2023年第二届全国大学生数据统计与分析竞赛——电影评分的大数据分析

问题一:请分析附件 1 中最受欢迎的电影类型是什么?排名前 250 名电影中 出现次数最多的导演前 10 名是谁?出现次数最多的国家前 5 名是哪些国家
最受欢迎的电影类型
lst = []
for i in df1['电影类型'].apply(lambda x : x.split('/')):
for j in i:
lst.append(j)
pd.DataFrame(lst).value_counts().head(1)
出现次数最多的导演前 10 名
df1['导演'].value_counts()[:10]
出现次数最多的国家前 5 名
lst1 = []
for i in df1['国家'].apply(lambda x : x.split('/')):
for j in i:
lst1.append(j.strip())
pd.DataFrame(lst1).value_counts().head(5)
问题二:请分析附件 1 中排名前 250 名电影的上映年份主要集中在哪几年? 排名前 250 名电影的评分与评论人数、国家、导演和电影类型是否有关系?
前 250 名电影的上映年份主要集中在哪几年
df1['上映年份'].value_counts()[:5]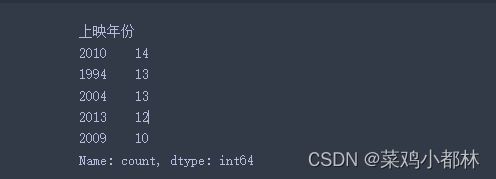
排名前 250 名电影的评分与评论人数、国家、导演和电影类型是否有关系?
import numpy as np
from scipy import stats
from pandas import DataFrame as df
data = df1[['评分','评论人数','国家','导演','电影类型']]
name = data.columns.tolist()
dic = dict()
for i in range(len(name)):
dic.update({i:name[i]})
Spearmanr = df(stats.spearmanr(data.iloc[:,:])[0])
Spearmanr = Spearmanr.rename(columns = dic).T.rename(columns = dic)
Spearmanr
感觉关系不大!!!!,下面的散点图也是这种感觉
from matplotlib import pyplot as plt
plt.figure(figsize=(15,6),facecolor='#fff')
plt.scatter(data['评论人数'],data['评分'])
plt.show()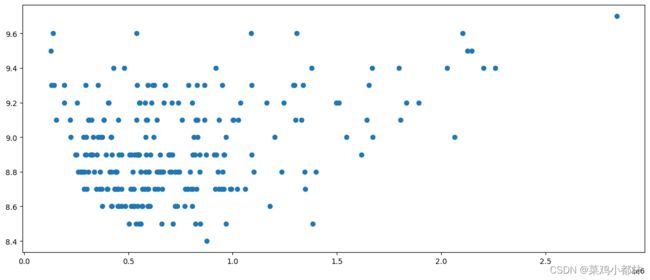
问题三:请你们收集相关数据,分析附件 2 中电影票房较高的电影主要是什么类型的电影?并给出这些电影的上映时间、总票房(元)、平均票价和平均场次 的相关统计图表。
这里用到的数据是用的附件1和附件2关联后取交集的结果。对附件外的数据并没有补充,有需要的可以自行百度去找到数据,并将数据代入其中。
df2 = pd.read_csv('附件2. 电影票房.csv',encoding='gbk')
#图中正常展示中文标签
plt.rcParams['font.sans-serif'] = ['simhei']
#展示负号
plt.rcParams['axes.unicode_minus'] = False
res1 = df1.merge(df2,how = 'inner',on = '电影名称').dropna(axis = 0)
lst3 = []
for i in res1.sort_values('总票房(元)',ascending = False)[:10]['电影类型'].apply(lambda x : x.split('/')):
for j in i:
lst3.append(j)
plt.figure(figsize=(15,6),facecolor='#fff')
plt.pie(
x = pd.DataFrame(lst3).value_counts().values.tolist(),
labels = pd.DataFrame(lst3).value_counts().index.tolist(),
autopct='%.0f%%'
)
plt.show()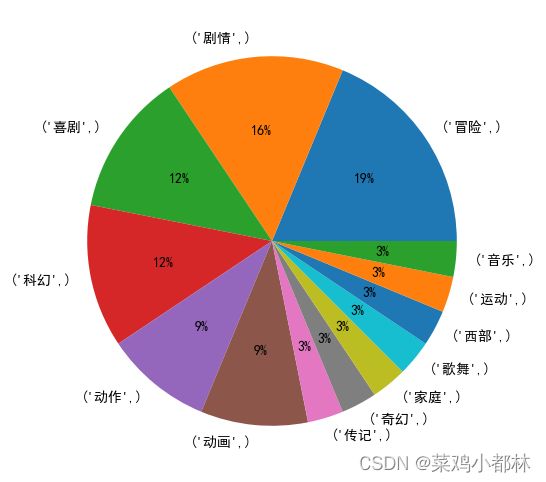
res1.sort_values('总票房(元)',ascending = False)[:10]['电影名称'].values
res1.sort_values('总票房(元)',ascending = False)[:10]['总票房(元)'].values
plt.bar(
res1.sort_values('总票房(元)',ascending = False)[:10]['电影名称'].values,
res1.sort_values('总票房(元)',ascending = False)[:10]['总票房(元)'].values,
color = '#BFA2C6'
)
plt.xticks(rotation = 330)
plt.show() 
res1.sort_values('总票房(元)',ascending = False)[:10]['平均票价'].value_counts()
plt.figure(figsize=(15,6),facecolor='#fff')
plt.pie(
x = res1.sort_values('总票房(元)',ascending = False)[:10]['平均票价'].value_counts().values.tolist(),
labels = res1.sort_values('总票房(元)',ascending = False)[:10]['平均票价'].value_counts().index.tolist(),
autopct='%.0f%%'
)
plt.title('平均票价')
plt.show()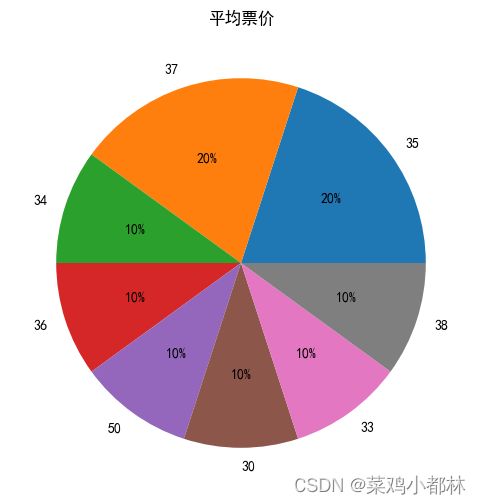
res1.sort_values('总票房(元)',ascending = False)[:10]['平均场次'].value_counts()
plt.figure(figsize=(15,6),facecolor='#fff')
plt.pie(
x = res1.sort_values('总票房(元)',ascending = False)[:10]['平均场次'].value_counts().values.tolist(),
labels = res1.sort_values('总票房(元)',ascending = False)[:10]['平均场次'].value_counts().index.tolist(),
autopct='%.0f%%'
)
plt.title('平均场次')
plt.show()
da