ceph源码阅读 erasure-code
1、ceph纠删码
纠删码(Erasure Code)是比较流行的数据冗余的存储方法,将原始数据分成k个数据块(data chunk),通过k个数据块计算出m个校验块(coding chunk)。把n=k+m个数据块保存在不同的节点,通过n中的任意k个块还原出原始数据。EC包含编码和解码两个过程。
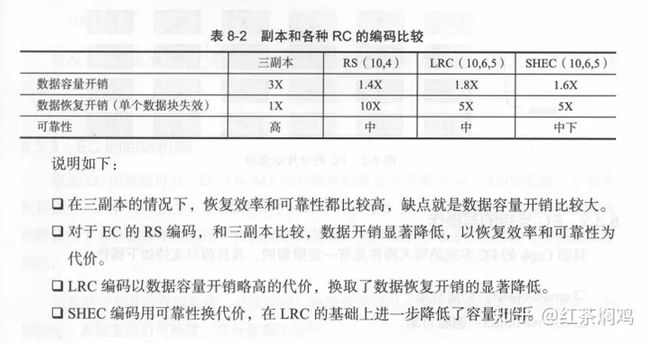
ceph中的EC编码是以插件的形式来提供的。EC编码有三个指标:空间利用率、数据可靠性和恢复效率。ceph提供以下几种纠删码插件:clay(coupled-layer)、jerasure、lrc、shec、isa。
clay:用于在修复失败的节点/OSD/rack时节省网络带宽和磁盘IO。
jerasure:开源库,目前ceph默认的编码方式。
isa:isa是Intel提供的EC库,利用intel处理器指令加速计算,只能运行在Intel CPU上。
lrc:将校验块分为全局校验块和局部校验块,减少单个节点失效后恢复过程的网络开销。
shec:shec(k,m,l),k为data chunk,m为coding chunk,l代表计算coding chunk时需要的data chunk数量。其最大允许失效数据块为:ml/k,恢复失效的单个数据块(data chunk)只需要额外读取l个数据块。
2、erasure-code文件结构
erasure-code是ceph的纠删码核心模块,包含5个文件夹和ErasureCodeInterface、ErasureCode、ErasureCodePlugin,采用工厂模式。
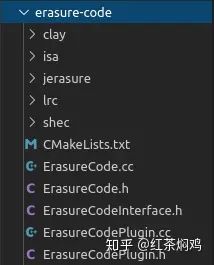
- clay、isa、jerasure、lrc、shec是ceph的EC插件。
- ErasureCodeInterface:提供EC插件的共有接口,每个接口有详细的说明。
- ErasureCode:提供获取纠删码参数和核心编码、解码接口。
- ErasureCodePlugin:提供纠删方式事件的注册、添加、删除登功能。
3、数据条带化
存储设备都有吞吐量限制,它会影响性能和伸缩性,所以存储系统一般都支持条带化(把连续的信息分片存储于多个设备)以增加吞吐量和性能。
- 基本概念
块(chunk):基于纠删码编码时,每次编码将产生若干大小相同的块(要求这些块时有序的,否则无法解码)。ceph通过数量相等的PG将这些分别存储在不同的osd中。
条带(strip):如果编码对象太大,可分多次进行编码,每次完成编码的部分称为条带。同一个对内的条带时有序的。
分片(shared):同一个对象中所有序号相同的块位于同一个PG上,他们组成对象的一个分片,分片的编号就是块的序号。
空间利用率(rate):通过k/n计算。
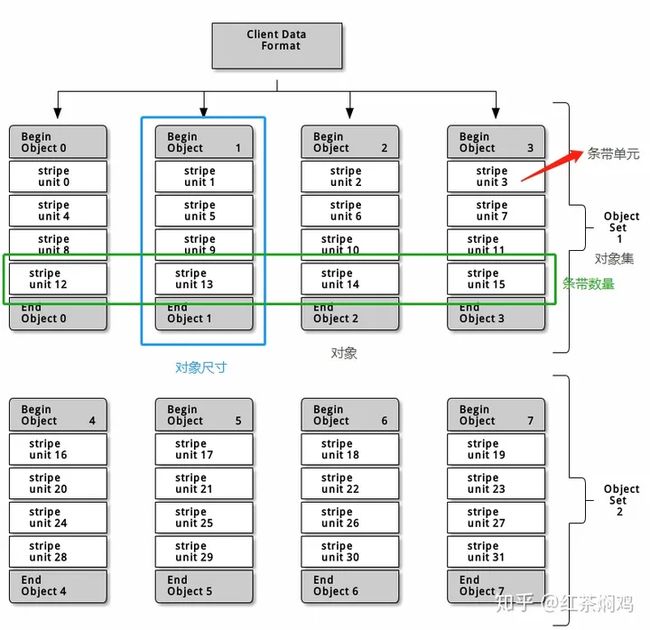
对象尺寸: Ceph 存储集群里的对象有最大可配置尺寸(如 2MB 、 4MB 等等),对象尺寸必须足够大以便容纳很多条带单元、而且应该是条带单元的整数倍。
条带数量: Ceph 客户端把一系列条带单元写入由条带数量所确定的一系列对象,这一系列的对象称为一个对象集。客户端写到对象集内的最后一个对象时,再返回到第一个。
条带宽度: 条带都有可配置的单元尺寸(如 64KB )。 Ceph 客户端把数据等分成适合写入对象的条带单元,除了最后一个。条带宽度应该是对象尺寸的分片,这样对象才能 包含很多条带单元。
strip_width=chunk_size*strip_size
假设有EC(k=4,m=2),strip_size=4,chunk_size=1K,那么strip_width=4K。在ceph中,strip_width默认为4K。
- 数据条带化过程
如果要处理大尺寸图像、大 S3 或 Swift 对象(如视频)、或大的 CephFS 目录,你就能看到条带化到一个对象集中的多个对象能带来显著的读/写性能提升。当客户端把条带单元并行地写入相应对象时,就会有明显的写性能,因为对象映射到了不同的归置组、并进一步映射到不同 OSD ,可以并行地以最大速度写入。
在上图中,客户端数据条带化到一个对象集(上图中的objectset1),它包含 4 个对象,其中,第一个条带单元是object0的stripe unit 0、第四个条带是object3的stripe unit 3,写完第四个条带,客户端要确认对象集是否满了。如果对象集没满,客户端再从第一个对象起写入条带(上图中的object0);如果对象集满了,客户端就得创建新对象集(上图的object set 2),然后从新对象集中的第一个对象(上图中的object 4)起开始写入第一个条带(stripe unit16)。
4、源码解析
- 编码流程
ECUtil::encode是将原始数据按条带宽度进行分割,然后对条带数据编码,得到条带的数据块和校验块。把每个条带化数据块和校验块有序的链接,形成数据块和校验块。
int ECUtil::encode(
const stripe_info_t &sinfo,
ErasureCodeInterfaceRef &ec_impl,
bufferlist &in,
const set &want,
map *out)
....
//文件每次按strip_width的大小进行encode编码
for (uint64_t i = 0; i < logical_size; i += sinfo.get_stripe_width()) {
map encoded;
bufferlist buf;
buf.substr_of(in, i, sinfo.get_stripe_width());
//调用对应的纠删码方式进行编码
int r = ec_impl->encode(want, buf, &encoded);
ceph_assert(r == 0);
//将条带化的数据块和校验块追加到out
for (map::iterator i = encoded.begin();
i != encoded.end();
++i) {
ceph_assert(i->second.length() == sinfo.get_chunk_size());
(*out)[i->first].claim_append(i->second);
}
}
....
return 0;
}
接下来深入分析ec_impl->encode(want, buf,&encoded),ErasureCode是ErasureCodeInterface的子类,因此调用ErasureCode::encode。在ErasureCode::encode主要是进行map
int ErasureCode::encode(const set &want_to_encode,
const bufferlist &in,
map *encoded)
{
unsigned int k = get_data_chunk_count();
unsigned int m = get_chunk_count() - k;
bufferlist out;
//encoded的内存块分配
int err = encode_prepare(in, *encoded);
if (err)
return err;
//进行编码操作
encode_chunks(want_to_encode, encoded);
for (unsigned int i = 0; i < k + m; i++) {
if (want_to_encode.count(i) == 0)
encoded->erase(i);
}
return 0;
}
ErasureCode::encode_prepare()进行参数初始化和内存分配。
int ErasureCode::encode_prepare(const bufferlist &raw,
map &encoded) const
{
unsigned int k = get_data_chunk_count();
unsigned int m = get_chunk_count() - k;
//每个块的大小
unsigned blocksize = get_chunk_size(raw.length());
//空白块的个数
unsigned padded_chunks = k - raw.length() / blocksize;
bufferlist prepared = raw;
//将数据raw按blocksize大小有序分割,并将分割后的块有序写入到encoded
for (unsigned int i = 0; i < k - padded_chunks; i++) {
bufferlist &chunk = encoded[chunk_index(i)];
chunk.substr_of(prepared, i * blocksize, blocksize);
chunk.rebuild_aligned_size_and_memory(blocksize, SIMD_ALIGN);
ceph_assert(chunk.is_contiguous());
}
if (padded_chunks) {
unsigned remainder = raw.length() - (k - padded_chunks) * blocksize;
bufferptr buf(buffer::create_aligned(blocksize, SIMD_ALIGN));
raw.copy((k - padded_chunks) * blocksize, remainder, buf.c_str());
buf.zero(remainder, blocksize - remainder);
encoded[chunk_index(k-padded_chunks)].push_back(std::move(buf));
for (unsigned int i = k - padded_chunks + 1; i < k; i++) {
bufferptr buf(buffer::create_aligned(blocksize, SIMD_ALIGN));
buf.zero();
encoded[chunk_index(i)].push_back(std::move(buf));
}
}
for (unsigned int i = k; i < k + m; i++) {
bufferlist &chunk = encoded[chunk_index(i)];
chunk.push_back(buffer::create_aligned(blocksize, SIMD_ALIGN));
}
return 0;
}
以上的工作完成后,可以开始正式的编码encode_chunks()。这里假设编码方式为jerasure,选用RS码。
int ErasureCodeJerasure::encode_chunks(const set &want_to_encode,
map *encoded)
{
char *chunks[k + m];
for (int i = 0; i < k + m; i++)
chunks[i] = (*encoded)[i].c_str();
jerasure_encode(&chunks[0], &chunks[k], (*encoded)[0].length());
return 0;
}
jerasure_encode()是调用jerasure库的编码函数。
void ErasureCodeJerasureReedSolomonVandermonde::jerasure_encode(char **data,
char **coding,
int blocksize)
{
jerasure_matrix_encode(k, m, w, matrix, data, coding, blocksize);
}
- 解码流程
ECUtil::decode函数有两个,挑个简单的来分析。
下面的decode()函数初始化数据,并进行解码。
int ECUtil::decode(
const stripe_info_t &sinfo,
ErasureCodeInterfaceRef &ec_impl,
map &to_decode,
bufferlist *out) {
ceph_assert(to_decode.size());
uint64_t total_data_size = to_decode.begin()->second.length();
....
for (uint64_t i = 0; i < total_data_size; i += sinfo.get_chunk_size()) {
map chunks;
for (map::iterator j = to_decode.begin();
j != to_decode.end();
++j) {
chunks[j->first].substr_of(j->second, i, sinfo.get_chunk_size());
}
bufferlist bl;
int r = ec_impl->decode_concat(chunks, &bl);
ceph_assert(r == 0);
ceph_assert(bl.length() == sinfo.get_stripe_width());
out->claim_append(bl);
}
return 0;
}
ErasureCode::decode_concat()进行解码,并且链接哥哥数据块,还原出原数据。
int ErasureCode::decode_concat(const map &chunks,
bufferlist *decoded)
{
set want_to_read;
for (unsigned int i = 0; i < get_data_chunk_count(); i++) {
want_to_read.insert(chunk_index(i));
}
map decoded_map;
//解码核心部分
int r = _decode(want_to_read, chunks, &decoded_map);
if (r == 0) {
//将解码后的数据块链接
for (unsigned int i = 0; i < get_data_chunk_count(); i++) {
decoded->claim_append(decoded_map[chunk_index(i)]);
}
}
return r;
}
同样地,这里也是假设使用纠删码插件为jerasure。jerasure_decode()是调用jerasure库的解码函数。
int ErasureCodeJerasure::decode_chunks(const set &want_to_read,
const map &chunks,
map *decoded)
{
unsigned blocksize = (*chunks.begin()).second.length();
int erasures[k + m + 1];//记录丢失块的编号
int erasures_count = 0;//丢失块的个数
char *data[k];
char *coding[m];
for (int i = 0; i < k + m; i++) {
if (chunks.find(i) == chunks.end()) {
erasures[erasures_count] = i;
erasures_count++;
}
if (i < k)
data[i] = (*decoded)[i].c_str();
else
coding[i - k] = (*decoded)[i].c_str();
}
erasures[erasures_count] = -1;
ceph_assert(erasures_count > 0);
return jerasure_decode(erasures, data, coding, blocksize);
}
参考资料:
1、体系结构 - Ceph Documentation
2、ceph源码分析 常涛
3、ceph设计原理与实现