eSTARK:Polygon zkEVM的扩展STARK协议——支持lookup、permutation、copy等arguments(3)
前序博客有:
- eSTARK:Polygon zkEVM的扩展STARK协议——支持lookup、permutation、copy等arguments(1)
- eSTARK:Polygon zkEVM的扩展STARK协议——支持lookup、permutation、copy等arguments(2)
3.6 控制中间多项式的constraint degree
vanilla STARK协议中:
- 其初始约束集是用于证实对unbounded degree的proof计算的。
- 但当计算完quotient多项式 Q Q Q之后,应将quotient多项式 Q Q Q切分为多个degree小于 n n n的多项式,以确保向FRI协议中的trace column多项式 tr i \text{tr}_i tri添加了相同的冗余。
本节,将解释另一种方案——在proof计算之初做多项式切分,而不是在proof计算末尾做多项式切分。
因此,首先假设在初始约束集中,已包含了2.5节所定义的各种arguments,其中:
- 由multiset equality argument和inclusion argument,所引入的grand product多项式 Z i Z_i Zi约束,是具有已知degree的——degree分别为2和3。
为此,本文所提出的切分方案,支持的多项式约束degree最大为3,若超过3,则会对其仅需切分。
假设初始多项式约束集 C = { C 1 , ⋯ , C l } \mathcal{C}=\{C_1,\cdots,C_l\} C={C1,⋯,Cl},包含了total degree大于等于4的某约束。
如,有 C = { C 1 , C 2 } \mathcal{C}=\{C_1,C_2\} C={C1,C2}:
C 1 ( X 1 , X 2 , X 3 , X 1 ′ , X 2 ′ , X 3 ′ ) = X 1 ⋅ X 2 ⋅ X 2 ′ ⋅ X 3 ′ − X 3 3 , C 2 ( X 1 , X 2 , X 3 , X 1 ′ , X 2 ′ , X 3 ′ ) = X 2 − 7 ⋅ X 1 ′ + X 3 ′ . (26) \begin{matrix} C_1(X_1,X_2,X_3,X_1',X_2',X_3')=X_1\cdot X_2\cdot X_2'\cdot X_3'-X_3^3, \\ C_2(X_1,X_2,X_3,X_1',X_2',X_3')=X_2-7\cdot X_1'+X_3'. \end{matrix} \tag{26} C1(X1,X2,X3,X1′,X2′,X3′)=X1⋅X2⋅X2′⋅X3′−X33,C2(X1,X2,X3,X1′,X2′,X3′)=X2−7⋅X1′+X3′.(26)
不同于vanilla STARK协议中的“先计算(unbounded)quotient多项式 Q Q Q再切分”的策略,本文采用如下流程:
- 1)将degree t ≥ 4 t\geq 4 t≥4的约束,通过在每次切分时引入一个正式变量和一个约束,将其切分为degree小于等于3的约束。
- 2)计算有理函数 q i q_i qi。注意前一步切分,限制了 q i q_i qi的degree小于 2 n 2n 2n。
- 3)计算quotient多项式 Q ∈ F < 2 n [ X ] Q\in\mathbb{F}_{<2n}[X] Q∈F<2n[X],然后将其切分为(最多)2个degree小于 n n n的多项式 Q 1 , Q 2 Q_1,Q_2 Q1,Q2:
Q ( X ) = Q 1 ( X ) + X n ⋅ Q 2 ( X ) , (27) Q(X)=Q_1(X)+X^n\cdot Q_2(X),\tag{27} Q(X)=Q1(X)+Xn⋅Q2(X),(27)
其中:- Q 1 Q_1 Q1提取了 Q Q Q的前 n n n个系数, Q 2 Q_2 Q2提取了 Q Q Q的后 n n n个系数(若不足则补零)。
- 注意有可能 Q 2 Q_2 Q2就是零多项式。该切分技术与等式(9)中的切分技术对应,将quotient多项式 Q Q Q均匀切分给每个trace quotient多项式 Q i Q_i Qi。
以上流程可控制quotient多项式 Q Q Q的degree总是小于 2 n 2n 2n。
对应上面等式(26)中的例子,引入正式变量 Y 1 Y_1 Y1和约束:
C 2 ( X 1 , X 2 , X 3 , X 1 ′ , X 2 ′ , X 3 ′ , Y 1 ) = X 1 ⋅ X 2 − Y 1 , (28) C_2(X_1,X_2,X_3,X_1',X_2',X_3',Y_1)=X_1\cdot X_2-Y_1,\tag{28} C2(X1,X2,X3,X1′,X2′,X3′,Y1)=X1⋅X2−Y1,(28)
现在,为计算有理函数 q i q_i qi:
- 不仅需将 C 2 C_2 C2与trace column多项式 tr i \text{tr}_i tri进行组合
- 还需将其它多项式与所引入的变量 Y i Y_i Yi进行组合。将这些多项式表示为 im i \text{im}_i imi,并撑起为intermediate polynomials(中间多项式)。
因此,等式(26)中的约束集,扩大为:
C 1 ( X 1 , X 2 , X 3 , X 1 ′ , X 2 ′ , X 3 ′ , Y 1 ) = Y 1 ⋅ X 2 ′ ⋅ X 3 ′ − X 3 3 C_1(X_1,X_2,X_3,X_1',X_2',X_3',Y_1)=Y_1\cdot X_2'\cdot X_3'-X_3^3 C1(X1,X2,X3,X1′,X2′,X3′,Y1)=Y1⋅X2′⋅X3′−X33
C 2 ( X 1 , X 2 , X 3 , X 1 ′ , X 2 ′ , X 3 ′ , Y 1 ) = X 1 ⋅ X 2 − Y 1 C_2(X_1,X_2,X_3,X_1',X_2',X_3',Y_1)=X_1\cdot X_2-Y_1 C2(X1,X2,X3,X1′,X2′,X3′,Y1)=X1⋅X2−Y1
C 3 ( X 1 , X 2 , X 3 , X 1 ′ , X 2 ′ , X 3 ′ , Y 1 ) = X 2 − 7 ⋅ X 1 ′ + X 3 ′ C_3(X_1,X_2,X_3,X_1',X_2',X_3',Y_1)=X_2-7\cdot X_1'+X_3' C3(X1,X2,X3,X1′,X2′,X3′,Y1)=X2−7⋅X1′+X3′
其中,为简化标记,将变量 Y 1 Y_1 Y1也包含在 C 3 C_3 C3中。
注意,此时有2个degree小于3的约束,但额外增加了一个变量和一个约束。
对比vanilla STARK协议中的“先计算(unbounded)quotient多项式 Q Q Q再切分”策略,和,本文的“先切分再计算quotient多项式 Q Q Q”策略:
- vanilla STARK协议中的策略,有:
deg ( Q ) = max i { deg ( q i ) } = max i { deg ( C i ) ( n − 1 ) − ∣ G ∣ } \deg{(Q)}=\max_i\{\deg (q_i)\}=\max_i\{\deg(C_i)(n-1)-|G|\} deg(Q)=maxi{deg(qi)}=maxi{deg(Ci)(n−1)−∣G∣}。
以 i m a x i_{max} imax来表示具有最大degree q i q_i qi的索引号。则将 Q Q Q切分的多项式个数 S S S等于:
⌈ deg ( Q ) n ⌉ = ⌈ deg ( C i m a x ) ( n − 1 ) − ∣ G ∣ n ⌉ = deg ( C i m a x ) + ⌈ − ∣ G ∣ n ⌉ \lceil \frac{\deg(Q)}{n} \rceil=\lceil \frac{\deg(C_{i_{max}})(n-1)-|G|}{n} \rceil=\deg(C_{i_{max}})+\lceil -\frac{|G|}{n} \rceil ⌈ndeg(Q)⌉=⌈ndeg(Cimax)(n−1)−∣G∣⌉=deg(Cimax)+⌈−n∣G∣⌉
其要么等于 deg ( C i m a x ) − 1 \deg(C_{i_{max}})-1 deg(Cimax)−1,要么等于 deg ( C i m a x ) \deg(C_{i_{max}}) deg(Cimax)。
必须将该 S S S值,与本文策略中所额外引入的约束数(或多项式数)进行对比。 - 本文策略中,最终总约束数为 l ~ = ∑ i = 1 l ⌈ deg ( C i ) 3 ⌉ \tilde{l}=\sum_{i=1}^{l}\lceil \frac{\deg(C_i)}{3} \rceil l~=∑i=1l⌈3deg(Ci)⌉,其中 l ~ ≥ l \tilde{l}\geq l l~≥l。
即,转为比较 l ~ − l \tilde{l}-l l~−l与 S S S中的最小值,谁最小,相应的方案就最优。当目标是:使proof生成过程中的多项式数量最少:- 若 min { l ~ − l , S } = S \min\{\tilde{l}-l, S\}=S min{l~−l,S}=S,则选择vanilla STARK方案。
- 若 min { l ~ − l , S } = l ~ − l \min\{\tilde{l}-l, S\}=\tilde{l}-l min{l~−l,S}=l~−l,则选择本文方案。
示例4:以如下约束集,以具体的数字,来对比这2种策略:
C 1 ( X 1 , X 2 , X 3 , X 4 , X 1 ′ ) = X 1 ⋅ X 2 2 ⋅ X 3 4 ⋅ X 4 − X 1 ′ C_1(X_1,X_2,X_3,X_4,X_1')=X_1\cdot X_2^2\cdot X_3^4\cdot X_4-X_1' C1(X1,X2,X3,X4,X1′)=X1⋅X22⋅X34⋅X4−X1′
C 2 ( X 1 , X 2 , X 3 ) = X 1 ⋅ X 3 2 + X 3 3 C_2(X_1,X_2,X_3)=X_1\cdot X_3^2+ X_3^3 C2(X1,X2,X3)=X1⋅X32+X33
C 3 ( X 2 , X 3 , X 4 , X 2 ′ ) = X 2 3 ⋅ X 3 4 ⋅ X 4 + X 2 ′ C_3(X_2,X_3,X_4,X_2')= X_2^3\cdot X_3^4\cdot X_4+X_2' C3(X2,X3,X4,X2′)=X23⋅X34⋅X4+X2′
- vanilla STARK策略,有 S = 8 S=8 S=8。
- 本文策略:采用了提前切分策略,将 X 1 ⋅ X 2 2 X_1\cdot X_2^2 X1⋅X22替换为 Y 1 Y_1 Y1,将 X 2 ⋅ X 3 ⋅ X 4 X_2\cdot X_3\cdot X_4 X2⋅X3⋅X4替换为 Y 2 Y_2 Y2,从而可将如上约束集,转换为degree小于等于3的约束集,其仅额外引入了2个约束:
C 1 ( X 1 ′ , Y 1 , Y 2 ) = Y 1 2 ⋅ Y 2 − X 1 ′ , C_1(X_1',Y_1,Y_2)=Y_1^2\cdot Y_2-X_1', C1(X1′,Y1,Y2)=Y12⋅Y2−X1′,
C 2 ( X 2 , X 3 , Y 1 ) = Y 1 ⋅ X 2 + X 3 3 , C_2(X_2,X_3,Y_1)=Y_1\cdot X_2+X_3^3, C2(X2,X3,Y1)=Y1⋅X2+X33,
C 3 ( X 2 , X 2 ′ , Y 2 ) = Y 2 ⋅ X 2 2 + X 2 ′ , C_3(X_2,X_2',Y_2)=Y_2\cdot X_2^2+X_2', C3(X2,X2′,Y2)=Y2⋅X22+X2′,
C 4 ( X 1 , X 2 , Y 1 ) = Y 1 − X 1 ⋅ X 2 2 , C_4(X_1,X_2,Y_1)=Y_1-X_1\cdot X_2^2, C4(X1,X2,Y1)=Y1−X1⋅X22,
C 5 ( X 2 , X 3 , X 4 , Y 2 ) = Y 2 − X 2 ⋅ X 3 ⋅ X 4 , C_5(X_2,X_3,X_4,Y_2)=Y_2-X_2\cdot X_3\cdot X_4, C5(X2,X3,X4,Y2)=Y2−X2⋅X3⋅X4, - 本例中,本文策略要优于vanilla STARK策略。
不过,先切分的方式并不唯一。可采用不同的降约束degree方式,仍以示例4为例,将 X 1 ⋅ X 2 2 X_1\cdot X_2^2 X1⋅X22替换为 Y 1 Y_1 Y1,将 X 3 3 X_3^3 X33替换为 Y 2 Y_2 Y2,将 X 3 ⋅ X 4 X_3\cdot X_4 X3⋅X4替换为 Y 3 Y_3 Y3,将 X 2 3 X_2^3 X23替换为 Y 4 Y_4 Y4,这样会额外引入4个多项式约束:
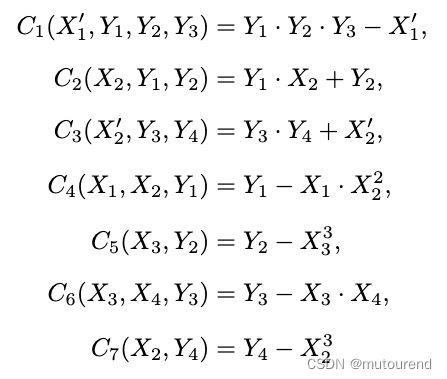
此外,具有如下格式的约束系统,就不太容易reduce:
C i ( X i , X i + 1 , X i + 2 ) = X i 3 ⋅ X i + 1 + X i + 1 3 ⋅ X i + X i + 2 C_i(X_i,X_{i+1},X_{i+2})=X_i^3\cdot X_{i+1}+X_{i+1}^3\cdot X_i+X_{i+2} Ci(Xi,Xi+1,Xi+2)=Xi3⋅Xi+1+Xi+13⋅Xi+Xi+2
若采用本文的先切分策略,这样格式的每个 C i C_i Ci会增加2个多项式约束。通俗来说,这样的约束没有重复单项,无法像之前那样生成优化替代项。因此,若哪怕只有一种这样格式的约束,也是使用Vanilla STARK的后切分策略 更优。
也就是说,应有仔细、成熟的分析来在二者中选择最优方案。不过,根据经验,只要是只有少数约束degree超过3或(/并且)在degree超过3的约束的单项之间存在多次重复,本文策略就更优。
3.7 FRI Polynomial Computation
如2.4节所示,vanilla STARK协议中的 F F F多项式计算方式为:【可并行计算】
F ( X ) : = ∑ i ∈ I 1 ε i ( 1 ) ⋅ tr i ( X ) − tr i ( z ) X − z + ∑ i ∈ I 2 ε i ( 2 ) ⋅ tr i ( X ) − tr i ( g z ) X − g z + ∑ i = 1 S ε i ( 3 ) ⋅ Q i ( X ) − Q i ( z S ) X − z S , F(X):=\sum_{i\in I_1}\varepsilon_i^{(1)}\cdot \frac{\text{tr}_i(X)-\text{tr}_i(z)}{X-z}+\sum_{i\in I_2}\varepsilon_i^{(2)}\cdot \frac{\text{tr}_i(X)-\text{tr}_i(gz)}{X-gz}\\+\sum_{i=1}^{S}\varepsilon_i^{(3)}\cdot \frac{Q_i(X)-Q_i(z^S)}{X-z^S}, F(X):=i∈I1∑εi(1)⋅X−ztri(X)−tri(z)+i∈I2∑εi(2)⋅X−gztri(X)−tri(gz)+i=1∑Sεi(3)⋅X−zSQi(X)−Qi(zS),
其中: I 1 = { i ∈ [ N ] : tr i ( z ) ∈ Evals ( z ) } , I 2 = { i ∈ [ N ] : tr i ( g z ) ∈ Evals ( g z ) } I_1=\{i\in [N]: \text{tr}_i(z)\in\text{Evals}(z)\},I_2=\{i\in [N]: \text{tr}_i(gz)\in\text{Evals}(gz)\} I1={i∈[N]:tri(z)∈Evals(z)},I2={i∈[N]:tri(gz)∈Evals(gz)} 且 ε i ( 1 ) , ε j ( 2 ) , ε k ( 3 ) ∈ K \varepsilon_i^{(1)},\varepsilon_j^{(2)},\varepsilon_k^{(3)}\in \mathbb{K} εi(1),εj(2),εk(3)∈K for all i ∈ I 1 , j ∈ I 2 , k ∈ [ S ] i\in I_1, j\in I_2, k\in [S] i∈I1,j∈I2,k∈[S],
所获得的 F F F多项式的degree 小于 n − 1 n-1 n−1,当且仅当:
- 1)trace column多项式 tr i \text{tr}_i tri 和 trace quotient 多项式 Q i Q_i Qi的degree均小于 n n n。
- 2)之前步骤中,Prover所发送的所有值,均为相应多项式的evaluation值。
与3.5节的情况类似,这种计算 F F F多项式的方式存在的主要问题是:
- 由Verifier发送的随机值的数量与 F F F中包含的的多项式个数成比例。
本文采用的,改进方案为:【可并行计算】【本文采用方案。】
- 只引入2个随机值 ε 1 , ε 2 ∈ K \varepsilon_1,\varepsilon_2\in\mathbb{K} ε1,ε2∈K,其中:
- ε 2 \varepsilon_2 ε2用于分别计算在 z z z和 g z gz gz点的evaluations值
- 最终通过 ε 1 \varepsilon_1 ε1来合并混合。
- 即定义多项式 F 1 , F 2 ∈ K n [ X ] F_1,F_2\in\mathbb{K}_{n}[X] F1,F2∈Kn[X]:
F 1 ( X ) : = ∑ i ∈ I 1 ε 2 i − 1 ⋅ tr i ( X ) − tr i ( z ) X − z + ∑ i = 1 S ε 2 ∣ I 1 ∣ + i − 1 ⋅ Q i ( X ) − Q i ( z ) X − z F_1(X):=\sum_{i\in I_1}\varepsilon_2^{i-1}\cdot \frac{\text{tr}_i(X)-\text{tr}_i(z)}{X-z}+\sum_{i=1}^S\varepsilon_2^{|I_1|+i-1}\cdot \frac{Q_i(X)-Q_i(z)}{X-z} F1(X):=∑i∈I1ε2i−1⋅X−ztri(X)−tri(z)+∑i=1Sε2∣I1∣+i−1⋅X−zQi(X)−Qi(z)
F 2 ( X ) : = ∑ i ∈ I 2 ε 2 i − 1 ⋅ tr i ( X ) − tr i ( g z ) X − g z F_2(X):=\sum_{i\in I_2}\varepsilon_2^{i-1}\cdot \frac{\text{tr}_i(X)-\text{tr}_i(gz)}{X-gz} F2(X):=∑i∈I2ε2i−1⋅X−gztri(X)−tri(gz)
然后设置 F ( X ) : = F 1 ( X ) + ε 1 ⋅ F 2 ( X ) F(X):=F_1(X)+\varepsilon_1\cdot F_2(X) F(X):=F1(X)+ε1⋅F2(X)。
注意,由于 ε 1 , ε 2 \varepsilon_1,\varepsilon_2 ε1,ε2是均匀采样元素,因此对于所有的 i ≥ 0 i\geq 0 i≥0, ε 1 ⋅ ε 2 i \varepsilon_1\cdot\varepsilon_2^i ε1⋅ε2i也是均匀采样元素。
实际常用的 F F F多项式计算替换版本为:【常用版本。不可并行计算】
- 引入单个随机值 ε ∈ K \varepsilon\in\mathbb{K} ε∈K,然后直接计算:
F ~ ( X ) : = ∑ i ∈ I 1 ε i − 1 ⋅ tr i ( X ) − tr i ( z ) X − z + ∑ i ∈ I 2 ε ∣ I 1 ∣ + i − 1 ⋅ tr i ( X ) − tr i ( g z ) X − g z + ∑ i = 1 S ε ∣ I 1 ∣ + ∣ I 2 ∣ + i − 1 ⋅ Q i ( X ) − Q i ( z S ) X − z S , \widetilde{F}(X):=\sum_{i\in I_1}\varepsilon^{i-1}\cdot \frac{\text{tr}_i(X)-\text{tr}_i(z)}{X-z}+\sum_{i\in I_2}\varepsilon^{|I_1|+i-1}\cdot \frac{\text{tr}_i(X)-\text{tr}_i(gz)}{X-gz}\\+\sum_{i=1}^{S}\varepsilon^{|I_1|+|I_2|+i-1}\cdot \frac{Q_i(X)-Q_i(z^S)}{X-z^S}, F (X):=i∈I1∑εi−1⋅X−ztri(X)−tri(z)+i∈I2∑ε∣I1∣+i−1⋅X−gztri(X)−tri(gz)+i=1∑Sε∣I1∣+∣I2∣+i−1⋅X−zSQi(X)−Qi(zS), - 这个版本的主要缺点在于,不像之前版本那样可并行计算,因此本文选择上面的改进版本,即使这意味着将让proof size增加1个域元素。
- 本文采用的改进版本:当在计算 ε 2 \varepsilon_2 ε2的powers时,也可同时依序并行计算多项式 F 1 , F 2 F_1,F_2 F1,F2。
- 常用版本:必须在计算万所有的 ε \varepsilon ε的powers之后,才能依序计算 F ~ \widetilde{F} F 。
4. Polygon zkEVM的eSTARK协议
4.1 Extended Algebraic Intermediate Representation (eAIR)
作为 充分研究的AIR 的扩展,本节将介绍eAIR和eAIR satisfiability的概念。
关于AIR的知识,参看:
- Eli Ben-Sasson等人2019年论文Scalable Zero Knowledge with no Trusted Setup。
eAIR在AIR的基础上,扩展支持了更多约束类型,从而更具表达性。
回顾下 G = < g > G=
已知多项式 p 1 , ⋯ , p M ∈ F [ X ] p_1,\cdots,p_M\in\mathbb{F}[X] p1,⋯,pM∈F[X],AIR和AIR satisfiability定义为:
- algebraic intermediate representation (AIR) A A A 定义为:一组代数约束 { C 1 , ⋯ , C K } \{C_1,\cdots,C_K\} {C1,⋯,CK},使得每个 C i C_i Ci为基于 F [ X 1 , ⋯ , X M , X 1 ′ , ⋯ , X M ′ ] \mathbb{F}[X_1,\cdots,X_M,X_1',\cdots,X_M'] F[X1,⋯,XM,X1′,⋯,XM′]的某多项式。
- 对于每个 C i C_i Ci,其前半部分变量 X 1 , ⋯ , X M X_1,\cdots,X_M X1,⋯,XM将被替换为多项式 p 1 ( X ) , ⋯ , p M ( X ) p_1(X),\cdots,p_M(X) p1(X),⋯,pM(X),其后半部分变量 X 1 ′ , ⋯ , X M ′ X_1',\cdots,X_M' X1′,⋯,XM′将被替换为多项式 p 1 ( g X ) , ⋯ , p M ( g X ) p_1(gX),\cdots,p_M(gX) p1(gX),⋯,pM(gX)。
- AIR satisfiability 定义为:当且仅当对所有的 i ∈ [ K ] i\in[K] i∈[K],有:
C i ( p 1 ( x ) , ⋯ , p M ( x ) , p 1 ( g x ) , ⋯ , p M ( g x ) ) = 0 , ∀ x ∈ G C_i(p_1(x),\cdots,p_M(x),p_1(gx),\cdots,p_M(gx))=0,\forall x\in G Ci(p1(x),⋯,pM(x),p1(gx),⋯,pM(gx))=0,∀x∈G
均成立,则称多项式 p 1 , ⋯ , p M p_1,\cdots,p_M p1,⋯,pM 满足 指定AIR A = { C 1 , ⋯ , C K } A=\{C_1,\cdots,C_K\} A={C1,⋯,CK}。
需注意,本文定义的AIR,与ethSTARK中定义的AIR,主要做了2方面的简化:
- 1)约束仅基于“non-shifted”多项式和“shifted-by-one”多项式,即分别对应 p i ( X ) 和 p i ( g X ) p_i(X)和p_i(gX) pi(X)和pi(gX)。
- 2)enforce了约束需vanish over整个 G G G,而不是vanish over G G G的某个子集。
而接下来的eAIR(extended AIR)定义,将支持更通用的版本——将支持3.5节中所定义的新的约束类型。
已知多项式 p 1 , ⋯ , p M ∈ F [ X ] p_1,\cdots,p_M\in\mathbb{F}[X] p1,⋯,pM∈F[X],Extended AIR定义为:
- extended algebraic intermediate representation (eAIR) e A eA eA 定义为:一组代数约束 { C 1 , ⋯ , C K } \{C_1,\cdots,C_K\} {C1,⋯,CK},使得每个 C i C_i Ci为以下格式之一:
- a)与AIR中定义一样,为基于 F [ X 1 , ⋯ , X M , X 1 ′ , ⋯ , X M ′ ] \mathbb{F}[X_1,\cdots,X_M,X_1',\cdots,X_M'] F[X1,⋯,XM,X1′,⋯,XM′]的某多项式。【即对应的为 e A eA eA中的identity constraints。】
- b)为某正整数 R i R_i Ri,某基于 F [ X 1 , ⋯ , X M ] \mathbb{F}[X_1,\cdots,X_M] F[X1,⋯,XM]的 2 R i 2R_i 2Ri个多项式集合 C i , j C_{i,j} Ci,j,以及2个基于 F [ X ] \mathbb{F}[X] F[X]的selectors f i s e l , t i s e l f_i^{sel},t_i^{sel} fisel,tisel。注意对于所有的 x ∈ G x\in G x∈G,有 f i s e l ( x ) , t i s e l ( x ) ∈ { 0 , 1 } f_i^{sel}(x),t_i^{sel}(x)\in\{0,1\} fisel(x),tisel(x)∈{0,1}。【对应 e A eA eA中的non-identity constraints。】
- c)为某正数 S i ∈ [ M ] S_i\in [M] Si∈[M], { p 1 , ⋯ , p M } \{p_1,\cdots,p_M\} {p1,⋯,pM}集合的子集—— S i S_i Si个多项式 p ( 1 ) , ⋯ , p ( S i ) ∈ F [ X ] p_{(1)},\cdots,p_{(S_i)}\in\mathbb{F}[X] p(1),⋯,p(Si)∈F[X],以及 S i S_i Si个代表permutation σ i \sigma_i σi多项式 S σ i , 1 , ⋯ , S σ i , S i S_{\sigma_i,1},\cdots,S_{\sigma_i,S_i} Sσi,1,⋯,Sσi,Si。【对应 e A eA eA中的non-identity constraints。】
以上Extended AIR定义的目的,是为了可 以更通用的方式来处理3.4节中所定义的non-identity约束(即lookup argument、permutation argument、connection argument)。对应这些arguments的多项式,是 p 1 , ⋯ , p M p_1,\cdots,p_M p1,⋯,pM的多项式组合。
接下来:
- 以 P ‾ \overline{P} P来作为 p 1 , ⋯ , p M p_1,\cdots,p_M p1,⋯,pM的简略表示
- C ∘ P ‾ C\circ\overline{P} C∘P:表示基于 F [ X ] \mathbb{F}[X] F[X]的单变量多项式,其通过将约束 C ∈ F [ X 1 , ⋯ , X M , X 1 ′ , ⋯ , X M ′ ] C\in\mathbb{F}[X_1,\cdots,X_M,X_1',\cdots,X_M'] C∈F[X1,⋯,XM,X1′,⋯,XM′]中的 X i , X i ′ X_i,X_i' Xi,Xi′分别替换为 p i ( X ) , p i ( g X ) p_i(X),p_i(gX) pi(X),pi(gX)而来。即 C ∘ P ‾ C\circ\overline{P} C∘P,对应多项式 C ( p 1 ( X ) , ⋯ , p M ( X ) , p 1 ( g X ) , ⋯ , p M ( g X ) ) C(p_1(X),\cdots,p_M(X),p_1(gX),\cdots,p_M(gX)) C(p1(X),⋯,pM(X),p1(gX),⋯,pM(gX))。
相应的Extended AIR Satisfiability定义为:
- 当且仅当对于每个 i ∈ [ K ] i\in[K] i∈[K],以下有且仅有一个等式 对于所有的 x ∈ G x\in G x∈G 成立:
( C ∘ P ‾ ) ( x ) = 0 , (C\circ\overline{P})(x)=0, (C∘P)(x)=0,
f i s e l ( x ) ⋅ ( ( C i , 1 ∘ P ‾ ) ( x ) , ⋯ , ( C i , R i ∘ P ‾ ) ( x ) ) ∈ t i s e l ( x ) ⋅ ( ( C i , R i + 1 ∘ P ‾ ) ( x ) , ⋯ , ( C i , 2 R i ∘ P ‾ ) ( x ) ) , f_i^{sel}(x)\cdot((C_{i,1}\circ\overline{P})(x),\cdots,(C_{i,R_i}\circ\overline{P})(x))\in t_i^{sel}(x)\cdot((C_{i,R_{i+1}}\circ\overline{P})(x),\cdots,(C_{i,2R_i}\circ\overline{P})(x)), fisel(x)⋅((Ci,1∘P)(x),⋯,(Ci,Ri∘P)(x))∈tisel(x)⋅((Ci,Ri+1∘P)(x),⋯,(Ci,2Ri∘P)(x)),
f i s e l ( x ) ⋅ ( ( C i , 1 ∘ P ‾ ) ( x ) , ⋯ , ( C i , R i ∘ P ‾ ) ( x ) ) ≐ t i s e l ( x ) ⋅ ( ( C i , R i + 1 ∘ P ‾ ) ( x ) , ⋯ , ( C i , 2 R i ∘ P ‾ ) ( x ) ) , f_i^{sel}(x)\cdot((C_{i,1}\circ\overline{P})(x),\cdots,(C_{i,R_i}\circ\overline{P})(x))\doteq t_i^{sel}(x)\cdot((C_{i,R_{i+1}}\circ\overline{P})(x),\cdots,(C_{i,2R_i}\circ\overline{P})(x)), fisel(x)⋅((Ci,1∘P)(x),⋯,(Ci,Ri∘P)(x))≐tisel(x)⋅((Ci,Ri+1∘P)(x),⋯,(Ci,2Ri∘P)(x)),
( p ( 1 ) , ⋯ , p ( S i ) ) ∝ ( S σ i , 1 , ⋯ , S σ i , S i ) . p_{(1)},\cdots,p_{(S_i)})\propto(S_{\sigma_i,1},\cdots,S_{\sigma_i,S_i}). p(1),⋯,p(Si))∝(Sσi,1,⋯,Sσi,Si).
则,称多项式 p 1 , ⋯ , p M ∈ F [ X ] p_1,\cdots,p_M\in\mathbb{F}[X] p1,⋯,pM∈F[X] 满足 指定eAIR e A = { C 1 , ⋯ , C K } eA=\{C_1,\cdots,C_K\} eA={C1,⋯,CK}。
4.2 Setup Phase
在4.3节的协议中,Prover和Verifier均需访问一组预处理多项式 pre i ∈ F [ X ] \text{pre}_i\in\mathbb{F}[X] prei∈F[X]。尤其是:
- Prover需以系数或evaluation形式,来完整访问这些预处理多项式,以 正确的生成proof。
- Verifier仅需访问这些预处理多项式基于domain H H H的evaluations的子集。
为此,eSTARK协议中会假设存在名为setup phase的阶段,即在协议消息交互之前,又在确定了特定待证明statement之后——即在确定了描述待证明statement约束集之后。
在setup phase,会计算预处理多项式,且Prover和Verifier会收到这些预处理多项式的不同信息。特别地,setup phase的输入为一组多项式约束,其包含如下步骤:
- 1)计算每个预处理多项式的trace LDE。
- 2)计算预处理多项式集合的Merkle tree。
- 3)最后:
- 将完整的Merkle tree发送给Prover。
- 将相应的Merkle tree root发送给Verifier。当Verifier需要计算任意预处理多项式基于 h ∈ H h\in H h∈H的evaluation值时,其可向Prover请求:
- Prover会响应相应的evaluation值的同时,也回复其对应的Merkle tree path。
- 然后,Verifier使用该Merkle tree root来验证所收到信息的正确性。
注意:
- 由于setup phase的算力要求大于 O ( log ( n ) ) \mathcal{O}(\log (n)) O(log(n)),因此若想让本协议满足verifier scalability,则无法将setup phase包含在verifier description中。
- 本setup phase,没有包含Verifier,对预处理多项式Merkle tree计算正确性,的衡量。但是,由于本setup phase的输入为代表problem’s statement的多项式约束集——其对Verifier也是已知的,因此Verifier可在setup phase的任意时间来运行检查该计算的有效性。
- Prover和Verifier都需要访问vanishing多项式 Z G ( X ) : = X n − 1 Z_G(X):=X^n-1 ZG(X):=Xn−1基于 H H H的evaluations值,以及首个Lagrange多项式 L 1 ( X ) : = g ( X n − 1 ) n ( X − g ) L_1(X):=\frac{g(X^n-1)}{n(X-g)} L1(X):=n(X−g)g(Xn−1)基于 H H H的evaluations值。
尽管 Z G 和 L 1 Z_G和L_1 ZG和L1将在eSTARK协议后续阶段出现,且原则上不认为它们是预处理多项式,但它们是公开已知的多项式,因此,也将 Z G 和 L 1 Z_G和L_1 ZG和L1包含在setup phase的Merkle tree计算中。
4.3 针对eAIR的IOP
在协议之初,假设上面的setup phase已成功执行,且Prover和Verifier固定了:
- 某特定eAIR实例 e A = { C ~ 1 , ⋯ , C ~ T ′ } eA=\{\widetilde{C}_1,\cdots,\widetilde{C}_{T'}\} eA={C 1,⋯,C T′}
- e A eA eA中的约束排序为:
- a)首先为identity约束;
- b)然后是inclusion argument;
- c)接下来是permutation argument;
- d)最后是connection argument。
在整个eSTARK协议描述过程中,使用如下标记:
- 令 N , R N,R N,R为2个非负整数。令 N N N为trace column多项式数量, R R R为预处理多项式数量。
- 在 e A eA eA的多项式约束集中,以 M , M ′ M ′ ′ ∈ Z ≥ 0 M,M'M''\in\mathbb{Z}_{\geq 0} M,M′M′′∈Z≥0来分别表示inclusion arguments的数量、permutation arguments的数量,以及connection arguments的数量。
- Prover的 p p pp pp参数中,包含:
- 有限域 F \mathbb{F} F
- domain G , H G,H G,H
- 扩域 K \mathbb{K} K
- eAIR实例 e A eA eA
- 所有公开值(public values)
- 承诺多项式集合
- 预处理多项式的Merkle tree。
- Verifier的 v p vp vp参数中包含:
- 有限域 F \mathbb{F} F
- domain G , H G,H G,H
- 扩域 K \mathbb{K} K
- eAIR实例 e A eA eA
- 所有公开值(public values)
- 预处理多项式的Merkle tree root。
eSTARK协议中对eAIR的IOP,可看成是Eli Ben-Sasson等人2019年论文DEEP-FRI: Sampling outside the box improves soundnes DEPP-ALI协议的扩展。
已知trace column多项式集合 tr 1 , ⋯ , tr N ∈ F < n [ X ] \text{tr}_1,\cdots,\text{tr}_N\in\mathbb{F}_{
-
1)Round 1:Trace Column Oracles:
- 1.1)Prover发送对 tr 1 , ⋯ , tr N ∈ F < n [ X ] \text{tr}_1,\cdots,\text{tr}_N\in\mathbb{F}_{
- 1.2)Verifier回复均匀采样值 α , β ∈ K \alpha,\beta\in\mathbb{K} α,β∈K给Prover。
- 1.3)Prover计算由部分identity约束组成的的中间多项式 im i ∈ F < n [ X ] \text{im}_i\in\mathbb{F}_{
由于在后续Round 3中也可能会引入新的中间多项式,此Round中,Prover将为 im 1 , ⋯ , im K \text{im}_1,\cdots,\text{im}_K im1,⋯,imK设置oracles。
- 1.1)Prover发送对 tr 1 , ⋯ , tr N ∈ F < n [ X ] \text{tr}_1,\cdots,\text{tr}_N\in\mathbb{F}_{
-
2)Round 2:Inclusion Oracles:详情见3.4节,如有需要,Prover可:
- 使用 α \alpha α,来将vector inclusions reduce为 simple inclusions或simple selected inclusion,以及将vector permutations reduce为 simple permutations或simple selected permutations。
- 使用 β \beta β,来将selected inclusions reduce为 simple (non-selected) inclusions,以及将selected permutations reduce为 simple (non-selected) permutations。
在完成以上2个reduction之后,Prover会为每个inclusion argument计算inclusion多项式 h i , 1 , h i , 2 ∈ K < n [ X ] h_{i,1},h_{i,2}\in\mathbb{K}_{
- 2.1)Prover发送oracle functions集合 [ h 1 , 1 ] , [ h 1 , 2 , ⋯ , [ h M , 1 ] , [ h M , 2 ] ] [h_{1,1}],[h_{1,2},\cdots,[h_{M,1}],[h_{M,2}]] [h1,1],[h1,2,⋯,[hM,1],[hM,2]]给Verifier。
- 2.2)Verifier回复均匀采样值 γ , δ ∈ K \gamma,\delta\in\mathbb{K} γ,δ∈K。
-
3)Round 3:Grand Product和Intermediate Oracles:
Prover使用 γ , δ \gamma,\delta γ,δ来计算每个argument的grand product多项式 Z i ∈ K < n [ X ] Z_i\in\mathbb{K}_{
注意,某些用于断言connection argument的grand product多项式有效 的identity约束,其degree可能大于等于4。因此按照3.6节,Prover会通过引入中间多项式,来将这些约束切分为degree最多为3的多个约束。令 K ′ ∈ Z ≥ 0 K'\in\mathbb{Z}_{\geq 0} K′∈Z≥0为所引入的中间多项式个数,表示为 im K + i ∈ K [ X ] \text{im}_{K+i}\in\mathbb{K}[X] imK+i∈K[X],对应 i ∈ [ K ′ ] i\in[K'] i∈[K′]。- 3.1)Prover发送oracle functions集合 [ Z 1 ] , ⋯ , [ Z M + M ′ + M ′ ′ ] [Z_1],\cdots,[Z_{M+M'+M''}] [Z1],⋯,[ZM+M′+M′′]和 [ im 1 ] , ⋯ , [ im K + K ′ ] [\text{im}_1],\cdots,[\text{im}_{K+K'}] [im1],⋯,[imK+K′]给Verifier。
- 3.2)Verifier回复均匀采样值 a ∈ K \mathfrak{a}\in\mathbb{K} a∈K。
至此,原始的eAIR e A = { C ~ 1 , ⋯ , C ~ T ′ } eA=\{\widetilde{C}_1,\cdots,\widetilde{C}_{T'}\} eA={C 1,⋯,C T′},就reduce为了,某AIR A = { C 1 , ⋯ , C T } A=\{C_1,\cdots,C_T\} A={C1,⋯,CT},有 T ≥ T ′ T\geq T' T≥T′。接下来,借助3.5节和3.6节提到的一些修改,可继续基于 A A A执行DEEP-ALI协议。【若eAIR实例 e A eA eA就是AIR,则可跳过以上Round 2和Round 3,转为在Round 1之后继续执行后续Round 4步骤。】
-
4)Round 4:Trace Quotient Oracles:
- 4.1)Prover使用 a \mathfrak{a} a来计算quotient多项式 Q ( X ) ∈ K [ X ] Q(X)\in\mathbb{K}[X] Q(X)∈K[X]:
Q ( X ) : = ∑ i = 1 T a i − 1 ( C i ∘ P ‾ ) ( X ) Z G ( X ) , (29) Q(X):=\sum_{i=1}^{T}\mathfrak{a}^{i-1}\frac{(C_i\circ \overline{P})(X)}{Z_G(X)},\tag{29} Q(X):=i=1∑Tai−1ZG(X)(Ci∘P)(X),(29)
其中:- 使用 P ‾ \overline{P} P来表示包含了 tr 1 , ⋯ , tr N , pre 1 , ⋯ , pre R , h 1 , 1 , h 1 , 2 , ⋯ , h M , 1 , h M , 2 , Z 1 , ⋯ , Z M + M ′ + M ′ ′ , im 1 , ⋯ , im K + K ′ \text{tr}_1,\cdots,\text{tr}_N,\text{pre}_1,\cdots,\text{pre}_R,h_{1,1},h_{1,2},\cdots,h_{M,1},h_{M,2},Z_1,\cdots,Z_{M+M'+M''},\text{im}_1,\cdots,\text{im}_{K+K'} tr1,⋯,trN,pre1,⋯,preR,h1,1,h1,2,⋯,hM,1,hM,2,Z1,⋯,ZM+M′+M′′,im1,⋯,imK+K′的多项式序列。
- 因此, ( C i ∘ P ‾ ) ( X ) (C_i\circ \overline{P})(X) (Ci∘P)(X)为单变量多项式,其是多变量多项式 C i C_i Ci,与 P ‾ \overline{P} P中各单变量多项式的non-shifted和shifted版本,的组合。
- 4.2)然后Prover将quotient多项式 Q Q Q切分为2个degree小于 n n n的trace quotient多项式 Q 1 , Q 2 Q_1,Q_2 Q1,Q2。二者满足如下关系:
Q = Q 1 ( X ) + X n ⋅ Q 2 ( X ) = ∑ i = 1 T a i − 1 ( C i ∘ P ‾ ) ( X ) Z G ( X ) , (30) Q=Q_1(X)+X^n\cdot Q_2(X)=\sum_{i=1}^{T}\mathfrak{a}^{i-1}\frac{(C_i\circ \overline{P})(X)}{Z_G(X)},\tag{30} Q=Q1(X)+Xn⋅Q2(X)=i=1∑Tai−1ZG(X)(Ci∘P)(X),(30) - 4.3)Prover发送oracle functions集合 [ Q 1 ] , [ Q 2 ] [Q_1],[Q_2] [Q1],[Q2]给Verifier。
- 4.1)Prover使用 a \mathfrak{a} a来计算quotient多项式 Q ( X ) ∈ K [ X ] Q(X)\in\mathbb{K}[X] Q(X)∈K[X]:
-
5)Round 5:DEEP Query Answers:
- 5.1)Verifier给Prover发送某均匀采样DEEP query值 z ∈ K ∖ ( G ∪ H ) z\in\mathbb{K}\setminus (G\cup H) z∈K∖(G∪H)。注意:
- 要求 z ∉ G z\notin G z∈/G,是为确保上面等式(30)右侧的分子有效。
- 要求 z ∉ H z\notin H z∈/H,是为确保后续Round 6 FRI协议中多项式 F ( X ) F(X) F(X)中的分子项有效。
- 5.2)Prover会返回之前rounds中oracles集合 或 预处理多项式oracles集合,相应的evaluations结合 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz)。
在此需注意2点:- 某个多项式可能同时有在 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz)中的evaluations。
- 预处理多项式的evaluations值也包含在 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz)中。
- 5.3)Verifier给Prover发送均匀采样值 ε 1 , ε 2 ∈ K \varepsilon_1,\varepsilon_2\in\mathbb{K} ε1,ε2∈K。
- 5.1)Verifier给Prover发送某均匀采样DEEP query值 z ∈ K ∖ ( G ∪ H ) z\in\mathbb{K}\setminus (G\cup H) z∈K∖(G∪H)。注意:
-
6)Round 6:FRI Protocol:
6.1)将 P ‾ \overline{P} P中evaluation分别属于 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz)的多项式,分别表示为 f i , h i f_i,h_i fi,hi。Prover计算多项式 F 1 , F 2 ∈ K [ X ] F_1,F_2\in\mathbb{K}[X] F1,F2∈K[X]:
F 1 ( X ) : = ∑ i = 1 ∣ Evals ( z ) ∣ ε 2 i − 1 f i ( X ) − f i ( z ) X − z , F_1(X):=\sum_{i=1}^{|\text{Evals}(z)|}\varepsilon_2^{i-1}\frac{f_i(X)-f_i(z)}{X-z}, F1(X):=∑i=1∣Evals(z)∣ε2i−1X−zfi(X)−fi(z),
F 2 ( X ) : = ∑ i = 1 ∣ Evals ( g z ) ∣ ε 2 i − 1 h i ( X ) − h i ( g z ) X − g z , F_2(X):=\sum_{i=1}^{|\text{Evals}(gz)|}\varepsilon_2^{i-1}\frac{h_i(X)-h_i(gz)}{X-gz}, F2(X):=∑i=1∣Evals(gz)∣ε2i−1X−gzhi(X)−hi(gz),
然后Prover计算多项式 F ( X ) : = F 1 ( X + ε 1 ⋅ F 2 ( X ) ) F(X):=F_1(X+\varepsilon_1\cdot F_2(X)) F(X):=F1(X+ε1⋅F2(X))。
6.2)最后Prover和Verifier运行FRI协议来证明 F F F是low degree的。在运行FRI协议之初,Prover首先会发送Verifier oracle [ F ] [F] [F]。 -
7)Round 7:Verification:与vanilla STARK Verifier类似,eSTARK协议Verifier的验证流程为:【若以下a)和b)有任意失败,则Verifier将中断并拒绝,否则接受。】
- a)ALI Consistency:
Verifier 通过 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz)中的evaluations值和等式(30),来检查trace quotient多项式 Q 1 , Q 2 Q_1,Q_2 Q1,Q2,与trace column多项式 tr 1 , ⋯ , tr N \text{tr}_1,\cdots,\text{tr}_N tr1,⋯,trN、预处理多项式 pre 1 , ⋯ , pre R \text{pre}_1,\cdots,\text{pre}_R pre1,⋯,preR、inclusion相关多项式 h 1 , 1 , h 1 , 2 , ⋯ , h M , 1 , h M , 2 h_{1,1},h_{1,2},\cdots,h_{M,1},h_{M,2} h1,1,h1,2,⋯,hM,1,hM,2、grand product多项式 Z 1 , ⋯ , Z M + M ′ + M ′ ′ Z_1,\cdots,Z_{M+M'+M''} Z1,⋯,ZM+M′+M′′、中间多项式 im 1 , ⋯ , im K + K ′ \text{im}_1,\cdots,\text{im}_{K+K'} im1,⋯,imK+K′,的一致性。 - b)Batched FRI Verification:Verifier基于多项式 F F F运行batched FRI验证流程。
- a)ALI Consistency:
很容易直观地给出Protocol 3的soundness上限。
Theorem 3(STIK for eAIR):
- Protocol 3中包含了a STIK for extended AIR satisfiability,即该协议用于证明拥有满足某特定extended AIR实例 e A = { C ~ 1 , ⋯ , C ~ T ′ } eA=\{\widetilde{C}_1,\cdots,\widetilde{C}_{T'}\} eA={C 1,⋯,C T′} 的多项式集合 p 1 , ⋯ , p N + R ∈ F < ∣ G ∣ [ X ] p_1,\cdots,p_{N+R}\in\mathbb{F}_{<|G|}[X] p1,⋯,pN+R∈F<∣G∣[X]。
以 ε e S T A R K \varepsilon_{eSTARK} εeSTARK来表示Protocol 3协议的soundness,则:
ε e S T A R K = ε A r g s + l ( T − 1 ∣ K ∣ + ( D + ∣ G ∣ + 2 ) ⋅ l ∣ K ∣ − ∣ H ∣ − ∣ G ∣ ) + ε F R I \varepsilon_{eSTARK}=\varepsilon_{Args}+l(\frac{T-1}{|\mathbb{K}|}+\frac{(D+|G|+2)\cdot l}{|\mathbb{K}|-|H|-|G|})+\varepsilon_{FRI} εeSTARK=εArgs+l(∣K∣T−1+∣K∣−∣H∣−∣G∣(D+∣G∣+2)⋅l)+εFRI
其中:- l = m / ρ l=m/\rho l=m/ρ, m m m为大于等于3的整数。
- D D D:为等式(29)中用于求和计算quotient多项式 Q Q Q的各多项式中的最大degree。
- ε A r g s \varepsilon_{Args} εArgs:为对应Protocol 2的soundness error。
- ε F R I \varepsilon_{FRI} εFRI:基于FRI多项式 F F F的batched FRI协议的soundness error。
“eSTARK协议的soundness error ε e S T A R K \varepsilon_{eSTARK} εeSTARK” 与 “2.4节vanilla STARK协议的soundness error ε S T A R K \varepsilon_{STARK} εSTARK” 的主要区别为:
- 1)在计算quotient多项式 Q Q Q时,使用单个随机值的powers a i − 1 \mathfrak{a}^{i-1} ai−1 来代替 每个约束 C i C_i Ci一组 ( a i , b i ) (\mathfrak{a}_i,\mathfrak{b}_i) (ai,bi)。如等式(30)所示,对应的quotient多项式对变量 a \mathfrak{a} a的degree为 T − 1 T-1 T−1。因此根据Schwartz-Zippel lemma,会将上限值由 1 / ∣ K ∣ 1/|\mathbb{K}| 1/∣K∣增加为 ( T − 1 ) / ∣ K ∣ (T-1)/|\mathbb{K}| (T−1)/∣K∣。
- 2)将quotient多项式切分为trace quotient多项式 Q 1 , Q 2 Q_1,Q_2 Q1,Q2,二者与 Q Q Q呈线性关系,即 Q 1 ( X ) + X n Q 2 ( X ) = Q ( X ) Q_1(X)+X^nQ_2(X)=Q(X) Q1(X)+XnQ2(X)=Q(X);而vanilla中是呈exponential关系,即 Q 1 ( X 2 ) + X Q 2 ( X 2 ) = Q ( X ) Q_1(X^2)+XQ_2(X^2)=Q(X) Q1(X2)+XQ2(X2)=Q(X)。从而仅需要约束采样空间为 z ∈ K ∖ ( G ∪ H ) z\in \mathbb{K}\setminus (G\cup H) z∈K∖(G∪H),而不是 z ∈ K ∖ ( G ∪ H ˉ ) z\in \mathbb{K}\setminus (G\cup \bar{H}) z∈K∖(G∪Hˉ)
以上Theorem 3结论的证明思路为,分为2种场景:
-
1)假设eAIR e A eA eA正好就是AIR,其中没有其它arguments约束。即意味着Protocol 3协议中的Round 2和Round 3均可跳过,最终的协议是(改进版的)vanilla STARK——即由:
- DEEP-ALI协议
- 和 batched FRI协议
组合。相应的soundness也对应分为2部分:
- DEEP-ALI协议的soundness:见Eli Ben-Sasson等人2019年论文DEEP-FRI: Sampling outside the box improves soundnes 中的Theorem 6.2。
- batched FRI协议的soundness:见Eli Ben-Sasson等人2020年论文Proximity gaps for reed-solomon codes中的Theorem 8.3。
这2种协议组合后的soundness分析见2021年论文ethSTARK documentatio中的Corollary 2。
即若eAIR e A eA eA正好就是AIR,由于其中没有其它arguments,有 ε A r g s = 0 \varepsilon_{Args}=0 εArgs=0,最终有 ε S T A R K = ε e S T A R K \varepsilon_{STARK}=\varepsilon_{eSTARK} εSTARK=εeSTARK。 -
2)对于eAIR e A eA eA中有arguments的情况。其第一项 ε A r g s \varepsilon_{Args} εArgs为所包含的arguments的soundness error,其余为DEEP-ALI soundness error和batched FRI协议的soundness error。
4.4 由STIK到Non-interactive STARK
如2.3节的STARK定义可知,将4.3节的STIK转换为STARK是非常简单的:
- 1)首先将Prover在每轮发送给Verifier的oracles,替换为单个Merkle tree root。详情见3.1节。
如,第一轮Prover发送的oracle 集合 [ tr 1 ] , ⋯ , [ tr N ] [\text{tr}_1],\cdots,[\text{tr}_N] [tr1],⋯,[trN],替换为,包含 tr 1 , ⋯ , tr N \text{tr}_1,\cdots,\text{tr}_N tr1,⋯,trN基于domain H H H的evaluations值组成的Merkle tree的root。 - 2)Verifier不再向Prover query一组多项式oracles [ f 1 ] , ⋯ , [ f N ] [f_1],\cdots,[f_N] [f1],⋯,[fN]在同一点 v v v的evaluation值,而是Prover在返回答案 f 1 ( v ) , ⋯ , f N ( v ) f_1(v),\cdots,f_N(v) f1(v),⋯,fN(v)的同时,还返回相应的Merkle path。
- 3)本文并未指定用于计算每个Merkle tree的哈希函数,仅强调:构建Merkle tree所用的哈希函数,与将协议变为non-interactive的哈希函数,二者没有任何关系,只要其输出空间在合适的域内即可。
以:
- seed \text{seed} seed:来表示对初始eAIR实例 e A = { C ~ 1 , ⋯ , C ~ T ′ } eA=\{\widetilde{C}_1,\cdots,\widetilde{C}_{T'}\} eA={C 1,⋯,C T′}中所有公开值和预处理多项式Merkle tree root的拼接。
这些值会用作模拟首个Verifier消息的哈希函数 H \mathcal{H} H的seed。
4.5 eSTARK完整协议描述
将eSTARK协议描述分为Prover算法和Verifier算法,并在每轮的Prover算法中 包含 (通过Fiat-Shamir)Verifier挑战值的计算,以及Prover实际计算的消息。
本节沿用4.3节的标记和假设。
4.5.1 eSTARK协议中 Prover算法
eSTARK协议中各轮的Prover算法有:
- 1)Round 1:Trace Column多项式:
- Prover对给定的trace column多项式 tr 1 , ⋯ , tr N ∈ F < n [ X ] \text{tr}_1,\cdots,\text{tr}_N\in\mathbb{F}_{
- 在本步骤中,Prover还会计算源自identity约束子集的中间多项式 im 1 , ⋯ , im K \text{im}_1,\cdots,\text{im}_K im1,⋯,imK,
- Round 1中Prover的输出为 MTR ( tr 1 , ⋯ , tr N ) \text{MTR}(\text{tr}_1,\cdots,\text{tr}_N) MTR(tr1,⋯,trN)。
- Prover对给定的trace column多项式 tr 1 , ⋯ , tr N ∈ F < n [ X ] \text{tr}_1,\cdots,\text{tr}_N\in\mathbb{F}_{
- 2)Round 2:Inclusion多项式:
- 首先初始化transcript实例 t r a n s c r i p t transcript transcript。
- Prover向 t r a n s c r i p t transcript transcript中添加: seed \text{seed} seed、用作trace column多项式 { tr } i \{\text{tr}\}_i {tr}i承诺值的Merkle root:
add t r a n s c r i p t ( seed , MTR ( { tr } i ) ) \text{add}_{transcript}(\text{seed},\text{MTR}(\{\text{tr}\}_i)) addtranscript(seed,MTR({tr}i))
然后从中提取Verifier会发来的挑战值 α , β ∈ K \alpha,\beta\in\mathbb{K} α,β∈K:
α = extract 1 ( t r a n s c r i p t ) , β = extract 2 ( t r a n s c r i p t ) . \alpha=\text{extract}_1(transcript),\beta=\text{extract}_2(transcript). α=extract1(transcript),β=extract2(transcript). - Prover使用 α , β \alpha,\beta α,β计算每个inclusion argument i ∈ [ M ] i\in[M] i∈[M] 相应的inclusion多项式 h i , 1 , h i , 2 ∈ K < n [ X ] h_{i,1},h_{i,2}\in\mathbb{K}_{
- Round 2中Prover的输出为 MTR ( h 1 , 1 , h 1 , 2 , ⋯ , h M , 1 , h M , 2 ) \text{MTR}(h_{1,1},h_{1,2},\cdots,h_{M,1},h_{M,2}) MTR(h1,1,h1,2,⋯,hM,1,hM,2)。
- 3)Round 3:Grand Product多项式和中间多项式:
- Prover向 t r a n s c r i p t transcript transcript中添加:承诺 { h } i , j \{h\}_{i,j} {h}i,j的Merkle tree的root值:
add t r a n s c r i p t ( MTR ( { h } i , j ) ) \text{add}_{transcript}(\text{MTR}(\{h\}_{i,j})) addtranscript(MTR({h}i,j))
然后从中提取Verifier会发来的挑战值 γ , δ ∈ K \gamma,\delta\in\mathbb{K} γ,δ∈K:
γ = extract 1 ( t r a n s c r i p t ) , δ = extract 2 ( t r a n s c r i p t ) . \gamma=\text{extract}_1(transcript),\delta=\text{extract}_2(transcript). γ=extract1(transcript),δ=extract2(transcript). - Prover使用 γ , δ \gamma,\delta γ,δ来计算每个argument i ∈ [ M + M ′ + M ′ ′ ] i\in[M+M'+M''] i∈[M+M′+M′′] 的grand product多项式 Z i ∈ K < n [ X ] Z_i\in\mathbb{K}_{
- Prover还会计算剩余的中间多项式 im K + 1 , im K + K ′ \text{im}_{K+1},\text{im}_{K+K'} imK+1,imK+K′。
- Round 3中,Prover会对grand product多项式进行承诺,还会对所有的中间多项式 im 1 , ⋯ , im K + K ′ \text{im}_1,\cdots,\text{im}_{K+K'} im1,⋯,imK+K′进行承诺。为节约proof中1个元素,Prover会让grand product多项式和中间多项式共用一棵Merkle tree。
- Round 3中Prover的输出为 MTR ( Z 1 , ⋯ , Z M + M ′ + M ′ ′ , im 1 , ⋯ , im K + K ′ ) \text{MTR}(Z_1,\cdots,Z_{M+M'+M''},\text{im}_1,\cdots,\text{im}_{K+K'}) MTR(Z1,⋯,ZM+M′+M′′,im1,⋯,imK+K′)。
- Prover向 t r a n s c r i p t transcript transcript中添加:承诺 { h } i , j \{h\}_{i,j} {h}i,j的Merkle tree的root值:
- 4)Round 4:trace quotient多项式:
- Prover向 t r a n s c r i p t transcript transcript中添加:承诺 { Z } i 和 { im } i \{Z\}_{i}和\{\text{im}\}_i {Z}i和{im}i的Merkle tree的root值:
add t r a n s c r i p t ( MTR ( { Z } i ) , MTR ( { im } i ) ) \text{add}_{transcript}(\text{MTR}(\{Z\}_{i}),\text{MTR}(\{\text{im}\}_{i})) addtranscript(MTR({Z}i),MTR({im}i))
然后从中提取Verifier会发来的挑战值 a ∈ K \mathfrak{a}\in\mathbb{K} a∈K:
a = extract 1 ( t r a n s c r i p t ) . \mathfrak{a}=\text{extract}_1(transcript). a=extract1(transcript). - Prover使用 a \mathfrak{a} a来计算quotient多项式 Q ( X ) ∈ K [ X ] Q(X)\in\mathbb{K}[X] Q(X)∈K[X]:
Q ( X ) : = ∑ i = 1 T a i − 1 ( C i ∘ P ‾ ) ( X ) Z G ( X ) , Q(X):=\sum_{i=1}^{T}\mathfrak{a}^{i-1}\frac{(C_i\circ \overline{P})(X)}{Z_G(X)}, Q(X):=i=1∑Tai−1ZG(X)(Ci∘P)(X),
然后像等式(27)那样,将quotient多项式 Q ( X ) Q(X) Q(X)切分为2个degree小于 n n n的多项式 Q 1 , Q 2 Q_1,Q_2 Q1,Q2。二者满足如下关系:
Q = Q 1 ( X ) + X n ⋅ Q 2 ( X ) = ∑ i = 1 T a i − 1 ( C i ∘ P ‾ ) ( X ) Z G ( X ) , (31) Q=Q_1(X)+X^n\cdot Q_2(X)=\sum_{i=1}^{T}\mathfrak{a}^{i-1}\frac{(C_i\circ \overline{P})(X)}{Z_G(X)},\tag{31} Q=Q1(X)+Xn⋅Q2(X)=i=1∑Tai−1ZG(X)(Ci∘P)(X),(31)
然后Prover对 Q 1 , Q 2 Q_1,Q_2 Q1,Q2进行承诺。 - Round 4中Prover的输出为 MTR ( Q 1 , Q 2 ) \text{MTR}(Q_1,Q_2) MTR(Q1,Q2)。
- Prover向 t r a n s c r i p t transcript transcript中添加:承诺 { Z } i 和 { im } i \{Z\}_{i}和\{\text{im}\}_i {Z}i和{im}i的Merkle tree的root值:
- 5)Round 5:DEEP Query Answers:
- Prover向 t r a n s c r i p t transcript transcript中添加:承诺 Q 1 和 Q 2 Q_1和Q_2 Q1和Q2的Merkle tree的root值:
add t r a n s c r i p t ( MTR ( Q 1 , Q 2 ) ) \text{add}_{transcript}(\text{MTR}(Q_1,Q_2)) addtranscript(MTR(Q1,Q2))
然后从中提取Verifier会发来的挑战值 z ∈ K z\in\mathbb{K} z∈K:
z = extract 1 ( t r a n s c r i p t ) . z=\text{extract}_1(transcript). z=extract1(transcript).- 若 z ∈ G z\in G z∈G或 z ∈ H z\in H z∈H,则额外引入一个计数器作为哈希函数的输入,并持续增加该计数器值,使 z ∈ K ∖ ( G ∪ H ) z\in\mathbb{K}\setminus (G\cup H) z∈K∖(G∪H)。 z z z不符合要求的概率为 ( ∣ G ∣ + ∣ H ∣ ) / ∣ K ∣ (|G|+|H|)/|\mathbb{K}| (∣G∣+∣H∣)/∣K∣,实际情况下这个概率很低。
- Prover计算evaluations集合 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz)。
- Round 5 Prover的输出为 ( Evals ( z ) , Evals ( g z ) ) (\text{Evals}(z),\text{Evals}(gz)) (Evals(z),Evals(gz))。
- Prover向 t r a n s c r i p t transcript transcript中添加:承诺 Q 1 和 Q 2 Q_1和Q_2 Q1和Q2的Merkle tree的root值:
- 6)Round 6:FRI协议:
- Prover向 t r a n s c r i p t transcript transcript中添加evaluations集合 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz):
add t r a n s c r i p t ( Evals ( z ) , Evals ( g z ) ) , \text{add}_{transcript}(\text{Evals}(z),\text{Evals}(gz)), addtranscript(Evals(z),Evals(gz)),
然后从中提取Verifier会发来的挑战值 ε 1 , ε 2 ∈ K \varepsilon_1,\varepsilon_2\in\mathbb{K} ε1,ε2∈K:
ε 1 = extract 1 ( t r a n s c r i p t ) , ε 2 = extract 2 ( t r a n s c r i p t ) . \varepsilon_1=\text{extract}_1(transcript),\varepsilon_2=\text{extract}_2(transcript). ε1=extract1(transcript),ε2=extract2(transcript). - Prover将 P ‾ \overline{P} P中evaluation分别属于 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz)的多项式,分别表示为 f i , h i f_i,h_i fi,hi。Prover计算多项式 F 1 , F 2 ∈ K [ X ] F_1,F_2\in\mathbb{K}[X] F1,F2∈K[X]:
F 1 ( X ) : = ∑ i = 1 ∣ Evals ( z ) ∣ ε 2 i − 1 f i ( X ) − f i ( z ) X − z , F_1(X):=\sum_{i=1}^{|\text{Evals}(z)|}\varepsilon_2^{i-1}\frac{f_i(X)-f_i(z)}{X-z}, F1(X):=∑i=1∣Evals(z)∣ε2i−1X−zfi(X)−fi(z),
F 2 ( X ) : = ∑ i = 1 ∣ Evals ( g z ) ∣ ε 2 i − 1 h i ( X ) − h i ( g z ) X − g z , F_2(X):=\sum_{i=1}^{|\text{Evals}(gz)|}\varepsilon_2^{i-1}\frac{h_i(X)-h_i(gz)}{X-gz}, F2(X):=∑i=1∣Evals(gz)∣ε2i−1X−gzhi(X)−hi(gz),
然后Prover计算多项式 F ( X ) : = F 1 ( X + ε 1 ⋅ F 2 ( X ) ) F(X):=F_1(X+\varepsilon_1\cdot F_2(X)) F(X):=F1(X+ε1⋅F2(X))。 - 最后Prover对,证明 F F F多项式为low degree的,运行(非交互式)FRI协议,获得FRI proof π F R I \pi_{FRI} πFRI。
- Round 6 Prover的输出为 π F R I \pi_{FRI} πFRI。
- Prover向 t r a n s c r i p t transcript transcript中添加evaluations集合 Evals ( z ) 和Evals ( g z ) \text{Evals}(z)和\text{Evals}(gz) Evals(z)和Evals(gz):
- 7)最终Prover返回的 π e S T A R K \pi_{eSTARK} πeSTARK为:

整个eSTARK协议框架描述为:

4.5.2 eSTARK协议中的Verifier算法
为验证eSTARK,Verifier会执行如下操作:
- 1)检查 MTR ( tr 1 , ⋯ , tr N ) \text{MTR}(\text{tr}_1,\cdots,\text{tr}_N) MTR(tr1,⋯,trN)、 MTR ( h 1 , 1 , h 1 , 2 , ⋯ , h M , 1 , h M , 2 ) \text{MTR}(h_{1,1},h_{1,2},\cdots,h_{M,1},h_{M,2}) MTR(h1,1,h1,2,⋯,hM,1,hM,2)、 MTR ( Z 1 , ⋯ , Z M + M ′ + M ′ ′