ORC文件存储格式和数据写入过程
文章目录
- ORC 文件格式,配置参数及相关概念
-
- ORC 文件格式
- UML类图
- OrcFile writer 创建
- OrcFile Writer 配置参数
- 相关概念
- 动态数组 DynamicIntArray 和 DynamicByteArray
-
- 初始化
- chunk 扩容
- OrcFile writer的 write()方法 写数据
-
- WriterImpl addRow程序入口
- StringTreeWriter : void write(Object obj)
- StringTreeWriter 内部数据存储结构
- 使用红黑树来做 dictionary
- OutStream 管理
-
- 使用 StreamFactory 创建 BufferedStream
- BufferedStream 数据写入 | RowIndexEntry 创建和管理
-
- recordDirectStreamPosition()
- ORC物理文件写入
-
- MemoryManager 的 checkMemory
- ORC 建立 OutputStream 输出文件
-
- getStream() 方法调用入口:
- OutputStream 说明:
- Stripe 数据写入
- String Dictionary
- RunLengthIntegerWriterV2
- 参考文献
ORC 文件格式,配置参数及相关概念
ORC 文件格式

Stripe:
MAGIC
stripe1 {
data
index
footer
},
stripe2 {
data
index
footer
},
...
metadata
footer
PostScript + size(PostScript)
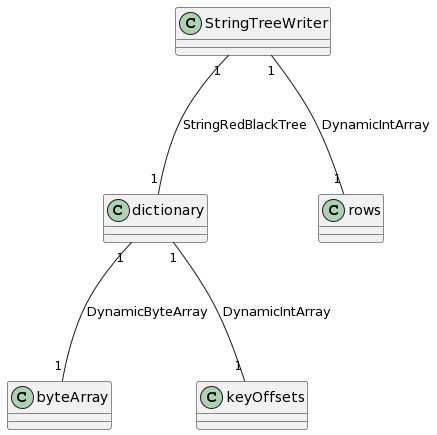
UML类图
部分关联类的调用关系

OrcFile writer 创建
通过 OrcFile.createWriter()静态方法设置写文件参数,生成一个WriterImpl对象来写ORC文件。
Writer writer = OrcFile.createWriter()
OrcFile Writer 配置参数
- opts.configuration,
- opts.inspectorValue, : 借用hive serde2 中的ObjectInspector 来解析 ROW,确定文件Schema
- opts.stripeSizeValue (default = 64L * 1024 * 1024) : Writer 操作单元,stripe 内容先写入内存,内存满了之后Flush到磁盘
- opts.compressValue (default = ZLIB) : 允许的压缩方式 CompressionKind(NONE, ZLIB, * SNAPPY, LZO)
- opts.bufferSizeValue (default = 256 * 1024) : memory buffers 大小
- opts.rowIndexStrideValue (default = 10000) : Stride is the number of rows an index entry represents.
- opts.memoryManagerValue, : 默认取当前Heap Max Size 的一半作为 totalMemoryPool
- opts.blockPaddingValue,
- opts.versionValue,
- opts.callback, : when the stripe and file are about to be closed,flush 磁盘,默认还是* 调用在 WriterImpl.checkMemory() 方法
- opts.encodingStrategy,
- opts.compressionStrategy,
- opts.paddingTolerance,
- opts.blockSizeValue
相关概念
- Writer : 一个Path对应一个Writer,并根据Path 去重
动态数组 DynamicIntArray 和 DynamicByteArray
动态数组是ORC 读写文件中非常重要的一步,设计的目的是 memory optimization,具有如下特点:
- 数据分chunks管理,当发生 resizes 操作的时候,只需要移动部分数据即可;
- space efficient storage of potentially huge arrays without good a-priori size guesses;
- API 介于 array 和 AbstractList之间
- DynamicIntArray 和 DynamicByteArray 类似,却别在于一个内存存储Int,一个存储Byte.
下面以 DynamicIntArray 为例。
初始化
DEFAULT_CHUNKSIZE = 8 * 1024
data = new int[128][];
- chunk初始个数 128个,每个ChunkSize 为 8192
- 增删改查操作需要根据 index,计算出对应的chunk 和在该chunk 内的偏移量来操作数据
- 当chunk个数不够的时候,将chunk个数 double一下,申请新的二维数组再来管理
- 内存空间的分配是根据当前使用到的最大 chunkIndex 需要来分配的,不会造成资源浪费。
data[0] : 0 - 8191
data[1] : 8192 - 16384
...
data[n] :
chunk 扩容
/**
* Ensure that the given index is valid.
*/
private void grow(int chunkIndex) {
if (chunkIndex >= initializedChunks) {
if (chunkIndex >= data.length) {
int newSize = Math.max(chunkIndex + 1, 2 * data.length);
int[][] newChunk = new int[newSize][];
System.arraycopy(data, 0, newChunk, 0, data.length);
data = newChunk;
}
for (int i=initializedChunks; i <= chunkIndex; ++i) {
data[i] = new int[chunkSize];
}
initializedChunks = chunkIndex + 1;
}
}
OrcFile writer的 write()方法 写数据
WriterImpl addRow程序入口
这里是后面程序入口,后面均会有介绍:
- treeWriter 写数据
- RowIndexEntry 管理
- memoryManager 内存管理
- Stripe 生成(flushStripe)
@Override
public void addRow(Object row) throws IOException {
synchronized (this) {
// 这里只是做 indexStatistics,NULL,bit位的一些统计
treeWriter.write(row);
rowsInStripe += 1;
if (buildIndex) {
rowsInIndex += 1;
// rows
if (rowsInIndex >= rowIndexStride) {
createRowIndexEntry();
}
}
}
memoryManager.addedRow();
}
StringTreeWriter : void write(Object obj)
// StringTreeWriter
@Override
void write(Object obj) throws IOException {
super.write(obj); // 父类TreeWriter 为抽象类,只做一些 indexStatistics 统计等抽象操作
if (obj != null) {
Text val = getTextValue(obj);
if (useDictionaryEncoding || !strideDictionaryCheck) {
rows.add(dictionary.add(val));
} else {
// write data and length
directStreamOutput.write(val.getBytes(), 0, val.getLength());
directLengthOutput.write(val.getLength());
}
indexStatistics.updateString(val);
}
}
- 未使用字典压缩(useDictionaryEncoding=false) 且 已经做了是否使用字典检查(strideDictionaryCheck =true)
- 不需要使用字典
- 将data and length直接写入OutStream,至于 directStreamOutput 和 directLengthOutput 后面会有详细介绍
- 不需要使用字典
- 否则调用
rows.add(dictionary.add(val));- dictionary.add(val) : 使用红黑树存储当前字符串的bytes值
- rows.add(dictionary.add(val)); : 元素存储在dictionary中的offset
StringTreeWriter 内部数据存储结构
例如,现在要写入两个字符串,01和234(因为对象的存储最终会存储该对象Writable方法的UDF-8编码 chars,所以使用数字字符串来理解);
-
内部数据存储结构
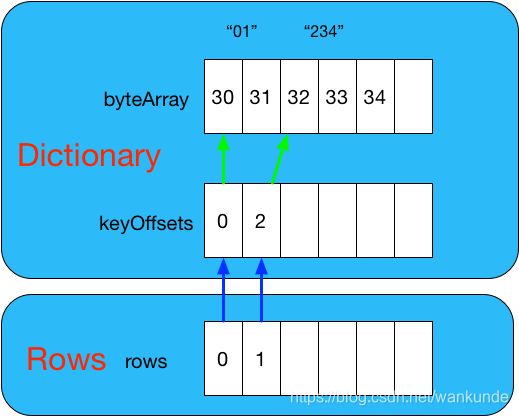
-
StringTreeWriter 中数据存储
使用红黑树来做 dictionary
- 如果 newKey 在 红黑树中不存在:
- add() 返回true,
- 将newKey的bytes数据存入byteArray
- 将数据在 byteArray中的offset 存入 keyOffsets
// StringRedBlackTree
private int addNewKey() {
// if the newKey is actually new, add it to our byteArray and store the offset & length
if (add()) {
int len = newKey.getLength();
keyOffsets.add(byteArray.add(newKey.getBytes(), 0, len));
}
return lastAdd;
}
OutStream 管理
使用 StreamFactory 创建 BufferedStream
以StringTreeWriter 创建的Stream为例
private final StreamFactory streamFactory = new StreamFactory(); // 全局唯一 streamFactory
treeWriter = createTreeWriter(inspector, streamFactory, false);
new StringTreeWriter(streamFactory.getNextColumnId(), inspector, streamFactory, nullable); // 根据 inspector.getCategory() 类型创建对应的TreeWriter
super(columnId, inspector, writer, nullable); // 调用父类 TreeWriter() 构造方法
rowIndexStream = streamFactory.createStream(id, OrcProto.Stream.Kind.ROW_INDEX); // 因为 HIVE_ORC_DEFAULT_ROW_INDEX_STRIDE(“hive.exec.orc.default.row.index.stride”, 10000) 默认 stride > 0(Stride is the number of rows an index entry represents.) 所以创建 (id=0,ROW_INDEX) 类型 OutStream
在 StringTreeWriter 构造方法中创建其他三个Stream
-
根据 column 和 kind 创建 OutStream 对象,并在 streams 中记录,后续在 flushStripe() 方法中会处理所有的streams.
-
BufferedStream 中有两个对象,
OutStream outStream和List。output TreeWriters直接写数据到outStream;codeccompresses the data as buffers 存储在output; -
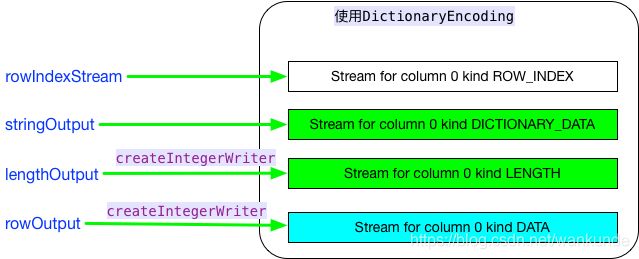
StringTreeWriter 内部Stream和引用对象关系
- 使用DictionaryEncoding
- 没有使用DictionaryEncoding
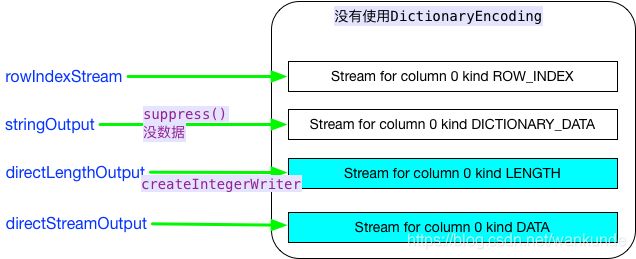
- 使用DictionaryEncoding
-
所有 TreeWriter 都有rowIndexStream
-
对于 LENGTH 类型的Stream 使用 createIntegerWriter 进行包装
-
对于 DATA 类型Stream,有createIntegerWriter的包装,也有Direct Stream
Column 可能创建的Stream 类型(OrcProto.Stream.Kind):
- DATA
- DICTIONARY_DATA
- LENGTH:
- DICTIONARY_COUNT:
- PRESENT:
- ROW_INDEX:
- SECONDARY:
BufferedStream 数据写入 | RowIndexEntry 创建和管理
- 当前IndexEntry 中记录数超过 10000 条,创建新的 IndexEntry,并添加到 rowIndex 中。
- OutStream 的write方法先将需要write的数据写入到 ByteBuffer current 中;当 current 被写满后,开始 spill()
- 在 BufferedStream 中有一个List output来存储中间结果,spill() 其实就是将将 current 添加到 BufferedStream的 output中,然后重新申请一个新的ByteBuffer 。
StringTreeWriter : void createRowIndexEntry() | void writeStripe()
private void flushDictionary() {
....
final int[] dumpOrder = new int[dictionary.size()];
if (useDictionaryEncoding) {
// Write the dictionary by traversing the red-black tree writing out
// the bytes and lengths; and creating the map from the original order
// to the final sorted order.
// 对red-black tree中所有node调用visit方法,将数据写入到 BufferedStream
dictionary.visit(new StringRedBlackTree.Visitor() {
private int currentId = 0;
@Override
public void visit(StringRedBlackTree.VisitorContext context
) throws IOException {
// 将red-black tree 中当前节点写入 stringOutput : DICTIONARY_DATA
context.writeBytes(stringOutput);
// 将当前节点长度写入 lengthOutput : LENGTH
lengthOutput.write(context.getLength());
// 当前节点在树中的位置,
dumpOrder[context.getOriginalPosition()] = currentId++;
}
});
} else {
// for direct encoding, we don't want the dictionary data stream
stringOutput.suppress();
}
int length = rows.size();
int rowIndexEntry = 0;
OrcProto.RowIndex.Builder rowIndex = getRowIndex();
Text text = new Text();
// write the values translated into the dump order.
for(int i = 0; i <= length; ++i) {
// now that we are writing out the row values, we can finalize the
// row index
if (buildIndex) {
// 对于每个 RowIndex,将base 对象包装为PositionRecorder,并调用当前recorder的position
while (i == rowIndexValueCount.get(rowIndexEntry) &&
rowIndexEntry < savedRowIndex.size()) {
OrcProto.RowIndexEntry.Builder base =
savedRowIndex.get(rowIndexEntry++).toBuilder();
if (useDictionaryEncoding) {
rowOutput.getPosition(new RowIndexPositionRecorder(base));
} else {
PositionRecorder posn = new RowIndexPositionRecorder(base);
directStreamOutput.getPosition(posn);
directLengthOutput.getPosition(posn);
}
// base.build() 创建一个 RowIndexEntry 实例,再添加到 rowIndex
rowIndex.addEntry(base.build());
}
}
if (i != length) {
if (useDictionaryEncoding) {
// 如果使用字典压缩,因为dictionary数据已经全部写出,只需要将对应数据在stringOutput : DICTIONARY_DATA 中的数组dumpOrder的下标即可
rowOutput.write(dumpOrder[rows.get(i)]);
} else {
// 如果不使用字典,将 text 值,写入 directStreamOutput,将 text length 写入 directLengthOutput
dictionary.getText(text, rows.get(i));
directStreamOutput.write(text.getBytes(), 0, text.getLength());
directLengthOutput.write(text.getLength());
}
}
}
rows.clear();
}
recordDirectStreamPosition()
在flush 完数据后,在下面的recordDirectStreamPosition() 方法中
- directStreamOutput中position
- codec = null 记录 uncompressedBytes
- codec != null 记录 compressedBytes, uncompressedBytes
- 记录 directLengthOutput 中position
- 因为是RunLengthIntegerWriterV2,先记录和上面一个的 position
- 再补充记录一个 numLiterals
ORC物理文件写入
MemoryManager 的 checkMemory
通过addRow() 方法入口,每5000条记录,检查一下内存使用是否超出 limit 限制,超出限制后,调用 flushStripe()
@Override
public synchronized boolean checkMemory(double newScale) throws IOException {
long limit = (long) Math.round(adjustedStripeSize * newScale);
long size = estimateStripeSize();
...
if (size > limit) {
flushStripe();
return true;
}
return false;
}
ORC 建立 OutputStream 输出文件
输出流的建立时机发生在checkMemory满足条件 或 close() 文件时,调用 flushStripe()方法。
getStream() 方法调用入口:
- void close()
- void flushStripe()
- int writeMetadata(long bodyLength)
- int writeFooter(long bodyLength)
- OrcFileMergeOperator : void processKeyValuePairs(Object key, Object value)
- void appendStripe(byte[] stripe, int offset, int length,StripeInformation stripeInfo,OrcProto.StripeStatistics stripeStatistics)
OutputStream 说明:
- rawWriter : 对应HDFS 文件 writer
- writer 和 protobufWriter:
- DirectStream : 包装 rawWriter,增加向outputStrema 写 ByteBuffer功能
- write() 方法将数据写入 current 中
- 在 spill() 和 flush() 方法中调用 codec.compress(current, compressed, overflow),再将 compressed 数据写出
- CodedOutputStream protobufWriter : 使用protobuf 包装 writer,增强写入BUFFER功能。
- 每次 protobufWriter flulsh之后,会同步flush writer。
@VisibleForTesting
FSDataOutputStream getStream() throws IOException {
if (rawWriter == null) {
rawWriter = fs.create(path, false, HDFS_BUFFER_SIZE,
fs.getDefaultReplication(), blockSize);
rawWriter.writeBytes(OrcFile.MAGIC);
headerLength = rawWriter.getPos();
writer = new OutStream("metadata", bufferSize, codec,
new DirectStream(rawWriter));
protobufWriter = CodedOutputStream.newInstance(writer);
}
return rawWriter;
}
Stripe 数据写入
- 将streams中的数据全部flush到ByteBuffer List中
- 依次将 streams 中各个Stream 中数据写入到文件,实现列存储
- 写入 footer
- build StripeInformation 对象,包括 Offset,rowsInStripe,indexSize,dataSize,footerLength
- rowCount
private void flushStripe() throws IOException {
getStream();
if (buildIndex && rowsInIndex != 0) {
createRowIndexEntry();
}
if (rowsInStripe != 0) {
if (callback != null) {
callback.preStripeWrite(callbackContext);
}
// finalize the data for the stripe
int requiredIndexEntries = rowIndexStride == 0 ? 0 :
(int) ((rowsInStripe + rowIndexStride - 1) / rowIndexStride);
OrcProto.StripeFooter.Builder builder =
OrcProto.StripeFooter.newBuilder();
treeWriter.writeStripe(builder, requiredIndexEntries);
long indexSize = 0;
long dataSize = 0;
for(Map.Entry<StreamName, BufferedStream> pair: streams.entrySet()) {
BufferedStream stream = pair.getValue();
if (!stream.isSuppressed()) {
stream.flush();
StreamName name = pair.getKey();
long streamSize = pair.getValue().getOutputSize();
builder.addStreams(OrcProto.Stream.newBuilder()
.setColumn(name.getColumn())
.setKind(name.getKind())
.setLength(streamSize));
if (StreamName.Area.INDEX == name.getArea()) {
indexSize += streamSize;
} else {
dataSize += streamSize;
}
}
}
OrcProto.StripeFooter footer = builder.build();
// Do we need to pad the file so the stripe doesn't straddle a block
// boundary?
long start = rawWriter.getPos();
final long currentStripeSize = indexSize + dataSize + footer.getSerializedSize();
final long available = blockSize - (start % blockSize);
final long overflow = currentStripeSize - adjustedStripeSize;
final float availRatio = (float) available / (float) defaultStripeSize;
if (availRatio > 0.0f && availRatio < 1.0f
&& availRatio > paddingTolerance) {
// adjust default stripe size to fit into remaining space, also adjust
// the next stripe for correction based on the current stripe size
// and user specified padding tolerance. Since stripe size can overflow
// the default stripe size we should apply this correction to avoid
// writing portion of last stripe to next hdfs block.
float correction = overflow > 0 ? (float) overflow
/ (float) adjustedStripeSize : 0.0f;
// correction should not be greater than user specified padding
// tolerance
correction = correction > paddingTolerance ? paddingTolerance
: correction;
// adjust next stripe size based on current stripe estimate correction
adjustedStripeSize = (long) ((1.0f - correction) * (availRatio * defaultStripeSize));
} else if (availRatio >= 1.0) {
adjustedStripeSize = defaultStripeSize;
}
if (availRatio < paddingTolerance && addBlockPadding) {
long padding = blockSize - (start % blockSize);
byte[] pad = new byte[(int) Math.min(HDFS_BUFFER_SIZE, padding)];
LOG.info(String.format("Padding ORC by %d bytes (<= %.2f * %d)",
padding, availRatio, defaultStripeSize));
start += padding;
while (padding > 0) {
int writeLen = (int) Math.min(padding, pad.length);
rawWriter.write(pad, 0, writeLen);
padding -= writeLen;
}
adjustedStripeSize = defaultStripeSize;
} else if (currentStripeSize < blockSize
&& (start % blockSize) + currentStripeSize > blockSize) {
// even if you don't pad, reset the default stripe size when crossing a
// block boundary
adjustedStripeSize = defaultStripeSize;
}
// 将 streams 中的List output 数据(Write the saved compressed buffers)写出到 rawWriter中
// write out the data streams
for(Map.Entry<StreamName, BufferedStream> pair: streams.entrySet()) {
BufferedStream stream = pair.getValue();
if (!stream.isSuppressed()) {
stream.spillTo(rawWriter);
}
stream.clear();
}
// write footer 数据
footer.writeTo(protobufWriter);
protobufWriter.flush();
// protobufWriter包装了writer,并增加了Buffer,所以需要同步flush writer
writer.flush();
long footerLength = rawWriter.getPos() - start - dataSize - indexSize;
OrcProto.StripeInformation dirEntry =
OrcProto.StripeInformation.newBuilder()
.setOffset(start)
.setNumberOfRows(rowsInStripe)
.setIndexLength(indexSize)
.setDataLength(dataSize)
.setFooterLength(footerLength).build();
// dirEntry 包含stripe 元数据信息
stripes.add(dirEntry);
rowCount += rowsInStripe;
rowsInStripe = 0;
}
}
@Override
public void close() throws IOException {
// remove us from the memory manager so that we don't get any callbacks
memoryManager.removeWriter(path);
// actually close the file
synchronized (this) {
flushStripe();
// 写入 treeWriter.stripeStatsBuilders 中所有Stripe metadata
int metadataLength = writeMetadata(rawWriter.getPos());
int footerLength = writeFooter(rawWriter.getPos() - metadataLength);
rawWriter.writeByte(writePostScript(footerLength, metadataLength));
rawWriter.close();
}
}
String Dictionary
RedBlackTree add() 方法
// RedBlackTree 和 StringRedBlackTree
// TODO 对应Int 类型红黑树的处理
/**
* Insert or find a given key in the tree and rebalance the tree correctly.
* Rebalancing restores the red-black aspect of the tree to maintain the
* invariants:
* 1. If a node is red, both of its children are black.
* 2. Each child of a node has the same black height (the number of black
* nodes between it and the leaves of the tree).
*
* Inserted nodes are at the leaves and are red, therefore there is at most a
* violation of rule 1 at the node we just put in. Instead of always keeping
* the parents, this routine passing down the context.
*
* The fix is broken down into 6 cases (1.{1,2,3} and 2.{1,2,3} that are
* left-right mirror images of each other). See Algorighms by Cormen,
* Leiserson, and Rivest for the explaination of the subcases.
*
* @param node The node that we are fixing right now.
* @param fromLeft Did we come down from the left?
* @param parent Nodes' parent
* @param grandparent Parent's parent
* @param greatGrandparent Grandparent's parent
* @return Does parent also need to be checked and/or fixed?
*/
private boolean add(int node, boolean fromLeft, int parent,
int grandparent, int greatGrandparent) {
if (node == NULL) {
if (root == NULL) {
lastAdd = insert(NULL, NULL, false);
root = lastAdd;
wasAdd = true;
return false;
} else {
lastAdd = insert(NULL, NULL, true);
node = lastAdd;
wasAdd = true;
// connect the new node into the tree
if (fromLeft) {
setLeft(parent, node);
} else {
setRight(parent, node);
}
}
} else {
int compare = compareValue(node);
boolean keepGoing;
// Recurse down to find where the node needs to be added
if (compare < 0) {
keepGoing = add(getLeft(node), true, node, parent, grandparent);
} else if (compare > 0) {
keepGoing = add(getRight(node), false, node, parent, grandparent);
} else {
lastAdd = node;
wasAdd = false;
return false;
}
// we don't need to fix the root (because it is always set to black)
if (node == root || !keepGoing) {
return false;
}
}
// Do we need to fix this node? Only if there are two reds right under each
// other.
if (isRed(node) && isRed(parent)) {
if (parent == getLeft(grandparent)) {
int uncle = getRight(grandparent);
if (isRed(uncle)) {
// case 1.1
setRed(parent, false);
setRed(uncle, false);
setRed(grandparent, true);
return true;
} else {
if (node == getRight(parent)) {
// case 1.2
// swap node and parent
int tmp = node;
node = parent;
parent = tmp;
// left-rotate on node
setLeft(grandparent, parent);
setRight(node, getLeft(parent));
setLeft(parent, node);
}
// case 1.2 and 1.3
setRed(parent, false);
setRed(grandparent, true);
// right-rotate on grandparent
if (greatGrandparent == NULL) {
root = parent;
} else if (getLeft(greatGrandparent) == grandparent) {
setLeft(greatGrandparent, parent);
} else {
setRight(greatGrandparent, parent);
}
setLeft(grandparent, getRight(parent));
setRight(parent, grandparent);
return false;
}
} else {
int uncle = getLeft(grandparent);
if (isRed(uncle)) {
// case 2.1
setRed(parent, false);
setRed(uncle, false);
setRed(grandparent, true);
return true;
} else {
if (node == getLeft(parent)) {
// case 2.2
// swap node and parent
int tmp = node;
node = parent;
parent = tmp;
// right-rotate on node
setRight(grandparent, parent);
setLeft(node, getRight(parent));
setRight(parent, node);
}
// case 2.2 and 2.3
setRed(parent, false);
setRed(grandparent, true);
// left-rotate on grandparent
if (greatGrandparent == NULL) {
root = parent;
} else if (getRight(greatGrandparent) == grandparent) {
setRight(greatGrandparent, parent);
} else {
setLeft(greatGrandparent, parent);
}
setRight(grandparent, getLeft(parent));
setLeft(parent, grandparent);
return false;
}
}
} else {
return true;
}
}
/**
* Add the new key to the tree.
* @return true if the element is a new one.
*/
protected boolean add() {
add(root, false, NULL, NULL, NULL);
if (wasAdd) {
setRed(root, false);
return true;
} else {
return false;
}
}
RunLengthIntegerWriterV2
TODO
参考文献
- ORC Talks
- ORC File and Vectorization
- LanguageManual ORC