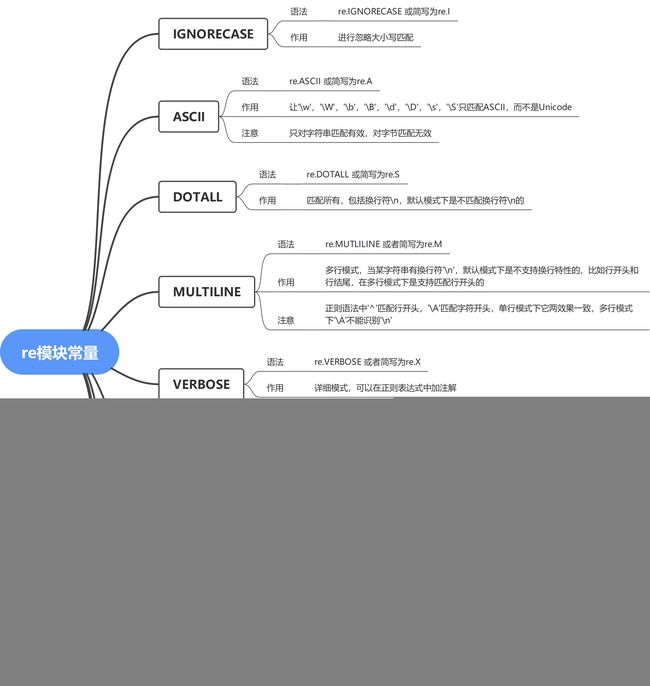
5.3 re模块变量
re模块中还提供了9个模块常量用于标记不同的功能细节,如下:
6. Python中的魔法方法类别有哪些?__init__和__new__的区别是什么?
6.1 魔法方法
- 魔法方法(Magic Methods)是Python中的内置函数,一般以双下划线开头和结尾,例如__init__、__del__等。之所以称之为魔法方法,是因为这些方法会在进行特定的操作时会自动被调用。
- 在Python中,可以通过dir()方法来查看某个对象的所有方法和属性,其中双下划线开头和结尾的就是该对象的魔法方法。以字符串为例:
其中有一些我们比较熟悉的例如:__ getattribute__定义当该类的属性被访问时的行为,__ getitem__定义获取容器中指定元素的行为等,具体用到的时候我们在去了解其作用。>>> dir("hello") ['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__', '__init__', '__le__', '__len__', '__lt__', '__mo d__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_formatter_field_name_split', '_formatter_parser', 'capitalize', 'center', 'count', 'decode', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum', 'isalpha', 'isdigit', 'isl ower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'partition', 'replace', 'rfind', 'rindex', ' rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate' , 'upper', 'zfill']
6.2 __ init__和__ new__的区别
在所有魔法方法中,__ init__和__ new__可能是最重要的一对魔法方法了,其区别如下:
- __ new__()方法用于创建实例,类实例化之前会首先调用,它是class的方法,是个静态方法。而__ init__()方法用户初始化实例,该方法用在实例对象创建后被调用,它是实例对象的方法,用于设置类实例对象的一些初始值。
- 如果类中同时出现了__ init__()方法和__ new__()方法,则先调用__ new__()方法后调用__ init__()方法。__ new__()方法是创建实例的第一步,执行完了需要返回创建的类的实例,否则则报错,无法执行__ init__()方法。其中,__ init__()方法将不返回任何信息。
- 如下是基于__ init_()方法实现的单例类:
class Mycls: _instance = None def __new__(cls): # 判断该类的属性是否为空;对第一个对象没有被创建,我们应该调用父类的方法,为第一个对象分配空间 if cls._instance == None: # 把类属性中保存的对象引用返回给python的解释器 cls._instance = object.__new__(cls) return cls._instance # 如果cls._instance不为None,直接返回已经实例化了的实例对象 else: return cls._instance def __init__(self): print('init') my1=Mycls() print(my1) my2=Mycls() print(my2) >>> init <__main__.Mycls object at 0x000000406E471148> Init <__main__.Mycls object at 0x000000406E471148>
7. 多重继承中的MRO机制
7.1 新式类和旧式类的区别
- 在早期版本的 Python 中,所有类并没有一个共同的祖先 object,如果定义一个类,但没有显式指定其祖先,那么就被解释为旧式类
- Python 2.x 版本中,为了向后兼容保留了旧式类。该版本中的 新式类必须显式继承 object 或者其他新式类
- Python 3.x 版本中,不再保留旧式类的概念。因此,没有继承任何其他类的类都隐式地继承自object
7.2 多重继承带来的问题
-
多继承中最经典的问题就是菱形继承会带来的子类重复调用问题,如下代码
class A: def fun(self): print('A.fun') class B(A): def fun(self): A.fun(self) print('B.fun') class C(A): def fun(self): A.fun(self) print('C.fun') class D(B , C): def fun(self): B.fun(self) C.fun(self) print('D.fun') D().fun() >>> A.fun B.fun A.fun C.fun D.fun可以看到,A类被初始化了两次,会造成资源浪费。
-
我们可以通过super()函数解决上述问题,如下代码:
class A: def fun(self): print('A.fun') class B(A): def fun(self): super(B , self).fun() print('B.fun') class C(A): def fun(self): super(C , self).fun() print('C.fun') class D(B , C): def fun(self): super(D , self).fun() print('D.fun') D().fun() >>> A.fun C.fun B.fun D.fun从上述结果看到,使用super()函数后A类仅初始化了一次,那么为什么输出A->C->B->D以及为什么super()可以避免菱形继承问题呢?下面进一步解释
7.3 MRO机制
- MRO全称为Method Resolution Order,在每个类声明之后,Python都会自动为创建一个名为“mro”的内置属性,这个属性就是Python的MRO机制生成的,该属性是一个tuple,定义的是该类的方法解析顺序(继承顺序),当用super调用父类的方法时,会按照__mro__属性中的元素顺序去挨个查找方法。我们可以通过“类名.mro”或“类名.mro()”来查看上面代码中D类的__mro__属性值:
- Python 发展至今,经历了以下 3 种 MRO 算法:
(1)从左往右,采用深度优先搜索(DFS)的算法,称为旧式类的 MRO;
(2)自 Python 2.2 版本开始,新式类在采用深度优先搜索算法的基础上,对其做了优化;
(3)自 Python 2.3 版本,对新式类采用了 C3 算法。由于 Python 3.x 仅支持新式类,所以该版本只使用 C3 算法。 - C3算法流程如下图所示:
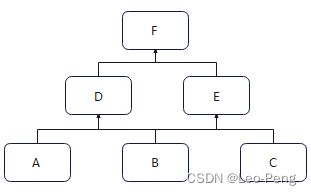
(1)首先将入度(指向该节点的箭头数量)为零的节点放入列表,并将F节点及与F节点有关的箭头从上图树中删除;
(2)继续找入度为0的节点,找到D和E,左侧优先,故而现将D放入列表,并从上图树中删除D,这是列表中就有了F、D。
(3)继续找入度为0的节点,有A和E满足,左侧优先,所以是A,将A从上图中取出放入列表,列表中顺序为F、D、E;
(4)接下来入度为0的节点只剩下E,取出E放入列表;
(5)只剩下B和C节点,且入度都为0,但左侧优先,二先将B放入列表,然后才是后才是C;
(6)不过别忘了,新式类Python所有类都有一个共同的父类,那就是object类,所以,最好还会把object放入列表末尾。
最终生成列表中元素顺序为:F->D->A->E->B->C->object。
7.4 super()作用
- super是一个类,实例化之后得到的是一个代理的对象,而不是得到了父类,并且我们使用这个代理对象来调用父类或者兄弟类的方法。
- super(type , obj),这个方式要传入两个常数,第一个参数type必须是一个类名,定义在__mro__数组中的那个位置开始找,第二个参数obj是一个该类的实例化对象,定义的是用哪个类的__mro__元素。如下:
上述代码__mro__的顺序:F->D->A->E->B->C->object,我们可以发现调用的都是type对应的类在__mro__顺序中的下一个类的fun方法。所以,我们可以通过type参数来指定调用父类的范围,通过obj参数指定的是用那个类的__mro__属性。class A(object): def fun(self): print('A.fun') class B(object): def fun(self): print('B.fun') class C(object): def fun(self): print('C.fun') class D(A,B): def fun(self): print('D.fun') class E(B, C): def fun(self): print('E.fun') class F(D, E): def fun(self): print('F.fun') # 保持obj实例不变,尝试不同的type super(E , F()).fun() # 输出结果:B.fun super(D , F()).fun() # 输出结果:A.fun super(F , F()).fun() # 输出结果:D.fun # 保持type不变,obj尝试不同的实例 super(B , F()).fun() # 输出结果:C.fun super(B , E()).fun() # 输出结果:C.fun super(B , B()).fun() # 这是错误的,会报错 - super()事实上是懒人版的super(type , obj),这种方式只能用在类体内部,Python会自动把两个参数填充上,type指代当前类,obj指导当前类的实例对象,相当于super(class , self)。
8. Python中为什么没有重载?
8.1 为什么没有重载
- 函数重载主要是为了解决两个问题:对于功能相同的函数做到可变参数类型和可变参数个数
- 对于可变参数类型问题,Python根本不需要处理,因为 python 可以接受任何类型的参数,如果函数的功能相同,那么不同的参数类型在 python 中很可能是相同的代码,没有必要做成两个不同函数。
- 对于可变参数个数问题,Python可以使用缺省参数。对那些缺少的参数设定为缺省参数即可解决问题。因为你假设函数功能相同,那么那些缺少的参数终归是需要用的。Python中还有一种特殊的函数参数,即可变参数。可变参数可以接受任意数量的参数,并将它们存储为一个元组或列表。
8.2 Python函数可变参数
我们经常会在代码中看到*args、**kwargs,他们都被称为可变参数(任意参数):
-
作为函数定义时:
(1)*参数收集所有未匹配的位置参数组成一个tuple对象,局部变量args指向此tuple对象;
(2)**参数收集所有未匹配的关键字参数组成一个dict对象,局部变量kwargs指向此dict对象;
例如def temp(*args,**kwargs): pass -
作为函数调用时:
(1)*参数用于解包tuple对象的每个元素,作为一个一个的位置参数传入到函数中;
(2)**参数用于解包dict对象的每个元素,作为一个一个的关键字参数传入到函数中;
例如:my_tuple = ("wang","yuan","wai") temp(*my_tuple) #---等同于---# temp("wangyuan","yuan","wai") my_dict = {"name":"wangyuanwai","age":32} temp(**my_dict) #----等同于----# temp(name="wangyuanwai",age=32)
9. Python内建模块
Python提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作Batteries Included。用Python开发,许多功能不必从零编写,直接使用现成的即可,因此作为开发者熟练掌握这些内建模块对于开发效率肯定是有帮助的。这里总结几种比较常用的模块:
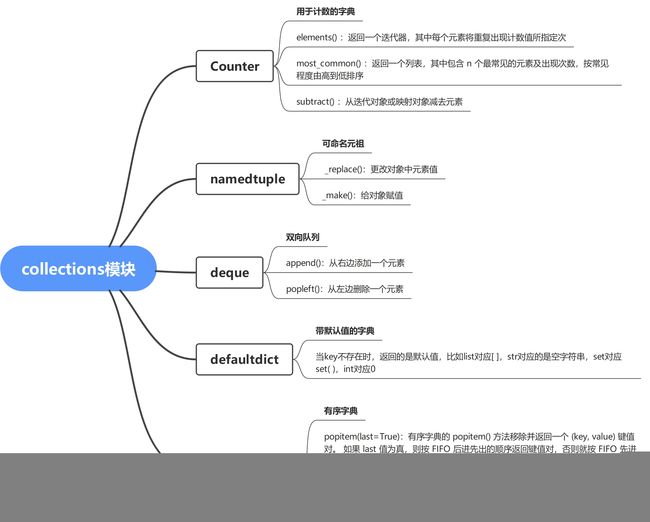
9.1 collections模块的用法
collections是集成专用容器的模块,作为对通用容器 dict、list、set 和 tuple 的补充。下面仅对常用方法进行整理。
9.2 functools模块的用法
functools是集成特殊装饰器的模块,基于这些装饰器通常可以用来节省内存或者简化函数。下面仅对常用方法进行整理:

9.3 itertools模块的用法
itertools是集成操作迭代器方法的模块,通过这些方法可以使得迭代更加高效,下面仅对常用方法进行整理:

10 协程
10.1 GIL的概念
- GIL的全称是Global Interpreter Lock(全局解释器锁),简单来说,是一个互斥锁,它只允许一个线程拥有Python解释器的控制权。这就意味着:同一时间,只能有一个线程在执行的状态。
- CPU密集型代码(各种循环处理、计数等等),在这种情况下,单线程的操作计数很快就会达到阈值,然后触发GIL的释放与再竞争,多个线程来回切换当然是需要消耗资源的,所以Python下的多线程对CPU密集型代码并不友好。
- IO密集型代码(文件处理、网络爬虫等),单线程下有的IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率。所以Python的多线程对IO密集型代码比较友好。
- 多核多线程比单核多线程更差,原因是单核下多线程,每次释放GIL,唤醒的那个线程都能获取到GIL锁,所以能够无缝执行,但多核下,CPU0释放GIL后,其他CPU上的线程都会进行竞争,但GIL可能会马上又被CPU0拿到,导致其他几个CPU上被唤醒后的线程会醒着等待到切换时间后又进入待调度状态,这样会造成线程颠簸,导致效率更低。
- Python下想要充分利用多核CPU,就用多进程,想要充分利用单核CPU,就用协程
10.2 协程的概念
在 Python 中,协程(Coroutine)是一种轻量级的并发编程方式,可以通过协作式多任务来实现高效的并发执行,协程相比于线程的优势如下:
- 轻量级:协程的上下文切换成本很小,可以在单线程内并发执行大量的协程。
- 低延迟:协程的执行过程中,没有线程切换的开销,也没有加锁解锁的开销,可以更快地响应外部事件。
- 高效性:协程的代码通常比多线程和多进程的代码更加简洁和可读,维护成本更低。
在 Python 3.4 之前,协程通常使用 yield 关键字来实现,称为“生成器协程”。在 Python 3.4 引入了 asyncio 模块后,可以使用 async/await 关键字来定义协程函数,称为“原生协程”。这里我们仅介绍下原生协程的用法:
下面给出一个简单的原生协程示例,其中包含一个 async 关键字修饰的协程函数 coroutine 和一个简单的异步 I/O 操作:
import asyncio
async def func():
print('Coroutine started')
await asyncio.sleep(1)
print('Coroutine finished')
async def main():
print('Main started')
await func()
print('Main finished')
asyncio.run(main())
>>>
Main started
Coroutine started
Coroutine finished
Main finished
在上面的代码中,使用 async 关键字定义了一个原生协程函数 ,并在其中使用 await 关键字来暂停函数的执行,等待异步 I/O 操作的完成。通过这种方式,可以在原生协程中编写异步并发代码,从而提高代码的性能和效率。(为什么要用asyncio.sleep, 而不用time.sleep呢? 因为await后面一个要跟一个异步函数的实例化对象,可是time.sleep并不是异步函数,也就不支持协程间切换,就没法实现并发,只能串行。)
以上是在两个异步函数中实现了切换,而如果一个普通的线程要能同时处理多个异步函数, 就要创建一个事件循环:
import asyncio
def main():
loop = asyncio.new_event_loop()
- 在事件循环中, 会执行所有异步函数;
- 但同一时间, 只有一个任务在执行;
- 当一个任务中执行await后, 此任务被挂起, 事件循环执行下一个任务;
下面通过一个简单的例子来说明事件循环的用法,平常我们上课时通常是一边听一边记笔记,
import asyncio
import time
async def listening():
"""听课"""
print('start listening')
await asyncio.sleep(1)
print("listening...")
await asyncio.sleep(1)
print("listening...")
await asyncio.sleep(1)
print('end listening')
return "finish listening"
async def taking_notes():
"""记笔记"""
print("start taking notes")
await asyncio.sleep(1)
print("taking notes...")
await asyncio.sleep(1)
print("taking notes...")
await asyncio.sleep(1)
print("end taking notes")
return "finish taking notes"
async def main():
print("start main")
future1 = listening()
future2 = taking_notes()
ret1 = await future1
ret2 = await future2
print(ret1, ret2)
print("end main")
if __name__ == '__main__':
t1 = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
t2 = time.time()
print('cost:', t2-t1)
>>>
start main
start listening
listening...
listening...
end listening
start taking notes
taking notes...
taking notes...
end taking notes
finish listening finish taking notes
end main
cost: 6.007081508636475
上述执行并不符合预期,原因是用await确实会切换协程, 但你事先没有告诉事件循环有哪些协程, 它不知道切换到哪个协程, 所以事件循环就会按顺序坚持执行完,但是当我们使用用asyncio.gather()补充改信息后结果就符合预期了:
async def main():
print("start main")
future1 = listening()
future2 = taking_notes()
ret1, ret2 = await asyncio.gather(future1, future2)
print(ret1, ret2)
print("end main")
>>>
start main
start listening
start taking notes
listening...
taking notes...
listening...
taking notes...
end listening
end taking notes
finish listening finish taking notes
end main
cost: 3.003592014312744
通过上述例子我们应该了解了协程的大致使用方法,协程的更细节的用法后续有机会实际使用后再进行补充