AQS源码解读
文章目录
- 前言
- 一、AQS是什么?
- 二、解读
-
- 重点属性
-
- state
- head、tail
- 同步变量竞争
-
- acquire
- 同步变量释放
- 总结
前言
AQS是AbstractQueuedSynchronizer的缩写,也是大神Doug Lea的得意之作。今天我们来进行尽量简化的分析和理解性的代码阅读。

一、AQS是什么?
其实从全称翻译来看,我们其实可以判断出AQS的作用,排队的同步器,或者翻译为“使同步器排队”。所以它的主要作用就是使得线程通过排队的方式进行同步。
二、解读
重点属性
state
state变量是一个volatile的变量,同时内部提供了普通的读写操作,加一个通过Unsafe实现的CAS更写state的方法。CAS更新变量的方法其实就是为了保证对于state变量的更新是线程安全的。
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
head、tail
既然是队列,那必然要有头尾节点,我们的头尾节点的类型是一个内部类-Node
static final class Node {
/** Marker to indicate a node is waiting in shared mode */
static final Node SHARED = new Node();
/** Marker to indicate a node is waiting in exclusive mode */
static final Node EXCLUSIVE = null;
/** waitStatus value to indicate thread has cancelled */
static final int CANCELLED = 1;
/** waitStatus value to indicate successor's thread needs unparking */
static final int SIGNAL = -1;
/** waitStatus value to indicate thread is waiting on condition */
static final int CONDITION = -2;
/**
* waitStatus value to indicate the next acquireShared should
* unconditionally propagate
*/
static final int PROPAGATE = -3;
/**
* Status field, taking on only the values:
* SIGNAL: The successor of this node is (or will soon be)
* blocked (via park), so the current node must
* unpark its successor when it releases or
* cancels. To avoid races, acquire methods must
* first indicate they need a signal,
* then retry the atomic acquire, and then,
* on failure, block.
* CANCELLED: This node is cancelled due to timeout or interrupt.
* Nodes never leave this state. In particular,
* a thread with cancelled node never again blocks.
* CONDITION: This node is currently on a condition queue.
* It will not be used as a sync queue node
* until transferred, at which time the status
* will be set to 0. (Use of this value here has
* nothing to do with the other uses of the
* field, but simplifies mechanics.)
* PROPAGATE: A releaseShared should be propagated to other
* nodes. This is set (for head node only) in
* doReleaseShared to ensure propagation
* continues, even if other operations have
* since intervened.
* 0: None of the above
*
* The values are arranged numerically to simplify use.
* Non-negative values mean that a node doesn't need to
* signal. So, most code doesn't need to check for particular
* values, just for sign.
*
* The field is initialized to 0 for normal sync nodes, and
* CONDITION for condition nodes. It is modified using CAS
* (or when possible, unconditional volatile writes).
*/
volatile int waitStatus;
volatile Node prev;
volatile Node next;
/**
* The thread that enqueued this node. Initialized on
* construction and nulled out after use.
*/
volatile Thread thread;
/**
* Link to next node waiting on condition, or the special
* value SHARED. Because condition queues are accessed only
* when holding in exclusive mode, we just need a simple
* linked queue to hold nodes while they are waiting on
* conditions. They are then transferred to the queue to
* re-acquire. And because conditions can only be exclusive,
* we save a field by using special value to indicate shared
* mode.
*/
Node nextWaiter;
}
Node类呢,几个常量属性还是挺好理解的,最难理解的莫过于waitStatus了。理解了这个,对于如何排队,以及排队的时候需要进行哪些操作也就清楚了。
CANCELED:被取消,一般情况是由于同步变量竞争超时或者线程被中断导致的
SIGNAL:说明这个Node的后继节点(继承节点)的thread需要被unpark,也就是唤醒;也就是他的后继节点当前正被阻塞或者待阻塞状态中。
0:初始状态
CONDITION和PROPAGATE先不管了:这俩用在读写锁上的,以后再看看填不填坑
同步变量竞争
acquire
这个方法就是同步变量竞争的最主要方法了。
如果我们自己如果实现排队获取某个属性,最朴素的一般都是直接往队列里添加排队,然后按序处理队列进行同步。但是Doug大神的想法比较全面,而且open。当然也有可能是参考了操作系统里面获取锁的逻辑(我猜的,如果有人知道操作系统层面的做法,可以留言讨论)。Doug大神加了一步tryAcquire。也就是说如果尝试获取失败,再进行排队处理。至于尝试获取是怎么尝试的,需要根据自己的需要进行重写(ReentrantLock、ThreadPoolExecutor等),当然ReentrantLock、ThreadPoolExecutor等类也都是大神自己写的。
而且大神代码精简,如下:
/**
* Acquires in exclusive mode, ignoring interrupts. Implemented
* by invoking at least once {@link #tryAcquire},
* returning on success. Otherwise the thread is queued, possibly
* repeatedly blocking and unblocking, invoking {@link
* #tryAcquire} until success. This method can be used
* to implement method {@link Lock#lock}.
* 独占模式下进行获取,至少会执行一次tryAcquire,如果成功了,就返回,否则就把线程排队
* 可能会重复不停的阻塞和解阻塞,执行tryAcquire,直到成功。
*
* @param arg the acquire argument. This value is conveyed to
* {@link #tryAcquire} but is otherwise uninterpreted and
* can represent anything you like.
*/
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
不得不说,注释写得很明白,不过可能很多同学不明白,为什么可能线程会重复阻塞和解阻塞,然后执行tryAcquire呢?
其实是因为即使一个thread被解阻塞(unpark)了,他还是要进行tryAcquire的,但是同时可能正在有新的thread不停加入acquire,然后也在执行tryAcquire,所以unpark了的线程不一定能获取成功,所以如果获取失败,还需要继续park的。
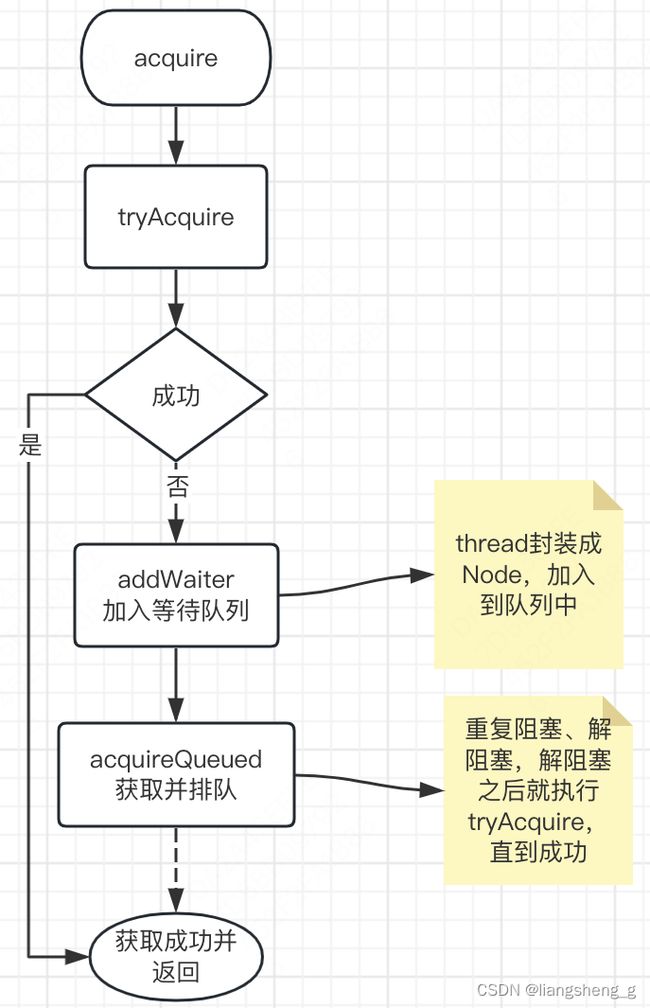
addWaiter
这个方法没什么复杂的,唯一需要注意的是如果没有头结点,是新建了一个空的Node对象作为head和tail,而不是把当前node设置为head,当前node只会设置为tail。所有设置防止并发,都是通过CAS实现
1. 如果tail不为null,就通过CAS的方法设置当前node设置为新的tail,然后返回
2. 如果设置尾结点失败,判断下有没有头结点,如果没有,设置一个空的Node为head和tail,并把当前node设置为新的tail,否则直接把当前node设置为尾结点
acquireQueued
此处也就引入了重复、自旋的概念。
由于所有的Node都排队了,且head并没有关联thread,所以从队头往队尾找thread。
下面这段逻辑是在死循环里的,所以会重复执行,直到获取成功或者由于某些意外情况退出死循环。
3. 如果是head的后继node,且执行tryAcquire成功,就把自己设置为head,然后把关联的线程置为null,把原来的head设置为孤儿node
4. 否则,就需要把前置node的waitStatus设置为SIGNAL,然后阻塞自身,暂停执行死循环
大家可能会对shouldParkAfterFailedAcquire方法逻辑感觉奇怪,为啥非要把前置的且非CANCELED的node的waitStatus设置为SIGNAL?最终达到的效果就是只有当前阻塞的node的waitStatus是0(默认值),其他前置node的waitStatus都是SIGNAL
其实waitStatus就是为了进行node状态用的,而SIGNAL状态的含义就是【后继node是阻塞的或者即将阻塞的】,也就是说此时是为了进行打标,避免唤醒的时候“惊群”。
!注:哪怕前置node是head,也要把其waitStatus设置为SIGNAL(毕竟默认的是0)
可以发现Doug大神为了防止滥用CPU,消耗性能,如果获取资源失败,并不会立马重试,而是通过LockSupport.park将当前线程进行阻塞,通过waitStatus来标志这个状态。(不像我们写业务代码,可能就让线程进行不停死循环,直到成功了)
而且Doug大神使用waitStatus这种写法还避免了类似“惊群”的现象,不浪费CPU性能做到了极致
同步变量释放
接下来看release,不过细心的同学一定知道了,release有个最重要的功能就是对一些被阻塞的node进行唤醒,当然就是唤醒SIGNAL的node的下一个非CANCELED的node,而不是所有node,避免“惊群”。
/**
* Releases in exclusive mode. Implemented by unblocking one or
* more threads if {@link #tryRelease} returns true.
* This method can be used to implement method {@link Lock#unlock}.
*
* @param arg the release argument. This value is conveyed to
* {@link #tryRelease} but is otherwise uninterpreted and
* can represent anything you like.
* @return the value returned from {@link #tryRelease}
*/
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
和tryAcquire一样,tryRelease是真正执行释放资源的操作,需要实现。
主逻辑就是如果释放成功了,需要唤醒后继第一个非CANCELED的node。
unparkSuccessor
1. 将node(此时的node可能是head也可能是被cancel的node)的waitStatus设置为0,因为需要唤醒下一个node进行资源竞争
2. 找到后继第一个非CANCELED的node,进行unpark,使得其继续执行acquireQueued,来竞争获取资源
这个方法里最有意思的一个逻辑是如果后继node是一个CANCELED了的node,那么没有继续这个CANCELED的node的next,而是基于tail从后往前找,找到离head最近的SIGNAL状态的node。
原因是因为当某个node被cancelAcquire的时候,会把该节点从队列里移除,但是因为方法逻辑是先设置状态,后移除,移除之后,node的next就会被设置为null。
所以此处基于tail从后往前找的原因就是防止并发导致读取到node的状态是CANCELED,然后后面基于next往后遍历读取到null,而反过来则不会出问题,因为没有把后继节点的pre设置为null。
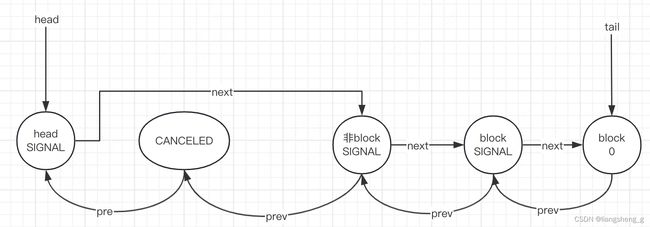
可以发现,节点被cancelAcquire的时候,只会把prev和当前node的next设置为null,而所有节点的prev指向都没变。所以从后往前找非CANCELED的node一定没问题。只有当某个node变为head时,才会把自身的prev设置为null
如果某个node被执行了cancelAcquire,也会unpark后继节点。
所以release和cancelAcquire都会unpark后继节点。
总结
竞争资源总体分三步
1. 尝试获取资源,成功就返回
2. 失败了的线程封装成Node,加入到队列
3. 加入到队列的Node,不停经历(阻塞-非阻塞-tryAcquire),直到获取资源成功
释放资源分两步
4. 尝试释放资源,失败了就返回
5. 释放成功了,需要把头结点的waitStatus置空,唤醒下一个非CANCELED的Node进行资源获取操作