基于区块链的分层联邦学习
分层联邦学习(HFL)在保留联邦学习(FL)隐私保护优势的同时,减轻了通信开销,具有高带宽和丰富计算资源的优点。当FL的工作人员或参数服务器不可信或恶意时,方法是使用分层联邦学习。
1.Semi-Asynchronous Hierarchical Federated Learning over Mobile Edge Networks
IEEE Access
QIMEI CHEN1, (Member, IEEE), ZEHUA YOU1, JING WU1, YUNPENG LIU1, and HAO JIANG1
2022
(端边云架构 先同步后异步 节点选择不是选择终端节点而是选择边缘节点 无区块链)
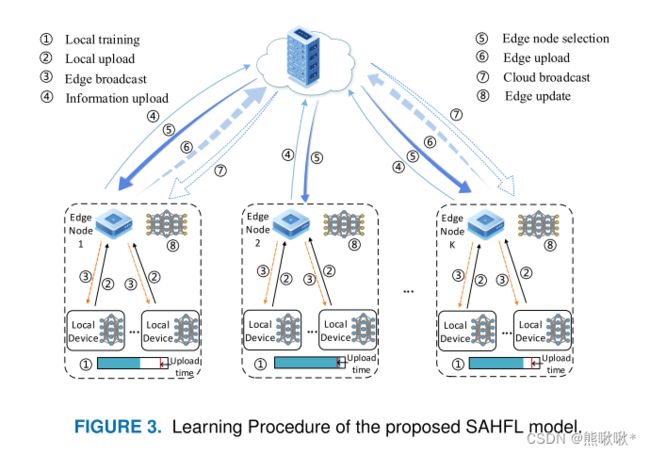
半异步分层联邦学习(SAHFL)框架,支持从数据感知到云模型的弹性边缘聚合。SAHFL框架,将本地-边缘的同步聚合模型和边缘-云的半异步聚合模型相结合。提出了一种分布式交替方向乘子法(ADMM)-块坐标更新(BCU)算法。利用该算法,可以在训练精度和传输时延之间取得折衷。
边缘模型聚合:同步聚合对更新后的模型进行平均。云聚合:在每轮中只能选择部分边节点。  = 1表示边节点k已被选中。
= 1表示边节点k已被选中。
2.FedAT: A High-Performance and Communication-Efficient Federated Learning System with Asynchronous Tiers
Zheng Chai Yujing Chen Ali Anwar
2021
(层内同步更新局部模型参数,在层间异步更新全局模型 无区块链)
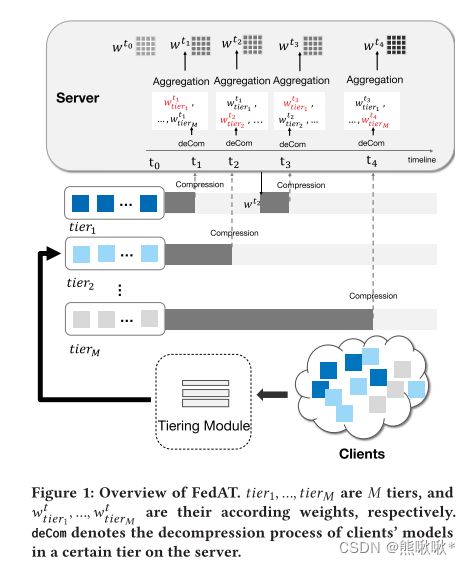
提出了一种新的加权聚集启发式算法,为较慢的层分配较高的权重。FedAT,它在层内同步更新局部模型参数,在层间异步更新全局模型。FEDAT由三个主要组件组成:集中式服务器;客户机;分层模块。
每一层进行同步更新过程,随机选择一小部分客户机,计算其本地数据的丢失梯度,然后将压缩后的权值发送给服务器进行同步更新,并在服务器上更新层模型。客户机迅速完成本地训练,压缩训练后的模型并发送到服务器。 服务器执行:解压缩;得到1 1,生成新的全局模型1。加权聚合启发式算法,根据每个层更新全局模式的次数,动态调整分配给每个层的相对权重。
3.Efficient Asynchronous Federated Learning Research in the Internet of Vehicles
IEEE Internet of Things Journal
Zhigang Yang, Member, IEEE, Xuhua Zhang, Dapeng Wu, Senior Member, IEEE, Ruyan Wang, Puning Zhang,
Member, IEEE, and Yu Wu.
2022
(端边云架构 )
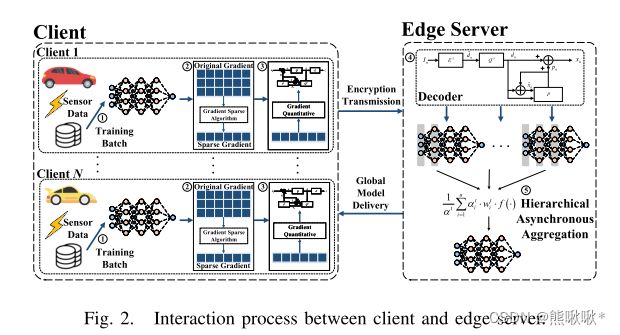
提出了一种高效的分层异步联邦学习(EHAFL)算法,该算法可以根据带宽动态调整编码长度,从而大大降低通信开销。
边缘服务器接收到客户端上传的梯度参数后,开始基于新鲜权重因子进行异步聚合,云服务器等待边缘服务器的梯度传输到达后进行同步聚合。由于参与训练的客户端数据不断变化,因此最近更新的模型应在聚合中给予更多权重。设计了一个权重方程来评估模型的新鲜度,当车辆在多轮通信中没有上传模型梯度时,分配一个新鲜度因子来增加客户端的梯度权重。。
4.FedDual: Pair-Wise Gossip Helps Federated Learning in Large Decentralized Networks
IEEE Transactions on Information Forensics and Security
Qian Chen , Zilong Wang , Member, IEEE, Hongbo Wang , and Xiaodong Lin , Fellow, IEEE
2023
提出了一种异步分层局部梯度聚合和全局模型更新算法FedDual。FedDual通过一个成对的gossip算法异步和分层地聚合局部梯度,并在每个客户端上本地更新全局模型。
我们考虑单个分散的地理集群中的FL过程,该地理集群包括n个客户端的子组。聚合目标是以分散和异步的方式计算局部梯度的加权平均值,客户端以分散的方式聚集它们的局部梯度,并且通过执行梯度下降算法来更新局部模型,局部模型聚合权重Pi与数据集有关。所有客户端周期性地执行上述局部训练、梯度聚集和全局模型更新过程,直到全局损失函数收敛到最优结果。
5.VFLChain: Blockchain-enabled Vertical Federated Learning for Edge Network Data Sharing
Ziwen Cheng Yongqi Pan Yi Liu
2022
(有区块链,部署在终端设备,使用智能合约)
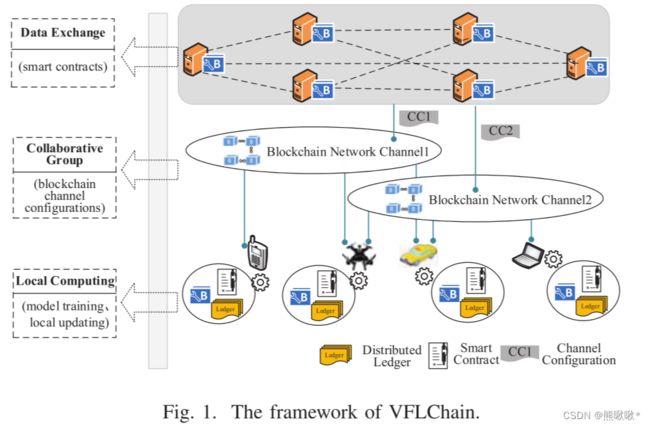
本文提出了一种增强隐私和智能保护的数据共享系统VFLChain。VFLChain基于联盟区块链和垂直联邦学习技术,实现数据共享。
将区块链技术集成到边缘计算和物联网设备中,并在边缘服务器中嵌入区块链通道配置,增强了物联网边缘数据共享的安全性和可信性。边缘服务器:嵌入了联盟区块链组件,为物联网终端设备提供辅助计算资源,如运行智能合约。区块链配置:允许参与者加入同一任务通道,形成临时协作组。物联网设备:在本地训练模型,并通过调用智能合约进行联合建模来共享学习结果。
6.Two-Phase Deep Reinforcement Learning of Dynamic Resource Allocation and Client Selection for Hierarchical Federated Learning
Xiaojing Chen1,2, Zhenyuan Li1, Wei Ni3, Xin Wang1,4, Shunqing Zhang1, Shugong Xu1, and Qingqi Pei2
2022
(无区块链,典型的云-边-端架构)
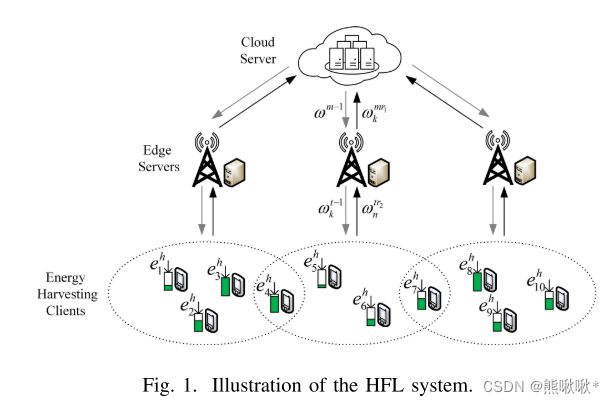
提出了一种新的两阶段深度确定性策略梯度框架,称为“ TPDDPG”,平衡学习延迟和模型精度。
一个云服务器,一组边缘服务器 K ,一组由可再生能源供电的客户端 N。在第m轮云聚合中,云服务器将全局模型 ωm-1分发给所有边缘服务器。HFL 系统对每个云聚合进行 r1轮边缘聚合。在 边聚合中,进行资源分配和客户端调度决策。新的基于掉队者感知的客户端关联和带宽分配算法来有效地优化其他决策,优化了 HFL 系统的学习延迟和模型精度。
7.Participant Selection for Hierarchical Federated Learning in Edge Clouds
Xinliang Wei, Jiyao Liu, Xinghua Shi, Yu Wang
2022
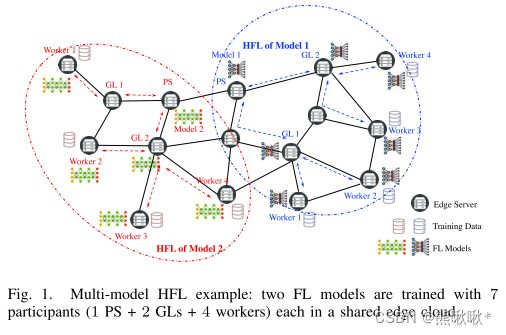
考虑并行HFL,并行训练多个FL模型。用一些中间层聚合器(或称为组领导者)来聚合来自工人的本地模型更新,并将组模型更新发送到参数服务器。每个模型需要从边缘服务器中选择一个参数服务器、几个组长和一定数量的工作者共同执行HFL。
所选择的GL和工人分别从PS及其GL下载全局模型,持续固定的局部迭代,工人将更新的模型和相关梯度上载到他们的GL用于组聚合,在GL处进行ϱj组聚合后,每个GL将组模型上传到PS进行聚合,以更新全局模型。
8.Accelerating Federated Learning with Cluster Construction and Hierarchical Aggregation
IEEE Transactions on Mobile Computing
Zhiyuan Wang, ∗Hongli Xu, Member, IEEE, Jianchun Liu, Student Member, IEEE,
Yang Xu, Member, IEEE, He Huang, Member, IEEE, ACM, Yangming Zhao
2022
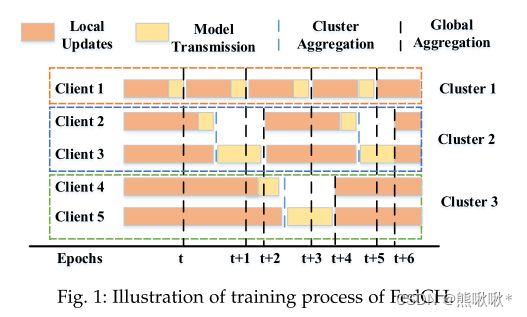
提出了一种高效的FL机制FedCH,用于加速异构边缘计算中的FL。FedCH将构建一个特殊的簇拓扑结构,并对训练进行分层聚合。簇中的客户端将其本地更新同步转发到簇头进行聚合,而所有簇头采用异步方法进行全局聚合。为了加速联邦学习,我们提出了有效的算法来确定资源约束下的最优簇数,并构造层次聚合的簇拓扑结构。
在H次迭代之后,本地模型转发到所选群首节点(表示为LNk)以进行聚合。参数服务器接收到一个模型后立即执行全局聚合。通过陈旧性感知全局更新方法,服务器在t 时期更新全局模型。对于簇k,其陈旧度被定义为自其最后一次全局更新以来经历的迭代的数目。模型的权值随着陈旧度的增加而迅速下降。每个簇的模型权重会随着簇数目的增加而下降。
9.Blockchain Assisted Decentralized Federated Learning (BLADE-FL): Performance Analysis and Resource Allocation
IEEE Transactions on Parallel and Distributed Systems
Jun Li , SeniorMember, IEEE, Yumeng Shao , Kang Wei , Ming Ding , SeniorMember, IEEE,
Chuan Ma, Member, IEEE, Long Shi , Member, IEEE, Zhu Han , Fellow, IEEE, and
H. Vincent Poor, Life Fellow, IEEE
2022
(不是分层架构 只有客户端 区块链部署在终端进行验证)
本文提出一种区块链辅助去中心化联邦学习(BLADE-FL),评估了BLADE-FL的学习性能,探讨了懒惰客户对BLADE-FL学习性能的影响。共识机制验证区块内的数据,并确保参与区块链的所有节点存储相同的数据。节点验证新区块,并将验证过的区块添加到现有区块链中。
Blade-FL系统由N个客户端组成在BLADE-FL系统中,客户端既充当训练器又充当矿工。作为训练者训练本地模型,然后将本地模型作为区块链的请求交易广播到整个网络。作为矿工挖掘包含所有准备聚合的局部模型的块。
10.InFEDge: A Blockchain-Based Incentive Mechanism in Hierarchical Federated Learning for End-Edge-Cloud Communications
IEEE Journal on Selected Areas in Communications
Xiaofei Wang , Senior Member, IEEE, Yunfeng Zhao ,Chao Qiu , Member, IEEE,Zhicheng Liu ,
Jiangtian Nie, Member, IEEE, and Victor C. M. Leung , Life Fellow, IEEE
2022
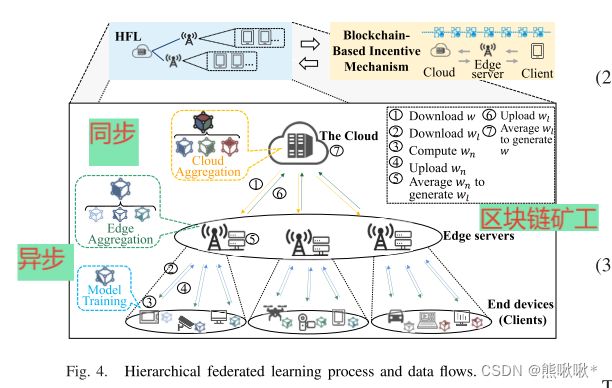
在HFL框架中,系统开销和模型性能难以平衡-------引入激励机制。多维属性、信息不完整和参与者不可靠等局限性会显著降低所设计机制的性能和效率-------提出了InFEDge。
区块链:永久记录相关信息(例如,多维个体属性)和双方之间的交易,引入基于区块链的激励机制。HFL中的学习过程:Tw个局部更新之后边缘服务器聚集来自连接的客户端的模型参数。Te个边缘模型聚合之后云服务器聚合模型参数。
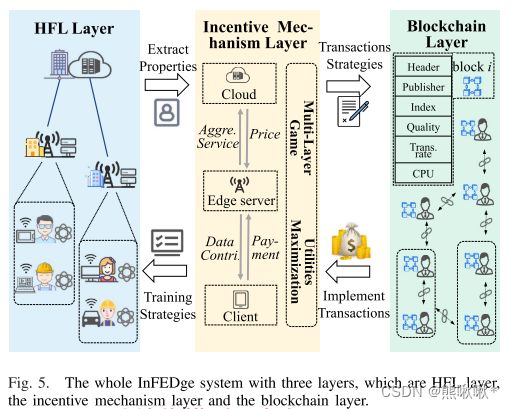
HFL层:参与者上传其关键参数更新到区块链,按照激励机制策略和经济激励策略来进行模型训练。区块链层:不仅验证和维护相关的更新,使用智能合约来实现激励机制。激励机制层:阅读相应的参数,计算出相应的策略,提供适当的经济激励。
11.BAFL: A Blockchain-Based Asynchronous Federated Learning Framework
Lei Feng , Member, IEEE, Yiqi Zhao, Shaoyong Guo , Xuesong Qiu , SeniorMember, IEEE,
Wenjing Li, and Peng Yu , SeniorMember, IEEE
2022
(不是端边云架构 区块链交叉验证信息)
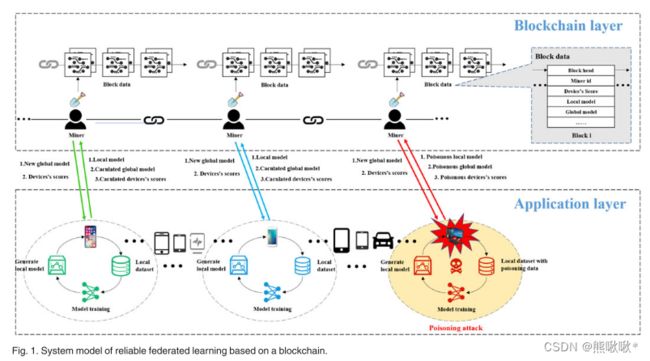
BAFL系统架构分为区块链层和应用层,每个设备都虚拟连接到区块链中的一个矿工,与设备相连的矿工充当设备的领导者,负责设备数据的上传和下载。在区块链层,分布式账本由所有矿工保管。区块链矿工是特定区块链网络的成员,并积极参与交易过程。他们通过自己的分布式分类账验证交易,并将模型和设备的分数存储在FL中。
设备的奖励与设备的分数线性相关,使用几个指标来评估设备的得分,例如数据大小,全局模型更新期间的错误数量以及历史得分。采用熵权法对指标权重进行估计。比较局部模型和全局模型之间每个参数的相关性,以确定局部训练性能 。
12.Two-Layered Blockchain Architecture for Federated Learning over Mobile Edge Network
Lei Feng∗, Member, IEEE, Zhixiang Yang∗, Shaoyong Guo∗†, Xuesong Qiu∗, Senior Member, IEEE, Wenjing Li∗,Peng Yu∗, Member, IEEE
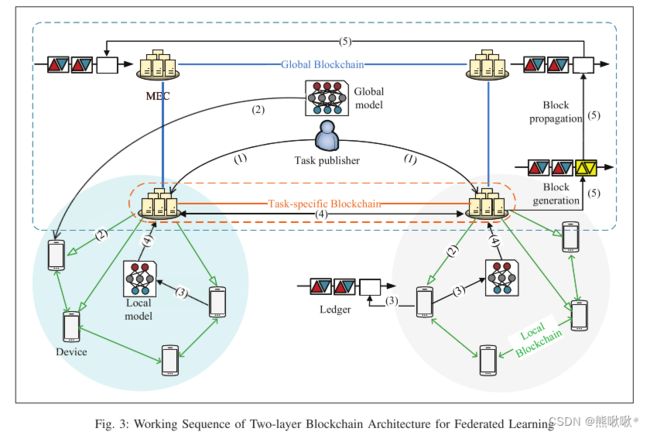
提出了一个区块链和FL融合框架,以管理在移动边缘网络上应用FL时的安全性和信任问题。由两种类型的区块链组成的两层体系结构: 由设备到设备 (D2D) 通信辅助的本地模型更新链 (LMUC) 和支持任务分片的全局模型更新链 (GMUC)。引入了基于声誉学习的激励机制,以使参与者本地设备对智能合约实现的奖励更加信任。MUC中的块用于记录FL参与者的本地模型更新结果,这有助于形成本地设备的长期声誉。GMUC通过防止MEC节点发生故障并将其划分为逻辑隔离的FL任务特定链来提供安全性和效率。
选择设备的过程:首先,每个MEC节点或本地设备需要注册到LMUC,并为它们中的每一个生成身份公钥/私钥对。其次,任务发布者生成请求提交事务,将事务广播到LMUC。如果资源可用,则生成包括资源信息和声誉意见的响应交易并将其广播到LMUC。根据交互历史和资源信息中的声誉意见,选择参与FL计算任务的本地设备。
基于智能合约的激励策略:将存储在GMUC中的声誉的历史统计信息以及FL任务发布者记录的设备的行为用作输入,以形成经过深度学习的网络。此网络的输出是本地设备的群集。如果参与的负载设备未能完成学习任务或行为不当,则设备将不会获得奖励。正确的群集设备可以获得更大的声誉值。