如何使用poi解析word生成html目录结构
POI解析word目录结构
- 简介说明
- 认识下Word
-
- 我们先看下doc版本的word
- 我们再看下docx版本的word(今天的主角)
- 目录解析的原理介绍
-
- 写word文档时,我们是怎么设置目录?
- 我们看下样式
-
- 准备点目录的css样式
- 定义一个层级的目录结构对象
- 整个目录结构的封装对象
- 转换逻辑
- 测试demo
- 结语
- 项目代码
简介说明
java使用POI转换word为Html的文章有很多,但是很少有涉及到目录解析的,包括一些付费的,开源的,甚至是office自带的另存为…功能都没有涉及到生成目录的。
本篇将介绍目录生成的基本原理和代码实现,windows,linux都可以使用。
https://zhangshaoju.me
认识下Word
我想大家都知道word有两个大的版本,一个是office97~2003,一个是office2007。最直观的区别就是一个是doc结尾的一个docx结尾的。
我们先看下doc版本的word
新建一个doc,如下图:
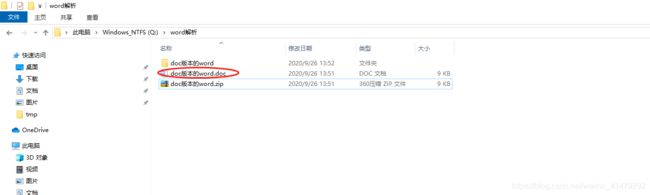
可以注意到,doc文件的下面有一个zip文件,这是我将上面的doc后缀,直接改成了zip。你可能会有疑问,不过没错,就是你想的那样,我们经常使用的word文档本质就是一个zip压缩包,在这里存储了word相关的一些文件,这些文件里存放的就是word里你写入的文件,进行的排版,粘贴的图片,插入的表格附件,超链接等等。我们解压这个文件,看到如下的结构:

所以到这里,我们对word文档是不是开始有了揭开面纱的认识。
当然,不好意思,doc版本的word不是我们这次解析的对象,我们解析的对象是docx版本的word。这里我只是带你看看而已,doc这里的文件都是二进制的格式,当然poi也可以读取解析,但是API完全不一样,而且这种格式已经逐渐淘汰了,另外有很多开源工具都可以将doc转换成docx,转换效果很不错。
PS:本人提供完整的docx转换html,解析范围:包括表格(合并行,列),包括超链接,包括目录结构,包括正文(粗体,字号,背景颜色,字体颜色,下滑写,删除线),包括图片,包括附件,包括矢量图,包括公式等等。可以说基本上word里你见过的都可以转换。可以联系我微信hoodlake。
我们再看下docx版本的word(今天的主角)
同样,我们新建一个docx文件,将文件后缀docx手动改成zip,解压后,如下图:

这个时候我们可以看到
- docx的word的解压内容更加丰富。
- docx的内部结构都是以xml的形式存放的。对,你想的没错,如果doc的二进制格式你还有所忌讳的话,docx的xml存储结构,自己是不是可以跃跃欲试了。说句大言不惭的话:会解析xml就能全方位掌握word了,甚至可以不用poi,任何能解析xml的语言都可以解析word。不用不好意思,相信自己,真的就是这个样子的,只是你还需要花费很多经历去分析他的xml文档结构。你将会发现使用POI的ooxml,xmlbeans对于解析word简直有如神助。
- 本人比较习惯使用eclipse,你也可以导入到你习惯的ide里,把所有的xml文件格式化一下(Word本身是压缩存储的),你将会更加清晰的看到word的内部结构,下图是格式化后的document.xml:

接下来将会讲述原理,以上的介绍,希望大家务必手动操作一下,这样对word有个属于自己的总结性的认识。对接下来的原理理解也会容易一点。
本篇文档内容只设计部分代码的展示,完整的目录解析代码,会以附件的形式,放在文章末尾。
目录解析的原理介绍
写word文档时,我们是怎么设置目录?
我们先回顾下这个画面,您是否自己认真写过一篇word文章,一篇满足规范的文章。如果没有的话,在这里你可以从认识段落开始,重新了解下word编辑正确的使用方式。

从上图可以看出几点:
- 段落的样式是特定的;当你选定了一种段落样式之后,那它就是这一套样式,在这一套样式里选择一级标题,二级标题,三级标题。这是一种规范,是一种大家约定熟成的约束。这里是word默认的段落样式,在我的认知的领域里,我还见过其他的段落格式,我们这里只是介绍原理,其他的多写点点适配代码就好了
- 右边通过章节菜单,展示出来了,这篇文档的目录结构,我们的目的也就是把这个目录结构在html里展示出来。
- 我们要有意识,目录一种层级结构,是一种树状结构,所以接下来我们会用到递归的算法。
- 在第1点中提到的样式的概念,希望你格外留意,这是你打开编码转换思路的一把钥匙。
我们看下样式
上面的截图,我们看到了格式化后的word文档结构:document.xml,word的所有编辑内容都是存放在这里的,word的整个结构关系,内容都是在这里的。但是这只是一个文本文档,是不能存储附件,图片,公式等二进制资源的,他是采用的引用的策略,通过r:id属性来引用对应的资源。对于特定格式的使用也是通过引用的方式的。
我们可以看到,除了document.xml,还有很多其他的xml文件,比如这里我们比较关注,style.xml,格式化后截图如下:

所以可以看出来,通过style,我们就可以看到文章有目录结构是怎么样的,但这里仅仅只能看出目录结构,有多少级目录而已。一切和段落撇开的目录都是耍流氓,对吧。至少我们得指定这个目录叫啥吧,这时候就需要结合document.xml了

如上图所示,所有的目录段落上面都有w:pStyle标签,记录了引用的样式,通过引用的样式就可以知道层级关系,通过层级关系和段落内容,就可以构建一个目录了,说到这里,no bb ,show me the code。
准备点目录的css样式
显而易见,既然要转换成html,一个像样的html页面,css怎么能少得了呢,上css代码,项目里就放在类路径下的word.css文件中,程序运行时,加载加入到html页面中,也可以通过link的方式引用,看具体场景。
*{
font-family: "Microsoft Yahei" , "Arial Narrow" ,Verdana, Geneva, sans-serif;
-webkit-overflow-scrolling: touch;
box-sizing: border-box;
-moz-box-sizing: border-box; /* Firefox */
-webkit-box-sizing: border-box;
}
blockquote,
body,
dd,
div,
dl,
dt,
fieldset,
form,
h1,
h2,
h3,
h4,
h5,
h6,
li,a
ol,
p,
pre,
svg,
td,
textarea,
th,
ul {
margin: 0;
padding: 0;
font-family: "Microsoft Yahei" , "Arial Narrow" ,Verdana, Geneva, sans-serif;
font-size: 12px;
box-sizing: border-box;
-moz-box-sizing: border-box; /* Firefox */
-webkit-box-sizing: border-box;
}
#catalog{
width: 300px;
height: 100%;
position: fixed;
left: 0px;
bottom: 0px;
display: none;
overflow-y:auto;
background: #F6F6F6;
}
#catalog a{
display: block;
height: 25px;
line-height: 25px;
cursor: pointer;
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
color: #333;
}
#catalog h1 a{
border-left:2px solid #dedede;
font-size: 12px;
padding-left: 10px;
}
#catalog h1 a:hover{
border-left:2px solid #1DC2DE;
color: #1DC2DE
}
#catalog h2 a{
padding-left: 20px;
font-size: 12px;
}
#catalog h3 a{
padding-left: 30px;
font-size: 12px;
}
#catalog h4 a{
padding-left: 40px;
font-size: 12px;
}
#catalog h5 a{
padding-left: 50px;
font-size: 12px;
}
#catalog h6 a{
padding-left: 60px;
font-size: 12px;
}
#catalog a:hover{
color: #1DC2DE
}
#catalog .act a{
color: #1DC2DE;
}
#catalog p{
font-size: 18px;
font-weight: bold;
padding: 10px;
}
定义一个层级的目录结构对象
package com.bigbrain.converter.docx2html;
import java.util.ArrayList;
import java.util.List;
/**
* @author big brain
* 目录条目封装类
*/
public class DocCatalog {
/**
* 上级目录
*/
private DocCatalog upperCatalog = null;
/**
* 子目录
*/
private List<DocCatalog> subCatalogs = new ArrayList<DocCatalog>();
/**
* 节点排序,从1开始,第几个目录条目
*/
private int sort;
/**
* 节点唯一编码:由上级节点编码和当前节点编码构成
*/
private String code;
/**
* 节点名称
*/
private String text;
/**
* 节点层级,根节点为1,依次累加
*/
private int level;
public int getSort() {
return sort;
}
public void setSort(int sort) {
this.sort = sort;
}
public DocCatalog getUpperCatalog() {
return upperCatalog;
}
public void setUpperCatalog(DocCatalog upperCatalog) {
this.upperCatalog = upperCatalog;
}
public List<DocCatalog> getSubCatalogs() {
return subCatalogs;
}
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
/**
* 获取全标题(输出当前目录节点的html代码)
* @return
*/
public String getFullTitle() {
return ""+this.code+""+this.text+"";
}
/**
* 是否拥有子目录
* @return
*/
public boolean hasSub() {
return subCatalogs.size()>0;
}
public int getLevel() {
return level;
}
public void setLevel(int level) {
this.level = level;
}
/**
* 添加子目录
* @param item
*/
public void addSubCatalog(DocCatalog item) {
this.subCatalogs.add(item);
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
整个目录结构的封装对象
package com.bigbrain.docx2html;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author zhangshaoju
* 文档目录结构
*/
public class DocCatalogList {
/**
* 所有根节点
*/
private List<DocCatalog> rootList = new ArrayList<>();
/**
* 树节点个数,总的目录条目数,初始为0
*/
private int count = 0;
/**
* 存储某个层级的最后一个节点
*/
private Map<Integer,DocCatalog> lastCatalogInLevel = new HashMap<>();
/**
* 销毁对象
*/
public void clear() {
this.rootList.clear();
this.lastCatalogInLevel.clear();
}
/**
* 添加一个新的目录节点
* @param text
* @param level
*/
public void addCatalog(String text,int level){
count++;
DocCatalog item = new DocCatalog();
item.setLevel(level);
item.setText(text);
item.setSort(count);
if(level == 1) {//根目录
item.setUpperCatalog(null);
item.setCode((rootList.size()+1)+".");
rootList.add(item);
}
if(level > 1) {//非根目录
DocCatalog upper = lastCatalogInLevel.get(level-1);
if(upper != null) {//可能会解析到不规范的文档,比如一级标题在二级标内部
item.setUpperCatalog(upper);
item.setCode(upper.getCode()+(upper.getSubCatalogs().size()+1)+".");
upper.addSubCatalog(item);
}
}
lastCatalogInLevel.put(level, item);//设置该节点为当前层级的最后一个节点
}
/**
* 遍历整个目录
* @param processor
*/
public void walk(DocCatalogNodeProcessor processor) {
for(DocCatalog catalog:rootList) {
walk(catalog,processor);
}
}
/**
* 遍历所有目录节点
* @param catalog
* @param processor
*/
private void walk(DocCatalog catalog,DocCatalogNodeProcessor processor) {
if(processor==null) {
processor= new DocCatalogNodeProcessor00();
__123Util.record("WARN:处理程序为空,使用默认处理程序");
}
processor.process(catalog);
List<DocCatalog> subList = catalog.getSubCatalogs();
for(DocCatalog one : subList) {
if(one.hasSub()) {
walk(one,processor);
}else {
processor.process(one);
}
}
}
}
转换逻辑
package com.bigbrain.docx2html;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.math.BigInteger;
import java.util.List;
import org.apache.poi.xwpf.usermodel.BodyElementType;
import org.apache.poi.xwpf.usermodel.IBodyElement;
import org.apache.poi.xwpf.usermodel.XWPFAbstractNum;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFNum;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFStyle;
/**
* @author big brain
* docx转换html之大纲目录解析
*/
public class Docx2Html_Catalog {
private DocCatalogList docCatalogList = new DocCatalogList();
/**
* 输出转换后的HTML
*/
private StringBuffer asHtml = new StringBuffer();
/**
* docx的poi文档对象
*/
private XWPFDocument document;
/**
* @param document 需要手动关闭,本转换程序不会关闭document对象
*/
public Docx2Html_Catalog(File docxFile) {
try {
this.document = new XWPFDocument(new FileInputStream(docxFile));
} catch (Exception e) {
//继承了RuntimeException的一个自定义异常类
throw new Word2HtmlParseException(e);
}
convert();
}
public String asHtml() {
return asHtml.toString();
}
/**
* 从类路径加载css文件
*
* @return
* @throws Exception
*/
private static String loadCss() {
BufferedReader br = new BufferedReader(new InputStreamReader(Docx2Html_Catalog.class.getResourceAsStream("/word.css")));
StringBuffer sb = new StringBuffer();
String line = null;
try {
while ((line = br.readLine()) != null) {
sb.append(line).append("\n");
}
br.close();
} catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* 返回段落样式名称
*
* @param document
* @param p
* @return
*/
private String getStyle(XWPFDocument document, XWPFParagraph p) {
XWPFStyle style = document.getStyles().getStyle(p.getStyleID());
if (style == null)
return "_default";
return style.getName().toLowerCase();
}
/**
* 开始构建目录
*
* @param elems
*/
private void buildCatalog() {
List<IBodyElement> elems = document.getBodyElements();
for (int i = 0; i < elems.size(); i++) {
IBodyElement be = elems.get(i);
if (be instanceof XWPFParagraph == false) {
continue;
}
XWPFParagraph p = (XWPFParagraph) be;
String style = getStyle(document, p);
if (!style.contains("heading") && !style.contains("标题")) {//两种标题模式
continue;
}
int level = 1;
try {
if(style.contains("heading")) {
level = Integer.parseInt(style.replace("heading", "").trim());
}
} catch (Exception e) {
System.err.println("忽略无法解析的样式:" + style + ",所在段落:" + p.getText());
continue;
}
String text = p.getText();
docCatalogList.addCatalog(text, level);
}
DocCatalogNodeProcessor01 process = new DocCatalogNodeProcessor01();
docCatalogList.walk(process);
asHtml.append("\t\t").append("\n");
asHtml.append("\t\t\t目录
");
asHtml.append(process.getContent()).append("\n");
asHtml.append("\t\t").append("\n");
}
/**
* 获取段落类型,这个段落类型是根据技术文档书写规范自定义的一个类型,(注意)和word本身的段落类型概念不一样,目前分为以下三种:
* 1.head 标题段落
* 2.list 列表段落
* 3.text 普通文本段落
*
* @param p
* @return
*/
private String getParagraphType(XWPFParagraph p) {
// 优先匹配层级段落
XWPFStyle style = document.getStyles().getStyle(p.getStyleID());
if (style != null) {// 检查是否是标题段落
for (int i = 1; i <= 9; i++) {// word最高支持9级标题,html最高支持6级标题
String styleName = "heading " + i;
if (styleName.equalsIgnoreCase(style.getName())) {
return styleName;
}
}
}
// 再匹配列表段落
BigInteger numId = p.getNumID();
// 检查是否是普通列表段落,numId=0可以认为是无效列表(之前生成的列表,后面清理了,但是没清理干净的,虽然word里看不见,但是底层xml文件里还残留)
if (numId != null && numId.intValue() != 0) {
XWPFNum num = this.document.getNumbering().getNum(numId);
XWPFAbstractNum abstractNum = this.document.getNumbering().getAbstractNum(num.getCTNum().getAbstractNumId().getVal());
String multiLevelType = abstractNum.getCTAbstractNum().getMultiLevelType().getVal().toString();
if ("singleLevel".equalsIgnoreCase(multiLevelType)) {
return "list";
}
}
return "text";// 普通文本段落
}
/**
* 转换程序,直接调用该方法进行word转换html的工作
*
* @return
* @throws Exception
*/
private void convert() {
asHtml.append("").append("\n");
asHtml.append("").append("\n");
asHtml.append("").append("\n");
asHtml.append("\tdocx转换html之解析目录结构 ").append("\n");
asHtml.append("\t").append("\n");
asHtml.append("\t\n");
asHtml.append("").append("\n");
asHtml.append("").append("\n");
List<IBodyElement> elems = document.getBodyElements();
asHtml.append("\t").append("\n");
buildCatalog();
asHtml.append("\t\t").append("\n");
for (IBodyElement be : elems) {
try {
if (be.getElementType().equals(BodyElementType.PARAGRAPH)) {// 是段落
XWPFParagraph p = (XWPFParagraph) be;
String text = p.getText();
String paragraphType = getParagraphType(p);
if (paragraphType.contains("heading")) {// 输出标题
DocCatalogNodeProcessor02 processor02 = new DocCatalogNodeProcessor02(p.getText());
docCatalogList.walk(processor02);
DocCatalog catalog = processor02.fetch();
if (catalog == null) {
continue;
}
String code = catalog.getCode();// 获取到目录节点代码
asHtml.append("\t + code + "\" id=\"" + code + "\">\n");
asHtml.append(").append(catalog.getLevel()).append(">");
asHtml.append(catalog.getFullTitle());
asHtml.append(" ).append(catalog.getLevel()).append(">\n");
asHtml.append("\t\n");
continue;
} else if (paragraphType.equals("list")) {// 说明是列表段落
System.out.println("忽略列表解析");
} else {// 输出正文
if (text == null || text.trim().equals("")) {
asHtml.append("\t\n");
continue;
} else {
String ali = p.getAlignment().name().toLowerCase();
int fstIndent = p.getFirstLineIndent() <= 0 ? 0 : p.getFirstLineIndent();
int lftIndent = p.getIndentFromLeft() <= 0 ? 0 : p.getIndentFromLeft();
int indent = fstIndent + lftIndent;
asHtml.append("\t + indent / 10 + "px;text-align:" + ali + "\">\n");
asHtml.append("");
asHtml.append(p.getText().replaceAll(" ", " "));
asHtml.append("");
asHtml.append("\t
\n");
continue;
}
}
} else{
System.out.println("其他word元素如表格,这里忽略");
}
} catch (Exception e) {
e.printStackTrace();
continue;
}
}
asHtml.append("\t\t").append("\n");
asHtml.append("\t").append("\n");
asHtml.append("").append("\n");
asHtml.append("");
}
}
测试demo
package com.bigbrain.docx2html;
import java.io.File;
import java.io.FileWriter;
public class DemoTest {
public static void main(String[] args) throws Exception{
Docx2Html_Catalog convertor = new Docx2Html_Catalog(new File("q:\\word解析\\docx版本的word.docx"));
String html = convertor.asHtml();
FileWriter fw = new FileWriter("q:\\word解析\\docx版本的word.html");
fw.write(html);
fw.close();
}
}
结语
到这里,docx的word文档的目录结构解析就完成了,您可以使用更加复杂的层级结构来检验。这里只是简单说明下目录原理,要达到现实中的使用需求,还有很多地方要补充完善,比如:
- 通过html锚点定位到文章指定地方
- 好的文档结构还有很多有序或者无序列表,和目录解析的原理也差不多,后面有时间,我会分享出来。
- 甚至还有一些地方不是严格按段落样式来的,有夹杂的地方,很多地方还需要做好兼容性控制。
项目代码
这是一个maven项目,点击下载即可。完整的代码都在里面。如需要更多的word解析转换功能可以关注后面的文章(如果写了的话),也可以联系我微信(hoodlake)
docx2html_catalog