第三章 信息收集
目录
3.1 信息收集的目标
3.2 信息收集的内容
1. 硬件设备
2. 操作系统
3. 应用软件
4. 网络环境
3.3 信息收集的分类
1.被动信息收集
2.主动信息收集
3.4 信息收集演练
3.4.1 IP地址查询
1. 查询本机的IP地址
2. 查询某个网站的IP地址
3.4.2 whois信息收集
1. 采用whois命令查询
2. 采用工具dmitry查询
3. 采用网站在线查询whois信息
3.4.3 DNS信息收集
1. 采用host命令查询DNS信息
2. 采用工具dnsenum查询DNS信息
3.4.4 旁站查询
1. 用微软必应搜索引擎查询
2.用其他提供旁站查询服务的在线网站查询
3.4.5 C段网站查询
3.4.6 Google Hack
3.4.7 发现主机
3.4.8 端口扫描
1. 用工具nmap进行端口扫描
2.用工具unicornscan进行端口扫描
3.4.9 指纹探测
1. 收集目标主机的系统及其版本信息
2. 收集目标主机开启的服务端口及其版本信息
3. 收集目标主机的CMS信息
3.4.10 Web敏感目录扫描
1. 用工具dirb扫描web目录
2. 用工具webscarab扫描web目录
3. 用工具burpsuite扫描web目录
3.1 信息收集的目标
1. 硬件设备
大的方面包括系统架构信息、网络设备信息(包括网络终端设备,如主机、服务器、智能终端;网络连接设备,如中继器、集线器、网关、交换机、路由器、网关、AP等);小的方面包括CPU、内存、磁盘、网卡、声卡、显卡、调制解调器、接口、数据线等各种设备的信息。
2. 操作系统
Windows操作系统、Linux操作系统等。
3. 应用软件
除了传统的四种大应用:Web应用、邮件服务、远程登录服务、FTP应用外,随着电子商务、电子政务和各种手机APP应用的普及,这些新兴的应用日渐成为黑客攻击的主要目标。
4. 网络环境
有线网络、无线网络。
3.2 信息收集的内容
1. 硬件设备
- 硬件设备名称、厂商、型号、生产日期、使用寿命
- 硬件产品的功能和用途
- 接口、制造工艺、容量、转速、磁盘访问速度、磁盘文件格式、散热情况信息
- 网卡接口、带宽、有线还是无线
- 对于无线网卡,其信号强度、信号覆盖范围、信道数等信息
2. 操作系统
主机名称、操作系统名称、操作系统类型(如32位、64位)、操作系统版本、操作系统制造商、操作系统配置、操作系统构件类型、系统用户、初始安装时间等。
3. 应用软件
软件的名称、版本、运行平台、运行环境、工作环境(如单机模式、客户机/服务器模式、浏览器/服务器模式、P2P模式等)、文件目录、文件名称和大小、可执行的程序名称、运行的进程名称、运行的端口、CPU占用率、内存使用情况、网络带宽等信息。
4. 网络环境
- 网络类型信息(有线网络、无线网络、卫星通信、局域网、广域网、私有网络、企业网络、内部网络、外部网络等)
- 网络拓扑信息(如物理拓扑、逻辑拓扑)
- 网络协议信息(如链路层协议、网络层协议、传输层协议、应用层协议、路由协议等)
- 网络技术指标(如组网及时、有线技术、无线网络技术、数据加密技术、数据传输技术等)
- 网络性能指标(如网络带宽、网络延时、带宽延时积、网络的收敛时网络吞吐量、网络的可靠性等)
3.3 信息收集的分类
1.被动信息收集
被动信息收集不会与目标服务器做直接的交互,在不被目标系统察觉的情况下,通过搜索引擎、社交媒体等方式对目标外围的信息进行收集。所谓被动信息收集,形象地说,就是不触及目标系统自身,而是对其周边情况进行打探,避免直接接触目标而打草惊蛇。
2.主动信息收集
主动信息收集会与目标主机系统有直接的接触和交互,从目标系统直接获取需要的情报信息,例如:直接扫描目标系统开发的服务端口、采用TCP/IP堆栈探测技术收集目标主机的操作系统信息。
3.4 信息收集演练
实践环境:
Kali系统采用VMware64位Kali虚拟机系统,版本2018.2
靶机是Metasplitable2
3.4.1 IP地址查询
IP地址是一个逻辑地址,工作在TCP/IP协议栈的网络层,位于IP报文的首部字段,分源IP地址和目的IP地址。目前IP协议有IPv4协议和IPv6协议,IPv4地址有32位,IPv6有128位。IP地址由网络地址和主机地址组成。
1. 查询本机的IP地址
在Windows系统中采用 ipconfig 命令,在Linux系统采用 ifconfig 命令。
查询Kali系统本机IP地址:

采用 ifconfig 命令可查看Kali虚拟机系统所有网络接口信息,其中 lo 为环回接口, eth0 为当前工作的网卡接口(有线网络)。
图中显示了eth0网络接口的最大传输单元(mtu 1500)、IP地址(inet 192.168.43.128)、网络掩码(netmask 255.255.255.0)、所在网段的广播地址(broadcast 192.168.43.255)、IPv6的地址(inet6)以及一些发送和接收数据包的信息。
2. 查询某个网站的IP地址
ping 命令,可以查看到网站的IP地址,如图:

目前很多网站为防止服务器IP地址的泄露,减轻服务器的负担,往往会采用“内容分发网络”(Content Delivery Network,CDN)技术,一方面可以避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输更快、更稳定;另一方面通过这种镜像访问服务,使得用户实际访问的是服务器的远程镜像(Mirror)缓存(Cache)服务器,而避免用户对源站点Web服务器的直接访问。故采用上述方法获取网站服务器的IP地址可能不是一个真实服务器的IP地址,而是多个镜像服务器IP地址中的一个。要想获得真实服务器的IP地址,在ping 网络域名时,可以把前面的www去掉,如图:

原理是其实采用CDN技术,通过ping方式获得的IP地址可能是网站的镜像服务器的IP地址,但很多CDN服务器的站点没有将一级域名解析到CDN服务器上,也就是去掉www后,baidu.com 变成了一级域名,该一级域名未解析到百度的CDN镜像服务器上,而是直接与百度真实服务器的IP地址相对应。
3.4.2 whois信息收集
1. 采用whois命令查询

可以看到百度网站的whois信息,有注册域名ID、注册的whois服务器、域名服务器等。
如果Kali中没有whois命令,可以用apt-get命令安装whois
apt-get install whois2. 采用工具dmitry查询
dmitry命令部分参数:
-i Perform a whois lookup on the IP address of a host
-w Perform a whois lookup on the domain name of a host
使用dmitry查询操作如图:

3. 采用网站在线查询whois信息
一些网站的whois信息出于安全的考虑,可能会被服务器商屏蔽,无法查询到其whois信息。
3.4.3 DNS信息收集
首先对DNS的NS记录、A记录、CNAME记录、MX记录进行简要解释:
- NS记录(Name Server)
NS记录指定哪个DNS服务器对域名进行解析。一般以ns1.domain.com、ns2.domain.com形式出现。 - A记录(Address)
A记录是用来记录主机名(或域名)对应的IP地址。 - CNAME记录(别名)
CNAME记录是把域名解析到另一个域名。例如有一台计算机名为"host.domain.com",它同时提供了WWW和MAIL服务,为了便于用户访问服务,可以为该计算机设置两个别名(CNAME):WWW和MAIL,这两个别名全称分别为"www.domain.com"和"mail.domain.com"。实际上它们都指向"host.domain.com"。 - MX记录(Mail Exchanger)
主要用于邮件服务器,作用是用于定位邮件服务器的地址。如一个用户要给邮件地址为[email protected]的用户发邮件,此时该用户的所属的邮件系统会通过DNS服务器来查找mail.com这个域名的MX记录,如果存在,就会根据这个MX记录来查找对应的A记录,从而得到邮件服务器的IP地址,并将此邮件发给服务器。
1. 采用host命令查询DNS信息
host命令相关参数:

-a 显示详细的DNS信息
-t <类型> 查询指定类型的记录

2. 采用工具dnsenum查询DNS信息
dnsenum命令参数
--enum Shortcut option equivalent to --threads 5 -s 15 -w


3.4.4 旁站查询
所谓旁站就是和目标网站处于同一个服务器的站点,有些情况下,在对一个网站进行渗透时,发现网站安全性较高,久攻不下,那么我们就可以试试从其旁站入手,等拿到一个旁站的webshell(是指asp、php、jsp、cgi等网页文件形式存在的一种命令执行环境,可将其视为一种网页后门)后,看是否有跨目录的权限,如果有,直接对目标网站进行跨权限渗透;如果没有,继续提升权限拿到更高权限在对目标网站进行渗透。
1. 用微软必应搜索引擎查询
2.用其他提供旁站查询服务的在线网站查询
网站:http://s.tool.chinaz.com/same
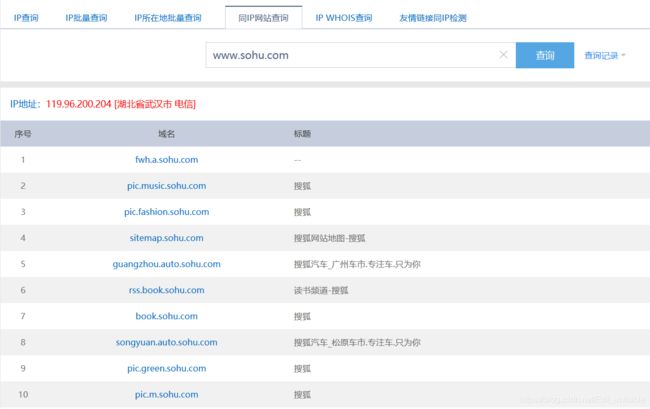
经测试,发现旁站也就是搜到的域名均与要查询的域名的IP地址为同一个。
3.4.5 C段网站查询
每个IP地址都有四个分段,如IP地址1.2.3.4,其中1为A段,2为B段,3为C段,4为D段。
如果目标网站没有拿下,旁站也一无所获,那么我们可以通过同一个C段的网站、提权拿下服务器,也就是固定A,B,C段,尝试D段1~254中的一台服务器,接着进行内网渗透。
3.4.6 Google Hack
- 查找与网站相关的URL(可能找到与目标网站的旁站)
site:要查找的网站域名
例如 site:baidu.com - 查找与网站存在的链接的站点(可能找到与目标网站的C段网站)
link:要查找的网站域名
例如 link:sohu.com - 查找指定类型的文件
filetype:文件类型
例如 site:wenku.baidu.com filetype:pdf
3.4.7 发现主机
可采用Kali里的nmap工具。
命令 nmap 相关参数:
-sP: Ping Scan - go no further than determining if host is online 用ping扫描,除了确定主机是否联机外,不要进行其他操作,一般不用,因为有的主机禁止ping。
-sn: 只进行主机发现,不进行端口扫描。


3.4.8 端口扫描
端口是一种抽象的软件结构,它既是通信进程的标识,也是进程访问传输服务的入口点。每个端口都有一个16位的端口号,有统一分配和本地分配两种。
1. 统一分配
所有协议都遵守这种分配,因此又称为熟知端口或周知端口,范围0~1023。
2. 本地分配
根据应用软件的需要动态分配端口号,也称临时端口,范围1024~65535。
端口扫描的工作原理:用客户端进程去尝试与服务器端端口建立连接,对于TCP端口,可以利用TCP建立连接三次握手的机制,当发起一个建立连接的请求包(SYN包)到目标主机指定的TCP端口时,如果收到来自对方端口的响应,则可以认为该端口是开发的;对于UDP端口,由于UDP端口是无连接的,这时可以发送UDP报文到目标主机指定的UDP端口,根据对方端口的响应方式来判断端口是否开放,一般情况下,如果接收方的UDP端口是关闭的,那么会向发送方发送一个ICMP端口不可达报文,这样发送方就能判断UDP端口是否开启。
1. 用工具nmap进行端口扫描
命令nmap参数
-p <端口号>-<端口号>: 指定要扫描的端口号范围。


2.用工具unicornscan进行端口扫描
命令unicornscan参数
-r, --pps *packets per second (total, not per host, and as you go higher it gets less accurate)
每秒数据包数(总包数,不是每台主机,越高越不准确)
-m, --mode *scan mode, tcp (syn) scan is default, U for udp T for tcp `sf' for tcp connect scan and A for arp
for -mT you can also specify tcp flags following the T like -mTsFpU for example
*扫描模式,tcp (syn)扫描为默认,U为udp T为tcp sf为tcp连接扫描,A为arp
对于-mT,您还可以在T后面指定tcp标志,例如-mTsFpU
-I, --immediate immediate mode, display things as we find them
-v, --verbose verbose (each time more verbose so -vvvvv is really verbose)
可以显示详细信息

3.4.9 指纹探测
1. 收集目标主机的系统及其版本信息
2. 收集目标主机开启的服务端口及其版本信息
3. 收集目标主机的CMS信息
1. 收集目标主机的系统及其版本信息
nmap -O 目标主机IP地址

其中CPE(Common Platform Enumerarion)为通用平台枚举。
2. 收集目标主机开启的服务端口及其版本信息
nmap -sV 目标主机IP 地址

3. 收集目标主机的CMS信息
CMS是Content Management System的缩写,意为“内容管理系统”,其作用是帮助管理员实现网站自动的管理和维护,以及内容的更新。在Kali里可以用工具whatweb来获取目标站点的CMS信息。



可以看到腾讯CDC网站采用的CMS是WordPress。
3.4.10 Web敏感目录扫描
1. 用工具dirb扫描web目录
2. 用工具webscarab扫描web目录
3. 用工具burpsuite扫描web目录
1. 用工具dirb扫描web目录
首先需要下载web目录字典文件,可以从网上下载到。然后使用命令
dirb 目标网站 web目录字典文件2. 用工具webscarab扫描web目录
1. 打开webscarab工具

2. 配置webscarab代理

3. 配置浏览器代理

4.访问目标网站
http://192.168.43.138

5.在webscarab中查看扫描结果

3. 用工具burpsuite扫描web目录
用burpsuite工具去扫描目录,也一样要先配置burpsuite代理和浏览器代理,然后再抓包,然后在将目标站点add to scope,进行扫描。

然后在查看一下添加进来的要爬取的网站

然后开启爬取

然后可以看到爬取到的目录,如图
