jenkins 原理篇——pipeline流水线 声明式语法详解
大家好,我是蓝胖子,相信大家平时项目中或多或少都有用到jenkins,它的piepeline模式能够对项目的发布流程进行编排,优化部署效率,减少错误的发生,如何去写一个pipeline脚本呢,今天我们就来简单看看pipeline的语法。
先拿一个hello world的pipeline脚本举例,我们来看看pipeline脚本的组成
pipeline {
agent any
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
}
}
}
脚本都是以pipeline的关键字开头,接着看下pipeline内部具体由哪几部分组成。
agent
agent 部分指明了pipeline脚本在哪台机器或者容器内执行,因为jenkins的工作模式是master-agent模式,master可以把流水线任务的执行放到其代理节点上执行。
同时jenkins的节点(master节点或者agent代理节点)可以打上标签,如下表示的是pipeline脚本需要在标签为jdk8的节点上运行。
pipeline {
agent {
node {label:'jdk8'}
}
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
}
}
}
agent模块也可以写到stage里,表示特定stage模块都在指定的agent节点上运行,如下所示,
pipeline {
agent any
stages {
stage('Hello') {
agent {
node {label:'jdk8'}
}
steps {
echo 'Hello World'
}
}
}
}
在文章开头的hello world的脚本中,agent我们指定了any,这表示可以在任意节点上运行pipeline脚本。agent模块不可省略不写。
stages
接着来看下stages模块,stages模块由多个stage组成,一个stage表示一个阶段,比如我们通常将发布的整个流程分为编译,传输,部署等几个阶段。
stage
一个阶段由多个步骤组成,在pipeline语法中,步骤通过steps模块表示,steps包含了一个或多个步骤,在上述hello world的pipeline脚本中,echo ‘Hello World’ 就是一个步骤,比如我们想要执行shell命令就要运行sh步骤,如下所示,
pipeline {
agent any
stages {
stage('Hello') {
steps {
sh 'ping 127.0.0.1'
}
}
}
}
pipeline的步骤是可插拔的,可以通过安装某些插件来执行特定的步骤。
post
除了上述模块,还可以在stages或者steps模块后面定义post模块来表示整个pipeline执行完成或者单个stage完成后需要执行的动作。
如下所示,
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'echo Build stage ...'
}
post {
always {
echo "post condition executed: always ..."
}
}
}
}
post {
unstable {
echo "post condition executed: unstable ..."
}
failure {
echo "post condition executed: unsuccessful ..."
}
cleanup {
echo "post condition executed: cleanup ..."
}
}
}
post模块可以定义多个条件块,条件块里写上要执行的步骤,条件块有以下几种,
- always: 无论当前执行结果是什么状态都执行
- changed: 当前完成状态和上一步完成状态不同则执行
- fixed: 上一步为失败或不稳定(unstable) ,当前状态为成功时
- regression: 上一次完成状态为成功,当前完成状态为失败、不稳定或中止(aborted)时执行。
- aborted: 当前执行结果是中止状态时(一般为人为中止)执行。
- failure:当前完成状态为失败时执行。
- success:当前完成状态为成功时执行。
- unstable:当前完成状态为不稳定时执行,通常是
- cleanup:清理条件块。不论当前完成状态是什么,在其他所有条件块执行完成后都执行。
这里再着重解释下unstable 状态,通常我们将测试失败的状态设定为unstable,可以把它理解成日志等级的warn状态。如下我们可以主动设置stage和构建结果为unstable状态。
pipeline {
agent any
stages {
stage('Test') {
steps {
warnError('watch it'){
sh '''
echo 'Running tests...'
exit 1
'''
}
}
}
stage('Hello2') {
steps {
echo 'hello'
}
}
}
post {
failure {
echo "failure"
}
success {
echo "success"
}
unstable {
echo "unstable"
}
}
}
最终产生的构建视图如下:
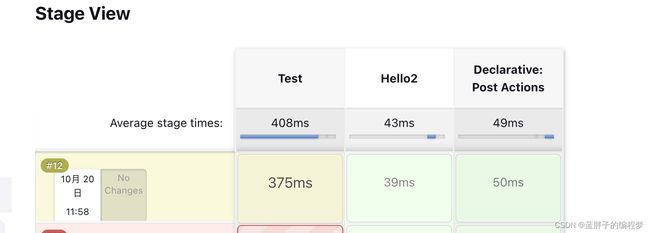
指令
pipeline除了上述的基本结构外,还提供了一些其他指令作为其基本结构的补充,
Jenkins pipeline支持的指令有:
- environment:用于设置环境变量,可定义在stage或pipeline部分。
- tools:可定义在pipeline或stage部分。它会自动下载并安装我们指定的工具,并将其加入PATH变量中。
- input:定义在stage部分,会暂停pipeline,提示你输入内容。
- options:用于配置Jenkins pipeline本身的选项,比如options {retry(3)}指当pipeline失败时再重试2次。options指令可定义在stage或pipeline部分。
- parallel:并行执行多个step。在pipeline插件1.2版本后,parallel开始支持对多个阶段进行并行执行。
- parameters:与input不同,parameters是执行pipeline前传入的一些参数。
- triggers:用于定义执行pipeline的触发器。
- when:当满足when定义的条件时,阶段才执行。
在使用指令时,需要注意的是每个指令都有自己的“作用域”。如果指令使用的位置不正确,Jenkins将会报错。
更多的配置案例请参考 流水线语法 (jenkins.io)
嵌入式脚本
在pipeline 声明式语法中,当需要执行代码块条件判断时除了使用when指令,还可以使用groovy语法的脚本,脚本还可以执行for循环的操作,配置代码如下,脚本需要被script块包括起来
写script块内的脚本需要先简单了解下groovy的语法
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
script {
def browsers = ['chrome', 'firefox']
for (int i = 0; i < browsers.size(); ++i) {
echo "Testing the ${browsers[i]} browser"
}
}
}
}
}
}
函数调用
pipeline脚本同样可以定义函数,然后通过调用函数来执行一段逻辑,函数的定义遵循groovy的语法,如下,我定义了一个hello的函数,然后对其进行调用。
注意,函数定义是放到pipeline外面的。因为要接收函数返回值,所以整个函数调用是放到了script块里,groovy的语法中双引号中可以用$变量名来引用特定的变量。
def hello(String name){
echo "$name"
return "Yes"
}
pipeline {
agent any
stages {
stage('Hello2') {
steps {
script {
def res = hello('Beatiful')
echo "$res"
}
}
}
}
}
共享库
虽然pipeline脚本能够定义函数提取重复逻辑,但是如果有100个pipeline脚本都需要同一个函数,不可能定义100遍这样的函数,所以jenkins提供了共享库的机制,来让我们方便去定义一个函数可以供多个pipeline脚本使用。下面介绍下写一个共享库的基本步骤,
创建一个代码库,并上传git
我们要写的函数就定义在vars目录下,在vars目录中的文件名如果有多个单词需遵循驼峰格式的命名,到时候引用函数的函数名和vars目录下的文件名一致。
BoxJenkins
├── README.md
├── src
└── vars
├── hello.groovy
hello.groovy 的文件内容如下,注意里面的函数名call是固定的,不可变动。
def call(String name){
echo "$name"
}
jenkins 引入共享库
在Jenkins的Manage Jenkins→Configure System→Global Pipeline Libraries中配置共享库的git地址。
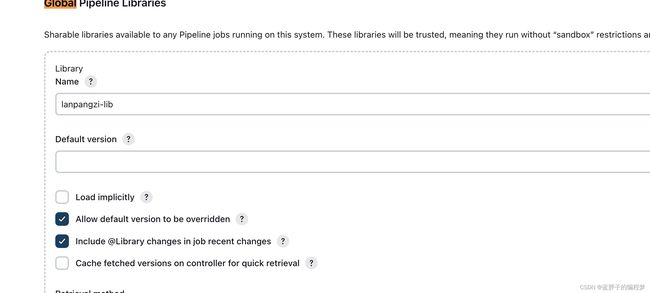
其中Name则是到时候我们要引入的库名称
pipeline 中引入共享库
引入共享库的语法为 在pipeline块外部使用@Library(‘lanpangzi-lib@master’) _ ,以下是配置示例,其中@master 中的master代表库的版本,可以由分支名,tag名,乃至commit id代替。
@Library('lanpangzi-lib@master') _
pipeline {
agent any
stages {
stage('Hello2') {
steps {
hello('wudi')
}
}
}
}
关于共享库还有更多的用法,例如在共享库中定义pipeline模板,以及使用共享库中src的代码,这里就不再展开了。
总结
这一节,基本上对jenkins的pipeline脚本语法做了比较完整的介绍,在以后再看pipeline脚本时,可能还会接触到许多插件提供的函数或更多的指令,但是它们都逃不开pipeline脚本的基本结构,掌握了基础语法,后面才能更上一层楼。