linux驱动开发(二):Linux字符设备驱动程序(设备号、cdev、设备节点、file_operations)
Linux系统将设备分成字符设备、块设备、网络设备三类。

用户程序调用硬件的过程如下。
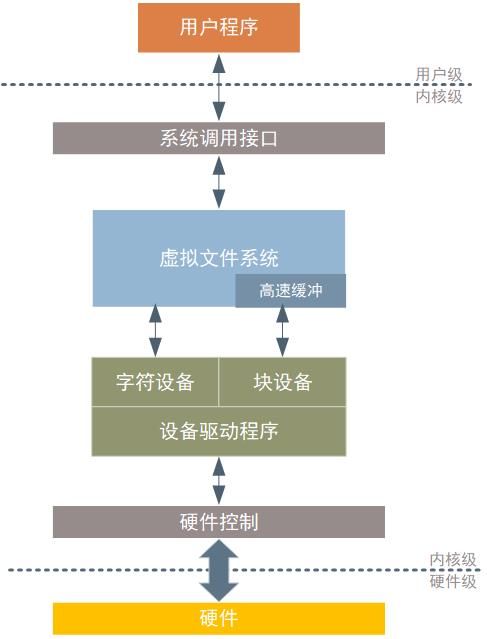
一、用户级、内核级和系统调用
Linux/Unix系统下的进程运行分为用户态和进程态两种状态。我们的应用程序通常仅在用户态下运行,出于保护内核资源的需要,用户态下运行的程序在只能访问有限的资源,例如不能访问内核的数据结构和程序。
内核的一个重要功能就是协调和管理硬件资源,包括CPU、内存、I/O设备等,从而为上层运行的诸多应用程序提供更好的运行环境。因此,驱动程序通常都是在内核态下运行。我们的进程大多数时间都是运行在用户态下的,一旦它需要操作系统帮助它完成一些自己没有权限和能力完成的工作,就会切换到内核态。而系统调用就是进程主动申请从用户态切换到内核态的方式。
除了系统调用以外,发生异常或外围设备的中断也会让进程从用户态进入内核态。但是,系统调用是应用程序主动转入内核态,而异常和中断是被动转入内核态。
异常又称内中断,来源于操作系统的内部,通常是进程执行时引发了故障,如缺页、地址越界、算术溢出、除数为零等。异常产生后,操作系统会夺回内核的使用权,对异常进行处理。
外围设备的中断是指在外围设备在处理完用户要求的操作后,会向操作系统发出中断信号,此时操作系统会暂停执行当前正在执行的指令,转而处理中断信号。这个过程需要在内核态下进行,因此会由用户态进入内核态。
二、虚拟文件系统(VFS)
1. 什么是虚拟文件系统
我们在Unix/Linux系统下用户程序操作普通文件,即txt、pdf、mp4等,使用open函数打开文件,使用read、write函数对文件进行读写,使用close函数关闭文件。但除了普通文件外,Unix/Linux的创作者提出“一切皆文件”的思想,希望将目录、字符设备、块设备、套接字等也被等同于文件对待,使用普通文件使用相同的文件操作接口,如open、read、write,对这些设备进行操作。
虚拟文件系统(Virtual File System,VFS)是Linux系统中的一个软件抽象层,它就是实现上述功能的关键。它为用户空间的程序提供了文件系统接口,同时定义了所有文件系统都支持的基本的、概念上的接口和数据结构。例如,读写普通的文本文件和读写I/O设备的具体实现方法必然是不同的,但VFS提供了统一的接口read和write,开发人员需要编写这些接口的具体的不同的实现。因此,在VFS层和内核的其他部分看来,所有文件都只需调用read和write函数就可以完成读写功能,具体的实现过程它们并不关心。
2. 文件接口结构体file_operation
Linux内核定义了结构体file_operation,作为提供给VFS的文件接口。该结构体的定义如下。
include/linux/fs.h
---------------------------------------------------------------------------------------------------
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iopoll)(struct kiocb *kiocb, bool spin);
int (*iterate) (struct file *, struct dir_context *);
int (*iterate_shared) (struct file *, struct dir_context *);
__poll_t (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
unsigned long mmap_supported_flags;
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **, void **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
void (*show_fdinfo)(struct seq_file *m, struct file *f);
#ifndef CONFIG_MMU
unsigned (*mmap_capabilities)(struct file *);
#endif
ssize_t (*copy_file_range)(struct file *, loff_t, struct file *,loff_t, size_t, unsigned int);
loff_t (*remap_file_range)(struct file *file_in, loff_t pos_in,struct file *file_out, loff_t pos_out,loff_t len, unsigned int remap_flags);
int (*fadvise)(struct file *, loff_t, loff_t, int);
};
file_operations的成员变量基本上都是函数指针,驱动开发者需要根据不同设备的要求,为这些函数指针编写具体的实现。以open函数为例,不同设备的打开方式不同,因此open函数的实现显然应该是不同的,但从VFS层面上看,都是只需要调用open函数就可以满足打开设备的需求。
举个例子。这一步同样在驱动程序cdev_driver.c中,我们需要首先新建一个file_operations结构体fops,并实现其中的open、release、read、write函数。
#define KMAX_LEN 32
static int demo_open(struct inode *ind, struct file *fp)
{
printk("demo open\n");
return 0;
}
static int demo_release(struct inode *ind, struct file *fp)
{
printk("demo release\n");
return 0;
}
static ssize_t demo_read(struct file *fp, char __user *buf, size_t size, loff_t *pos)
{
int rc;
char kbuf[KMAX_LEN] = "read test\n";
if (size > KMAX_LEN)
size = KMAX_LEN;
rc = copy_to_user(buf, kbuf, size); //将字符串kbuf拷贝到用户空间下的buf中
if(rc < 0) {
return -EFAULT;
pr_err("copy_to_user failed!");
}
return size;
}
static ssize_t demo_write(struct file *fp, const char __user *buf, size_t size, loff_t *pos)
{
int rc;
char kbuf[KMAX_LEN];
if (size > KMAX_LEN)
size = KMAX_LEN;
rc = copy_from_user(kbuf, buf, size); //将用户空间下的buf中的内容拷贝到内核空间中
if(rc < 0) {
return -EFAULT;
pr_err("copy_from_user failed!");
}
printk("%s", kbuf);
return size;
}
static struct file_operations fops = {
.open = demo_open,
.release = demo_release,
.read = demo_read,
.write = demo_write,
};
file_operations结构体中的成员都是函数指针,我们的工作就是编写四个函数demo_open、demo_release、demo_read、demo_write,并将它们分别赋值给.open、.release、.read、.write四个函数指针。其中demo_open和demo_release两个函数比较简单,打印两句话即可,demo_read和demo_write分别实现读写操作。demo_read用于将内核中定义的字符串“read test”读出到buf中,并返回实际读出的字符串长度size;demo_write用于向内核中写入一个长度为size的字符串buf。size不能超过限定的最大长度KMAX_LEN。
由于读出和写入操作是跨越用户空间和内核空间的,所以需要使用copy_to_user和copy_from_user两个函数。前者用来从内核空间拷贝到用户空间,后者反之。
三、设备号
1. 什么是设备号
Linux系统使用设备号来区分各个设备。设备号是一个32位的无符号整型数,它的高12位是主设备号,低20位是次设备号。

为什么要区分主设备号和次设备号呢?
举个例子,在一个硬件上可能有多个串口,系统会将每个串口都作为一个设备处理。但很多时候,这些串口发挥的作用是相同的,只有地址不同。我们希望这些串口都由同一个驱动管理,而不是为每个串口都写一个驱动程序,因此Linux将设备号分为主设备号和次设备号。我们将这些串口分配相同的主设备号和不同的次设备号,这样只要使用同一个驱动程序即可。
/proc/devices文件下记录着每个设备和它对应的设备号,注意,字符设备和块设备是分开独立编号的。(/proc目录用来存放系统进程运行时使用的文件)

2. 与设备号有关的宏
Linux内核定义了一些与设备号有关的宏,常见的宏如下。
#define MKDEV(major, minor) //将主设备号和次设备号拼接成设备号
#define MAJOR(devno) //从设备号中提取主设备号
#define MINOR(devno) //从设备号中提取次设备号
3. 分配和释放设备号的函数
(1) register_chrdev_region()函数静态分配设备号
register_chrdev_region()函数用来静态分配一系列字符设备号给字符设备。这一系列字符设备有相同的主设备号,次设备号是连续的。之所以是静态分配,是指需要程序员自己指定分配哪个设备号给设备。
函数原型为
int register_chrdev_region(dev_t from, unsigned count, const char *name)
各个参数的含义。
| 参数 | 含义 |
|---|---|
| from | 要分配的这一系列设备号的第一个设备号 |
| count | 分配的设备号的个数 |
| name | 设备的名字 |
返回值:设备分配成功时返回0,分配失败时,例如要分配的设备号已经被占用了,则返回一个负值的错误码。
举个例子,上文中使用cat /proc/devices指令可以看出233号设备号没有被分配,所以我们选取233设备号分配给新的驱动设备,只分配一个次设备号且第一个次设备号为0。代码如下
static int major = 233; //主设备号
static int minor = 0; //一系列次设备号中的第一个次设备号
static dev_t devno; //设备号
static int demo_init(void)
{
int rc;
devno = MKDEV(major, minor); //根据主设备号和次设备号合成设备号
rc = register_chrdev_region(devno, 1, "test"); //向系统中注册设备号
if(rc < 0) {
pr_err("register_chrdev_region failed!");
return rc;
}
return 0;
}
module_init(demo_init);
可以看到233号主设备号已经分配给了设备“test”。

(2) alloc_chrdev_region()函数动态分配设备号
alloc_chrdev_region()函数用来动态分配一系列字符设备号给字符设备,也就是说系统会自动从未分配出去的设备号中选择一个分配给当前设备,而不再需要程序员自己手动找一个未分配的设备号。
函数原型如下。
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, const char *name)
各个参数的含义。
| 参数 | 含义 |
|---|---|
| dev | 将分配的一系列设备号的第一个的值通过该参数返回出来 |
| baseminor | 要分配的这一系列设备号的第一个次设备号 |
| count | 分配的设备号的个数 |
| name | 设备的名字 |
返回值:设备分配成功时返回0,分配失败时返回一个负值的错误码。
举个例子,我们通过该函数动态分配设备号给设备,第一个次设备号为0,只分配一个设备号,则代码如下。
static dev_t devno; //设备号
static int demo_init(void)
{
int rc;
rc = alloc_chrdev_region(&devno, 0, 1, "test"); //系统动态分配设备号
if(rc < 0) {
pr_err("alloc_chrdev_region failed!");
return rc;
}
printk("MAJOR is %d\n", MAJOR(devno));
printk("MINOR is %d\n", MINOR(devno));
return 0;
}
module_init(demo_init);
dmesg打印一下内核的输出信息,可以看到系统分配了240设备号给该设备。

查看一下/proc/devices文件,可以看到240设备号的分配。

(3) unregister_chrdev_region()函数释放设备号
unregister_chrdev_region函数用来将设备号释放掉,register_chrdev_region()和register_chrdev_region()申请的设备号都能用该函数释放。由于设备号是临界资源,同一个设备号不能被多个设备共有,因此设备使用结束后一定要及时释放,以免不必要的资源浪费。
void unregister_chrdev_region(dev_t from, unsigned count)
该函数参数的含义与register_chrdev_region参数的含义相同。
举例如下。
static void demo_exit(void)
{
unregister_chrdev_region(devno, 1); //向系统中注销设备号
return;
}
module_exit(demo_exit);
4. 设备号分配的原理
在Linux内核中定义了一个全局指针数组chrdevs,用来管理分配出去的设备号。chrdevs的每一个元素都是一个指向char_device_struct结构体的指针。它的具体定义如下。
fs/char_dev.c
-----------------------------------------------------------------------------------------------
#define CHRDEV_MAJOR_HASH_SIZE 255
static struct char_device_struct {
struct char_device_struct *next;
unsigned int major;
unsigned int baseminor;
int minorct;
char name[64];
struct cdev *cdev;
} *chrdevs[CHRDEV_MAJOR_HASH_SIZE];
每个成员的含义如下。
| 成员 | 含义 |
|---|---|
| next | 链表中指向下一个节点的指针 |
| major | 主设备号 |
| baseminor | 次设备号的第一个 |
| minorct | 申请的次设备号的数量 |
| name | 设备的名字 |
| cdev | 下文中会具体介绍cdev结构体 |
chrdevs实际上是一个哈希表,它的关键字为主设备号major,散列函数为index = major % 255。初始状态下,没有设备号被分配出去,chrdevs数组为空。一旦有设备号被分配,则首先为该设备创建一个char_device_struct结构体对象,然后根据主设备号计算得到散列结果,将结构体对象挂载在chrdevs中的对应位置上。如果该位置已经有节点,则根据次设备号由小到大的寻找到合适的位置,挂载在对应节点的next指针上,构成有序列表。
下面举个例子说明这个过程。
初始状态下的的chrdevs表,实际上是255个char_device_struct *类型指针。
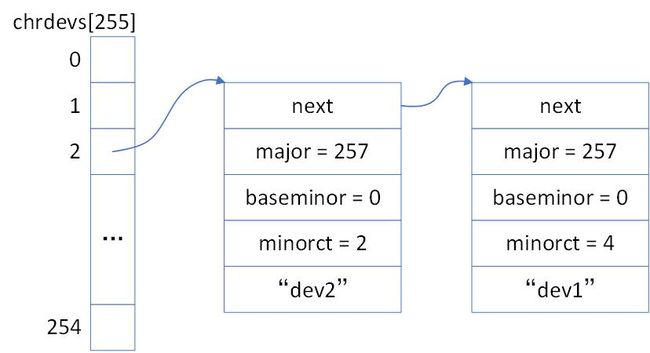
使用register_chrdev_region函数,向系统注册一个主设备号major = 257、次设备号为0到3的设备、名称为“dev1”的设备,则需要首先创建一个char_device_struct结构体,并对结构体中的成员进行初始化,然后计算散列值i = 257 % 255 = 2,并让chrdevs[2]这个指针指向这个结构体。

如果我们再向系统注册一个主设备号为2、次设备号为0到1、名称为“dev2”的设备,则同样创建一个char_device_struct结构体并初始化。这次我们计算得到的散列值i = 2 % 255依旧为2,与上一个设备在哈希表上产生了冲突,这时结构体中的指针发挥了作用,我们将新结构体挂在老结构体的前面或后面,形成一个链表即可。挂载的位置由主设备号的大小决定,我们要求形成的链表是一个major由小到大排序的有序链表。
四、字符设备的内核抽象
1. 字符设备结构体cdev
内核为字符设备抽象出一个结构体cdev,定义如下:
struct cdev {
struct kobject kobj;
struct module *owner;
const struct file_operation *ops;
struct list_head list;
dev_t dev;
unsigned int count;
};
每个成员的含义如下。
| 成员 | 含义 |
|---|---|
| kobj | 内嵌的内核对象,此处不展开讨论 |
| owner | 字符设备驱动程序所在的内核模块指针,此处不展开讨论 |
| ops | 提供给VFS的文件接口结构体 |
| list | 将系统中的字符设备形成链表 |
| dev | 字符设备的设备号 |
| count | 隶属于同一主设备号的次设备号的数量,表示当前设备驱动程序控制的设备的数量 |
2. 字符设备的初始化函数cdev_init()
Linux内核为初始化cdev对象提供了cdev_init函数,定义如下。
fs/char_dev.c
-----------------------------------------------------------------------------------------------
void cdev_init(struct cdev *cdev, const struct file_operations *fops)
{
memset(cdev, 0, sizeof *cdev);
INIT_LIST_HEAD(&cdev->list);
kobject_init(&cdev->kobj, &ktype_cdev_default);
cdev->ops = fops;
}
这个函数的作用就是针对一个cdev结构体里面的成员进行初始化,其中最重要的一步就是把cdev和fops连接在一起,因为每一个设备都会有一个自己的文件操作逻辑,即需要实现一个自己的file_operations结构体。
3. 向系统添加字符设备函数cdev_add()
将字符设备加入到系统中,简单地说,就是将上文中我们初始化的cdev结构体添加到Linux系统维护的一个全局哈希链表cdev_map中,这样其他模块才能使用通过cdev_map找到它。Linux为了完成这个操作,提供了cdev_add函数,实现如下。
fs/char_dev.c
-----------------------------------------------------------------------------------------------
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
{
p->dev = dev;
p->count = count;
return kobj_map(cdev_map, dev, count, NULL, exact_match, exact_lock, p);
}
函数参数的含义如下。
| 参数 | 含义 |
|---|---|
| p | 要加入系统的字符设备对象的指针 |
| dev | 该设备的设备号 |
| count | 被注册的设备数量 |
该函数的核心功能在kobj_map函数中实现,该函数的实现略微有些复杂,此处不再赘述,有兴趣的可以阅读附录。
4. 向设备删除字符设备函数cdev_del()
相应的,删除设备需要使用cdev_del函数。该函数的作用就是将对应的设备从系统中移除,即从cdev_map链表中删除节点并释放内存空间。其定义如下。
fs/char_dev.c
-----------------------------------------------------------------------------------------------
void cdev_del(struct cdev *p)
{
cdev_unmap(p->dev, p->count);
kobject_put(&p-> kobj);
}
5. 举例
在上文中已经完成了file_operations接口实现和alloc_chrdev_region()函数注册设备号这两个操作后,可以在模块初始化函数demo_init()函数中调用cdev_init()和cdev_add()初始化并添加字符设备。
cdev_init(&cd, &fops); //初始化字符设备结构体
rc = cdev_add(&cd, devno, 1); //将字符设备结构体加入系统中
if (rc < 0) {
pr_err("cdev_add failed!");
return rc;
}
在模块卸载函数demo_exit()中调用cdev_del函数删除字符设备。
cdev_del(&cd); //从系统中删除字符设备结构体
五、设备节点
1. 什么是设备节点
设备节点也可以称为设备文件,是一种特殊类型的文件,其作用是沟通用户空间的应用程序和内核空间的驱动程序的节点。应用程序如果想使用驱动程序提供的服务,则必须经过设备节点实现。
2. 设备节点的创建
设备节点有静态创建和动态创建两种方式,我们这里只介绍静态创建方法。Linux系统使用mknod命令静态创建设备节点,该命令需要列出设备节点的设备节点名、主设备号和次设备号。通常情况下,Linux系统将所有设备节点都放在/dev目录下,因此我们也将设备节点创建在/dev目录下。该命令具体格式如下。
mknod /dev/<设备节点名> c <主设备号> <次设备号>
参数c表示节点的类型为字符设备。
如上文中alloc_chrdev_region()函数在系统中申请了240设备号给该字符设备,字符设备节点的名称取名为test_chr_dev,则则mknod指令的写法如下
![]()
查看dev目录可以看到新增加的设备节点。
mknod命令是通过调用mknod函数实现,它会通过系统调用sys_mknod进入内核空间,并生成一个inode。
inode是Linux文件管理系统维护的一个结构体,每一个文件(不限于设备节点)都会有一个自己inode,用来存储文件的静态信息,如文件访问权限、属主、组、大小、生成时间、访问时间、最后修改时间等。
由于inode结构体中的成员非常多,我们此处不再一一列举,只列举几个常用的。
struct inode {
kuid_t i_uid; //属主的ID(UID)
kgid_t i_gid; //属主的组ID(GID)
loff_t i_size; //文件大小
dev_t i_rdev;
struct cdev *i_cdev;
......
};
这里我们主要用到i_rdev和i_cdev两个成员,i_rdev是该设备的设备号,i_cdev是该设备的cdev结构体。
3. 设备节点的打开
在创建了设备节点和它的inode后,应用程序就可以像打开普通文件一样使用open函数打开设备节点。用户空间下的应用程序使用open系统调用,其函数原型如下。
int open(const char *filename, int flags, mode_t mode);
参数的含义
| 参数 | 含义 |
|---|---|
| filename | 要打开的文件的文件名 |
| flags | 该文件的打开模式或创建模式 |
| mode | 仅在创建一个新文件时使用,用于指定新建文件的访问权限 |
| 返回值 | 成功时返回该文件的文件描述符,失败时返回-1 |
文件描述符(File Discriptor, fd)本质是一个int型变量(非负整数),可以看作Linux系统为每个打开的文件分配的一个索引值。在后续对该文件的read、write、close等操作时,都要通过这个索引值,来找到这个打开的文件。
系统调用open通过层层复杂的机制,最终会调用到我们为该设备编写的file_operations结构体中的.open函数中,最终实现该设备的打开操作。
Linux会为每一个打开的文件维护一个file结构体,它在文件打开时被创建,直到该文件关闭时被释放。与inode结构体不同,一个文件只能有一个inode结构体,但如果它被同时打开很多次,那么Linux会为它创建多个file结构体,且file结构体最终指向同一个inode。
file结构体中的成员较多,下面列举一些常用的成员。
struct file {
struct inode *f_inode;
const struct file_operations *f_op;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
void *private_data;
......
};
几个常用的成员及其含义如下。
| 成员 | 含义 |
|---|---|
| f_op | 与文件关联的各种操作file_operations |
| f_count | 记录该文件对象被引用的次数,也就是有多少个进程正在使用该文件 |
| f_flags | 文件打开时指定的标志,驱动程序中常用O_NONBLOCK来检查是否是非阻塞请求 |
| f_mode | 文件的读写模式,通过置位FMODE_READ和FMODE_WRITE,来确定文件是可读、可写或者既可读又可写的 |
| f_pos | 文件当前的读写位置,本质是一个long long类型的值 |
| private_data | 用来保存自定义设备结构体的地址 |
以上就是字符设备中常用的数据结构和算法,在下一篇博客中,我会举一个实例,来使用上述内容完成一个应用程序与驱动程序交互的实例。