Flink CDC
一、 CDC 简介
1.1 什么是 CDC
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1.2 CDC 的种类
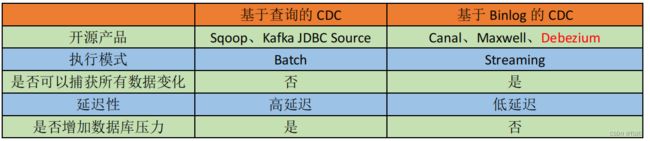
CDC 主要分为基于查询和基于 Binlog 两种方式,我们主要了解一下这两种之间的区别:
1.3 Flink-CDC
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectors
二、 Flink CDC 案例实操
2.1 导入依赖
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
2.2 DataStream 方式
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("cdc_test") // 监控的mysql 库名
// .tableList("cdc_test.user_info") // 监控的mysql 当前库下的具体表
.deserializer(new StringDebeziumDeserializationSchema()) // 自带的序列化器
.startupOptions(StartupOptions.initial()) //可选择监控binlog方式: initial,earliest,latest,specificOffset,timestamp
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3.数据打印
dataStreamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
2.3 FlinkSQL 方式
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQLCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.使用FLINKSQL DDL模式构建CDC 表
tableEnv.executeSql("CREATE TABLE user_info ( " +
" id STRING primary key, " +
" name STRING, " +
" sex STRING " +
") WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'scan.startup.mode' = 'latest-offset', " +
" 'hostname' = 'hadoop102', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = '000000', " +
" 'database-name' = 'cdc_test', " +
" 'table-name' = 'user_info' " +
")");
//3.查询数据并转换为流输出
Table table = tableEnv.sqlQuery("select * from user_info");
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
//4.启动
env.execute("FlinkSQLCDC");
}
}
2.4自定义序列化器
import com.atguigu.func.CustomerDeserializationSchema;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC2 {
public static void main(String[] args) throws Exception {
//1.获取Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("cdc_test")
// .tableList("cdc_test.user_info")
.deserializer(new CustomerDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3.数据打印
dataStreamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserializationSchema implements DebeziumDeserializationSchema<String> {
/**
* {
* "db":"",
* "tableName":"",
* "before":{"id":"1001","name":""...},
* "after":{"id":"1001","name":""...},
* "op":""
* }
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//创建JSON对象用于封装结果数据
JSONObject result = new JSONObject();
//获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
result.put("db", fields[1]);
result.put("tableName", fields[2]);
//获取before数据
Struct value = (Struct) sourceRecord.value();
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
//获取列信息
Schema schema = before.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
beforeJson.put(field.name(), before.get(field));
}
}
result.put("before", beforeJson);
//获取after数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
//获取列信息
Schema schema = after.schema();
List<Field> fieldList = schema.fields();
for (Field field : fieldList) {
afterJson.put(field.name(), after.get(field));
}
}
result.put("after", afterJson);
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
result.put("op", operation);
//输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
三、Mysql的binlog开启
MySQL Server 的四种类型的日志:Error Log、General Query Log、Slow Query Log 和Binary Log
- Error Log 即 错误日志,记录 mysqld 发生的一些错误。
- General Query Log 即 一般查询日志,记录 mysqld 正在做的事情,如客户端的连接和断开、来自客户端每条 Sql Statement 记录信息;如果你想准确知道客户端究竟传了什么内容给服务端,这个日志就非常管用了,当然了这货非常影响性能。
- Slow Query Log 即 慢查询日志,记录一些查询执行较慢的 SQL 语句,这个日志非常常用,主要是给开发者调优用的。
Binary Log 简称 Binlog 即 二进制日志文件,这个文件记录了mysql所有的 DML 操作。通过 Binlog 日志我们可以做数据恢复,做主主复制和主从复制等等。对于开发者可能对 Binlog 并不怎么关注,但是对于运维或者架构人员来讲是非常重要的。
简而言之,Binlog 两个重要的用途——复制和恢复,很多十分好用的 MySQL 体验比如说增量备份,回滚至指定时间以及上面提到的主主和主从等等都依赖于 Binlog。
Binlog 有三种模式:
-
STATEMENT:顾名思义,STATEMENT 格式的 Binlog 记录的是数据库上执行的原生SQL语句
-
ROW:这种格式的 Binlog 记录的是数据表的行是怎样被修改的。
-
MIXED:混合模式,如果设置了这种格式,MariaDB / MySQL 会在一些特定的情况下自动从STATEMENT 格式切换到 ROW 格式。例如,包含 UUID 等不确定性函数的语句,引用了系统变量的语句等等
3.1 检查是否开启
show global variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | OFF |
+---------------+-------+
1 row in set (0.001 sec)
如果返回的是 log_bin | OFF 那么就是没有开启,ON 则是已经开启;
3.2 设置开启
修改 my.cnf 文件,一般来说都位于 /etc/my.cnf 这边,部分像 MariaDB 可能是修改/etc/my.cnf.d/server.cnf 文件。
下写入如下内容:
# 指定一个集群内的 MySQL 服务器 ID,如果做数据库集群那么必须全局唯一,一般来说不推荐 指定 server_id 等于 1。
server_id = 1
# 设置方面提到过的三种 Binlog 的日志模式
binlog_format = ROW
#控制对哪些数据库进行收集
binlog_do_db=xxxDbName
# 其他:
# 开启 Binlog 并写明存放日志的位置
#log_bin = /usr/local/mysql/log/bin-log
# 指定索引文件的位置
#log_bin_index = /usr/local/mysql/log/mysql-bin.index
#删除超出这个变量保留期之前的全部日志被删除
#expire_logs_days = 7
- max_binlog_size ,binary log 最大的大小
- binlog_cache_size ,当前的多少事务cache在内存中
- binlog_cache_disk_use ,当前有多少事务暂存在磁盘上的,如果这个值有数值的话,就应该要注意调优了。
- max_binlog_cache_size ,最大能有多少事务cache在内存中
- binlog_do_db和binlog_ingore_db ,是一对控制对哪些数据库进行收集的选项。
- sync_binlog ,这个值控制cache的数据commit多少次才刷到磁盘上。默认是0,也就是让数据库自己决定同步的频率。如设置成1的话,则每commit一次就会将cache的数据同步到磁盘上,这样做最安全,但是性能最差。
3.3 重启数据库
service mysql restart
或者 service mysqld restart
检查一下是否开启
show global variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)
show master status;
+----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------+----------+--------------+------------------+-------------------+
| bin-log.000002 | 498 | xxxDbName | | |
+----------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
或者到文件夹中查看: