【API篇】三、Flink转换算子API
文章目录
- 0、demo数据
- 1、基本转换算子:映射map
- 2、基本转换算子:过滤filter
- 3、基本转换算子:扁平映射flatMap
- 4、聚合算子:按键分区keyBy
- 5、聚合算子:简单聚合sum/min/max/minBy/maxBy
- 6、聚合算子:归约聚合reduce
- 7、用户自定义函数:函数类
- 8、用户自定义函数:富函数类
创建完执行环境,从数据源读入数据,就该用转换算子对数据做处理了,即使用各种转换算子,将一个或多个DataStream转换为新的DataStream

0、demo数据
准备一个实体类WaterSensor:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class WaterSensor{
private String id; //水位传感器类型
private Long ts; //传感器记录时间戳
private Integer vc; //水位记录
}
//注意所有属性的类型都是可序列化的,如果属性类型是自定义类,那要实现Serializable接口
1、基本转换算子:映射map
map即把数据流中的数据进行转换,形成新的数据流。一一映射,消费一个元素就产出一个元素。

DataStream对象调用map()方法进行转换处理。map方法形参是接口MapFunction的实现对象,返回值类型还是DataStream:
public class TransMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_2", 2, 2)
);
// 方式一:传入匿名类,实现MapFunction
stream.map(new MapFunction<WaterSensor, String>() {
@Override
public String map(WaterSensor e) throws Exception {
return e.id;
}
}).print();
// 方式二:传入MapFunction的实现类
stream.map(new MapFunctionImpl()).print();
//方式三:Lambda表达式
stream.map(t -> t.getId()).print();
//方式四:Lambda表达式
stream.map(WaterSensor::getId).print();
env.execute();
}
}
public class MapFunctionImpl implements MapFunction<WaterSensor, String> {
@Override
public String map(WaterSensor e) throws Exception {
return e.id;
}
}
在实现MapFunction接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还需要重写一个map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。当好几个作业都需要这个转换逻辑时,不用匿名内部类,而是实现类好点,省的重复写转换逻辑。
2、基本转换算子:过滤filter
通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为true则元素正常输出,若为false则元素被过滤

filter转换需要传入的参数需要实现FilterFunction接口,而FilterFunction内要实现filter()方法,就相当于一个返回布尔类型的条件表达式。
public class TransFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
// 传入匿名类实现FilterFunction
stream.filter(new FilterFunction<WaterSensor>() {
@Override
public boolean filter(WaterSensor e) throws Exception {
return "sensor_1".equals(e.getId());
}
}).print();
// Lambda表达式
// stream.filter(t -> "sensor_1".equals(t.getId())).print();
env.execute();
}
}
3、基本转换算子:扁平映射flatMap
flatMap主要是将数据流中的整体拆分成一个一个的个体使用,消费一个元素,可以产生0到多个元素。先扁平化,再映射。

//实现:如果输入的数据是sensor_1,只打印vc;
//如果输入的数据是sensor_2,既打印ts又打印vc
public class TransFlatmap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
stream.flatMap(new FlatMapFunctionImpl()).print();
env.execute();
}
}
public class FlatMapFunctionImpl implements FlatMapFunction<WaterSensor, String> {
@Override
public void flatMap(WaterSensor value, Collector<String> out) throws Exception {
if (value.id.equals("sensor_1")) {
out.collect(String.valueOf(value.vc)); //一进一出
} else if (value.id.equals("sensor_2")) {
out.collect(String.valueOf(value.ts)); //一进多出
out.collect(String.valueOf(value.vc));
}
//sensor_3 一进0出
}
}
//value为WaterSensor类型,收集器为String类型,即WaterSensor转String
map和flatMap相比,map总是能一进一出是因为MapFunction接口的map方法是有return返回值的,一个传入,肯定对应一个返回。而flatMap下,FlatMapFunction接口的flatMap方法返回值类型为void,最终返回啥,是靠收集器往下游传,调用n次采集器的collect方法,就输出n条数据,一次也不调,那就是不处理,又是void,那就相当于被过滤了,因此有了flatMap的一进多出:
- 一进一出
- 一进多出
- 一进零出
4、聚合算子:按键分区keyBy
对海量数据进行聚合计算前,分组是必要的。
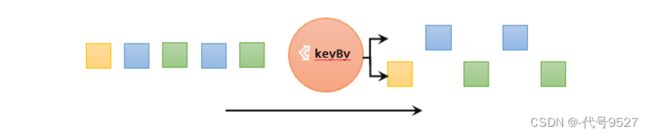
- 按键分区keyBy,返回的是一个KeyedStream键控流
- keyBy不是转换算子,不能设置并行度,只是对数据做一个重分区
- 在内部,是通过计算key的哈希值(hash code),对分区数进行取模运算来实现的。所以这里key如果是POJO的话,必须要自己重写hashCode()方法
关于keyBy分组和分区的关系:
- keyBy是对数据分组,保证相同key的数据在同一个分区
- 分区,一个子任务可以理解为一个分区
- 一个分区(子任务)中可以有多个分组
//演示以demo类的id字段来分类
public class TransKeyBy {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
// 方式一:使用Lambda表达式
KeyedStream<WaterSensor, String> keyedStream = stream.keyBy(t -> t.id);
// 方式二:使用匿名类实现KeySelector
KeyedStream<WaterSensor, String> keyedStream1 = stream.keyBy(new KeySelector<WaterSensor, String>() {
@Override
public String getKey(WaterSensor e) throws Exception {
return e.id;
}
});
//分区后继续做你需要的聚合
env.execute();
}
}
- keyBy得到的结果将不再是DataStream,而是会将DataStream转换为KeyedStream
- KeyedStream泛型中第一个为流中的元素类型外,第二个是key的类型
- KeyedStream也继承自DataStream,所以基于它的操作也都归属于DataStream API
- 只有基于KeyedStream才可以做后续的聚合操作(比如sum,reduce)
5、聚合算子:简单聚合sum/min/max/minBy/maxBy
注意点:
- 在完成keyBy分组后,可以进行简单聚合
- sum/min/max/minBy/maxBy是KeyedStream类下的API,因此必须先完成分组
- 而简单聚合算子返回的,又变回了一个SingleOutputStreamOperator,即先分区、后聚合,得到的依然是一个DataStream
- 是分组内的聚合,即对同一个key的数据进行聚合,不会跨key聚合
关于这些API:
- sum():在分组内,对指定的字段做叠加求和
- min():在分组内,对指定的字段求最小值
- max():在分组内,对指定的字段求最大值
- minBy():与min类似,区别是,min只计算指定字段的最小值,其他字段会保留最初第一条数据的值,而minBy则是字段最小值所在的整条数据。也就是除了指定字段,其他字段以谁为准的区别。
- maxBy():与max类似,区别同上
public class TransAggregation {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
stream.keyBy(t -> t.id).max("vc"); // 指定字段名称
//stream.keyBy(t -> t.id).max(2); //报错
env.execute();
}
}
注意,这几个聚合算子的传参有两种:指定位置,和指定名称,对于元组类型的数据,两种都行。但如果数据流中的类型不是元组,而是一个pojo类,那就只能通过字段名来指定,而不能传一个位置,否则报错Cannot reference field by position on POJO
一个聚合算子,会为每一个key保存一个聚合的值,在Flink中我们把它叫作“状态”(state)。所以每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以我们使用聚合算子,应该只用在含有有限个key的数据流上。
6、聚合算子:归约聚合reduce
public class TransFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_1", 3, 3),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
// 传入匿名类实现ReduceFunction
stream.reduce(new ReduceFunction<WaterSensor>() {
@Override
public boolean reduce(WaterSensor value1, WaterSensor value2) throws Exception {
System.out.println("value1===" + value1);
System.out.println("value2===" + value2);
return new WaterSensor(value1.getId(),value2.getTs(),value1.getVc() + value2.getVc());
}
}).print();
env.execute();
}
}
运行:

总结:
-
reduce算子依旧是keyBy之后KeyedStream的API
-
该算子传入一个ReduceFunction对象,要求数据的输入类型等于输出类型

-
ReduceFunction接口的reduce方法,value1和value2是流中某key分组的两个数据,
中途,value1是之前的计算结果(存状态,有状态计算),value2是后面新来的数据 -
每个key的分组里第一条数据来的时候,不会执行reduce方法,只是存起来,然后就发到下游了
-
reduce算子和前面的简单算子一样,会存每一个key的状态值,且状态不会清空,因此,如果是无界流,其key值要有限个
7、用户自定义函数:函数类
自定义函数,即用户根据自己的需求,重新实现算子的逻辑。Flink暴露了所有UDF函数的接口,具体实现方式为接口或者抽象类,例如MapFunction、FilterFunction、ReduceFunction等。所以用户可以自定义一个函数类,实现对应的接口。
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
DataStream<String> stream = stream.filter(new FilterFunctionImpl("sensor_1")); //new对象的时候传入str,通过构造方法赋值给了id属性
public class FilterFunctionImpl implements FilterFunction<WaterSensor> {
private String id;
FilterFunctionImpl(String id) {
this.id=id;
}
@Override
public boolean filter(WaterSensor value) throws Exception {
return thid.id.equals(value.id); //当前对象的id属性
}
}
关于函数类,写实现类、Lambda表达式、匿名内部类等方式重写算子对应的接口,前面已经演示过,上面重点改良了一下代码,把过滤关键字做为类的属性,通过构造方法传了进去。
8、用户自定义函数:富函数类
富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,可以实现更复杂的功能。
public class RichFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.fromElements(1,2,3,4)
.map(new RichMapFunction<Integer, Integer>() {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("索引是:" + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期开始");
}
@Override
public Integer map(Integer integer) throws Exception {
return integer + 1;
}
@Override
public void close() throws Exception {
super.close();
System.out.println("索引是:" + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期结束");
}
})
.print();
env.execute();
}
}
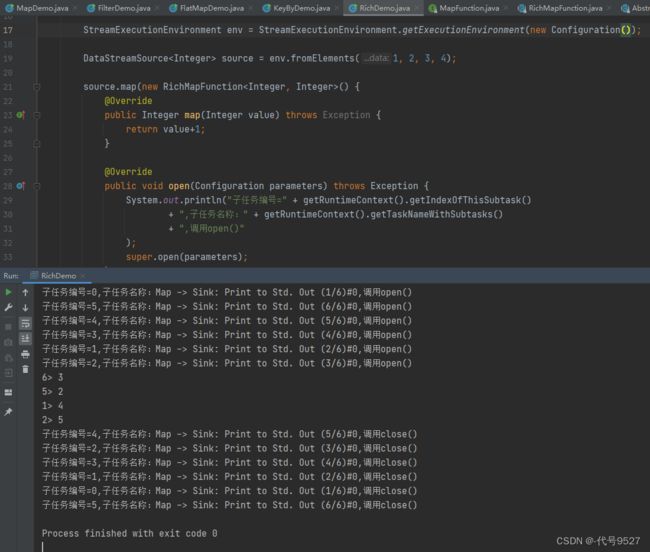
生命周期的方法即:
- open():每个子任务,在启动时,调用一次
- close():每个子任务,在结束时,调用一次
但需要注意:
-
当一个算子的实际工作方法例如map()或者filter()方法被调用之前,open()会首先被调用
-
处理有界流,处理完以后程序运行结束,调用close
-
处理无界流,程序中止时调用close
-
如果Flink是异常中止,则不会调用close
-
如果是正常调用cancle命令(控制台去cancle),则会正常调用close方法
关于富函数:
- 相比普通的自定义函数类,富函数多了一个运行时上下文对象,可通过这个对象获取到运行时环境的信息,比如子任务编号、子任务名称
- 有的Flink函数类都有其Rich版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction等
- 处理数据需求有时机要求时,可使用富函数