设计模式之享元模式
文章目录
- 一、介绍
- 二、主要角色
- 三、通用代码演示
- 四、案例演示
-
- 1. 姓名接口类`Name`
- 2. 姓名实现类`NameImpl`
- 3. 姓名工厂类`NameFactory`
- 4. 姓名客户端类`NameClient`
- 5. 输出结果
- 五、享元模式在jdk中的应用
-
- 1. Integer类中的IntegerCache
- 2. Byte类中的ByteCache
- 六、与单例模式的关系
-
- 1. 为什么不属于创建型设计模式
- 七、优缺点
一、介绍
享元模式(FlyWeight),属于结构型设计模式,主要解决实例化大量相同的对象,从而导致可能的内存泄漏的问题。
为了解决这个问题,享元模式提出的解决办法是将相同的对象保存在内存中,且仅保存一个对象,因此该对象应该是不可被修改的,当需要获取该对象实例时,直接从内存中读取即可,从而避免了相同对象的重复创建。
下面是享元模式的定义:
运用共享技术有效地支持大量细粒度的对象。
二、主要角色
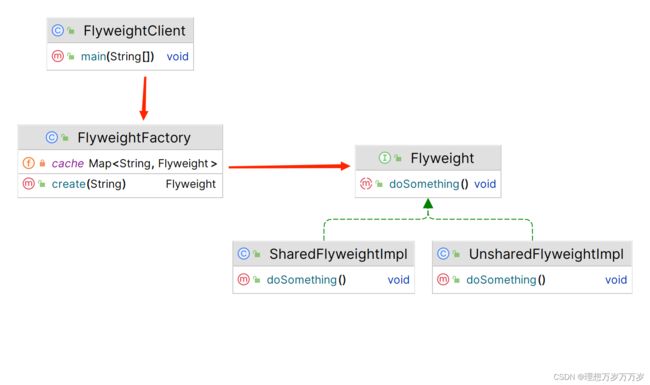
享元模式有以下四个基本角色:
-
享元工厂(FlyWeightFactory)
工厂模式的应用,用来创建并管理享元对象,根据某一标准,在完成享元对象实例化以后,判断是否需要对该实例对象进行管理。如果客户端需要从享元工厂中获取某些实例,享元工厂将会判断是否对相同的实例进行管理,如果存在被管理的相同的实例对象,则无需重复对其进行实例化,而是直接返回被管理的对象。
一般来说,享元工厂通过
HashMap对需要共享的实例进行管理。 -
抽象享元(FlyWeight)
享元类的抽象接口,规定了对象的行为。
-
共享的具体享元(SharedFlyWeightImpl)
实现于抽象享元接口,对其规定的行为进行具体实现。并且该类的实例对象在由享元工厂实例化以后,需要被工厂管理,以便在以后需要相同的对象时直接返回,而不是重复实例化。
-
非共享的具体享元(UnsharedFlyWeightImpl)
实现于抽象享元接口,对其规定的行为进行具体实现。与共享的具体享元实例不同的是,非共享的具体享元在被享元工厂实例化以后,不被工厂管理,即每一次需要该实例时,都需要享元工厂重复创建。
享元模式的通用UML类图如下所示
三、通用代码演示
基于以上通用UML类图,我们通过代码对其进行演示
-
新建**抽象享元(Flyweight)**接口
public interface Flyweight { void doSomething(); } -
新建**共享的具体享元(SharedFlyweightImpl)**类
public class SharedFlyweightImpl implements Flyweight{ @Override public void doSomething() { System.out.println("共享的享元对象:doSomething()方法,hash值:" + hashCode()); } } -
新建**非共享的具体享元(UnsharedFlyweightImpl)**类
public class UnsharedFlyweightImpl implements Flyweight{ @Override public void doSomething() { System.out.println("非共享的享元对象:doSomething()方法,hash值:" + hashCode()); } } -
新建**享元工厂(FlyweightFactory)**类
在享元工厂中,我们使用**Map对象
cache**模拟缓存,由工厂创建并管理的实例都保存在该cache中。如果我们需要的享元实例是以
share_开头,说明该实例是共享的享元实例,则需要从缓存中判断是否存在对应的实例,如果存在,则说明该实例已被创建且被管理,直接返回即可。如果不存在,则创建后保存到缓存cache并返回该实例。如果我们需要的享元实例是以
unshare_开头,说明该实例是非共享的实例,工厂则需要重复创建实例并返回,而无需保存到缓存。public class FlyweightFactory { private static final Map<String, Flyweight> cache = new HashMap<>(); public static Flyweight create(String flyweightKey) { Flyweight flyweight = null; if (flyweightKey.startsWith("share_")) { flyweight = cache.get(flyweightKey); if (flyweight == null) { flyweight = new SharedFlyweightImpl(); cache.put(flyweightKey, flyweight); } } else if (flyweightKey.startsWith("unshare_")) { flyweight = new UnsharedFlyweightImpl(); } return flyweight; } } -
新建**客户端(FlyweightClient)**类
public class FlyweightClient { public static void main(String[] args) { // 第一个share_instance1实例 Flyweight first = FlyweightFactory.create("share_instance1"); // 第二个share_instance1实例 Flyweight second = FlyweightFactory.create("share_instance1"); first.doSomething(); second.doSomething(); System.out.println(first == second); // 输出为true,说明两个实例对象为同一个,来自缓存 System.out.println(); Flyweight instance2 = FlyweightFactory.create("share_instance2"); instance2.doSomething(); System.out.println(first == instance2); System.out.println(); // 第一个unshare_instance3实例 Flyweight third = FlyweightFactory.create("unshare_instance3"); // 第二个unshare_instance3实例 Flyweight forth = FlyweightFactory.create("unshare_instance3"); third.doSomething(); forth.doSomething(); System.out.println(third == forth); // 输出为true,说明两个实例对象不是同一个,重复创建 } }
运行以上代码,可得以下结果

四、案例演示
我们以给新生儿起名字为例,在我们社会中,比如张伟、晓燕、小宝,这些名字到处可见,而嬴政、玄烨、乔治这样的名字又少之又少。从代码的角度来看,如果我们在每次需要起张伟这个名字的时候,都去创建一个实例,那么对内存占用无疑是一种不友好的行为;而起嬴政、玄烨、乔治这样的名字时,由于使用这种名字的人本来就不多,也就无所谓我们重复创建了。
所以我们使用享元模式来模拟该案例。
1. 姓名接口类Name
public interface Name {
}
2. 姓名实现类NameImpl
该类中使用属性name保存姓名,该属性通过构造方法设置。
public class NameImpl implements Name{
private final String name;
public NameImpl(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
3. 姓名工厂类NameFactory
在该工厂中,有一个保存常用姓名的字段commonNameList,使用这些名字的姓名实例Name在创建实例后由缓存cache管理,再次需要相同的名字实例时从缓存cache中获取即可,避免了相同实例的重复创建;而不是常用名字的情况,则需要重复创建实例。
public class NameFactory {
// 常用的名字
private static final List<String> commonNameList = Arrays.asList("ZhangWei", "XiaoYan", "XiaoBao");
// Map模拟缓存
private static Map<String, Name> cache = new HashMap<>();
public static Name create(String nameStr) {
Name name = null;
if (commonNameList.contains(nameStr)) {
name = cache.get(nameStr);
if (name == null) {
name = new NameImpl(nameStr);
cache.put(nameStr, name);
}
} else {
name = new NameImpl(nameStr);
}
return name;
}
}
4. 姓名客户端类NameClient
public class NameClient {
public static void main(String[] args) {
Name zhangWei_1 = NameFactory.create("ZhangWei");
Name zhangWei_2 = NameFactory.create("ZhangWei");
// 如果为true,说明ZhangWei是从缓存中获取的共享实例,避免了实例的重复创建
System.out.println("如果为true,说明ZhangWei是从缓存中获取的共享实例,避免了实例的重复创建");
System.out.println(zhangWei_1 == zhangWei_2);
System.out.println();
Name xiaoYan_1 = NameFactory.create("XiaoYan");
Name xiaoYan_2 = NameFactory.create("XiaoYan");
System.out.println("如果为true,说明XiaoYan是从缓存中获取的共享实例,避免了实例的重复创建");
System.out.println(xiaoYan_1 == xiaoYan_2);
System.out.println();
System.out.println("如果为false,说明ZhangWei和XiaoYan是来自缓存的两个不同实例");
System.out.println(zhangWei_1 == xiaoYan_1);
System.out.println();
Name yingZheng_1 = NameFactory.create("YingZheng");
Name yingZheng_2 = NameFactory.create("YingZheng");
System.out.println("如果为false,说明名字为YingZheng的两个实例yingZheng_1和yingZheng_2是重复创建的两个实例");
System.out.println(yingZheng_1 == yingZheng_2);
}
}
5. 输出结果
运行该案例,输出以下结果

五、享元模式在jdk中的应用
享元模式在jdk中广泛应用,如Integer.valueOf() 和 Byte.valueOf(),看过源码的同学都知道,在Integer.valueOf()中,如果我们传入的参数是-128 ~ 127之间的整数,那么Integer会从IntegerCache中返回一个已经创建好的实例。同样的,在Byte.valueOf()中,由于一个字节只有8个bit,其范围是从-128~ 127,共256个整数,因此在jvm启动时,就会预先创建好这256个整数对应的Byte实例。
下面我们看源码解析
1. Integer类中的IntegerCache
首先查看Integer.valueOf()方法
// 其中IntegerCache.low = -128,IntegerCache.high = 127
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
从该方法中,我们看到,如果传入的参数位于-128和127之间,则从IntegerCache的cache数组中返回。
下面我们来看IntegerCache的源码。该类中有一个静态代码块,在jvm启动时就会立刻执行该代码块。
在该代码块中,通过for循环对cache数组进行初始化,数组中每一个元素都是-128和127之间的Integer实例。
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
2. Byte类中的ByteCache
同样进入Byte.valueOf()方法
public static Byte valueOf(byte b) {
final int offset = 128;
return ByteCache.cache[(int)b + offset];
}
从该源码中看到,直接从ByteCache的cache数组中返回对应的Byte实例
下面我们查看ByteCache的源码
与IntegerCache类似,在静态代码块中通过for循环直接对cache数组进行初始化,该数组中每一个元素都是对应的Byte对象。
private static class ByteCache {
private ByteCache(){}
static final Byte cache[] = new Byte[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Byte((byte)(i - 128));
}
}
六、与单例模式的关系
从设计的角度来讲,享元模式与单例模式的区别似乎都应该属于创建型设计模式,因为他们的目的都是为了避免频繁创建相同的对象。
1. 为什么不属于创建型设计模式
从使用者的角度来讲,他们之间又有很大的不同,通过单例模式获取的对象实例,并没有对我们修改实例做出限制,而通过享元模式获取的对象实例,我们是无法对其做出修改的,从Integer和Byte中的应用我们也可以看出,他们都是被final所修饰的,不允许修改。
七、优缺点
优点:
- 可以避免重复创建大量相同的对象实例。
- 可以帮助我们确定哪些对象是放在缓存共享的,哪些不需要共享。
缺点:
- 代码的复杂程度有所增加,需要确定哪些对象是放在缓存共享的,哪些不需要共享。
纸上得来终觉浅,绝知此事要躬行。
————————我是万万岁,我们下期再见————————