HashMap为什么要先插入再扩容JDK1.8
我们知道 HashMap 的底层是由数组,链表,红黑树组成的,在 HashMap 做扩容操作时,除了把数组容量扩大为原来的两倍外,还会对所有元素重新计算 hash 值,因为长度扩大以后,hash值也随之改变。(jdk1.7是先扩容再插入)
如果是简单的 Node 对象,只需要重新计算下标放进去就可以了,如果是链表和红黑树,那么操作就会比较复杂,下面我们就来看下,JDK1.8 下的 HashMap 在扩容时对链表和红黑树做了哪些优化?
rehash 时,链表怎么处理?
假设一个 HashMap 原本 bucket 大小为 16。下标 3 这个位置上的 19, 3, 35 由于索引冲突组成链表。
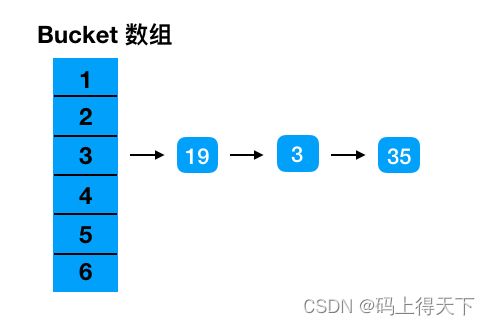
当 HashMap 由 16 扩容到 32 时,19, 3, 35 重新 hash 之后拆成两条链表。

查看 JDK1.8 HashMap 的源码,我们可以看到关于链表的优化操作如下:
// 把原有链表拆成两个链表
// 链表1存放在低位(原索引位置)
Node loHead = null, loTail = null;
// 链表2存放在高位(原索引 + 旧数组长度)
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
// 链表1
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 链表2
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 链表1存放于原索引位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 链表2存放原索引加上旧数组长度的偏移量
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
} 正常我们是把所有元素都重新计算一下下标值,再决定放入哪个桶,JDK1.8 优化成直接把链表拆成高位和低位两条,通过位运算来决定放在原索引处或者原索引加原数组长度的偏移量处。我们通过位运算来分析下。
先回顾一下原 hash 的求余过程:

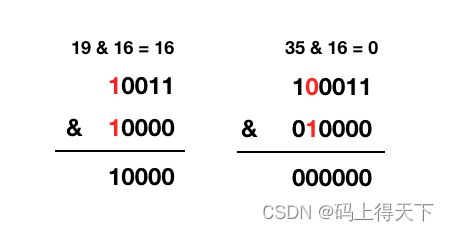
再看一下 rehash 时,判断时做的位操作,也就是这句 e.hash & oldCap:
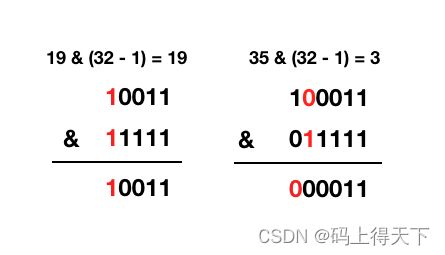
再看下扩容后的实际求余过程:
这波操作是不是很666,为什么 2 的整数幂 - 1可以作 & 操作可以代替求余计算,因为 2 的整数幂 - 1 的二进制比较特殊,就是一串 11111,与这串数字 1 作 & 操作,结果就是保留下原数字的低位,去掉原数字的高位,达到求余的效果。2 的整数幂的二进制也比较特殊,就是一个 1 后面跟上一串 0。
HashMap 的扩容都是扩大为原来大小的两倍,从二进制上看就是给这串数字加个 0,比如 16 -> 32 = 10000 -> 100000,那么他的 n - 1 就是 15 -> 32 = 1111 -> 11111。也就是多了一位,所以扩容后的下标可以从原有的下标推算出来。差异就在于上图我标红的地方,如果标红处是 0,那么扩容后再求余结果不变,如果标红处是 1,那么扩容后再求余就为原索引 + 原偏移量。如何判断标红处是 0 还是 1,就是把 e.hash & oldCap。
注意:
从上面的例子可以看出hashcode一样,元素位置肯定一样,hashcode不一样,元素的位置也可能一样,所以扩容后,链表的元素是可能分布在新数组的不同的位置的,因为它们的hashcode可能不一样。
rehash 时,红黑树怎么处理?
// 红黑树转链表阈值
static final int UNTREEIFY_THRESHOLD = 6;
// 扩容操作
final Node[] resize() {
// ....
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
// ...
}
final void split(HashMap map, Node[] tab, int index, int bit) {
TreeNode b = this;
// Relink into lo and hi lists, preserving order
// 和链表同样的套路,分成高位和低位
TreeNode loHead = null, loTail = null;
TreeNode hiHead = null, hiTail = null;
int lc = 0, hc = 0;
/**
* TreeNode 是间接继承于 Node,保留了 next,可以像链表一样遍历
* 这里的操作和链表的一毛一样
*/
for (TreeNode e = b, next; e != null; e = next) {
next = (TreeNode)e.next;
e.next = null;
// bit 就是 oldCap
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
// 尾插
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
// 树化低位链表
if (loHead != null) {
// 如果 loHead 不为空,且链表长度小于等于 6,则将红黑树转成链表
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
/**
* hiHead == null 时,表明扩容后,
* 所有节点仍在原位置,树结构不变,无需重新树化
*/
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
// 树化高位链表,逻辑与上面一致
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
} 从源码可以看出,红黑树的拆分和链表的逻辑基本一致,不同的地方在于,重新映射后,会将红黑树拆分成两条链表,根据链表的长度,判断需不需要把链表重新进行树化。
临界点情形一
假设当前插入节点是红黑树结构有7个, 如果先扩容后会有1个节点移到别的index索引时,导致当前红黑树的节点变成6个就会降级成链表再插入变成7个节点的链表。
而如果是先插入的话就是8个节点红黑树,然后扩容即使有1个节点移到别的位置也还是7个节点也不会转变成链表
而且即使大于7个节点的红黑树先扩容都有可能降成链表
而先扩容再插入时如果连续再插入2个相同索引位置的节点链表就又会变红黑树
临界点情形二
和情形一逻辑相反的情况,如果当前插入节点为8个且为链表的时候,如果先扩容后会有1个节点移到别的index索引时再插入还是8个节点链表不会变红黑树,而如果是先插入就会变成红黑树再扩容有1节点移动时变成8个节点的红黑树,如果此时移除节点又有可能降成链表,先分析下移除节点时降链表条件的源码
//这是移除时的部分源码
if (root == null || root.right == null || (rl = root.left) == null || rl.left == null) {
tab[index] = first.untreeify(map); // too small
return;
}
可以看出在移除节点的时候不一定是6个节点就会导致红黑树降级成链表,根据红黑树的特点有可能当前链表 3 <= Nodes <=6时才会降级成链表
而且只有链表为8个节点的时候先插入才会变红黑树
先插入再扩容时如果再连续移除最少2个最多5个节点的时候才又会降成链表
结论:通过以上两种临界情形对比,很明显如果先扩容再插入时频繁转变的概率要比先插入后扩容频繁转变的概率高
这里也给一个模拟HashMap造出红黑树的测试代码,红黑树为7个节点的时候,从64扩容到128时导致了key为64的节点移到第64的索引中去,而红黑树就变成了链表了
public static void main(String[] args) {
//默认64个大小hashMap,只要数组长度>=64, 且链表 》=8时时才会转红黑树
HashMap map = new HashMap<>(64);
map.put(0, "王二麻子 0");
map.put(64, "王二麻子 1");
map.put(128, "王二麻子 2");
map.put(256, "王二麻子 3");
map.put(512, "王二麻子 4");
map.put(1024, "王二麻子 5");
map.put(2048, "王二麻子 6");
map.put(4096, "王二麻子 7");
map.put(8192, "王二麻子 8");
//以上步骤就会生成在第0的索引上的一个9个节点的红黑树结构
map.remove(8192);
map.remove(4096);
//移除二个后此时是一个有7个节点的红黑树
//这一步添加41个其他位置上的节点,只要不在0节点上就行,让节点总数达到 64*0.75 = 48个
for (int i = 1; i <= 41; i++) {
map.put(i, "张三 " + i);
}
//插入第49个时触发扩容,此后红黑树结构就变成链表结构了
map.put(42, "李四");
}
————————————————
版权声明:本文为CSDN博主「程序猿锦鲤」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_68102643/article/details/124771393