FlinkCDC
第 1 章 CDC 简介
1.1 什么是 CDC
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1.2 CDC 的种类

基于查询的CDC只关心数据的结果,中间过程无所谓,所以会丢失一部分数据
基于Binlog的CDC执行模式是流,数据不会丢失,关注数据过程
基于Binlog的CDC不会增加数据库压力:Binlog通过有权限验证,读取的是磁盘文件,不直接与mysql文件联系,相当于实时架构和离线架构的区别,进行了解耦不直接访问,减少数据库的压力
基于Binlog的CDC不好处理每日全量问题(where 1=1):因为底层是流,如果是用于每日增量、新增及变化和特殊场景,完全可以由基于Binlog的CDC来代替基于查询的CDC
1.3 Flink-CDC
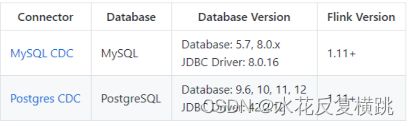
Flink 社区(阿里的云邪个人兴趣爱好)开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:
https://github.com/ververica/flink-cdc-connectors
第 2 章 FlinkCDC 案例实操
2.1 DataStream 方式的应用
2.1.1 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.1.2 编写代码
package online.shuihua;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.executiongraph.restart.RestartStrategy;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1.1 开启CK并指定状态后端为FS memory fs rocksdb
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-2022-flink/ck"));
//2.Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点续传,需要从 Checkpoint 或者 Savepoint 启动程序
//2.1 开启 Checkpoint,每隔 5 秒钟做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK 的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setCheckpointTimeout(3000);
// env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
// 2.通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall-2022-flink")
// 如果不添加该参数,则消费指定数据库中所有表的数据.如果指定指定方式为db.table
.tableList("gmall-2022-flink.base_trademark")
.deserializer(new StringDebeziumDeserializationSchema())
// 初始化分开-- 全量阶段和增量阶段 -- 加锁表
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
// 3.打印数据
streamSource.print();
// 4.启动任务
env.execute();
}
}
2.1.3 案例测试
1)打包并上传至 Linux

2)开启 MySQL Binlog 并重启 MySQL
3)启动 Flink 集群
[chenyunde@hadoop102 flink-standalone]$ bin/start-cluster.sh
4)启动 HDFS 集群
[chenyunde@hadoop102 flink-standalone]$ start-dfs.sh
5)启动程序
[chenyunde@hadoop102 flink-standalone]$ bin/flink run -c online.shuihua.FlinkCDC flink-1.0-SNAPSHOT-jar-with-dependencies.jar
6)在 MySQL 的 gmall-flink.z_user_info 表中添加、修改或者删除数据
7)给当前的 Flink 程序创建 Savepoint
[chenyunde@hadoop102 flink-standalone]$ bin/flink savepoint JobId
hdfs://hadoop102:8020/flink/save
8)关闭程序以后从 Savepoint 重启程序
[chenyunde@hadoop102 flink-standalone]$ bin/flink run -s hdfs://hadoop102:8020/flink/save/… -c online.shuihua.FlinkCDC
flink-1.0-SNAPSHOT-jar-with-dependencies.jar
2.2 FlinkSQL 方式的应用
2.2.1 添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
2.2.2 代码实现
package online.shuihua;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkCDCWithSQL {
public static void main(String[] args) throws Exception{
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2.DDL方式建表
tableEnv.executeSql("CREATE TABLE mysql_binlog (" +
" id STRING NOT NULL," +
" tm_name STRING," +
" logo_url STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'hadoop102'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'gmall-2022-flink'," +
" 'table-name' = 'base_trademark'" +
")");
// 3.查询数据
Table table = tableEnv.sqlQuery("select * from mysql_binlog");
// 4.将动态表转换为流
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
// 5.启动任务
env.execute("FlinkCDCWithSQL");
}
}
2.3 自定义反序列化器
2.3.1 代码实现
package online.shuihua;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.Properties;
public class Flink_CDCWithCustomerSchema {
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.创建 Flink-MySQL-CDC 的 Source
Properties properties = new Properties();
//initial (default): Performs an initial snapshot on the monitored database tables upon first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first startup, just read from the end of the binlog which means only have the changes since the connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified timestamp. The consumer will traverse the binlog from the beginning and ignore change events whose timestamp is smaller than the specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon
//first startup, and directly read binlog from the specified offset.
DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-flink")
.tableList("gmall-flink.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.startupOptions(StartupOptions.initial())
.deserializer(new DebeziumDeserializationSchema<String>() { //自定义数据解析器
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//获取主题信息,包含着数据库和表名mysql_binlog_source.gmall-flink.z_user_info
String topic = sourceRecord.topic();
String[] arr = topic.split("\\.");
String db = arr[1];
String tableName = arr[2];
//获取操作类型 READ DELETE UPDATE CREATE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//获取值信息并转换为 Struct 类型
Struct value = (Struct) sourceRecord.value();
//获取变化后的数据
Struct after = value.getStruct("after");
//创建 JSON 对象用于存储数据信息
JSONObject data = new JSONObject();
for (Field field : after.schema().fields()) {
Object o = after.get(field);
data.put(field.name(), o);
}
//创建 JSON 对象用于封装最终返回值数据信息
JSONObject result = new JSONObject();
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
//发送数据至下游
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
})
.build();
//3.使用 CDC Source 从 MySQL 读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
//4.打印数据
mysqlDS.print();
//5.执行任务
env.execute();
}
}