Spring常用框架集
后端架构设计
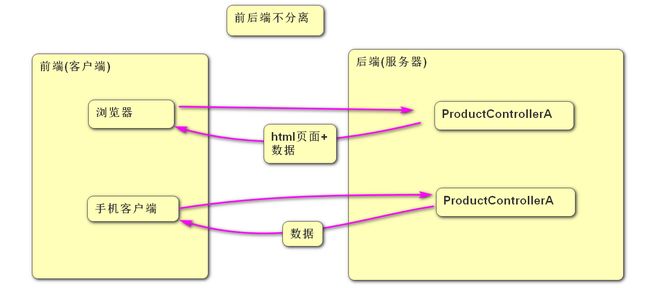
前后端不分离: 指在Controller中需要处理页面相关代码, 这样就把前端代码和后端代码混在一起了, 如果前端还包括手机端的话, 则需要再准备一套Controller, 这样的话对于后端Java程序员工作量就翻倍了,而且会有大量的重复代码
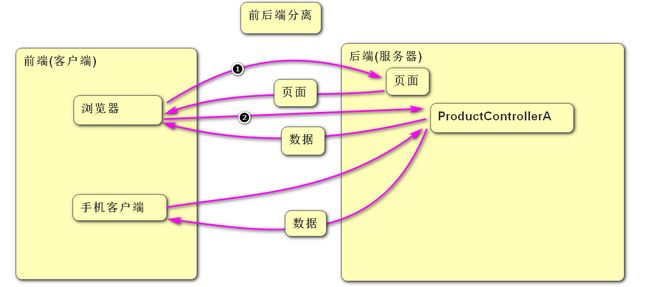
前后端分离: 指Controller中不再处理页面只提供数据, 不管前端是浏览器还是手机端都一视同仁只返回数据, 这样的话浏览器需要页面需要单独发一次请求获取. 这样的话java程序员只需要提供一套Controller即可 从而提高了开发效率
SpringBoot框架
如果不使用SpringBoot框架创建Maven工程, 工程里面如果需要添加其它框架, 除了需要在pom.xml文件中添加大量的依赖信息以外,很多的框架还需要有对应的xml配置文件,在xml配置文件中还需要书写大量的配置信息, 这些工作都需要程序员完成, 使用SpringBoot框架创建工程时,如果需要引入其它框架只需要通过打钩的方式即可把其它框架引入到自己的工程 不需要写配置文件,SpringBoot框架帮助程序员做好了其它工作
MyBatis框架
此框架是目前最流行的数据持久层框架, 框架可以帮助我们生成JDBC代码, 从而提高开发效率 .使用此框架程序员只需要通过注解或xml配置文件写好需要执行的SQL语句, Mybatis框架会自动生成对应的JDBC代码,同类型的框架还有Spring Data JPA、Hibernate等。
导入框架
IDEA创建工程的时候勾选Spring Web,Mybatis Framework,MySQL Driver 。或者在pom文件中添加依赖
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.2.2
mysql
mysql-connector-java
runtime
创建完工程后需要在application.properties 配置文件中添加连接数据库的信息
spring.datasource.url=jdbc:mysql//localhost:3306/databasename?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=rootMapper层interface
使用Mybatis框架时,访问数据的抽象方法必须定义在接口中,因为Mybatis框架是通过“接口代理”的设计模式,生成了接口的实现对象
扫描接口方式
【不推荐】在接口上添加@Mapper注解,这样导致每个数据访问接口上都需要此注解
【推荐】在配置类上添加@MapperScan注解,并配置Mapper接口所在的包
在根包下的任何类中添加了@Configuration注解的类都是配置类
只需要一次配置,各数据访问接口不必添加@Mapper注解
@Configuration
@MapperScan("xx.xx.xx.mapper")
public class MybatisConfiguration {
}接口方法
返回值类型:如果要执行的SQL操作是增、删、改类型的,使用int作为返回值类型,表示“受影响的行数”,不建议使用void,如果要执行的SQL操作是查询类型的,只需要保证返回值类型可以封装必要的结果即可,如果查询结果可能超过1条,必须使用List类型
方法名称:自定义的,但推荐遵循规范,不要使用重载
获取单个对象的方法用 get 做前缀
获取多个对象的方法用 list 做前缀
获取统计值的方法用 count 做前缀
插入的方法用 save / insert 做前缀
删除的方法用 remove / delete 做前缀
修改的方法用 update 做前缀
参数列表:取决于需要执行的SQL语句需要哪些参数,在抽象方法中,可以将这些参数一一列举出来,也可以将这些参数封装到自定义类中,使用自定义类作为抽象方法的参数
Mapper层xml
需要在application.properties中配置XML文件所在的位置
mybatis.mapper-locations=classpath:mapper/*.xml编写SQL语句位置
【不推荐】在Mapper接口的抽象方法上使用@Insert等注解来配置SQL语句,但不利于复用和DBA协作,切sql语句过于长不利于阅读
【推荐】在工程的resources文件中创建mapper文件,在里面创建xxxMapper.xml,在XML文件来配置SQL语句
编写xml文件
根标签必须是
,模板如下图
在
标签上必须配置namespace属性,此属性的值是接口的全路径名
在
标签内部,使用 / / /
必须配置resultType或resultMap这2个属性中的其中1个
resultType属性如果是对象则为全路径的类名,如果是基本类型则直接输入基本类型
会自动将列名(Column)与属性名(Property)相同的数据进行封装,例如,将查询结果集中名为name的数据封装到对象的name属性中,默认情况下,对于列名与属性名不同的数据,不予处理.如需对列名和属性名不同的数据做处理可以使用resultMap属性配置
标签,此标签的作用就是指导Mybatis将查询结果集中的数据封装到对象中
是可以复用的,如果另一个
中编写SQL语句,并且使用 在SQL语句中引入
查询的字段列表很可能是不同的,所以应该使用不同的VO类,同时为了避免后续维护添加字段导致的调整,即使当前查询详情和查询列表的字段完全相同,也应该使用不同的VO类
配置useGeneratedKeys="true"和keyProperty="属性名"这2个属性,就可获取插入的新数据的自动编号的主键值并封装到参数对象的id属性(由keyProperty指定)
各配置SQL语句的标签必须配置id属性,取值为对应接口里面的抽象方法名
各配置SQL语句的标签内部是编写SQL语句
sql语句
标签的属性配置,遍历生成SQL语句
collection:表示被遍历的参数列表,如果抽象方法的参数只有1个,当参数类型是List集合类型时,当前属性取值为list,当参数类型是数组类型时,当前属性取值为array
item:用于指定遍历到的各元素的变量名,并且,在
的子级,使用#{}时的名称也是当前属性指定的名字
separator:用于指定遍历过程中各元素的分隔符
DELETE FROM
table_name
WHERE
id IN (
#{id}
)
<if>标签的属性配置,对参数进行判断,例如在update属性的时候可以只更新部分属性
会自动识别是否需要去除最后一个元素的分隔符
使用两个
代替java中的if...else if...else
UPDATE
table_name
name=#{name},
description=#{description},
WHERE
id=#{id}
系列标签,以实现类似if ... else ...
满足条件时的SQL片段
不满足条件时的SQL片段
当查询出来的数据赋值给对象时候,对象里面有list结构使用下列标签,MyBatis会自动识别
now()表示当前时间
gmt_create < NOW()常见的关系运算符英文缩写,在xml文件中部分符号无法编译,所以用以下代替
lt < (less than)
gt >(great than)
le <= (less equals)
ge >= (great equals)
eq ==
ne !=(not equals)
gmt_create > #{startTime}
AND
gmt_create < #{endTime}占位符
在使用Mybatis时,在SQL语句中的参数,可以使用#{}或${}格式的占位符
在SQL语句中,除了关键字、数值、特定位置的字符或字符串以外,只要没有使用特殊符号框住,SQL语句中的其它内容都会被视为“字段名”,特殊符号有:
使用一对单撇符号框住的就是自定义名称
使用一对单引号框住的都是字符串
SQL语句中的参数使用#{}格式的占位符,会进行预编译的处理,如果使用的是${}格式的占位符,则不会预编译
#{}格式的占位符,则#{xxxxxx}会被识别成参数,经过预编译(先编译,再传值,再执行)处理后,无论在此处传入什么值,都会被认为是参数,语义不会发生变化,同时不必关心参数值的数据类型问题,并且没有SQL注入的风险
${}格式的占位符,则会先将参数值代入到SQL语句中,然后再执行编译.同时需要关心参数值的数据类型问题,如果参数的值是字符串类型的,必须在值的两侧添加单引号,这种做法存在SQL注入的风险,因为传入的参数值可能会改变语义.但优点是这种格式的占位符可以表示SQL语句中的任何片段,使得这个SQL语句更加的灵活,不需要一味的拒绝
实体类
实体类是POJO的其中一种。在项目中,如果某个类的作用就是声明若干个属性,并且添加Setter & Getter方法等,并不编写其它的功能性代码,这样的类都称之POJO,用于表示项目中需要处理的数据
POJO的命名规范
数据对象:xxxDO/PO(例如entity,bean),xxx 即为数据表名,如数据库Insert和update中使用的数据用于Service层向Mapper层的数据传输
数据传输对象:xxxDTO,xxx 为业务领域相关的名称,如用户提交的数据用于Controller层向Service层的数据传输
展示对象:xxxVO,xxx 一般为网页名称,如数据库中Select中出来的数据用于Mapper层向Service层的数据传输
数据表中的字段类型与Java中的属性的数据类型的对应关系
MySQL中的数据类型 |
Java中的数据类型 |
tinyint / smallint / int |
Integer |
bigint |
Long |
char / varchar / text系列 |
String |
datetime |
LocalDateTime |
decimal |
BigDecimal |
实体类规范
所有属性都应该是私有的
所有属性都应该有对应的、规范名称的Setter、Getter方法
必须重写equals()和hashCode(),并保证:
如果两个对象的各属性值完全相同,则equals()对比结果为true,且hashCode()值相同
如果两个对象存在属性值不同的,则equals()对比结果为false,且hashCode()值不同
如果两个对象的hashCode()相同,则equals()对比结果必须为true
如果两个对象的hashCode()不同,则equals()对比结果必须为false
必须实现Serializable接口
建议重写toString()方法,输出各属性的值
使用Lombok框架
在项目中使用Lombok框架,可以实现添加注解,即可使得Lombok在项目的编译期自动生成一些代码(例如Setter & Getter)
导入框架,在pom文件中添加依赖
org.projectlombok
lombok
1.18.20
provided
在POJO类上添加Lombok框架的@Data注解,可以在编译期生成规范的Setter & Getter,规范的hashCode()与equals(),包含各属性与值的toString()
@Data
public class Test implements Serializable {
private Long id;
}当使用了Lombok后,由于源代码中并没有Setter & Getter方法,所以当编写代码时,IntelliJ IDEA不会提示相关方法,并且即使强行输入调用这些方法的代码,还会报错,但是并不影响项目的运行,为了解决此问题,强烈推荐安装Lombok插件
gmt_create和gmt_modified
在每张数据表中,都有gmt_create、gmt_modified这2个字段(是在阿里的开发规范上明确要求的),这2个字段的值是有固定规则的
gmt_create的值就是INSERT这条数据时的时间
mt_modified的值就是每次执行UPDATE时更新的时间
由于这是固定的做法,可以使用Mybatis拦截器进行处理,即每次执行SQL语句之前,先判断是否为INSERT / UPDATE类型的SQL语句,如果是,再判断SQL语句是否处理了相关时间,如果没有,则修改原SQL语句,得到处理了相关时间的新SQL语句,并放行,使之最终执行的是修改后的SQL语句
package test.mybatis;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.executor.statement.StatementHandler;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.plugin.*;
import java.lang.reflect.Field;
import java.sql.Connection;
import java.time.LocalDateTime;
import java.util.Properties;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 基于MyBatis的自动更新"最后修改时间"的拦截器
* 需要SQL语法预编译之前进行拦截,则拦截类型为StatementHandler,拦截方法是prepare
* 具体的拦截处理由内部的intercept()方法实现
*拦截所有的update方法(根据SQL语句以update前缀进行判定),无法不拦截某些update方法
* 所有数据表中"最后修改时间"的字段名必须一致,由本拦截器的FIELD_MODIFIED属性进行设置
*/
@Slf4j
@Intercepts({@Signature(
type = StatementHandler.class,
method = "prepare",
args = {Connection.class, Integer.class}
)})
public class InsertUpdateTimeInterceptor implements Interceptor {
/**
* 自动添加的创建时间字段
*/
private static final String FIELD_CREATE = "gmt_create";
/**
* 自动更新时间的字段
*/
private static final String FIELD_MODIFIED = "gmt_modified";
/**
* SQL语句类型:其它(暂无实际用途)
*/
private static final int SQL_TYPE_OTHER = 0;
/**
* SQL语句类型:INSERT
*/
private static final int SQL_TYPE_INSERT = 1;
/**
* SQL语句类型:UPDATE
*/
private static final int SQL_TYPE_UPDATE = 2;
/**
* 查找SQL类型的正则表达式:INSERT
*/
private static final String SQL_TYPE_PATTERN_INSERT = "^insert\\s";
/**
* 查找SQL类型的正则表达式:UPDATE
*/
private static final String SQL_TYPE_PATTERN_UPDATE = "^update\\s";
/**
* 查询SQL语句片段的正则表达式:gmt_modified片段
*/
private static final String SQL_STATEMENT_PATTERN_MODIFIED = ",\\s*" + FIELD_MODIFIED + "\\s*=";
/**
* 查询SQL语句片段的正则表达式:gmt_create片段
*/
private static final String SQL_STATEMENT_PATTERN_CREATE = ",\\s*" + FIELD_CREATE + "\\s*[,)]?";
/**
* 查询SQL语句片段的正则表达式:WHERE子句
*/
private static final String SQL_STATEMENT_PATTERN_WHERE = "\\s+where\\s+";
/**
* 查询SQL语句片段的正则表达式:VALUES子句
*/
private static final String SQL_STATEMENT_PATTERN_VALUES = "\\)\\s*values?\\s*\\(";
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 日志
log.debug("准备拦截SQL语句……");
// 获取boundSql,即:封装了即将执行的SQL语句及相关数据的对象
BoundSql boundSql = getBoundSql(invocation);
// 从boundSql中获取SQL语句
String sql = getSql(boundSql);
// 日志
log.debug("原SQL语句:{}", sql);
// 准备新SQL语句
String newSql = null;
// 判断原SQL类型
switch (getOriginalSqlType(sql)) {
case SQL_TYPE_INSERT:
// 日志
log.debug("原SQL语句是【INSERT】语句,准备补充更新时间……");
// 准备新SQL语句
newSql = appendCreateTimeField(sql, LocalDateTime.now());
break;
case SQL_TYPE_UPDATE:
// 日志
log.debug("原SQL语句是【UPDATE】语句,准备补充更新时间……");
// 准备新SQL语句
newSql = appendModifiedTimeField(sql, LocalDateTime.now());
break;
}
// 应用新SQL
if (newSql != null) {
// 日志
log.debug("新SQL语句:{}", newSql);
reflectAttributeValue(boundSql, "sql", newSql);
}
// 执行调用,即拦截器放行,执行后续部分
return invocation.proceed();
}
public String appendModifiedTimeField(String sqlStatement, LocalDateTime dateTime) {
Pattern gmtPattern = Pattern.compile(SQL_STATEMENT_PATTERN_MODIFIED, Pattern.CASE_INSENSITIVE);
if (gmtPattern.matcher(sqlStatement).find()) {
log.debug("原SQL语句中已经包含gmt_modified,将不补充添加时间字段");
return null;
}
StringBuilder sql = new StringBuilder(sqlStatement);
Pattern whereClausePattern = Pattern.compile(SQL_STATEMENT_PATTERN_WHERE, Pattern.CASE_INSENSITIVE);
Matcher whereClauseMatcher = whereClausePattern.matcher(sql);
// 查找 where 子句的位置
if (whereClauseMatcher.find()) {
int start = whereClauseMatcher.start();
int end = whereClauseMatcher.end();
String clause = whereClauseMatcher.group();
log.debug("在原SQL语句 {} 到 {} 找到 {}", start, end, clause);
String newSetClause = ", " + FIELD_MODIFIED + "='" + dateTime + "'";
sql.insert(start, newSetClause);
log.debug("在原SQL语句 {} 插入 {}", start, newSetClause);
log.debug("生成SQL: {}", sql);
return sql.toString();
}
return null;
}
public String appendCreateTimeField(String sqlStatement, LocalDateTime dateTime) {
// 如果 SQL 中已经包含 gmt_create 就不在添加这两个字段了
Pattern gmtPattern = Pattern.compile(SQL_STATEMENT_PATTERN_CREATE, Pattern.CASE_INSENSITIVE);
if (gmtPattern.matcher(sqlStatement).find()) {
log.debug("已经包含 gmt_create 不再添加 时间字段");
return null;
}
// INSERT into table (xx, xx, xx ) values (?,?,?)
// 查找 ) values ( 的位置
StringBuilder sql = new StringBuilder(sqlStatement);
Pattern valuesClausePattern = Pattern.compile(SQL_STATEMENT_PATTERN_VALUES, Pattern.CASE_INSENSITIVE);
Matcher valuesClauseMatcher = valuesClausePattern.matcher(sql);
// 查找 ") values " 的位置
if (valuesClauseMatcher.find()) {
int start = valuesClauseMatcher.start();
int end = valuesClauseMatcher.end();
String str = valuesClauseMatcher.group();
log.debug("找到value字符串:{} 的位置 {}, {}", str, start, end);
// 插入字段列表
String fieldNames = ", " + FIELD_CREATE + ", " + FIELD_MODIFIED;
sql.insert(start, fieldNames);
log.debug("插入字段列表{}", fieldNames);
// 定义查找参数值位置的 正则表达 “)”
Pattern paramPositionPattern = Pattern.compile("\\)");
Matcher paramPositionMatcher = paramPositionPattern.matcher(sql);
// 从 ) values ( 的后面位置 end 开始查找 结束括号的位置
String param = ", '" + dateTime + "', '" + dateTime + "'";
int position = end + fieldNames.length();
while (paramPositionMatcher.find(position)) {
start = paramPositionMatcher.start();
end = paramPositionMatcher.end();
str = paramPositionMatcher.group();
log.debug("找到参数值插入位置 {}, {}, {}", str, start, end);
sql.insert(start, param);
log.debug("在 {} 插入参数值 {}", start, param);
position = end + param.length();
}
if (position == end) {
log.warn("没有找到插入数据的位置!");
return null;
}
} else {
log.warn("没有找到 ) values (");
return null;
}
log.debug("生成SQL: {}", sql);
return sql.toString();
}
@Override
public Object plugin(Object target) {
// 本方法的代码是相对固定的
if (target instanceof StatementHandler) {
return Plugin.wrap(target, this);
} else {
return target;
}
}
@Override
public void setProperties(Properties properties) {
// 无须执行操作
}
/**
* 获取BoundSql对象,此部分代码相对固定
* 注意:根据拦截类型不同,获取BoundSql的步骤并不相同,此处并未穷举所有方式!
*
* @param invocation 调用对象
* @return 绑定SQL的对象
*/
private BoundSql getBoundSql(Invocation invocation) {
Object invocationTarget = invocation.getTarget();
if (invocationTarget instanceof StatementHandler) {
StatementHandler statementHandler = (StatementHandler) invocationTarget;
return statementHandler.getBoundSql();
} else {
throw new RuntimeException("获取StatementHandler失败!请检查拦截器配置!");
}
}
/**
* 从BoundSql对象中获取SQL语句
*
* @param boundSql BoundSql对象
* @return 将BoundSql对象中封装的SQL语句进行转换小写、去除多余空白后的SQL语句
*/
private String getSql(BoundSql boundSql) {
return boundSql.getSql().toLowerCase().replaceAll("\\s+", " ").trim();
}
/**
* 通过反射,设置某个对象的某个属性的值
*
* @param object 需要设置值的对象
* @param attributeName 需要设置值的属性名称
* @param attributeValue 新的值
* @throws NoSuchFieldException 无此字段异常
* @throws IllegalAccessException 非法访问异常
*/
private void reflectAttributeValue(Object object, String attributeName, String attributeValue) throws NoSuchFieldException, IllegalAccessException {
Field field = object.getClass().getDeclaredField(attributeName);
field.setAccessible(true);
field.set(object, attributeValue);
}
/**
* 获取原SQL语句类型
*
* @param sql 原SQL语句
* @return SQL语句类型
*/
private int getOriginalSqlType(String sql) {
Pattern pattern;
pattern = Pattern.compile(SQL_TYPE_PATTERN_INSERT, Pattern.CASE_INSENSITIVE);
if (pattern.matcher(sql).find()) {
return SQL_TYPE_INSERT;
}
pattern = Pattern.compile(SQL_TYPE_PATTERN_UPDATE, Pattern.CASE_INSENSITIVE);
if (pattern.matcher(sql).find()) {
return SQL_TYPE_UPDATE;
}
return SQL_TYPE_OTHER;
}
}Mybatis拦截器必须注册后才能生效,可以在配置类(或任何组件类)中
@Configuration
@AutoConfigureAfter(MybatisAutoConfiguration.class)
public class AutoUpdateTimeInterceptorConfiguration {
@Autowired
private List sqlSessionFactoryList;
@PostConstruct
public void addInterceptor() {
InsertUpdateTimeInterceptor interceptor = new InsertUpdateTimeInterceptor();
for (SqlSessionFactory sqlSessionFactory : sqlSessionFactoryList) {
sqlSessionFactory.getConfiguration().addInterceptor(interceptor);
}
}
} application文件配置
mybatis:
configuration:
cache-enabled: false # 不启用mybatis缓存
map-underscore-to-camel-case: true # 映射支持驼峰命名法
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 将运行的sql输出到控制台问题解决方案
表字段和属性字段不一致解决方案:
通过@Result注解
通过在application.properties里面添加配置信息(mybatis.configuration.map-underscore-to-camel-case=true)
SpringMVC框架
核心流程
Spring MVC框架主要解决了接收请求参数、转换响应结果、统一处理异常等
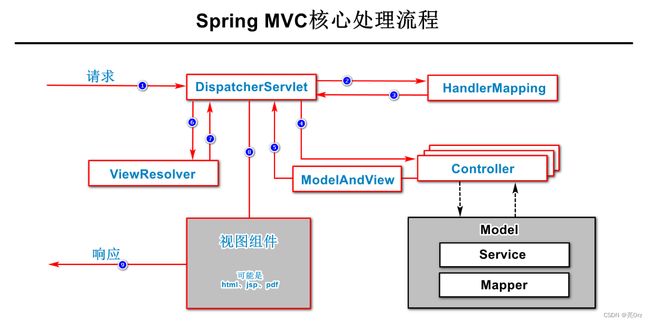
以上示例图描述是“非响应正文”的处理流程
Spring MVC框架的5个核心组件:
DispatcherServlet:也称之为“前端控制器”,用于在Spring MVC框架接收所有来自客户端的请求,并进行分发、组织整个处理流程,此组件将由配置文件进行处理,在Spring Boot项目中,是自动配置的
HandlerMapping:记录了请求路径与处理请求的控制器(方法)的对应关系,在开发实践时,使用@RequestMapping系列注解配置的请求路径,本质就是在向HandlerMapping中添加映射关系
Controller:实际处理请求的组件,是由开发人员自行定义的
注意:如果设计的控制器处理请求的方法是响应正文的,当Controller组件执行结束后,就会开始向客户端响应数据,不会执行以上示例图中剩余的流程
ModelAndView:是Controller处理请求后返回的对象,此对象封装了Controller处理请求后的数据和显示这些数据所使用到的视图组件的名称
ViewResolver:也称之为“视图解析器”,可以根据“视图组件的名称”来决定具体使用的视图组件
导入框架
需要在项目中添加spring-boot-starter-web依赖项。同时spring-boot-starter-web是包含了spring-boot-starter和spring-webmvc的,所以添加spring-boot-starter-web后,就不必再显式的添加spring-boot-starter了和spring-webmvc
org.springframework.boot
spring-boot-starter-web
spring-boot-starter-web包含了一个内置的Tomcat,当启动项目时,会自动将当前项目编译、打包并部署到此Tomcat上
Service层
业务逻辑层的主要价值是设计业务流程,及业务逻辑,以保证数据的完整性和安全性。
在代码的设计方面,业务逻辑层将使用Service作为名称的关键词,并且应该先自定义业务逻辑层接口,再自定义类实现此接口,实现类的名称应该在接口名称的基础上添加Impl后缀,并且在实现类加上@Service注解
在实现类中通过注解@Autowired引入Mapper层的接口实现对象
public interface ITestService {
}@Service
public class TestServiceImpl implements ITestService {
@Autowired
private TestMapper testMapper;
}Controller层
Controller层的主要作用是接收请求,并响应结果,在根包下的任何一个类,添加了@Controller注解,就会被视为控制器类。
在默认情况下,控制器类中处理请求的方法,响应的结果是”视图组件的名称“,即:控制器对请求处理后将返回视图名称,Spring MVC还会根据视图名称来确定视图组件,并且由此视图组件来响应,这种默认情况属于前后端不分离的做法
可以在处理请求的方法上添加@ResponseBody注解,则此方法处理请求后,返回的值就是响应到客户端的数据,这种做法通常称之为”响应正文“。@ResponseBody注解还可以添加在控制器类上,则此控制器类中所有处理请求的方法都将是”响应正文“的
@RestController取代@Controller+@ResponseBody
在类中通过注解@Autowired引入Service层的接口
@RequestMapping作用是:配置请求路径与处理请求的方法的映射关系。
在类上注解表示共用的请求请求路径
在方法上注解表示进入此方法的请求路径
@RestController
@RequestMapping("/test")
public class TestController {
@Autowired
privage TestService testService;
@RequestMapping("/add")
public String test() {
}
}在@RequestMapping上添加限定请求方式的注解
@GetMapping
@PostMapping
@PutMapping
@DeleteMapping
@PatchMapping
请求参数
客户端提交哪些请求参数,在此方法的参数列表中就设计哪些参数,如果参数的数量有多个,并且多个参数具有相关性,则可以封装,并使用封装的类型作为方法的参数,另外可以按需添加Spring容器中的其它相关数据作为参数,例如HttpServletRequest、HttpServletResponse、HttpSession等
参数注意点
如果客户端没有提交对应名称的请求参数,则方法的参数值为null
如果客户端提交了对应名称的请求参数,但是没有值,则方法的参数值为空字符串(""),如果方法的参数是需要将字符串转换为别的格式,但无法转换,则参数值为null,例如声明为Long类型时
如果客户端提交对应名称的请求参数,且参数有正确的值,则方法的参数值为就是请求参数值,如果方法的参数是需要将字符串转换为别的格式,但无法转换,则会抛出异常
@RequestParam(required = false,defaultValue = "1"),可以设置当没有传入参数时候的默认值
推荐将某些具有唯一性的(且不涉及隐私)参数设计到URL中,使得这些参数值是URL的一部分,Spring MVC框架支持在设计URL时,使用{名称}格式的占位符,实际处理请求时此占位符位置是任意值都可以匹配得到.在处理请求的方法的参数列表中,用于接收占位符的参数,需要添加@PathVariable注解
如果{}占位符中的名称,与处理请求的方法的参数名称不匹配,则需要在@PathVariable注解上配置占位符中的名称
在配置占位符时,可以在占位符名称的右侧,可以添加冒号,再加上正则表达式,对占位符的值的格式进行限制
请求方法上可以有多个@RequestMapping,多个不冲突有正则表达式的占位符配置的URL是可以共存的
某个URL的设计没有使用占位符,与使用了占位符的,是允许共存的,Spring MVC会优先匹配没有使用占位符的URL,再尝试匹配使用了占位符的URL
@RequestMapping("/delete/{ids}")
@RequestMapping("/delete/{ids:[a-z]+}")
@RequestMapping("/delete/{ids:[0-9]+}")
@RequestMapping("/delete/test")
public String delete(@PathVariable("ids") Long id) {
}当添加了@RequestBody注解,则客户端提交的请求参数必须是对象格式的,如果客户端提交的数据不是对象在接收到请求时将报错.
【建议使用】当没有添加@RequestBody注解,则客户端提交的请求参数必须是FormData格式,如果客户端提交的数据不是FormData格式的,而是对象,则无法接收到参数,不会报错,控制器中各参数值为null。FormData格式的参数,在Knife4j框架的调试界面中则会显示各请求参数对应的输入框。
使用Validation框架对请求参数进行检查.虽然在客户端(例如网页)已经检查了请求参数,但服务器端应该再次检查,因为:
客户端的程序是运行在用户的设备上的,存在程序被篡改的可能性,所以提交的数据或执行的检查是不可信的
在前后端分离的开发模式下,客户端的种类可能较多,例如网页端、手机端、电视端,可能存在某些客户端没有检查
升级了某些检查规则,但是用户的设备上,客户端软件没有升级(例如手机APP还是此前的版本)
请求结果
通常需要使用自定义类,作为处理请求的方法、处理异常的方法的返回值类型。响应到客户端的数据中,应该包含“业务状态码”,以便于客户端迅速判断操作成功与否,为了规范的管理业务状态码的值
定义响应码,在异常的定义中添加响应码,在数据正确返回的时候也需要定义返回码
public enum ServiceCode {
OK(20000),
ERR_NOT_FOUND(40400),
ERR_CONFLICT(40900);
private Integer value;
ServiceCode(Integer value) {
this.value = value;
}
public Integer getValue() {
return value;
}
}使用自定义类型,表示响应到客户端的数据,包含是异常时候的返回数据或者正确的数据,同时可以使用Knife4J框架对返回的数据进行Api注解
@Data
public class JsonResult implements Serializable {
/**
* 业务状态码的值
*/
private Integer state;
/**
* 操作失败时的提示文本
*/
private String message;
public static JsonResult ok() {
JsonResult jsonResult = new JsonResult();
jsonResult.state = ServiceCode.OK.getValue();
return jsonResult;
}
public static JsonResult fail(ServiceCode serviceCode, String message) {
JsonResult jsonResult = new JsonResult();
jsonResult.state = serviceCode.getValue();
jsonResult.message = message;
return jsonResult;
}
}在实际处理请求和异常时,Spring MVC框架会将方法返回的JsonResult对象转换成JSON格式的字符串。需要在JSON结果中包含为null的属性,所以可以在application.properties /yml中进行配置
# JSON结果中将不包含为null的属性
spring.jackson.default-property-inclusion=non_nul
# Spring相关配置
spring:
# Jackson框架相关配置
jackson:
# JSON结果中是否包含为null的属性的默认配置
default-property-inclusion: non_nullRESTful风格
RESTful也可以简称为REST,是一种设计软件的风格,既不是规定,也不是规范
处理请求后是响应正文的
将具有唯一性的参数值设计在URL中
根据请求访问数据的方式,使用不用的请求方式
如果尝试添加数据,使用POST请求方式
如果尝试删除数据,使用DELETE请求方式
如果尝试修改数据,使用PUT请求方式
如果尝试查询数据,使用GET请求方式
这种做法在复杂的业务系统中并不适用
注解
@AliasFor("path")
String[] value() default {};以上源代码表示在此注解中存在名为value的属性,并且,此属性的值类型是String[],例如你可以配置@RequestMapping(value = {"xxx", "zzz"}),此属性的默认值是{}(空数组)。
在所有注解中,value是默认的属性,所以如果你需要配置的注解参数是value属性,且只配置这1个属性时,并不需要显式的指定属性名
在所有注解中,如果某个属性的值是数组类型的,但是你只提供1个值(也就是数组中只有1个元素),则这个值并不需要使用大括号框住
value属性的声明上还有@AliasFor("path"),它表示”等效于“的意思,也就是说value属性与另一个名为path的属性是完全等效的
统一异常处理
场景:Service在处理业务,如果视为”失败“,将抛出异常,并且抛出时还会封装”失败“的描述文本,而Controller每次调用Service的任何方法时,都会使用try..catch进行捕获并处理,并且处理的代码都是相同的,这样的做法是非常固定的,导致在Controller中存在大量的try...catch.为了解决这个问题Spring MVC提供了统一处理异常的机制,它可以使得Controller不再处理异常,改为抛出异常,而Spring MVC在调用Controller处理请求时,会捕获Controller抛出的异常并尝试统一做处理。
Spring MVC建议将处理异常的代码写在专门的类中,并且在类上添加@ControllerAdvice注解,当添加此注解后,此类中处理异常的代码将作用于整个项目每次处理请求的过程中.但这种属于前后端不分离,因为使用了Controller默认的返回视图对象,所以推荐使用@RestControllerAdvice(@RestControllerAdvice相当于@ControllerAdvice+@ResponseBody),在类的处理异常的方法上使用@ExceptionHandler,方法的参数列表至少需要添加1个异常类型的参数
允许存在多个处理异常的方法,只要这些方法处理的异常类型不直接冲突即可
即:不允许2个处理异常的方法都处理同一种异常
即:允许多个处理异常的方法中处理的异常存在继承关系,例如A方法处理NullPointerException,B方法处理RuntimeException
在实际处理时,最后推荐添加一下对Throwable处理的方法,以避免某些异常没有被处理,导致响应500错误。
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler {
public GlobalExceptionHandler() {
System.out.println("创建全局异常处理器对象:GlobalExceptionHandler");
}
@ExceptionHandler
public String handleServiceException(ServiceException e) {
log.debug("捕获到ServiceException:{}", e.getMessage());
return e.getMessage();
}
@ExceptionHandler
public String handleThrowable(Throwable e) {
log.debug("捕获到Throwable:{}", e.getMessage());
e.printStackTrace(); // 强烈建议
return "服务器运行过程中出现未知错误,请联系系统管理员!";
}
}创建configuration类,对统一异常处理的这个类进行扫描不然无法识别
@Configuration
@ComponentScan("xx.xx.xxxx.exception")
public class CommonsConfiguration {
}Spring框架
Spring框架主要解决了创建对象、管理对象的相关问题,Spring会在创建对象之后,完成必要的属性赋值等操作,并且还会持有所创建的对象的引用,由于持久大量对象的引用,所以Spring框架也通常被称之为“Spring容器”.IOC和AOP是其两大核心
AOP
面向切面的编程,实现了横切关注的相关问题,通常是许多不同的数据处理流程中都需要解决的共同的问题.在整个请求处理的过程中,虽然处理请求不同,但是需要执行一些高度相似甚至完全相同的代码,某些特定的执行时间节点可以通过一些特殊的组件来完成,例如Java EE中的Filter、Spring MVC的Interceptor、Mybatis的Interceptor,但是这些特殊的组件只能在特定的时间节点执行,例如Filter是在服务器接收到请求的第一时间就已经执行,Spring MVC的Interceprot是在Controller的前后执行,Mybatis的Intercepror是在处理SQL语句时执行,如果需要在其它执行时间节点处理相同的任务,这些组件都是不可用的
使用AOP通常解决以下类型的问题:安全、事务管理、日志等等。同时切面是无侵入性的,在不修改任何其它类的任何代码的情况下,就可以作用于整个数据处理过程
需要添加依赖项
org.springframework.boot
spring-boot-starter-aop
创建用于执行业务的切面类,这种切面类本身是个组件类,并且需要添加@Aspect注解
@Slf4j
@Aspect
@Component
public class TestAop {
/**
*关于execution表达式:用于匹配在何时执行AOP相关代码
*表达式中的星号:匹配任意内容,只能匹配1次
*表达式中的2个连续的小数点:匹配任意内容,可以匹配0~n次,只能用于包名和参数列表部分
*表达式中的包是根包,会自动包含其子孙包中的匹配项
*/
/**
*第一个星号:无论方法的返回值类型是什么
*第二个星号:无论是哪个类
*第三个星号:无论是哪个方法
*两个连续的点:任何参数列表
*/
@Around("execution(* xx.xxxx.xxxxx.xxxx.xxxx.*.*(..))")
public Object test(ProceedingJoinPoint pjp) throws Throwable {
Object result = pjp.proceed(); // 执行连接点方法,获取返回结果
return result;
}
}在AOP中,有多种Advice(通知)
@Around:包裹,可以实现在连接点之前和之后均自定义代码,仅当使用@Around时,方法才可以自行处理ProceedingJoinPointer
必须调用proceed()方法,表示执行表达式匹配到的方法
调用proceed()方法必须获取返回值,且作为当前方法的返回值,表示返回表达式匹配的方法的返回值
调用proceed()方法时的异常必须抛出,不可以使用try...catch进行捕获并处理
@Before:在连接点之前执行
@After:在连接点之后执行,无论是正常返回还是抛出异常都会执行
@AfterReturning:在连接点返回之后执行
@AfterThrowing:在连接点抛出异常之后执行
@Around
try {
@Before
连接点方法
@AfterReturning
} catch (Throwable e) {
@AfterThrowing
} finally {
@After
}
@AroundIOC和DI
IOC = Inversion of Control,控制反转,表现为“将对象的管理权交给了框架”
DI = Dependency Injection,依赖注入,表现为“为类中的属性自动赋值”
Bean对象
Spring框架创建对象有2种做法
通过配置类中的@Bean方法.在任何配置类中,自定义返回对象的方法,并在方法上添加@Bean注解,则Spring会自动调用此方法,并且获取此方法返回的对象,将对象保存在Spring容器中.在开发实践中,如果需要创建非自定义类(例如Java官方的类,或其它框架中的类)的对象,必须使用@Bean方法,毕竟你不能在别人声明的类上添加组件注解
通过组件扫描。需要通过@ComponentScan注解来指定扫描的根包,则Spring框架会在此根包下查找组件,并且创建这些组件的对象.常用组件有
@Component:通用组件注解
@Controller:应该添加在控制器类上
@Service:应该添加在处理业务逻辑的类上
@Repository:应该添加在处理数据访问(直接与数据源交互)的类上
@Configuration:应该添加在配置类上.会使用CGLib的代理模式来创建对象,并且,被Spring实际使用的是代理对象
@SpringBootApplication: 在Spring Boot项目中,在启动类上注解,此注解的元注解包含@ComponentScan注解,所以Spring Boot项目启动时就会执行组件扫描,扫描的根包就是启动类所在的包
对象的作用域,Spring管理的对象默认是“单例”的,则在整个程序的运行过程中,随时可以获取或访问Spring容器中的“单例”对象.默认情况下预加载的,可以通过@Lazy注解配置为懒加载的
果是通过@Bean方法创建对象,则@Lazy注解添加在@Bean方法上
如果是通过组件扫描创建对象,则@Lazy注解添加在组件类上
如果需要Spring管理某个对象采取“非单例”的模式,可以通过@Scope("prototype")注解来实现
如果是通过@Bean方法创建对象,则@Scope("prototype")注解添加在@Bean方法上
如果是通过组件扫描创建对象,则@Scope("prototype")注解添加在组件类上
自动装配机制
当Spring管理的类的属性需要被自动赋值,或Spring调用的方法的参数需要值时,Spring会自动从容器中找到合适的值,为属性 / 参数自动赋值
当类的属性需要值时,可以在属性上添加@Autowired注解.
当Spring调用的方法的参数需要值时,主要表现为:构造方法、配置类中的@Bean方法等
调用构造方法
如果类中存在无参数构造方法(无论是否存在其它构造方法),Spring会自动调用无参数构造方法
如果类中仅有1个构造方法,Spring会自动尝试调用,且如果此构造方法有参数,Spring会自动尝试从容器中查找合适的值用于调用此构造方法
如果类中有多个构造方法,且都是有参数的,Spring不会自动调用任何构造方法,且会报错
如果希望Spring调用特定的构造方法,应该在那一个构造方法上添加@Autowired注解
关于合适的值:Spring框架首先会查找容器中匹配类型的对象的数量
0个:无法装配,需要判断@Autowired注解的required属性:
true:在加载Spring时直接报错NoSuchBeanDefinitionException
false:放弃自动装配,且尝试自动装配的属性将是默认值
1个:直接装配,且装配成功
超过1个:尝试按照名称来匹配,如果均不匹配,则在加载Spring时直接报错NoUniqueBeanDefinitionException,按照名称匹配时,要求被装配的变量名与Bean Name保持一致
关于Bean Name:每个Spring Bean都有一个Bean Name
如果是通过@Bean方法创建的对象,
Bean Name默认就是方法名,
通过@Bean注解参数来指定名称
如果是通过组件扫描的做法来创建的对象
Bean Name默认是将类名首字母改为小写的名称,例如,类名为TestServiceImpl,则Bean Name为testServiceImpl,(此规则只适用于类名中第1个字母大写、第2个字母小写的情况,如果不符合此情况,则Bean Name就是类名)
通过@Component等注解的参数进行配置
在需要装配的属性上使用@Qualifier注解来指定装配的Bean的Bean Name
在处理属性的自动装配上,还可以使用@Resource注解取代@Autowired注解,@Resource是先根据名称尝试装配,再根据类型装配的机制,和@Autowired注解的匹配机制刚好相反
计划任务
在Spring Boot项目,计划任务默认是禁用的,需要在配置类上添加@EnableScheduling注解以开启项目中的计划任务。
@Configuration
@EnableScheduling
public class ScheduleConfiguration {
public ScheduleConfiguration() {
}
}在Spring Boot项目中,在任何组件类中自定义的方法上添加@Scheduled注解,并通过此注解配置计划任务的执行周期或执行时间,则此方法就是一个计划任务方法
@Slf4j
@Component
public class TestSchedule {
public TestSchedule() {
}
@Scheduled(fixedRate = 5 * 60 * 1000)
public void testCache() {
//执行计划方法
}
}@Scheduled注解的属性配置
fixedRate:不管前一个任务执行是否执行完毕,每间隔多少毫秒执行一次
fixedDelay:前一个任务执行完毕后,过多少毫秒执行一次
cron:使用一个字符串,其中包含6~7个值,每个值之间使用1个空格进行分隔
在cron的字符串的各值分别表示:秒 分 时 日 月 周(星期) [年]
例如:cron = "56 34 12 2 1 ? 2035",则表示2035年1月2日12:34:56将执行此计划任务,无论这一天是星期几
以上各值都可以使用通配符,使用星号(*)则表示任意值,使用问号(?)表示不关心具体值,并且,问号只能用于“周(星期)”和“日”这2个位置
以上各值,可以使用“x/x”格式的值,例如,分钟对应的值使用“1/5”,则表示当分钟值为1的那一刻开始执行,往后每间隔5分钟执行一次
由于计划任务是在专门的线程中处理的,与普通的处理请求、处理数据的线程是并行的,所以需要关注线程安全问题。
Spring JDBC事务框架
事务:Transaction,是数据库中的一种能够保证多个写操作要么全部成功,要么全部失败的机制
在执行数据访问操作时,数据库有一个“自动提交”的机制。事务的本质是会先将“自动提交”关闭,当业务方法执行结束之后,再一次性“提交”。
开启事务:BEGIN
提交事务:COMMIT
回滚事务:ROLLBACK
Spring JDBC框架在处理事务时,默认出现RuntimeException时候进行回滚
可以配置@Transactional注解的rollbackFor或rollbackForClassName属性来指定回滚的异常类型
可以配置@Transactional注解的noRollbackFor或noRollbackForClassName属性用于指定不回滚的异常
建议在业务方法中执行了任何增、删、改操作后,都获取受影响的行数,并判断此值是否符合预期,如果不符合,应该及时抛出RuntimeException或其子孙类异常
在基于Spring JDBC的数据库编程中,添加@Transactional注解,即可使用事务管理
业务实现类上,将作用于当前类中所有方法
业务实现类的方法上,仅作用于当前方法
【推荐】业务接口上
将作用于当前接口中所有抽象方法
无论是哪个类实现了此接口,重写的所有方法都是将是事务性的
【推荐】业务接口的抽象方法上
仅作用于此抽象方法
无论是哪个类重写此方法,这个类的此方法都将是事务性的
SLF4j框架
在Spring Boot项目中,spring-boot-starter依赖项中已经包含日志框架,如果项目中添加了Lombok依赖项后,可以在任何类上添加@Slf4j注解,则Lombok会在编译期声明一个名为log的日志对象变量,此变量可以调用相关方法来输出日志
@Slf4j
public class Slf4jTests {
void testLog() {
log.info("输出了一条日志……");
}
}日志级别
trace
debug:调试
info:一般信息(默认)
warn:警告信息
error:错误信息
在application.properties中配置logging.level的属性以此修改日志的级别,xx为需要配置的包名
logging.level.xx.xx.xx=infoKnife4j框架
Knife4j是一款基于Swagger 2的在线API文档框架。
添加Knife4j依赖
com.github.xiaoymin
knife4j-spring-boot-starter
2.0.9
在主配置文件(application.yml)
knife4j:
# 开启增强配置
enable: true
# 生产环境屏蔽,开启将禁止访问在线API文档
production: false
# Basic认证功能,即是否需要通过用户名、密码验证后才可以访问在线API文档
basic:
# 是否开启Basic认证
enable: false
# 用户名,如果开启Basic认证却未配置用户名与密码,默认是:admin/123321
username: root
# 密码
password: root添加Knife4j的配置类,进行必要的配置,必须指定控制器的包
public class Knife4jConfiguration {
/**
* 【重要】指定Controller包路径
*/
private String basePackage = "xx.xxxx.xxxx.xx.controller";
/**
* 分组名称
*/
private String groupName = "xxx";
/**
* 主机名
*/
private String host = "http://xxxxxxx";
/**
* 标题
*/
private String title = "xxxxxxx";
/**
* 简介
*/
private String description = "xxxxxxxx";
/**
* 服务条款URL
*/
private String termsOfServiceUrl = "http://www.apache.org/licenses/LICENSE-2.0";
/**
* 联系人
*/
private String contactName = "xxxxxxx";
/**
* 联系网址
*/
private String contactUrl = "xxxxxxx";
/**
* 联系邮箱
*/
private String contactEmail = "[email protected]";
/**
* 版本号
*/
private String version = "1.0.0";
@Autowired
private OpenApiExtensionResolver openApiExtensionResolver;
public Knife4jConfiguration() {
log.debug("加载配置类:Knife4jConfiguration");
}
@Bean
public Docket docket() {
String groupName = "1.0.0";
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.host(host)
.apiInfo(apiInfo())
.groupName(groupName)
.select()
.apis(RequestHandlerSelectors.basePackage(basePackage))
.paths(PathSelectors.any())
.build()
.extensions(openApiExtensionResolver.buildExtensions(groupName));
return docket;
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title(title)
.description(description)
.termsOfServiceUrl(termsOfServiceUrl)
.contact(new Contact(contactName, contactUrl, contactEmail))
.version(version)
.build();
}
}完成后,启动项目,通过 http://localhost:[服务端口号]/doc.html 即可访问在线API文档
注解
@Api:添加在控制器类上
tags属性,可以指定模块名称,并且在指定名称时,建议在名称前添加数字作为序号,Knife4j会根据这些数字将各模块升序排列
@ApiOpearation:添加在控制器类中处理请求的方法上
value属性,可以指定业务/请求资源的名称
@ApiOperationSupport:添加在控制器类中处理请求的方法上
order属性(int),可以指定排序序号,Knife4j会根据这些数字将各业务/请求资源升序排列
@ApiImplicitParam:对于处理请求的方法的参数列表中那些未封装的参数(例如String、Long),需要在处理请求的方法上使用此注解
name属性,此属性的值就是方法的参数名称
value属性,对参数进行说明
required属性,表示是否必须提交此参数,默认为false
dataType属性,配置参数的数据类型,如果未配置此属性,在API文档中默认显示为string,可以按需修改为int、long、array
@ApiImplicitParams:有多个@ApiImplicitParam需要放在@ApiImplicitParams里
@ApiIgnore:忽略这个参数
@ApiModel:在POJO类上声明,表示是knife4j在线文档测试的注解
@ApiModelProperty:如果处理请求时,参数是封装的POJO类型,需要对各请求参数进行说明时,应该在此POJO类型的各属性上使用此注解进行配置
value属性配置请求参数的名称
requeired属性配置是否必须提交此请求参数(并不具备检查功能)
example属性配置示例
@Data
public class TestDTO implements Serializable {
@ApiModelProperty(value = "名称", example = "张三", required = true)
private String name;
}Validation框架
Spring Validation框架可用于在服务器端检查请求参数的基本格式(例如是否提交了请求参数、字符串的长度是否正确、数字的大小是否在允许的区间等)
添加依赖导入框架
org.springframework.boot
spring-boot-starter-validation
对请求参数的POJO对象进行检测
在处理请求的方法的参数列表中,在POJO类型前添加@Validated或@Valid注解,表示需要通过Spring Validation框架对此POJO类型封装的请求参数进行检查
在POJO类型的属性上,使用检查注解来配置检查规则,例如@NotNull注解就表示“不允许为null”,即客户端必须提交此请求参数
如果请求参数是一些基本值,没有封装(例如String、Integer、Long),首先需要在控制器类上添加@Validated注解,然后在需要将检查注(检查注解定义在下方)解添加在请求参数上
所有检查注解都有message属性,配置此属性,可用于向客户端响应相关的错误信息。
由于Spring Validation验证请求参数格式不通过时,会抛出异常,所以可以在全局异常处理器中对此类异常进行处理,POJO检查抛出的异常是org.springframework.validation.BindException,直接参数抛出的异常是ConstraintViolationException
检查时快速失败:默认情况下,Spring Validation在检查请求参数格式时,如果检查不通过,会记录下相关的错误,然后继续进行其它检查,直到所有检查全部完成,才会返回错误信息,这样比较消耗服务器资源,可以通过在配置类中进行配置,使得检查出错时直接结束并返回错误.
@Slf4j
@Configuration
public class ValidationConfiguration {
public ValidationConfiguration() {
log.debug("创建配置类:ValidationConfiguration");
}
@Bean
public javax.validation.Validator validator() {
return Validation.byProvider(HibernateValidator.class)
.configure() // 开始配置Validator
.failFast(true) // 快速失败,即检查请求参数发现错误时直接视为失败,并不向后继续检查
.buildValidatorFactory()
.getValidator();
}
}常用的检查注解
@NotNull:不允许为null,适用于所有类型的请求参数
@NotEmpty:不允许为空字符串(长度为0的字符串),仅适用于字符串类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
@NotBlank:不允许为空白(形成空白的主要有:空格、TAB制表位、换行等),仅适用于字符串类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
@Pattern:要求被检查的请求参数必须匹配某个正则表达式,通过此注解的regexp属性可以配置正则表达式,仅适用于字符串类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
@Range:要求被检查的数值型请求参数必须在某个数值区间范围内,通过此注解的min属性可以配置最小值,通过此注解的max属性可以配置最大值,仅适用于数值类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
Lombok
@Data:在POJO类上注解,能自动生成get、set、toString、equals、hashcode等方法
@EqualsAndHashcode:生成equals和hashCode方法
of属性,指定使用什么字段来生成这两个方法
callSuper属性,是否调用父类的quals方法
在pom文件添加依赖
org.projectlombok
lombok
true
为了不让IDEA出错,需要在IDEA中安装Lombok插件
Spring Security框架
Spring Security主要解决了认证与授权的相关问题。
Spring Security的基础依赖项是spring-security-core,在Spring Boot项目中,通常添加spring-boot-starter-security这个依赖项,它包含了spring-security-core
框架作用
所有请求都是必须通过认证的
如果未认证,同步请求将自动跳转到 /login,是框架自带的登录页,非跨域的异步请求将响应 403 错误
提供了默认的登录信息,用户名为 user,密码是启动项目是随机生成的,在启动日志中可以看到
当登录成功后,会自动重定向到此前访问的URL
当登录成功后,可以执行所有同步请求,所有异步的POST请求都暂时不可用
可以通过 /logout 退出登录
基础配置
在Configuration文件中进行基础配置,白名单配置规则
在配置路径时,星号是通配符
1个星号只能匹配任何文件夹或文件的名称,但不能跨多个层级
例如:/*/test.js,可以匹配到 /a/test.js 和 /b/test.js,但不可以匹配到 /a/b/test.js
2个连续的星号可以匹配若干个文件夹的层级
例如:/**/test.js,可以匹配 /a/test.js 和 /b/test.js 和 /a/b/test.js
@Slf4j
@Configuration
public class SecurityConfiguration extends WebSecurityConfigurerAdapter {
//返回的算法应该跟数据库中用户密码所使用的的算法一致
@Bean
public PasswordEncoder passwordEncoder() {
// 无操作的密码编码器,在密码比对之前不会对原文执行加密处理
//return NoOpPasswordEncoder.getInstance();
//使用BCrypt算法对用户传进来的密码进行加密然后跟数据库加密后密码比对
return new BCryptPasswordEncoder();
}
@Override
protected void configure(HttpSecurity http) throws Exception {
// 配置白名单
String[] urls = {
"/doc.html",
"/**/*.js",
"/**/*.css",
"/swagger-resources",
"/v2/api-docs"
};
http.csrf().disable(); // 禁用CSRF(防止伪造的跨域攻击)
http.authorizeRequests() // 对请求执行认证与授权
.antMatchers(urls) // 匹配某些请求路径
.permitAll() // (对此前匹配的请求路径)不需要通过认证即允许访问
.anyRequest() // 除以上配置过的请求路径以外的所有请求路径
.authenticated(); // 要求是已经通过认证的
// 开启表单验证,即视为未通过认证时,将重定向到框架默认的登录表单,如果无此配置,则直接响应403
http.formLogin();
http.cors(); // 启用Spring Security框架的处理跨域的过滤器,此过滤器将放行跨域请求,包括预检的OPTIONS请求.因为如果客户端把JWT放在`Authorization`中,会认定为复杂请求需要经过预检.
}
}PasswordEncoder:当Spring容器中存在密码编码器时,在Spring Security处理认证时会自动调用,本质上,是调用了密码编码器的以下方法,Spring Security会使用用户提交的密码作为以上方法的第1个参数,使用UserDetails对象中的密码作为以上方法的第2个参数,然后根据调用以上方法返回的boolean结果来判断此用户是否能通过密码验证,所以,如果配置了BCryptPasswordEncoder,则返回的UserDetails对象中的密码必须是BCrypt密文
boolean matches(CharSequence rawPassword, String encodedPassword);获取用户认证信息
在处理认证流程中,当用户(使用者)输入了用户名、密码并提交,Spring Security就会自动使用用户在表单中输入的用户名来调用loadUserByUsername()方法,作为开发者,应该重写此方法,此方法返回的结果将决定此用户是否能够成功登录,此用户的信息应该来自数据库的管理员表中的数据UserDetails对象中应该包含用户的相关信息,例如密码等,当Spring Security得到调用loadUserByUsername()返回的UserDetails对象后,会自动处理后续的认证过程,例如验证密码是否匹配等
@Slf4j
@Service
public class UserDetailsServiceImpl implements UserDetailsService {
@Override
public UserDetails loadUserByUsername(String s) throws UsernameNotFoundException {
UserDetails userDetails = User.builder()
.username(s)
//真实数据应该是从数据库中查询出来的密码
.password("123456")
.accountExpired(false)
.accountLocked(false)
.disabled(false)
// 真实数据应该是从数据库中查询出来的权限
.authorities("这是一个山寨的权限标识")
.build();
return userDetails;
}
}BCrypt算法
用于验证密码原文与密文是否对应,BCrypt算法被设计为是一种慢速运算的算法,可以一定程度上避免或缓解密码被暴力破解(使用循环进行穷举的破解)
框架引入,当添加了Spring Security相关的依赖项后,此依赖项中将包含BCryptPasswordEncoder工具类,是一个使用BCrypt算法的密码编码器,它实现了PasswordEncoder接口,并重写了接口中的String encode(String rawPassword)方法,用于对密码原文进行编码(加密),及重写了boolean matches(String rawPassword, String encodedPassword)方法
BCrypt算法会自动使用随机的盐值进行加密处理,所以,当反复对同一个原文进行加密处理,每次得到的密文都是不同的
自定义登录
目前,可以通过Spring Security的默认登录表单来实现认证,但是这并不是前后端分离的做法,因为登录页面在框架内也就是在java后端中,如果需要实现前后端分离的登录认证,需要:
禁用Spring Security的登录表单,在SecurityConfiguration的void configurer(HttpSecurity http)方法中,不再调用http.formLogin()即可
使用程序的控制器接收客户端提交的登录请求,需要将此请求的URL添加到SecurityConfiguration的“白名单”中
在Service实现类中处理登录认证需要用到AuthenticationManager对象,所以在在SecurityConfiguration配置类(继承自WebSecurityConfigurerAdapter)中重写authenticationManager()或authenticationManagerBean()方法
@Slf4j
@Configuration
public class SecurityConfiguration extends WebSecurityConfigurerAdapter {
@Bean
@Override
public AuthenticationManager authenticationManagerBean() throws Exception {
return super.authenticationManagerBean();
}
}在Service实现类中调用AuthenticationManager对象的authenticate()方法,将由Spring完成认证
调用authentication()方法时,需要传入用户名、密码,则Spring Security框架会自动调用UserDetailsService对象的loadUserByUsername()方法,并自动处理后续的认证(判断密码、enable等),认证过程中如果出现问题就会直接抛出异常
@Slf4j
@Service
public class LoginServiceImpl implements ILoginService {
@Override
public void login(AdminLoginDTO adminLoginDTO) {
Authentication authentication
= new UsernamePasswordAuthenticationToken(
adminLoginDTO.getUsername(), adminLoginDTO.getPassword());
UsernamePasswordAuthenticationToken token
= authenticationManager.authenticate(authentication);
}
}当调用了AuthenticationManager对象的authenticate()方法,且通过认证后,此方法将返回Authentication接口类型的对象,此对象的具体类型是UsernamePasswordAuthenticationToken,此对象中包含名为Principal(当事人)的属性,值为UserDetailsService对象中loadUserByUsername()返回的对象
在登录认证通过后,返回可识别的标识符给前端,用于SpringSecurity对用户访问其他接口时候的登录校验,如JWT等
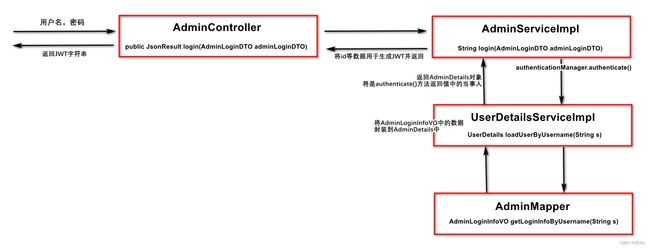
流程图
登录失败处理
当认证失败的时候SpringSecurity会抛出AuthenticationException和DisabledException异常,所以需要在全局异常处理中处理
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler {
public GlobalExceptionHandler() {
System.out.println("创建全局异常处理器对象:GlobalExceptionHandler");
}
@ExceptionHandler({
InternalAuthenticationServiceException.class,
BadCredentialsException.class
})
public String handleAuthenticationException(AuthenticationException e) {
log.debug("异常信息:{}", e.getMessage());
return e.getMessage();
}
@ExceptionHandler
public String handleDisabledException(DisabledException e) {
log.debug("捕获到DisabledException:{}", e.getMessage());
return e.getMessage();
}
}
自定义UserDetails
目前在UserDetailsServiceImpl中返回的UserDetails接口类型的对象是User类型的,此类型只有用户名和密码两个属性,如果需要添加其它属性,必须自定义类,继承自User或实现UserDetails接口,在自定义类中补充声明所需的属性
@Setter
@Getter
@EqualsAndHashCode
@ToString(callSuper = true)
public class AdminDetails extends User {
//自定义属性
private Long id;
public AdminDetails(String username, String password, boolean enabled,
Collection authorities) {
super(username, password, enabled,
true, true, true,
authorities);
}
}在UserDetailsServiceImpl中返回自定义类的对象,则处理认证通过后,返回的Authentication中的Principal就是自定义类的对象
@Slf4j
@Service
public class UserDetailsServiceImpl implements UserDetailsService {
@Override
public UserDetails loadUserByUsername(String s) throws UsernameNotFoundException {
AdminDetails adminDetails = new AdminDetails();
//其他参数自行传入
adminDetails.setId(loginInfo.getId());
return adminDetails;
}
}认证校验
Spring Security框架会自动从SecurityContext读取认证信息,如果存在有效信息,则视为已登录,否则视为未登录.
SecurityContext,是通过ThreadLocal进行处理的,所以是线程安全的,每个客户端对应的SecurityContext中的信息是互不干扰的,另外,SecurityContext中的认证信息是通过Session存储的,所以一旦向SecurityContext中存入了认证信息,在后续一段时间(Session的有效时间)的访问中,即使不携带JWT,也是允许访问的,会被视为“已登录
SpinrgSecurity对于认证是通过一连串的过滤器一步步的校验
以JWT为例,当客户端已经登录成功并得到JWT,相当于现实生活中某人已经成功购买到了火车票,接下来,此人应该携带火车票去乘车,在程序中,就表现为:客户端应该携带JWT向服务器端提交请求。关于客户端携带JWT数据,业内惯用的做法是,在服务器端,通常使用过滤器组件来解析JWT数据
当前过滤器应该尝试解析客户端可能携带的JWT,如果解析成功,则创建对应的认证信息,并存储到SecurityContext中
@Slf4j
@Component
public class JwtAuthorizationFilter extends OncePerRequestFilter {
public static final int JWT_MIN_LENGTH = 100;
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain) throws ServletException, IOException {
// 尝试获取客户端提交请求时可能携带的JWT
String jwt = request.getHeader("Authorization");
// 判断是否获取到有效的JWT,未获取则直接交给SpringSecurity处理
if (!StringUtils.hasText(jwt) || jwt.length() < JWT_MIN_LENGTH) {
filterChain.doFilter(request, response);
return;
}
// 尝试解析JWT,从中获取用户的相关数据,例如id、username等
String secretKey = "xxxxxxxxxxxxxx";
Claims claims = Jwts.parser().setSigningKey(secretKey).parseClaimsJws(jwt).getBody();
Long id = claims.get("id", Long.class);
String username = claims.get("username", String.class);
String authorityString = claims.get("authority", String.class);
// 将根据从JWT中解析得到的数据来创建认证信息
List authorities = new ArrayList<>();
GrantedAuthority authority = new SimpleGrantedAuthority(authorityString);
authorities.add(authority);
Authentication authentication = new UsernamePasswordAuthenticationToken(
username, null, authorities);
// 将认证信息存储到SecurityContext中
SecurityContext securityContext = SecurityContextHolder.getContext();
securityContext.setAuthentication(authentication);
// 放行
filterChain.doFilter(request, response);
}
} 最后需要在SecurityConfiguration中自动装配自定义的JWT过滤器,这样我们自定义的过滤器就会成为SpringSecurity认证过滤器中的一环
@Slf4j
@Configuration
public class SecurityConfiguration extends WebSecurityConfigurerAdapter {
@Autowired
JwtAuthorizationFilter jwtAuthorizationFilter;
@Override
protected void configure(HttpSecurity http) throws Exception {
http.addFilterBefore(jwtAuthorizationFilter, UsernamePasswordAuthenticationFilter.class);
}
}在JWT过滤器中,解析JWT时可能会出现异常,由于解析JWT是发生成过滤器中的,而过滤器是整个Java EE体系中最早接收到请求的组件(此时,控制器等其它组件均未开始执行),Spring MVC的全局异常处理器在控制器(Controller)抛出异常之后执行,所以此时出现的异常不可以使用,只能通过最原始的try...catch...语法捕获并处理异常,处理时需要使用到过滤器方法的第2个参数HttpServletResponse response来向客户端响应错误信息.强烈推荐在最后补充处理Throwable异常,以避免某些异常未被考虑到,并且,在处理Throwable时,应该执行e.printStackTrace(),则出现未预测的异常时,可以通过控制台看到相关信息,并在后续补充对这些异常的精准处理,异常的类型主要有
SignatureException
MalformedJwtException
ExpiredJwtException
Principal
关于SecurityContext中的认证信息,应该包含当事人(Principal)和权限(Authorities),其中,当事人(Principal)被声明为Object类型的,则可以使用任意数据类型作为当事人
在使用了Spring Security框架的项目中,当事人的数据是可以被注入到处理请求的方法中的,所以使用哪种数据作为当事人,主要取决于“你在编写控制器中处理请求的方法时,需要通过哪些数据来区分当前登录的用户”。通常,使用自定义的数据类型作为当事人,并在此类型中封装关键数据,例如id、username
在JWT过滤器创建认证信息时,使用自定义类型的对象作为认证信息中的当事人
@Slf4j
@Component
public class JwtAuthorizationFilter extends OncePerRequestFilter {
public static final int JWT_MIN_LENGTH = 100;
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain) throws ServletException, IOException {
LoginPrincipal loginPrincipal = new LoginPrincipal();
loginPrincipal.setId(id);
loginPrincipal.setUsername(username);
Authentication authentication = new UsernamePasswordAuthenticationToken(
loginPrincipal, null, authorities);
// 放行
filterChain.doFilter(request, response);
}
}完成后,在当前项目任何控制器中任何处理请求的方法上,都可以添加@AuthenticationPrincipal LoginPrincipal loginPrincipal参数(与原有的其它参数不区分先后顺序),此参数的值就是以上过滤器中存入到认证信息中的当事人,所以,可以通过这种做法,在处理请求时识别当前登录的用户
@RestController
@RequestMapping("/test")
public class TestController {
@Autowired
privage TestService testService;
@RequestMapping("/test")
public String test(
@ApiIgnore @AuthenticationPrincipal LoginPrincipal loginPrincipal) {
log.debug("当前登录的当事人:{}", loginPrincipal);
}
}配置请求权限
先在SecurityConfiguration上添加@EnableGlobalMethodSecurity(prePostEnabled = true)开启在方法上使用注解配置权限的功能
@Slf4j
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class SecurityConfiguration extends WebSecurityConfigurerAdapter {
}在任何处理请求的方法上,通过@PreAuthorize注解来配置对应请求所需的权限,只有具备/ams/admin/test权限的管理员才允许访问的,如果当前JWT对应的管理员不具备此权限,则会出现AccessDeniedException异常
@RestController
@RequestMapping("/test")
public class TestController {
@Autowired
privage TestService testService;
@RequestMapping("/test")
@PreAuthorize("hasAuthority('/ams/admin/test')")
public String test() {
}
}Shiro框架
基础配置
pom文件添加依赖
org.apache.shiro
shiro-spring-boot-web-starter
1.9.1
在configuration中配置黑白名单
@Configuration
public class ShiroConfig {
@Bean("shiroFilterFactoryBean")
public ShiroFilterFactoryBean shiroFilter(SecurityManager securityManager){
ShiroFilterFactoryBean shiroFilter=new ShiroFilterFactoryBean();
shiroFilter.setSecurityManager(securityManager);
Map filterMap = new HashMap<>();
filterMap.put("jwt",new JwtFilter());
shiroFilter.setFilters(filterMap);
//设置拦截路径
Map map=new LinkedHashMap<>();
//路径为anon标识不用被拦截,jwt表示除了上面的请求都需要经过过滤器
map.put("/login","anon");
map.put("/doc.html","anon");
map.put("/**/*.js","anon");
map.put("/**/*.css","anon");
map.put("/swagger-resources","anon");
map.put("/v2/api-docs","anon");
map.put("/**", "jwt");
shiroFilter.setFilterChainDefinitionMap(map);
return shiroFilter;
}
} 登录认证授权
Controller:UsernamePasswordToken是框架提供的便捷token
@RestController
@Api(tags = "测试模块")
public class TestController {
@ApiOperation("登录")
@PostMapping("/login")
@ApiImplicitParams({
@ApiImplicitParam(value = "用户名",name="userName",example = "123",required = true,dataType = "string"),
@ApiImplicitParam(value = "用户密码",name="password",example = "123",required = true,dataType = "string")
})
public String login(String userName, String password, HttpServletResponse response){
UsernamePasswordToken token = new UsernamePasswordToken();
token.setUsername(userName);
token.setPassword(password.toCharArray());
SecurityUtils.getSubject().login(token);
//登录成功后可以做JTW存储
response.setHeader("Authorization", "aa");
return userName+password;
}
}UserNamePasswordRealm:配置登录认证和授权
@Component
public class UserNamePasswordRealm extends AuthorizingRealm {
@Override
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
SimpleAuthorizationInfo info = new SimpleAuthorizationInfo();
String userName = ((UsernamePasswordToken)SecurityUtils.getSubject()).getUsername();
//权限应该根据用户名字去查询数据库
Set permissions = new HashSet<>();
permissions.add("buy");
info.setStringPermissions(permissions);
return info;
}
@Override
protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException {
UsernamePasswordToken usernamePasswordToken = (UsernamePasswordToken) authenticationToken;
String userName = usernamePasswordToken.getUsername();
//真实数据应该根据userName从数据库查出来
String userNameDatabase = "root";
String userPasswordDatabase = "root";
return new SimpleAuthenticationInfo(userNameDatabase, userPasswordDatabase, getName());
}
//此Realm只能UsernamePasswordToken使用
@Override
public boolean supports(AuthenticationToken token) {
return token instanceof UsernamePasswordToken;
}
}
JWT登录认证授权
配置JWT过滤器
@Component
public class JwtFilter extends BasicHttpAuthenticationFilter {
// 过滤器拦截请求的入口方法
@Override
protected boolean onAccessDenied(ServletRequest request, ServletResponse response, Object mappedValue) {
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
String token = httpServletRequest.getHeader("Authorization");
//没有携带令牌不通过
if (token==null || token.equals("")) {
return false;
}
SecurityUtils.getSubject().login(new JwtToken(token));
return true;
}
}public class JwtToken implements AuthenticationToken {
private String token;
public JwtToken(String token) {
this.token = token;
}
@Override
public Object getPrincipal() {
return token;
}
@Override
public Object getCredentials() {
return token;
}
}配置jwt的Realm
public class JwtRealm extends AuthorizingRealm {
@Override
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
SimpleAuthorizationInfo info = new SimpleAuthorizationInfo();
String user = (String) SecurityUtils.getSubject().getPrincipal();
// 这里获取到了登录信息后,可以根据用户从数据库里获取该用户所拥有的权限
// 这里只作为演示,所以就写死了几个权限存放
Set permissions = new HashSet<>();
permissions.add("buy");
info.setStringPermissions(permissions);
return info;
}
@Override
protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException {
String token = (String) authenticationToken.getCredentials();
//校验token模拟
if (!token.equals("true")){
throw new AuthenticationException("token无效");
}
String user = "root";
SimpleAuthenticationInfo simpleAuthenticationInfo = new SimpleAuthenticationInfo(user, token, this.getName());
return simpleAuthenticationInfo;
}
@Override
public boolean supports(AuthenticationToken token) {
return token instanceof JwtToken;
}
} 开启权限注解:在接口方法上添加注解
@RequiresAuthentication:表示subject已经通过登录验证,才可使用
@RequiresUser:表示subject已经身份验证或者通过记住我登录,才可使用
@RequiresGuestp:表示subject没有身份验证或通过记住我登录过,即是游客身份,才可使用
@RequiresRoles(value={“admin”, “user”}, logical=Logical.AND):表示subject需要xx(value)角色,才可使用
@RequiresPermissions (value={“user:a”, “user:b”},logical= Logical.OR):表示subject需要xxx(value)权限,才可使用
Redis框架
Redis是一款使用K-V结构的基于内存的NoSQL非关系型数据库
与Java语言中的Map相同,在Redis中的Key也是唯一的,所以当通过 set key value 命令存入数据时,如果Key不存在,则是新增数据的操作,如果Key已经存在,则是修改数据的操作
Redis是读写单线程操作的,多线程完成请求和返回
Reids是对内存的操作,所以速度快不需要多线程
避免了多线的上下文切换影响效率
Redis终端命令
redis-cli:登录Redis客户端,当登录成功后,操作提示符将变为 xxx.x.x.xxx:6379>
exit:退出,回到操作系统的终端
ping:检查Redis服务是否仍处于可用状态
shutdown:停止Redis服务
redis-server:启动Redis服务
set key value:向Redis中存入数据,如set name xxxxx
get key:从Redis中取出曾经存入的数据,如get name
keys key/keys *:查询Redis中的相关key/所有的列表
数据类型
string以字符串形式存储数据,经常用于记录用户的访问次数、文章访问量等。
hash以对象形式存储数据,比较方便的就是操作其中的某个字段,例如存储登陆用户登陆状态,实现购物车。
list以列表形式存储数据,可记录添加顺序,允许元素重复,通常应用于发布与订阅或者说消息队列、慢查询。
set以集合形式存储数据,不记录添加顺序,元素不能重复,也不能保证存储顺序,通常可以做全局去重、投票系统。
zset排序集合,可对数据基于某个权重进行排序。可做排行榜,取TOP N操作。直播系统中的在线用户列表,礼物排行榜,弹幕消息等。
导入框架
在Spring Boot项目中,要实现Redis编程,应该在pom文件中添加相关的依赖
org.springframework.boot
spring-boot-starter-data-redis
Redis的基本使用
Redis编程主要通过RedisTemplate工具来实现,应该通过配置类的@Bean方法返回此类型的对象,并在需要使用Redis编程时自动装配此对象
@Slf4j
@Configuration
public class RedisConfiguration {
public RedisConfiguration() {
log.debug("创建配置类对象:RedisConfiguration");
}
@Bean
public RedisTemplate redisTemplate(
RedisConnectionFactory redisConnectionFactory) {
RedisTemplate redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setValueSerializer(RedisSerializer.json());
return redisTemplate;
}
} 关于RedisTemplate的基本使用,在测试类中自动装配RedisTemplate并测试使用
@Slf4j
@SpringBootTest
public class RedisTests {
@Autowired
RedisTemplate redisTemplate;
//存入引用类型对象
@Test
void setObjectValue() {
String key = "test1";
Test test = new Test();
test.setId(1L);
test.setName("测试");
ValueOperations ops = redisTemplate.opsForValue();
ops.set(key, test);
}
//取出引用类型对象
@Test
void getObjectValue() {
String key = "test1";
ValueOperations ops = redisTemplate.opsForValue();
Serializable value = ops.get(key);
}
//查询Redis中所有符合表达式的Key
@Test
void keys() {
String keyPattern = "*";
Set keys = redisTemplate.keys(keyPattern);
}
//删除key-value值
@Test
void delete() {
String key = "test1";
Boolean result = redisTemplate.delete(key);
}
//删除Redis中所有符合表达式的Key-value值
@Test
void deleteX() {
String keyPattern = "*";
Set keys = redisTemplate.keys(keyPattern);
Long count = redisTemplate.delete(keys);
}
//存入List集合
@Test
void setList() {
List tests = new ArrayList<>();
for (int i = 1; i <= 8; i++) {
Test test = new Test();
test.setId(i + 0L);
test.setName("测试" + i);
tests.add(test);
}
String key = "test2";
ListOperations ops = redisTemplate.opsForList();
for (Test test : tests) {
ops.rightPush(key, test);
}
}
//查看Reids中某个List集合的长度
@Test
void listSize() {
String key = "test2";
ListOperations ops = redisTemplate.opsForList();
Long size = ops.size(key);
}
//取出Redis中的某个List集合,end=-1代表取出所有
@Test
void listRange() {
String key = "test2";
long start = 0;
long end = -1;
ListOperations ops = redisTemplate.opsForList();
List list = ops.range(key, start, end);
}
} 关于存取字符串类型的数据,直接存、取即可。
关于存取对象型的数据,由于已经将值的序列化器配置为JSON,在处理过程中框架会自动将对象序列化成JSON字符串/将JSON字符串反序列化成对象,所以对于Redis而言,操作的仍是字符串,所以在存取对象型数据时,使用的API与存取字符串完全相同。
RedisTemplate对象在保存数据到Redis时,实际上会将数据序列化后保存,这样做,对java对象或类似的数据在Redis中的读写效率较高,缺点是不能在Redis中修改这个数据,就容易在高并发情况下,由于线程安全问题导致"超卖",SpringDataRedis提供了StringRedisTemplate类型,直接操作Redis中的字符串类型对象,使用StringRedisTemplate向Redis保存数据,就没有序列化的过程,直接保存字符串值,Redis支持直接将数值格式的字符串直接进行修改,所以适合保存库存数,最后结合Redis操作数据的是单线程的特征,避免线程安全问题防止超卖
存储原理
如果需要从多个元素的集合中寻找某个元素取出,或检查某个Key在不在的时候,推荐我们使,HashMap或HashSet,因为这种数据结构的查询效率最高,因为它内部使用了"散列表"
槽位越多代表元素多的时候,查询性能越高,HashMap默认16个槽,Redis底层保存数据用的也是这样的散列表的结构,Redis将内存划分为16384个区域(类似hash槽),将数据的key使用CRC16算法计算出一个值,取余16384,得到的结果是0~16383,这样Redis就能非常高效的查找元素了
Reids存取List的原理
在Redis的List中,允许从左右两端操作列表(请将栈想像为横着的)

在读取List中的数据时,相关的API需要指定start和end,也就是读取整个列表中的某个区间的数据,无论是start还是end,都表示需要读取的数据的位置下标。在整个List中,第1个数据的下标为0,并且Redis中的List元素都有正向的和反向的下标,正向的是从0开始递增的,反向下标是以最后一个元素作为-1,并且向前递减的:

所以,如果需要读取如以上图例的列表的全部数据,start值可以为0或-8,end值可以为7或-1,通常,读取全部数据推荐使用start为0,且end为-1
使用原则
由于Redis的存取效率非常高,在开发实践中,通常会将一些数据从关系型数据库(例如MySQL)中读取出来,并写入到Redis中,后续当需要访问相关数据时,将优先从Redis中读取所需的数据,以此可以提高数据的读取效率,并且一定程度的保护关系型数据库
Redis的适用场景
高频率访问的数据
例如热门榜单
修改频率非常低的数据
例如电商平台中商品的类别
对数据的“准确性”(一致性)要求不高的
例如商品的库存余量
数据量不能太大
使用Redis的策略
直接尝试从Redis中读取数据,如果Redis中无此数据,则从MySQL中读取并写入到Redis
从运行机制上,类似单例模式中的懒汉式
当项目启动时,就直接从MySQL中读取数据并写入到Redis
从运行机制上,类似单例模式中的饿汉式,这种做法通常称之为“缓存预热”
缓存淘汰策略
Redis将数据保存在内存中, 内存的容量是有限的,如果Redis服务器的内存已经全满,现在还需要向Redis中保存新的数据,如何操作,就是缓存淘汰策略
noeviction:返回错误(默认),如果我们不想让它发生错误,就可以设置它将满足某些条件的信息删除后,再将新的信息保存
volatile-ttl:删除剩余有效时间最少的数据
allkeys-random:所有数据中随机删除数据
volatile-random:有过期时间的数据中随机删除数据
allkeys-lru:所有数据中删除上次使用时间距离现在最久的数据
volatile-lru:有过期时间的数据中删除上次使用时间距离现在最久的数据
allkeys-lfu:所有数据中删除使用频率最少的
volatile-lfu:有过期时间的数据中删除使用频率最少的
频率、距离上次使用时间、随机、直接返回
缓存问题
缓存穿透
所谓缓存穿透,就是一个业务请求先查询redis,redis没有这个数据,那么就去查询数据库,但是数据库也没有的情况,一旦发生上面的穿透现象,仍然需要连接数据库,一旦连接数据库,项目的整体效率就会被影响,如果有恶意的请求,高并发的访问数据库中不存在的数据,严重的,当前服务器可能出现宕机的情况
解决方案:业界主流解决方案:
布隆过滤器
针对现有所有数据,生成布隆过滤器,保存在Redis中
在业务逻辑层,判断Redis之前先检查这个id是否在布隆过滤器中
如果布隆过滤器判断这个id不存在,直接返回
如果布隆过滤器判断id存在,在进行后面业务执行
恶意攻击的话可以做一个数据校验
把空对象也存在Redis中并且设置一个比较短的过期时间
缓存击穿
一个计划在Redis保存的数据,业务查询,查询到的数据Redis中没有,但是数据库中有,这种情况要从数据库中查询后再保存到Redis,这就是缓存击穿
但是这个情况也不是异常情况,因为我们大多数数据都需要设置过期时间,而过期时间到时,这个数据就会从Redis中移除,再有请求查询这个数据,就一定会从数据库中再次同步,缓存击穿本身并不是灾难性的问题,也不是不允许发生的现象
解决方案
互斥锁。在并发的多个请求中,保证只有一个请求线程能拿到锁,并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
热点数据不设置过期时间,后由定时任务去异步加载数据,更新缓存。
热点数据不设置过期时间,后由定时任务去异步加载数据,更新缓存。
缓存雪崩
同一时间发生少量击穿是正常的,但是如果出现同一时间大量击穿现象就会缓存雪崩,所谓缓存雪崩,指的就是Redis中保存的数据,短时间内有大量数据同时到期的情况,本应该由Redis反馈的信息,由于雪崩都去访问了Mysql,mysql承担不了,非常可能导致异常,要想避免这种情况,就需要避免大量缓存同时失效
解决办法
我们可以通过在设置有效期时添加一个随机数,这样就能够防止大量数据同时失效了
互斥锁。在并发的多个请求中,保证只有一个请求线程能拿到锁,并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
持久化
Redis将信息保存在内存,内存的特征就是一旦断电,所有信息都丢失,对于Redis来讲,所有数据丢失后,再重新加载数据,就需要从数据库重新查询所有数据,这个操作不但耗费时间,而且对数据库的压力也非常大
而且有些业务是先将数据保存在Redis,隔一段时间和数据库同步的,如果Redis断电,这段时间的数据就完全丢失了
为了防止Redis的重启对数据库带来额外的压力和数据的丢失,Redis支持了持久化的功能,所谓持久化就是将Redis中保存的数据,以指定方式保存在Redis当前服务器的硬盘上,如果存在硬盘上,那么断电数据也不会丢失,再启动Redis时,利用硬盘中的信息来回复数据,Redis实现持久化有两种策略
RDB
RDB本质上就是数据库快照(就是当前Redis中所有数据转换成二进制的对象,保存在硬盘上),默认情况下,每次备份会生成一个dump.rdb的文件,当Redis断电或宕机后,重新启动时,会从这个文件中恢复数据,获得dump.rdb中所有内容
实现这个效果我们可以在application的Redis的配置文件中添加如下信息
save 60 5配置效果:1分钟内如果有5个key以上被修改,就启动rdb数据库快照程序
备份节点
基于配置文件中的save规则周期性的执行持久化。
手动执行了shutdown操作会自动执行rdb方式的持久化。
手动调用了save或bgsave指令执行数据持久化。
save会阻塞主线程导致无法处理请求
bgsave会fork进子线程中备份,不会阻塞主线程
主从复制(Master/Slave)架构下Slave连接到Master时,Master会对数据持久化,然后全量同步到Slave。
优点:
因为是整体Redis数据的二进制格式,体积小
只有一个文件,数据恢复是整体恢复的
缺点:
RDB 方式使用 fork 子进程进行数据的持久化,子进程的内存是在fork操作时父进程中数据快照的大小,如果数据快照比较大的话,fork 时开辟内存会比较耗时,同时这个fork是同步操作,所以,这个过程会导致父进程无法对外提供服务。
如果突然断电,只能恢复最后一次生成的rdb中的数据,造成一段时间的数据丢失
AOF
AOF策略是将Redis运行过的所有命令(日志)备份下来,保存在硬盘上,这样即使Redis断电,我们也可以根据运行过的日志,恢复为断电前的样子
我们可以在application的Redis的配置文件中添加如下配置信息
appendonly yes实际情况下,Redis非常繁忙时,我们会将日志命令缓存之后,整体发送给备份,减少io次数以提高备份的性能 和对Redis性能的影响,Linux中会把缓存写入页缓存中,然后才写入硬盘,配置一般会采用每秒将日志文件发送一次的策略,断电最多丢失1秒数据
Redis的AOF为减少日志文件的大小,支持AOF rewrite,简单来说就是将日志中无效的语句删除,能够减少占用的空间
优点:
相对RDB来讲,信息丢失的较少
当 AOF文件太大时,Redis 会自动在后台进行重写。重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。
缺点:
因为保存的是运行的日志,所以占用空间较大
Redis集群
主从复制
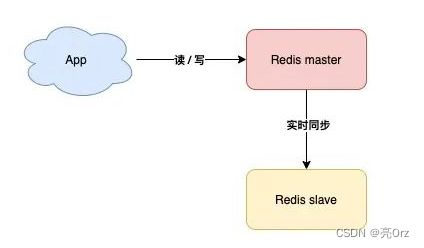
Redis最小状态是一台服务器,这个服务器的运行状态,直接决定Redis是否可用,如果它离线了,整个项目就会无Redis可用,系统会面临崩溃,为了防止这种情况的发生,我们可以准备一台备用机
也就是主机(master)工作时,安排一台备用机(slave)实时同步数据,万一主机宕机,我们可以切换到备机运行,数据的备份是单向的,只能从主节点备份到从节点,备份文件是RDB文件,缺点,这样的方案,slave节点没有任何实质作用,只要master不宕机它就和没有一样,没有体现价值
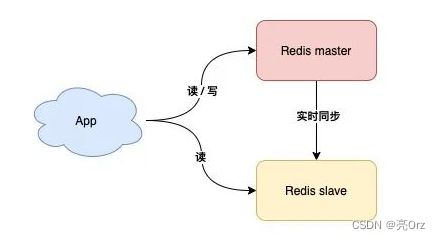
读写分离
slave在master正常工作时也能分担Master的工作了,但是如果master宕机,实际上主备机的切换,实际上还是需要人工介入的,这还是需要时间的,那么如果想实现发生故障时自动切换,一定是有配置好的固定策略的
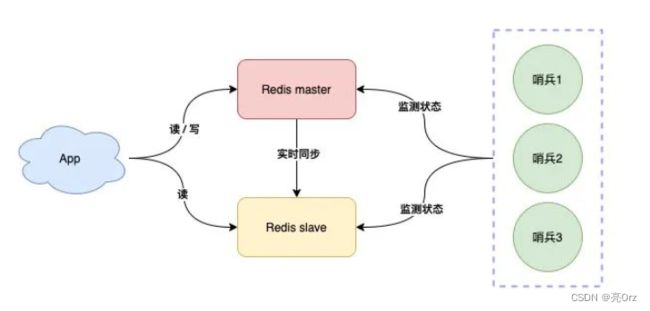
哨兵模式
故障自动切换.哨兵(sentinel)节点每隔固定时间向所有节点发送请求,如果正常响应认为该节点正常,如果没有响应,认为该节点出现问题,哨兵能自动切换主备机,如果主机master下线,自动切换到备机运行

哨兵集群
如果哨兵判断节点状态时发生了误判,那么就会错误将master下线,降低整体运行性能,所以要减少哨兵误判的可能性
我们可以将哨兵节点做成集群,由多个哨兵投票决定是否下线某一个节点,哨兵集群中,每个节点都会定时向master和slave发送ping请求,如果ping请求有2个(集群的半数节点)以上的哨兵节点没有收到正常响应,会认为该节点下线
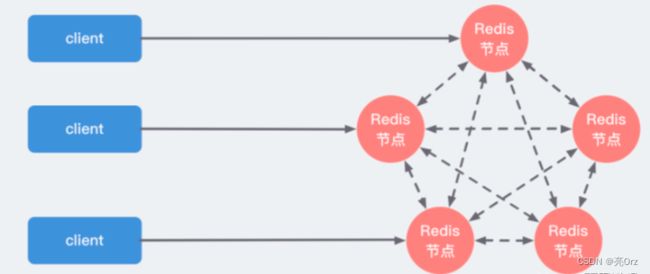
分片集群
当业务不断扩展,并发不断增高时,只有一个节点支持写操作无法满足整体性能要求时,系统性能就会到达瓶颈,这时我们就要部署多个支持写操作的节点,进行分片,来提高程序整体性能
每个Reids节点都是两两相连的
分片就是每个节点负责不同的区域,Redis0~16383号槽,例如
MasterA负责0~5000
MasterB负责5001~10000
MasterC负责10001~16383
一个key根据CRC16算法只能得到固定的结果,一定在指定的服务器上找到数据
节省成本方案
为了节省哨兵服务器的成本,有些公司在Redis集群中直接添加哨兵功能,既master/slave节点完成数据读写任务的同时也都互相检测它们的健康状态
Linux下部署Redis
Linux中已经安装好docker,输入指令拉去Redis镜像:docker pull redis
输入指令启动Redis:docker run -itd --name redis-test -p 6379:6379 redis
Redisson
利用Redis作为分布式锁,其他节点需要操作同一个数据库的时候就可以先去redis中查询当前是否有人再用,如果有的话就循环等待
原理:setnx key value 也是设置key的值为value,不过,它会先判断key是否已经存在,如果key不存在,那么就设置key的值为value,并返回1;如果key已经存在,则不更新key的值,直接返回0
Redis原始命令无法满足部分业务原子性操作的问题,Redis提供了Lua脚本的支持。Lua脚本是一种轻量小巧的脚本语言,它支持原子性操作,Redis会将整个Lua脚本作为一个整体执行,中间不会被其他请求插入,因此Redis执行Lua脚本是一个原子操作。
我们把get key value、判断value是否属于当前线程、删除锁这三步写到Lua脚本中,使它们变成一个整体交个Redis执行
application文件配置
Profile配置
Spring Boot简化了Profile配置的使用,它支持使用application-xxx.properties作为配置文件的名称,其中xxx部分是完全自定义的名称,你可以针对不同的环境,编写一组配置文件,这些配置文件中配置了相同的属性,但是值不同
application-dev.properties(推荐为“开发”环境使用的配置文件)
application-test.properties(推荐为“测试”环境使用的配置文件)
application-prod.properties(推荐为“生产”环境使用的配置文件)
在application.properties中激活后就可以生效
# 激活Profile配置
spring.profiles.active=prodappliation.properties是始终加载的配置文件,放公用的配置
YAML配置
YAML是一种使用.yml作为扩展名的配置文件,在Spring Boot项目中,默认已经集成了相关依赖项,所以可以直接使用。相对于Profile配置他更简洁
YAML的配置语法
spring:
datasource:
url: jdbc:mysql://localhost:3306/mall_ams?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Chongqing
username: root
password: '1234'项目配置
后端(服务器端)项目使用默认端口8080,建议调整可以通过配置文件中的server.port属性来指定
# 服务端口
server:
port: 9080
# 使用哪个环境下的配置文件
spring:
profiles:
active: dev
# 配置数据库
datasource:
url: jdbc:mysql://localhost:3306/mall_ams?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Chongqing
username: root
password: root
mybatis:
#扫描mapper.xml的文件路径
mapper-locations: classpath:mapper/*.xml
#开启Knife4j的增强模式
knife4j:
enable: truepom文件配置
标签
test:此依赖项仅用于测试,则此依赖项不会被打包,并且这些依赖项在src/main中不可用
runtime:此依赖项仅在运行时需要,即编写代码时并不需要此依赖项
provided:在执行(启动项目,或编译源代码)时,需要运行环境保证此依赖项一定是存在的
标签
项目中定义的版本号,这些内容本质上是变量的声明,可以在配置文件中其他地方进行引用${mybatis.version},方便管理
标签
添加依赖,子项目会全部继承这个标签下的依赖
<packaging>标签
pom:在父级项目中的pom.xml文件使用的packaging配置一定为pom,只是给子项目提供一个依赖整合,方便对个个子项目的依赖文件做管理,在maven打包并不会为这个工程打包
jar:也就是所谓的jar包,通常提供给他人使用,maven打包的时候会把这里的java文件编译成.class文件,最后整合成一个.jar文件,此文件中不会包含任何依赖的文件
war:于jar相同,都是把java文件编译成.class文件,但是包含了依赖的文件,可以直接在容器(Tomcat、Jetty等)上部署
标签
作用是在里面定义出所有子模块,然后就可以一键maven构建,不需要到一个个子模块中一个个的构建,方便.如果喜欢到子模块中一个个进行maven构建可以不需要这个标签
里面的值是子模块的相对路径
标签
只是什么依赖,并不是添加依赖,所以并不会继承给子项目,只是例举出子项目中可以选择是否使用的依赖,父项目中如果在这定义了版本号,子项目需要使用这个依赖的时候只需要引入就行,不用再定义版本号,称为锁版本
如果子项目另外定义了版本号则会使用子项目的版本号
标签
子项目继承父项目的依赖的时候,对于spring全家桶这种集成的框架依赖,可以使用这个标签去除掉自己不需要的部分依赖,减少项目最后打成war包的体积
项目配置
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.5.9
xx.xx
xxxxxxx
0.0.1
1.8
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.2.2
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
1.18.20
provided
org.springframework.boot
spring-boot-starter-test
test
com.github.xiaoymin
knife4j-spring-boot-starter
2.0.9
org.springframework.boot
spring-boot-starter-validation
JAVA后端基础
会话管理
客户端和服务器之间进行数据传输遵循的是HTTP协议,此协议属于无状态协议(一次请求对应一次响应,响应完之后端开连接),服务器是无法跟踪客户端的请求,通过Cookie技术可以给客户端添加一个标识,客户端之后发出的每次请求都会带着这个标识从而让服务器识别此客户端, 但是由于Cookie的数据是保存在客户端的存在被篡改的风险, Session技术是将数据保存在服务器端的这样就可以提高安全性,不存在被篡改的风险
通过会话管理相关的cookie和Session技术保存的数据是和客户端相关的数据,而不是用户的数据,用户的数据是保存在数据库中的.
Cookie: 数据保存在客户端(类似打孔式的会员卡)
cookie数据默认保存在浏览器的内存中,当会话结束时cookie会从内存中清除, cookie也可以修改任意保存时间,只要是设置了时间数据会从内存中保存到磁盘中
只能保存字符串类型的数据
由于cookie保存的数据会随着每次请求一起传递给服务器,Cookie是存在于请求头中的,所以单个cookie的数据存储量只能保存几k的数据
应用场景: 记住用户名和密码 通过cookie实现
Session: 数据保存在服务器(类似银行卡)
Session数据是保存在服务器内存中, 由于服务器内存资源紧张 保存的时间只有半个小时左右
类似Map结构的数据,每个客户端都有一个属于自己的Key,在服务器端有对应的Value.当某客户端第1次向服务器端提交请求时,并没有可用的Key,所以并不携带Key来提交请求,当服务器端发现客户端没有携带Key时,就会响应一个Key到客户端,客户端会将这个Key保存下来,并在后续的每一次请求中自动携带这个Key。并且服务器端为了保证各个Key不冲突,会使用UUID算法来生成各个Key。由于这些Key是用于访问Session数据的,所以一般称之为Session ID
可以保存任意对象类型的数据
单个Session没有保存数据量的限制, 但是由于服务器内存资源紧张,也不建议保存大量数据
应用场景: 记住登录状态
存在的问题:
不能直接用于集群甚至分布式系统,可以通过共享Session技术来解决
将占用服务器端的内存,则不宜长时间保存
处理密码加密
用户的密码必须被加密后再存储到数据库,否则,就存在用户账号安全问题。用户使用的原始密码通常称之为“原文”或“明文”,经过算法的运算,得到的结果通常称之为“密文”。
在处理密码加密时,不可以使用任何加密算法,因为所有加密算法都是可以被逆向运算的,也就是说,当密文、算法、加密参数作为已知条件的情况下,是可以根据密文计算得到原文的(加密算法通常是用于保障数据传输过程的安全的,并不适用于存储下来的数据安全),对存储的密码进行加密处理,通常使用消息摘要算法,算法的特点
消息(原文、原始数据)相同,则摘要相同
无论消息多长,每个算法的摘要结果长度固定
消息不同,则摘要极大概率不会相同
消息摘要算法是不可逆向运算的算法,即你永远不可能根据摘要(密文)逆向计算得到消息(原文)
常见的消息摘要算法有:
SHA系列:SHA-1、SHA-256、SHA-384、SHA-512
MD家族:MD2、MD4、MD5
Spring框架内有DigestUtils的工具类,提供了MD5的API
public class MessageDigestTests {
public void testMd5() {
String rawPassword = "123456";
String encodedPassword = DigestUtils.md5DigestAsHex(rawPassword.getBytes());
}
}只要原密码足够复杂,此原密码与密文的对应关系大概率是没有被“破解”平台收录的,则不会被破解
要求用户使用安全强度更高的原始密码
在处理加密的过程中,使用循环实现多重加密
使用位数更长的算法
加盐
单点登录(SSO)
在集群或分布式系统中,客户端在其中的某1个服务器登录,后续的请求被分配到其它服务器处理时,其它服务器也能识别用户的身份
单点登录的实现方案有
共享Session
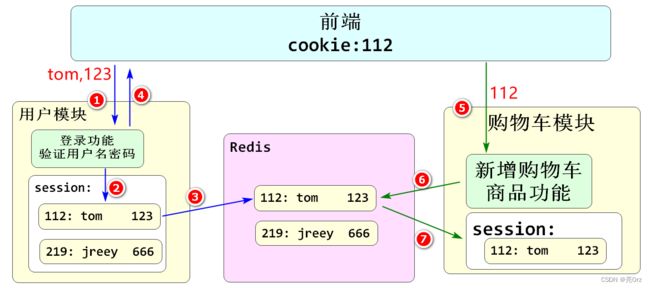
把所有客户端的Session数据存储到专门的服务器上,其它任何服务器需要识别客户端身份时,都从这个专门的服务器上去查找、读取Session数据,例如在Redis中
缺点:Session的有效期不宜过长,因为内存严重冗余,不适合大量用户的微服务项目
优点:编码简单,读取Session数据基本上没有额外牺牲性能
Token
当某客户端登录成功,服务器端将响应Token到客户端,在后续的访问中,客户端自行携带Token数据来访问任何服务器,且任何服务器都具备解析此Token的功能,即可识别客户端的身份
JWT(JSON Web Token)也是Token的一种
缺点:编写代码略难,需要频繁解析JWT,需要牺牲一部分性能来进行解析
优点:可以长时间有效

Token
Token机制是目前主流的取代Session用于服务器端识别客户端身份的机制。Token就类似于现实生活中的“火车票”,当客户端向服务器端提交登录请求时,就类似于“买票”的过程,当登录成功后,服务器端会生成对应的Token并响应到客户端,则客户端就拿到了所需的“火车票”,在后续的访问中,客户端携带“火车票”即可,并且,服务器端有“验票”机制,能够根据客户端携带的“火车票”识别出客户端的身份。
JWT
JWT:JSON Web Token,是使用JSON格式来组织多个属性于值,主要用于Web访问的Token。JWT的本质就是只一个字符串,是通过算法进行编码后得到的结果
JWT包含三个部分Header、PayloadHeader、Payload,本质是不安全的
Header使用Base64编码,可以翻译回来
Payload使用Base64编码,可以翻译回来
Signature使用自定义的加密算法,对Header,Playload和秘钥加密生成用于校验真实性
引入JWT工具包,pom文件中添加依赖
io.jsonwebtoken
jjwt
0.9.1
生成JWT和解析JWT
public class JwtTests {
String secretKey = "kns439a}fdLK34jsmfd{MF5-8DJSsLKhJNFDSjn";
//生成JWT
public void testGenerate() {
Map claims = new HashMap<>();
claims.put("id", 1);
claims.put("username", "xxxxxx");
claims.put("email", "[email protected]");
//设置过期时间
Date expirationDate = new Date(System.currentTimeMillis() + 10 * 60 * 1000);
String jwt = Jwts.builder()
// Header
.setHeaderParam("alg", "HS256")
.setHeaderParam("typ", "JWT")
// Payload
.setClaims(claims)
.setExpiration(expirationDate)
// Signature
.signWith(SignatureAlgorithm.HS256, secretKey)
// 整合
.compact();
}
//解析JWT
public void testParse(String jwt) {
Claims claims = Jwts.parser().setSigningKey(secretKey).parseClaimsJws(jwt).getBody();
Integer id = claims.get("id", Integer.class);
String username = claims.get("username", String.class);
String email = claims.get("email", String.class);
}
} 出现异常原因
如果尝试解析的JWT已经过期,则会出现ExpiredJwtException
如果尝试解析的JWT数据的签名有问题(也可能由于恶意修改正确JWT的任何部分导致),则会出现SignatureException
如果尝试解析的JWT数据的格式错误,则会出现:MalformedJwtException
安全问题
JWT是不安全的,因为在不知道secretKey的情况下,任何JWT都是可以解析出Header、Payload部分的,这2部分的数据并没有做任何加密处理,所以,如果JWT数据被暴露,则任何人都可以从中解析出Header、Payload中的数据
如果JWT数据被泄露,他人使用有效的JWT是可以正常使用的
建议
在相对比较封闭的操作系统(例如智能手机的操作系统)中,JWT的有效时间可以设置得很长
不太封闭的操作系统(例如PC端的操作系统)中,JWT的有效时间应该相对较短
不要在JWT中存放敏感数据,例如:手机号码、身份证号码、明文密码,如果一定要在JWT中存放敏感数据,应该自行使用加密算法处理过后再用于生成JWT
项目中如何使用JWT
在登录成功后只需要把生成的JWT返回给前端,由前端保存起来
在下一次访问服务器的时候客户端应该将JWT放在请求头(Request Headers)中名为Authorization的属性中,由后端进行校验.如果使用了SpringSecurity框架的话,通常使用过滤器组件来解析JWT数据
因为JWT配置在请求的Authorization中,此请求会被视为“复杂请求”,则会要求执行“预检”(PreFlight),如果预检不通过,则会导致跨域请求错误.如果使用了SpringSecurity框架的话需要对需要在SecurityConfiguration的configurer()方法中对预检请求放行
在处理JWT时,无论是生成JWT,还是解析JWT,都需要使用同一个secretKey,则应该将此secretKey定义在某个类中作为静态常量,或定义在配置文件(application.yml或等效的配置文件)中,由于此值是允许被软件的使用者(甲方)自行定义的,所以更推荐定义在配置文件中
# 自定义配置
xxxxx:
jwt:
secret-key: kns439a}fdLK34jsmfd{MF5-8DJSsLKhJNFDSjn@Value("${xxxxx.jwt.secret-key}")
String secretKey;以上使用的@Value注解可以读取当前项目中的全部环境变量,将包括:操作系统的环境变量、JVM的环境变量、各配置文件中的配置。并且@Value注解可以添加在全局属性上,也可以添加在被Spring自动调用的方法的参数上。
异常处理
在JWT过滤器中,解析JWT时可能会出现异常,异常的类型主要有:
SignatureException
MalformedJwtException
ExpiredJwtException
WEB服务器
Web服务器就是一个能够接收http请求并作出响应的程序,我们现在开发的标准SpringBoot项目启动时内置的Web服务器叫Tomcat,实际上我们业界中还有很多Web服务器,它们具备很多不同的特征,网关Gateway项目使用Netty服务器,Netty服务器内部是NIO的所以性能更好
Tomcat是也有缺点,常规情况下,一个tomcat并发数在100多一点,一般情况下,一个网站要1000人在线,并发数是2%~5% 也就是20~50并发,如果需要一个支持更高并发的服务器,就是需要使用Nginx
CSRF攻击
攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的
令牌同步模式是目前主流的CSRF攻击防御方案。具体的操作方式就是在每一个HTTP请求中,除了默认自动携带的Cookie参数之外,再提供一个安全的、随机生成的宇符串,我们称之为CSRF令牌。这个CSRF令牌由服务端生成,生成后在HttpSession中保存一份。当前端请求到达后,将请求携带的CSRF令牌信息和服务端中保存的令牌进行对比,如果两者不相等,则拒绝掉该HTTP请求。
服务器开发常见问题
跨域问题
默认情况下,不允许向别的服务提交异步请求,例如,在http://localhost:9000服务上,向http://localhost:8080提交异步请求,这是不允许的
配置CORS允许跨域请求
如果客户端向服务器端提交请求,在跨域的前提下,如果提交的请求配置了请求头中的非典型参数,例如配置了Authorization,此请求会被视为“复杂请求”,则会要求执行“预检”(PreFlight),如果预检不通过,则会导致跨域请求错误
在基于Spring Boot的项目中,要允许跨域访问,需要在实现了WebMvcConfigurer接口的配置类中,通过重写addCorsMappings()方法进行配置,这样对于大多数的简单跨域请求都能通过,对于部分复杂请求需要另外处理
@Configuration
public class WebMvcConfiguration implements WebMvcConfigurer {
public WebMvcConfiguration() {
System.out.println("创建配置类:WebMvcConfiguration");
}
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOriginPatterns("*")
.allowedMethods("*")
.allowedHeaders("*")
.allowCredentials(true)
.maxAge(3600);
}
}Autowired提示警告问题
关于在属性上使用@Autowired时的提示:Field injection is not recommended,其意思是“字段注入是不推荐的”,警告提示出现的原因如下
开发工具认为,你有可能在某些情况下自行创建当前类的对象,例如自行编写代码:TestController testController = new TestController();,由于是自行创建的对象,Spring框架在此过程中是不干预的,则类的属性ITestService testService将不会由Spring注入值,如果此时你也没有为这个属性赋值,则这个的属性就是null,如果还执行类中的方法,就可能导致NPE(NullPointerException),这种情况可能发生在单元测试中。
开发工具建议使用构造方法注入,即使用带参数的构造方法,且通过构造方法为属性赋值,并且类中只有这1个构造方法,在这种情况下,即使自行创建对象,由于唯一的构造方法是带参数的,所以,创建对象时也会为此参数赋值,不会出现属性没有值的情况,所以,通过构造方法为属性注入值的做法被认为是安全的,是建议使用的做法
开发实践,通常并不会使用构造方法注入属性的值,因为属性的增、减都需要调整构造方法,并且如果类中需要注入值的属性较多,也会导致构造方法的参数较多,不是推荐的