数据库中使用自增量字段与Guid字段作主键的性能对比
1.概述:
在我们的数据库设计中,数据库的主键是必不可少的,主键的设计对整个数据库的设计影响很大.我就对自动增量字段与Guid字段的性能作一下对比,欢迎大家讨论.
2.简介:
1.自增量字段
自增量字段每次都会按顺序递增,可以保证在一个表里的主键不重复。除非超出了自增字段类型的最大值并从头递增,但这几乎不可能。使用自增量字段来做主键是非常简单的,一般只需在建表时声明自增属性即可。
自增量的值都是需要在系统中维护一个全局的数据值,每次插入数据时即对此次值进行增量取值。当在当量产生唯一标识的并发环境中,每次的增量取值都必须最此全局值加锁解锁以保证增量的唯一性。这可能是一个并发的瓶颈,会牵扯一些性能问题。
在数据库迁移或者导入数据的时候自增量字段有可能会出现重复,这无疑是一场恶梦(本人已经深受其害).
如果要搞分布式数据库的话,这自增量字段就有问题了。因为,在分布式数据库中,不同数据库的同名的表可能需要进行同步复制。一个数据库表的自增量值,就很可能与另一数据库相同表的自增量值重复了。
2.uniqueidentifier(Guid)字段
在MS Sql 数据库中可以在建立表结构是指定字段类型为uniqueidentifier,并且其默认值可以使用NewID()来生成唯一的Guid(全局唯一标识 符).使用NewID生成的比较随机,如果是SQL 2005可以使用NewSequentialid()来顺序生成,在此为了兼顾使用SQL 2000使用了NewID().
Guid:指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的,其算法是通过以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字生成。其格式为:04755396-9A29-4B8C-A38D-00042C1B9028.
Guid的优点就是生成的id比较唯一,不管是导出数据还是做分步开发都不会出现问题.然而它生成的id比较长,占用的数据库空间也比较多,随着外存价格的下降,这个也无需考虑.另外Guid不便于记忆,在这方面不如自动增量字段,在作调试程序的时候不太方便。
3.测试:
1.测试环境
操作系统:windows server 2003 R2 Enterprise Edition Service Pack 2
数据库:MS SQL 2005
CPU:Intel(R) Pentium(R) 4 CPU 3.40GHz
内存:DDRⅡ 667 1G
硬盘:WD 80G
2.数据库脚本
 -- 自增量字段表 CREATE TABLE [ dbo ] . [ Table_Id ] ( [ Id ] [ int ] IDENTITY ( 1 , 1 ) NOT NULL , [ Value ] [ varchar ] ( 50 ) COLLATE Chinese_PRC_CI_AS NULL , CONSTRAINT [ PK_Table_Id ] PRIMARY KEY CLUSTERED ( [ Id ] ASC ) WITH (IGNORE_DUP_KEY = OFF ) ON [ PRIMARY ] ) ON [ PRIMARY ] GO -- Guid字段表 CREATE TABLE [ dbo ] . [ Table_Guid ] ( [ Guid ] [ uniqueidentifier ] NOT NULL CONSTRAINT [ DF_Table_Guid_Guid ] DEFAULT ( newid ()), [ Value ] [ varchar ] ( 50 ) COLLATE Chinese_PRC_CI_AS NULL , CONSTRAINT [ PK_Table_Guid ] PRIMARY KEY CLUSTERED ( [ Guid ] ASC ) WITH (IGNORE_DUP_KEY = OFF ) ON [ PRIMARY ] ) ON [ PRIMARY ] GO
-- 自增量字段表 CREATE TABLE [ dbo ] . [ Table_Id ] ( [ Id ] [ int ] IDENTITY ( 1 , 1 ) NOT NULL , [ Value ] [ varchar ] ( 50 ) COLLATE Chinese_PRC_CI_AS NULL , CONSTRAINT [ PK_Table_Id ] PRIMARY KEY CLUSTERED ( [ Id ] ASC ) WITH (IGNORE_DUP_KEY = OFF ) ON [ PRIMARY ] ) ON [ PRIMARY ] GO -- Guid字段表 CREATE TABLE [ dbo ] . [ Table_Guid ] ( [ Guid ] [ uniqueidentifier ] NOT NULL CONSTRAINT [ DF_Table_Guid_Guid ] DEFAULT ( newid ()), [ Value ] [ varchar ] ( 50 ) COLLATE Chinese_PRC_CI_AS NULL , CONSTRAINT [ PK_Table_Guid ] PRIMARY KEY CLUSTERED ( [ Guid ] ASC ) WITH (IGNORE_DUP_KEY = OFF ) ON [ PRIMARY ] ) ON [ PRIMARY ] GO
测试代码
using System;2
using System.Collections.Generic;3
using System.Text;4
using System.Data.SqlClient;5
using System.Diagnostics;6
using System.Data;7
8
namespace GuidTest9
 {
{10
 class Program
class Program11
 {
{ 12
string Connnection = "server=.;database=GuidTest;Integrated Security=true;";13
static void Main(string[] args)14
{15
Program app = new Program();16
int Count = 10000;17
Console.WriteLine("数据记录数为{0}",Count);18
//自动id增长测试;19
Stopwatch WatchId = new Stopwatch();20
Console.WriteLine("自动增长id测试");21
Console.WriteLine("开始测试");22
WatchId.Start();23
Console.WriteLine("测试中 ");
");24
25
app.Id_InsertTest(Count);26
//app.Id_ReadToTable(Count);27
//app.Id_Count();28
29
//查询第300000条记录;30
//app.Id_SelectById();31
32
WatchId.Stop();33
Console.WriteLine("时间为{0}毫秒",WatchId.ElapsedMilliseconds);34
Console.WriteLine("测试结束");35
36
Console.WriteLine("-----------------------------------------");37
//Guid测试;38
Console.WriteLine("Guid测试");39
Stopwatch WatchGuid = new Stopwatch();40
Console.WriteLine("开始测试");41
WatchGuid.Start();42
Console.WriteLine("测试中");43
44
app.Guid_InsertTest(Count);45
//app.Guid_ReadToTable(Count);46
//app.Guid_Count();47
48
//查询第300000条记录;49
//app.Guid_SelectById();50
51
WatchGuid.Stop();52
Console.WriteLine("时间为{0}毫秒", WatchGuid.ElapsedMilliseconds);53
Console.WriteLine("测试结束");54
Console.Read();55
 }
}56
57
/// 58
/// 自动增长id测试59
/// 60
private void Id_InsertTest(int count)61
{62
string InsertSql="insert into Table_Id ([Value]) values ({0})";63
using (SqlConnection conn = new SqlConnection(Connnection))64
{65
conn.Open();66
SqlCommand com = new SqlCommand();67
for (int i = 0; i < count; i++)68
{69
com.Connection = conn;70
com.CommandText = string.Format(InsertSql, i);71
com.ExecuteNonQuery();72
}73
}74
}75
76
/// 77
/// 将数据读到Table78
/// 79
private void Id_ReadToTable(int count)80
{81
string ReadSql = "select top " + count.ToString() + " * from Table_Id";82
using (SqlConnection conn = new SqlConnection(Connnection))83
{84
SqlCommand com = new SqlCommand(ReadSql, conn);85
SqlDataAdapter adapter = new SqlDataAdapter(com);86
DataSet ds = new DataSet();87
adapter.Fill(ds);88
Console.WriteLine("数据记录数为:{0}", ds.Tables[0].Rows.Count);89
}90
}91
92
/// 93
/// 数据记录行数测试94
/// 95
private void Id_Count()96
{97
string ReadSql = "select Count(*) from Table_Id";98
using (SqlConnection conn = new SqlConnection(Connnection))99
{100
SqlCommand com = new SqlCommand(ReadSql, conn);101
conn.Open();102
object CountResult = com.ExecuteScalar();103
conn.Close();104
Console.WriteLine("数据记录数为:{0}",CountResult);105
}106
}107
108
/// 109
/// 根据id查询;110
/// 111
private void Id_SelectById()112
{113
string ReadSql = "select * from Table_Id where Id="+300000;114
using (SqlConnection conn = new SqlConnection(Connnection))115
{116
SqlCommand com = new SqlCommand(ReadSql, conn);117
conn.Open();118
object IdResult = com.ExecuteScalar();119
Console.WriteLine("Id为{0}", IdResult);120
conn.Close();121
}122
}123
124
/// 125
/// Guid测试;126
/// 127
private void Guid_InsertTest(int count)128
{129
string InsertSql = "insert into Table_Guid ([Value]) values ({0})";130
using (SqlConnection conn = new SqlConnection(Connnection))131
{132
conn.Open();133
SqlCommand com = new SqlCommand();134
for (int i = 0; i < count; i++)135
{136
com.Connection = conn;137
com.CommandText = string.Format(InsertSql, i);138
com.ExecuteNonQuery();139
}140
}141
}142
143
/// 144
/// Guid格式将数据库读到Table145
/// 146
private void Guid_ReadToTable(int count)147
{148
string ReadSql = "select top "+count.ToString()+" * from Table_GuID";149
using (SqlConnection conn = new SqlConnection(Connnection))150
{151
SqlCommand com = new SqlCommand(ReadSql, conn);152
SqlDataAdapter adapter = new SqlDataAdapter(com);153
DataSet ds = new DataSet();154
adapter.Fill(ds);155
Console.WriteLine("数据记录为:{0}", ds.Tables[0].Rows.Count);156
}157
}158
159
/// 160
/// 数据记录行数测试161
/// 162
private void Guid_Count()163
{164
string ReadSql = "select Count(*) from Table_Guid";165
using (SqlConnection conn = new SqlConnection(Connnection))166
{167
SqlCommand com = new SqlCommand(ReadSql, conn);168
conn.Open();169
object CountResult = com.ExecuteScalar();170
conn.Close();171
Console.WriteLine("数据记录为:{0}", CountResult);172
}173
}174
175
/// 176
/// 根据Guid查询;177
/// 178
private void Guid_SelectById()179
{180
string ReadSql = "select * from Table_Guid where Guid='C1763624-036D-4DB9-A1E4-7E16318C30DE'";181
using (SqlConnection conn = new SqlConnection(Connnection))182
{183
SqlCommand com = new SqlCommand(ReadSql, conn);184
conn.Open();185
object IdResult = com.ExecuteScalar();186
Console.WriteLine("Guid为{0}", IdResult);187
conn.Close();188
}189
}190
}191
192
 }
} 193
3.数据库的插入测试
测试1
数据库量为:100条
运行结果

测试2
数据库量为:10000条
运行结果

测试3
数据库量为:100000条
运行结果
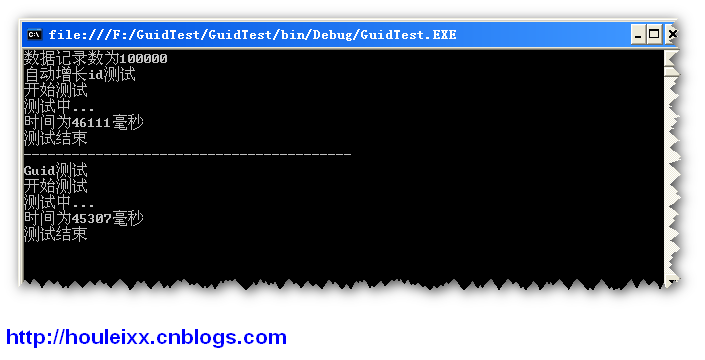
测试4
数据库量为:500000条
运行结果

4.将数据读到DataSet中
测试1
读取数据量:100
运行结果
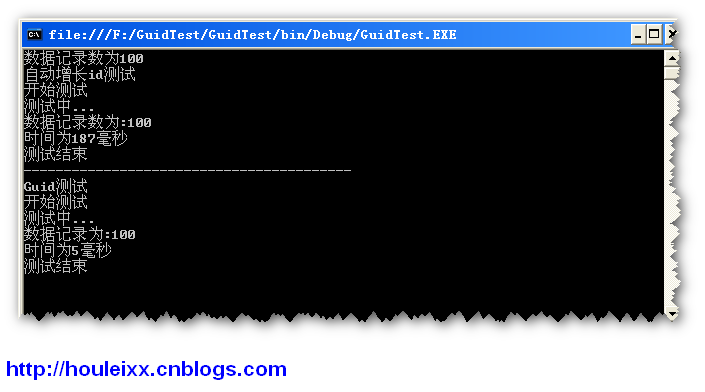
测试2
读取数据量:10000
运行结果
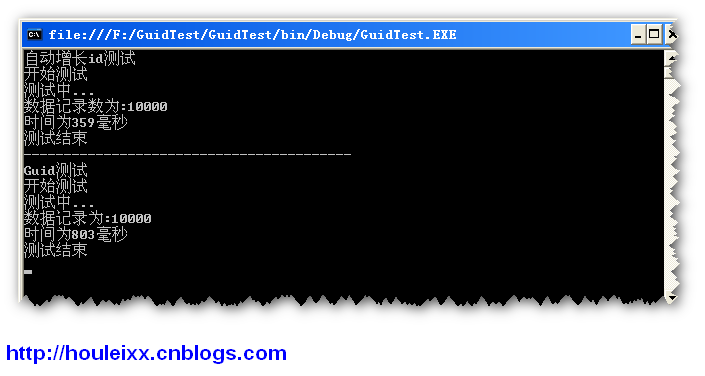
测试3
读取数据量:100000
运行结果

测试4
读取数据量:500000
运行结果

4.记录总数测试
测试结果

5.指定条件查询测试
查询数据库中第300000条记录,数量记录量为610300.

4.总结:
使用Guid作主键速度并不是很慢,它反而要比使用自动增长型的增量速度还要快.
5.参考:
http://www.cnblogs.com
http://www.cnblogs.com/leadzen/archive/2008/05/10/1191010.html
5.2.2 选择主键
主键是能够惟一地定义一行数据的一列或多列。主键中的列值不能设置为null值。主键为数据库引擎提供了一种获取数据库表中某个特定行的方法。主键还用于保证引用的完整性。在处理非连接数据时,如果多个用户同时插入数据,则必须确保不会出现重复的主键。
1. 对比智能键、常规键和代理键
智能键是一种基于商业数据表示的键。例如,SKU(Stock Keeping Unit,常用保存单元)就是智能键的一个例子,它定义为一个包含10个字符的字段(在数据库中定义为CHAR(10))。该SKU可能包含以下信息:前四个字符保存供应商代号,随后的三个字符保存产品类型代号,最后三个字符保存一个序列号。
常规键(natural primary key)由商业数据中现有的单个或多个列构成,用于惟一地标识记录。例如,某个现有的商业过程可能要使用社会保险号来标识医院的患者。
尽管智能键和常规键互不相同,但它们都由使用商业相关数据的列构成,并且用户一般都可以查看它们。本书以后将这些键统一称为智能键。
代理主键的键值是由系统生成的,这些值与行中的商业数据没有关系,因此又称为非智能键(dumb key)。本书以后将这些键统一称为代理键(surrogate key)。自动增值的列就是这种键的一个例子,在添加新的行时,该列的值将相应地设置为1,2,3…,依此类推。在Microsoft SQL Server中,自动增值的列称为Identity列。本书以后将这种键统一称为Identity键(identity key)。GUID(globally unique identifier,全局惟一标识符)是另一个由系统生成键值的例子,它通过使用取值算法来生成惟一的键值。本书以后将这种键统一称为GUID键。
专家推荐使用哪一种主键类型呢?不同的专家有着各自的见解。大家在做出选择之前,应深入地理解各种方法的主要优缺点。
图5.3显示了智能键和代理键的一种实现示例。该示例包含三个表:第一个表用于保存作者数据,第二个表用于保存书籍数据,第三个表是一个多对多的联接表(join table),因为一个作者能够编写多本书籍,一本书籍也能够由多个作者共同编写。
注意,代理主键的实现在TblAuthor和TblBook表中额外包含了一个Id列,因为代理主键的键值是由系统生成的,与行数据无关。用户应不能看见代理主键。下面,我们将分析智能键与代理主键之间在实现上的差异。
数据大小 数据大小本身并不十分重要,重要的是在数据库和客户之间传输数据时所占用的带宽。代理主键的实现在每个主表中都额外增加了一列。这将显著地增大数据量的大小。如果代理主键是一个GUID列,则增加的列将使每行增加16个字节。如果增加的是一个自动增值的列,则因该列引起的数据增量取决于所选用的数据类型(int型增加4个字节,long型增加8个字节)。由于联接表通常包含数量庞大的行记录,因此在分析数据库大小的总体差异时,一定要考虑到智能键与代理主键在数据增量大小方面的差异。此外,主键通过创建一个惟一索引来确保自身的惟一性,因此还要考虑到这方面的数据增量。表5.1列出了每种主键类型在数据增量方面的比较结果。
智能键 代理键
图5.3 智能键和代理键的实现示例
表5.1 主键大小示例
| 描述 |
智能键 |
Identity键(int型) |
GUID键 |
| 1000条作者记录 |
9个字节/SSN = 9,000个字节 |
4个字节/int = 4,000个字节 |
16个字节/GUID = 16,000个字节 |
| 3000条书籍记录 |
10个字节/ISBN = 30,000个字节 |
4个字节/int = 12,000个字节 |
16个字节/GUID = 48,000个字节 |
| 10,000条作者/书籍记录 |
19个字节/键= 190,000个字节 |
8个字节/键 = 80,000个字节 |
32个字节/键 = 320,000个字节 |
| 小计 |
229,000个字节 |
96,000个字节 |
384,000个字节 |
| 索引 |
229,000个字节 |
96,000个字节 + 9000个SSN + 30,000个ISBN = 135,000个字节 |
384,000个字节 + 9000个SSN + 30,000个ISBN = 423,000个字节 |
| 总数 |
458,000个字节 |
231,000个字节 |
807,000个字节 |
显然,Identity键是这一比较回合的赢家,但要记住的是,int型的最大值是231-1=2 147 483 647。对于大多数应用程序而言,该值已经足够了,但是有些应用程序需要使用long数据类型来保存更多的记录。注意,计算不同类型索引大小的方法是互不相同的。代理键的实现仍需要在SSN列和ISBN列上提供一个惟一索引,以确保这些列的惟一性。
键的可见性 代理键对用户是不可见的,但智能键是可见的,并且用户知道如何使用智能键。客户应用程序可以隐藏代理键,但数据库工具却不能隐藏它们。这就要求使用数据库工具的人员必须理解如何使用代理键。因此,智能键是这一比较回合的赢家。
键的易修改性 主键是难以进行修改的,因为如果对主键进行修改,则修改结果必然对子表造成影响。这时就应该使用代理键取代智能键。为什么呢?因为代理键并不显示给用户,所以不必修改它们;而智能键包含用户可以看到的商业数据,因此必须允许该数据能够进行修改。
int型代理键也需要进行修改,以确保惟一性(正如前文所述),但GUID型代理键从不需要进行修改。这正是我为什么喜欢使用GUID型代理键的主要原因。
联接个数 在某些情况中,可以使用智能键来减少联接的个数。例如,如果想运行一个显示每个作者所著书籍的报表,并且该报表只包含作者的SSN字段和书籍的ISBN字段,则在实现智能主键时,只需查询TblAuthorBook联接表即可。在实现代理主键时,必须联合查询TblAuthor表、TblAuthorBook表和TblBook表才能获得该信息。因此,智能键是这一比较回合的赢家,但实践中很少只查询这两列信息而不查询其他的信息,诸如作者的姓名和书名。
SQL复杂性 智能键的实现通常使用多个列来确保惟一性。SQL查询会因为使用这样的复合智能键而变得错综复杂。正如前文所述,尽管可以联合更多的代理键,但代理键更易于使用,因为它们不使用复合键(联接表除外)。对比前面两种代理键类型,Identity键在实现上比GUID键更易于编写查询,但是一旦掌握了GUID数据类型(稍后将会予以讨论)的使用特点,就会发现,GUID键相较于Identity键,并不是特别难用的。
在非连接时确保惟一性 在 非连接环境中,几乎不能保证智能键在用户输入数据时的惟一性。问题是在向数据库服务器添加新行时,有人可能输入匹配信息,从而导致冲突。有人可能会辩解 说,使用代理键就可以解决该问题,但不要忘记,大家仍可以在诸如社会保险号或车辆标识号等字段上创建惟一索引,以在添加重复信息时能抛出一个异常。
在使用int型代理键时,管理主键列编号的窍门是将DataSet非连接对象中的AutoIncrement属性设置为true,AutoIncrementStep(增量)设置为-1(负1),AutoIncrementSeed(起始值)设置为-1,这样,在添加新行时,编号将从-1开始,每新增一行,编号就减1。负值认为是非连接占位符,因此不会与服务器的Identity列设置产生冲突,因为服务器只会分配正值编号。下面的SQL命令首先插入一行数据,然后立即查询该插入行。该命令所返回的信息用于将占位符(负值键)更新为数据库所创建的值。
SQL INSERT命令
INSERT INTO [TBLAUTHOR] ([SSN], [LastName], [FirstName])
VALUES (@SSN, @LastName, @FirstName)
SELECT Id, SSN, LastName, FirstName FROM TblAuthor
WHERE (Id = SCOPE_IDENTITY())
SCOPE_IDENTITY函数返回刚才所插入的作者ID值。注意,不要使用@@IDENTITY函数,因为在激活一个插入触发器,以在包含Identity列的表中插入一行或多行数据时,该函数将返回一个错误值。
因为必须获取服务器中的 数据来更新非连接数据中的占位符,所以必须考虑更新主键值对性能的影响。如果使用服务器中创建的值更新非连接数据键,会发生什么情况呢?这时,所有的子数 据都必须进行更新,以反映键值的变化;为实现这一目的,可以根据它们之间的相互关系启用级联更新功能。这又会引出另一个性能问题,尤其对于较大的DataSet对象。
在使用GUID代理主键时,一旦设置了主键就不必再修改它。主要的问题是如何设置键值。下面的代码片段演示了如何初始化GUID。
Visual Basic
Private Sub Form1_Load(ByVal sender As System.Object, _
ByVal e As System.EventArgs) Handles MyBase.Load
For Each dt As DataTable In salesSurrogateGuidKeyDs.Tables
If (not dt.Columns("Id") Is Nothing) Then
AddHandler dt.TableNewRow, addressof InitializeGuid
End If
Next
End Sub
Private Sub InitializeGuid(ByVal sender As Object, _
ByVal e As DataTableNewRowEventArgs)
If (TypeOf e.Row("Id") Is DBNull) Then
e.Row("Id") = Guid.NewGuid()
End If
End Sub
C#
public Form1() //constructor
{
InitializeComponent();
foreach (DataTable dt in sales_SurrogateGuidKeyDs.Tables)
{
if(dt.Columns["Id"] != null)
dt.TableNewRow += new DataTableNewRowEventHandler(InitializeGuid);
}
}
private void InitializeGuid(object sender, DataTableNewRowEventArgs e)
{
if(e.Row["Id"] is DBNull)
e.Row["Id"] = Guid.NewGuid();
}
因为TblAuthor表和TblBook表具有同名的主键(“Id”),所以前面的示例代码包含一个InitializeGuid方法,用于创建新的GUID,在触发这些表的TableNewRow事件时,将调用该方法。通常,像该示例代码那样,使所有的代理键具有相同的名称是一种不错的做法。不必使用该实现创建级联关系。所以,GUID型代理键是这一比较回合的赢家。
在数据库间移动数据 在实现Identity键时,需要额外做一些工作才能在数据库之间移动数据。假设表的键值范围从1到n,这些值也可以作为数据库中所有外键的值。如何取出该数据,并将其合并到另一个使用相同数据编号的数据库中呢?要想解决这一问题,则需要对所有的Identity列进行重新编号。
如果使用GUID键实现,则移动数据只是将数据从一个数据库复制到另一个数据库,因此,GUID键是这一比较回合的赢家。
最终的赢家是… 我刚刚开发完成了一项实现GUID键的大型项目,并且还开发了多个使用智能键和Identity键实现的项目。表5.2总结了各种键类型在一些影响性能、数据大小和易用性等因素中所占的百分比。我根据自己使用这些键类型的经验,将权重值的范围设定为0%到100%,其中100%表示权重值最大。此外,键类型的系数分为以下三级:第一级系数为1,第二级系数为0.5,第三级系数为0,通过将键类型系数乘以每个因素的权重值,就可以得到每种键类型的权重值。
表5.2 基于因素及其权重的最终百分比
| 权重值 |
|||
| 因素及其权重 |
智能键 |
Identity键 |
GUID键 |
| 数据大小 = 25% |
12.5% |
25% |
0% |
| 键的可见性 = 5% |
5% |
2.5% |
0% |
| 键的易修改性 = 20% |
0% |
10% |
20% |
| 联接个数 = 5% |
5% |
2.5% |
2.5% |
| SQL复杂性 = 5% |
0% |
5% |
2.5% |
| 确保惟一性 = 25% |
0% |
12.5% |
25% |
| 数据移动 = 15% |
7.5% |
0% |
15% |
| 总计 = 100% |
30% |
57.5% |
65% |
根据表5.2中的权重值,GUID键的绝大部分因素权重值都是最大的。如果大家对某些因素的权重存有异议,可以尝试着修改权重以验证是否能得到不同的结果。注意,这些主键的实现都不能面分之百地满足所有因素。一般认为,GUID键实现是最适合非连接数据应用程序的。智能键实现是否有属于自己的用武之地呢?有的,它最适合用于数据仓库应用程序,因为数据仓库应用程序在设计上一般都会提供高性能只读访问,并且包含最少的联接数。因为数据是只读的,所以“修改键”因素所占的权重较小。表5.3通过对表5.2中的权重进行局部调整,提供了各种键类型基于另一种权重的百分比。
表5.3 基于因素及其权重的数据仓库百分比
| 权重值 |
|||
| 因素及其权重 |
智能键 |
Identity键 |
GUID键 |
| 数据大小=25% |
12.5% |
25% |
0% |
| 键的可见性=10% |
10% |
0% |
0% |
| 键的易修改性=5% |
0% |
2.5% |
5% |
| 联接个数=25% |
25% |
0% |
0% |
| SQL复杂性=10% |
10% |
5% |
5% |
| 确保惟一性=5% |
0% |
0% |
5% |
| 数据移动=20% |
10% |
0% |
20% |
| 总计=100% |
67.5% |
32.5% |
35% |
前面的表只是作为一种参考,大家在做项目的时候,一定要考虑到其他可能影响项目的任何因素。
5.3 GUID的用法
许多开发人员在试图使用GUID键时,对GUID感到非常恐惧。GUID可能非常大,但它们并不难以使用。下面将介绍一些使用技巧。
5.3.1 复制/粘贴GUID
在调试时,可以选中包含一个GUID键的代码,这时IntelliSense会显示该GUID键(如图5.4所示);接着,选中该GUID键的键值,并将其复制到剪贴板;然后将该值粘贴到一个查询窗口中,并将大括号替换为单引号,如下面的SQL语句所示。
图5.4 使用IntelliSense复制一个GUID键,并将其粘贴到查询工具中
使用GUID键的SQL查询命令
SELECT Id, SSN, LastName, FirstName
FROM TblAuthor
WHERE (Id = 'cbc8c64c-6ba6-4bec-baef-4c0e50e8b251')
5.3.2 在非联接表中使用同名的主键列
强烈建议大家在所有非联接表中使用同名的主键列(诸如Id)。这样做有利于编写处理GUID键的存储过程。此外,使主键成为每个表中的第一列还可以帮助用户理解该字段的目的。
5.3.3 查找数据库中的GUID
由于数据库的设计原因,大家在查找某个外键列中的一个GUID时,却不知道该GUID的数据在哪儿。例如,假设有一个如图5.5所示的独占性OR关系。这种类型的关系经常出现在面向对象的环境中——一个Book类可能包含多个子类,诸如Ebook类、PaperBack类和HardCover类。这些类的字段互不相同,因此要么创建一个包含大量列值为null的表,要么如图5.5所示,为每个子类单独创建一个表,必须在这两种方法中选择其一。
图5.5 独占性OR关系的一个示例
如果想确定某个特定的GUID包含在哪个表中,则可以使用下面的存储过程来定位将该GUID作为主键值的表。
SQL uspGetDataForId
CREATE PROCEDURE dbo.uspGetDataForId
(
@id uniqueidentifier
)
AS
SET NOCOUNT ON
--NOTE: This proc assumes that all user tables have 'Tbl' prefix
--Usage: in Query Analyser, type the following without the '--'
--exec uspGetDataForId '78257ec8-c8f9-4d35-a636-d58d8a67c3d4'
DECLARE @tbl varchar(2000)
DECLARE @sql varchar(2000)
IF OBJECT_ID('tempdb..#idTable') IS NOT NULL DROP TABLE #idTable
CREATE TABLE #idTable (
Id uniqueidentifier,
Count INT,
TableName varchar(2000)
)
DECLARE tables_cursor CURSOR
FOR SELECT TABLE_NAME FROM information_schema.Tables
WHERE substring (TABLE_NAME,1,3)='Tbl'
OPEN tables_cursor
FETCH NEXT FROM tables_cursor INTO @tbl
WHILE @@FETCH_STATUS = 0
BEGIN
IF EXISTS (SELECT * FROM information_schema.columns
WHERE table_name=@tbl AND Column_Name='Id')
BEGIN
SET @sql = 'INSERT INTO #idTable SELECT id as ''Id'', '
+ 'count(*) as ''Count'',''' + @tbl +''' as ''TableName'' FROM '
+ @tbl + ' WHERE ID=''' + CONVERT(varchar(2000),@id)
+ ''' group by Id'
EXEC(@sql)
END
FETCH NEXT FROM tables_cursor INTO @tbl
END
CLOSE tables_cursor
DEALLOCATE tables_cursor
SELECT Id, TableName FROM #idTable WHERE Count > 0
注意,该存储过程要求所有主键列的名称都为Id,用户表的前缀都为Tbl。该存储过程没有尝试在其他任何列中查找一个GUID,但如果需要查找所有使用某个GUID的位置,则要读取所有的列。